c语言程序分析
#define _CRT_SECURE_NO_WARNINGS#include <stdio.h>#include <stdlib.h>int main(int argc, char const *argv[]){printf("%s\n", "hello world\n");system("pause");return EXIT_SUCCESS;}
#include <stdio.h> 就是一条预处理指令,他的作用就是通知c语言编译系统在对c程序进行正式编译之前需做一些预处理工作#就是预处理的标识, 展开头文件宏替换
ps: windows路径以 \\ 或者 /
system("C:/Users/hello.exe");
system("C:\\Users\\hello.exe");
程序编译链接
过程
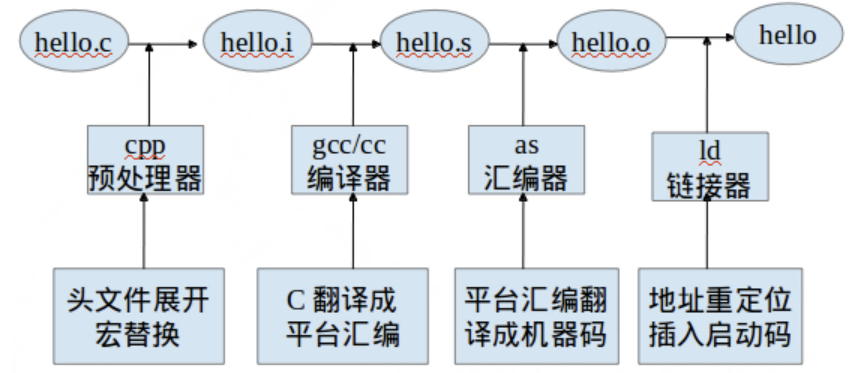
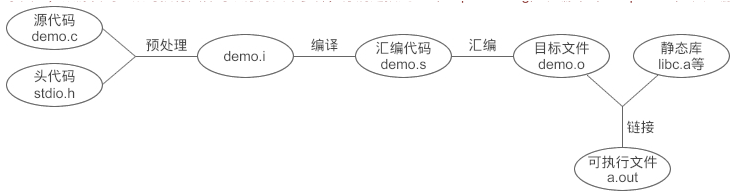
- 预处理:宏文件展开,头文件展开,条件编译等,同时将代码中的注释删除,这里并不会检查语法
- 编译: 检查语法,将预处理后文件编译生成汇编文件
- 汇编: 将汇编文件生成目标文件(二进制文件)
- 链接: C语言写的程序是需要依赖各种库的,所以编译之后还需要把库链接到最终可执行程序中去
GCC 的-std=参数还可以指定按照哪个 C 语言的标准进行编译。预处理: gcc -E hello.c -o hello.i 编译: gcc -S hello.i -o hello.s 汇编: gcc -c hello.s -o hello.o 链接: gcc hello.o -o hello_elfgcc -std=c99 hello.c
| 选项 | 含义 |
|---|---|
| -E | 只进行预处理 |
| -S(大写) | 只进行预处理和编译 |
| -c(小写) | 只进行预处理,编译和汇编 |
| -o file | 指定生成的输出文件名为file |
在 Visual Studio 中,不用进行任何设置就可以在工程目录下看到 demo.asm 文件
预处理, 展开头文件和宏替换
.c -> .i
gcc -E hello.c -o hello.i
编译, 检查语法, c源代码变为汇编
.i / .c -> .s
gcc -S hello.i -o hello.s
汇编, 汇编变为二进制
.s -> .o
gcc -c hello.s -o hello.o
链接, 二进制文件变为可执行文件
写的程序需要依赖各种库的, 所以编译之后还需要把库链接到最终可执行程序中
.o -> 可执行程序app
gcc hello.o -o app
预处理
预处理过程主要是处理那些源文件和头文件中以#开头的命令,比如 #include、#define、#ifdef 等。
预处理的规则一般如下:
- 将所有的
#define删除,并展开所有的宏定义。 - 处理所有条件编译命令,比如 #if、#ifdef、#elif、#else、#endif 等。
- 处理
#include命令,将被包含文件的内容插入到该命令所在的位置,这与复制粘贴的效果一样。注意,这个过程是递归进行的,也就是说被包含的文件可能还会包含其他的文件。 - 删除所有的注释
//和/* ... */ - 添加行号和文件名标识,便于在调试和出错时给出具体的代码位置。
- 保留所有的
#pragma命令,因为编译器需要使用它们。
预处理的结果是生成.i文件。.i文件也是包含C语言代码的源文件,只不过所有的宏已经被展开,所有包含的文件已经被插入到当前文件中。
当你无法判断宏定义是否正确,或者文件包含是否有效时,可以查看.i文件来确定问题。
在 GCC 中,可以通过下面的命令生成.i文件:gcc -E demo.c -o demo.i-E表示只进行预编译
在 Visual Studio 中,在当前工程的属性面板中将“预处理到文件”设置为“是”,如下图所示: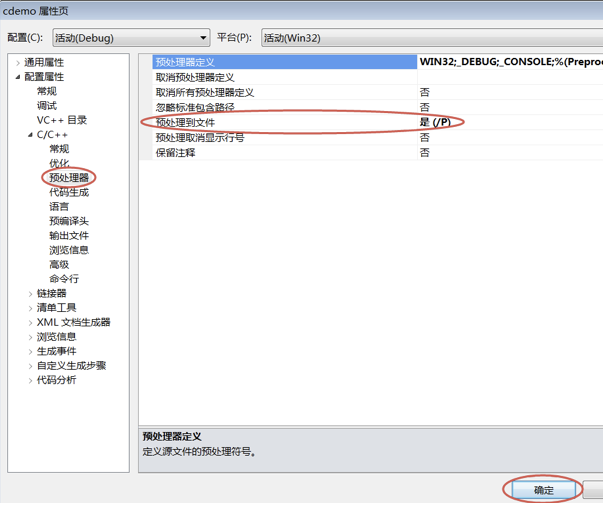
然后点击“运行(Run)”或者“构建(Build)”按钮,就能在当前工程目录中看到 demo.i
编译
检查语法,将预处理后文件编译生成汇编文件
编译: gcc -S hello.i -o hello.s
汇编(Assembly)
汇编的过程就是将汇编代码转换成可以执行的机器指令。大部分汇编语句对应一条机器指令,有的汇编语句对应多条机器指令
汇编过程相对于编译来说比较简单,没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编语句和机器指令的对照表一一翻译就可以了。
汇编的结果是产生目标文件,在 GCC 下的后缀为**.o**,在 Visual Studio 下的后缀为**.obj**
链接(Linking)
目标文件已经是二进制文件,与可执行文件的组织形式类似,只是有些函数和全局变量的地址还未找到,程序不能执行。
链接的作用就是找到这些目标地址,将所有的目标文件组织成一个可以执行的二进制文件。
预处理和汇编的过程都比较简单。
编译的过程最为复杂,可以细分为词法分析、语法分析、语义分析和指令优化,这里涉及到诸多算法以及正则表达式
而目标文件的结构、可执行文件的结构、链接的过程是我们要重点研究的,它能够让我们明白多文件编程以及模块化开发的原理,这是大型项目开发的基石。
最后需要说明的是:汇编的过程非常简单,仅仅是查表翻译,我们通常把它作为编译过程的一部分,不再单独提及。这样,源文件经过预处理、编译和链接就生成了可执行文件
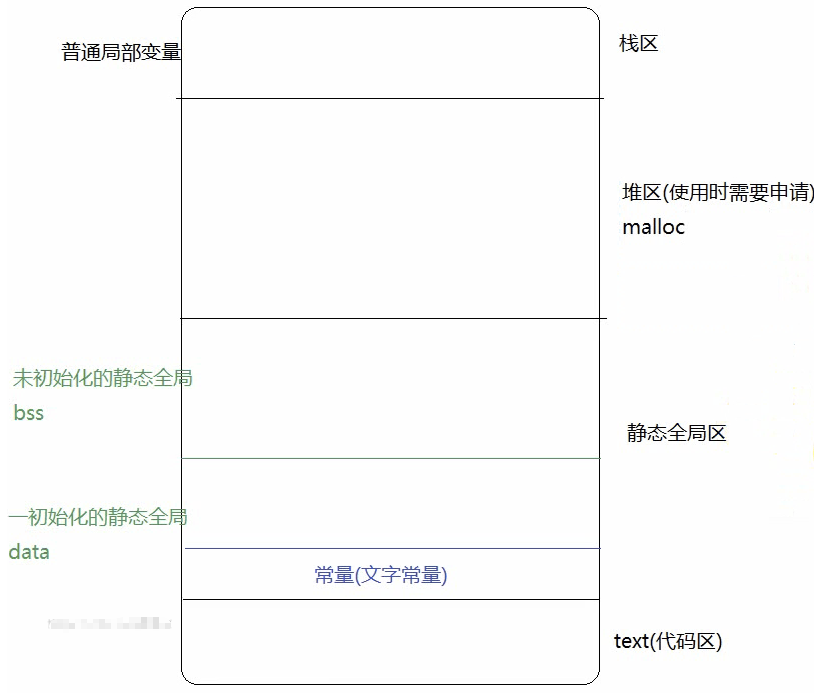
内存四区
代码区,数据区,栈区,堆区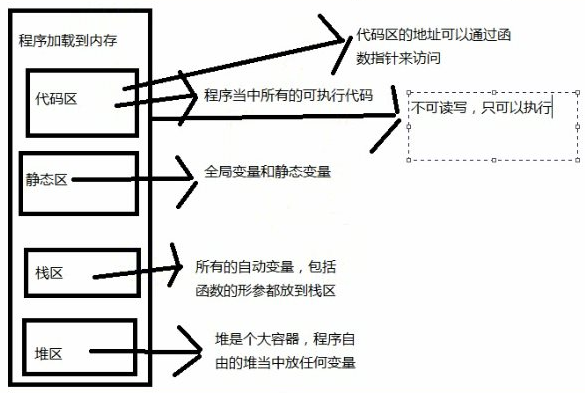
- 代码区: 程序被操作系统加载到内存, 所有可执行代码加载到 代码区, 也叫代码段, 可以在运行期间修改
数据区: 主要包括静态全局区和常量区, 如果要站在汇编的角度还可以分为很多小的区域.
全局区(静态区)(static): 全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一 块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一款区域. 程序结束有序释放.
例子: ```cppdefine _CRT_SECURE_NO_WARNINGS
include
include
char fa()
{
char pa = “123456”;//pa指针在栈区,“123456”在常量区,该函数调用完后指针变量pa就被释放了
char p = NULL;
p = (char)malloc(100);//本函数在这里开辟了一块堆区的内存空间,并把地址赋值给p
strcpy(p, “abc 1234566”);//把常量区的字符串拷贝到堆区
return p;//返回给主调函数fb(),相对fa来说fb是主调函数,相对main来说,fa(),fb()都是被调用函数
}
char fb() { char pstr = NULL; pstr = fa(); return pstr;//指针变量pstr在这就结束 }
int main(int argc, char const argv[]) { char str = NULL; str = fb(); printf(“str = %s\n”, str); free(str); //防止内存泄漏 str = NULL;//防止产生野指针 system(“pause”); return EXIT_SUCCESS; }
总结
1. 主调函数分配的内存空间(堆,栈,全局区)可以在被调用函数中使用,可以以指针作函数参数的形式来使用
2. 被调用函数分配的内存空间只有堆区和全局区可以在主调函数中使用(返回值和函数参数),而栈区却不行,因为栈区函数体运行完之后, 这个函数占用的内存编译器自动帮你释放了
3. 一定要明白函数的主被调关系以及主被调函数内存分配回收,也就是后面接下几篇总结的函数的输入输出内存模型
4. **sizeof测量的就是在栈区和堆区的字长**,比如讲,在一个结构体中,存在一个 static int a 的成员,sizeof是不会计算a的这四个字节长度,**因为static静态数据成员是在数据区内,不在sizeof的测量范围内**
<a name="q6su5"></a>
# size
常量在data里面<br /><br />通过上图可以得知,在没有运行程序前,也就是说程序没有加载到内存前,可执行程序内部已经分好3段信息,分别为代码区(text)、数据区(data)和未初始化数据区(bss)3 个部分(有些人直接把data和bss合起来叫做静态区或全局区)。
:::info
- 代码区
存放 CPU 执行的机器指令。通常代码区是可共享的(即另外的执行程序可以调用它),使其可共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可。代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指t令。另外,代码区还规划了局部变量的相关信息。
- 全局初始化数据区/静态数据区(data段)
该区包含了在程序中明确被初始化的全局变量、已经初始化的静态变量(包括全局静态变量和t)和常量数据(如字符串常量)。
- 未初始化数据区(又叫 bss 区)
存入的是全局未初始化变量和未初始化静态变量。未初始化数据区的数据在程序开始执行之前被内核初始化为 0 或者空(NULL)。
总体来讲说,程序源代码被编译之后主要分成两种段:程序指令(代码区)和程序数据(数据区)。代码段属于程序指令,而数据域段和.bss段属于程序数据。
:::
:::success
那为什么把程序的指令和程序数据分开呢?
- 程序被load到内存中之后,可以将数据和代码分别映射到两个内存区域。由于数据区域对进程来说是可读可写的,而指令区域对程序来讲说是只读的,所以分区之后呢,可以将程序指令区域和数据区域分别设置成可读可写或只读。这样可以防止程序的指令有意或者无意被修改;
- 当系统中运行着多个同样的程序的时候,这些程序执行的指令都是一样的,所以只需要内存中保存一份程序的指令就可以了,只是每一个程序运行中数据不一样而已,这样可以节省大量的内存。比如说之前的Windows Internet Explorer 7.0运行起来之后, 它需要占用112 844KB的内存,它的私有部分数据有大概15 944KB,也就是说有96 900KB空间是共享的,如果程序中运行了几百个这样的进程,可以想象共享的方法可以节省大量的内存。
:::
<a name="R5VLk"></a>
# 查看依赖哪些库
```cpp
ldd xx
linux下可以用 **ldd 可执行文件名**, 看一个可执行文件依赖哪些库
mac用otool -L来代替ldd
➜ bin git:(master) otool -L ./openresty
./openresty:
/usr/lib/libSystem.B.dylib (compatibility version 1.0.0, current version 1311.100.3)
/opt/homebrew/Cellar/openresty/1.21.4.1_1/luajit/lib/libluajit-5.1.2.dylib (compatibility version 2.1.0, current version 2.1.0)
/opt/homebrew/opt/pcre/lib/libpcre.1.dylib (compatibility version 4.0.0, current version 4.13.0)
/opt/homebrew/opt/openresty-openssl111/lib/libssl.1.1.dylib (compatibility version 1.1.0, current version 1.1.0)
/opt/homebrew/opt/openresty-openssl111/lib/libcrypto.1.1.dylib (compatibility version 1.1.0, current version 1.1.0)
/usr/lib/libz.1.dylib (compatibility version 1.0.0, current version 1.2.11)
/opt/homebrew/opt/geoip/lib/libGeoIP.1.dylib (compatibility version 8.0.0, current version 8.12.0)
windows可以用 **Dependency** 这个工具来看一个可执行文件依赖哪些库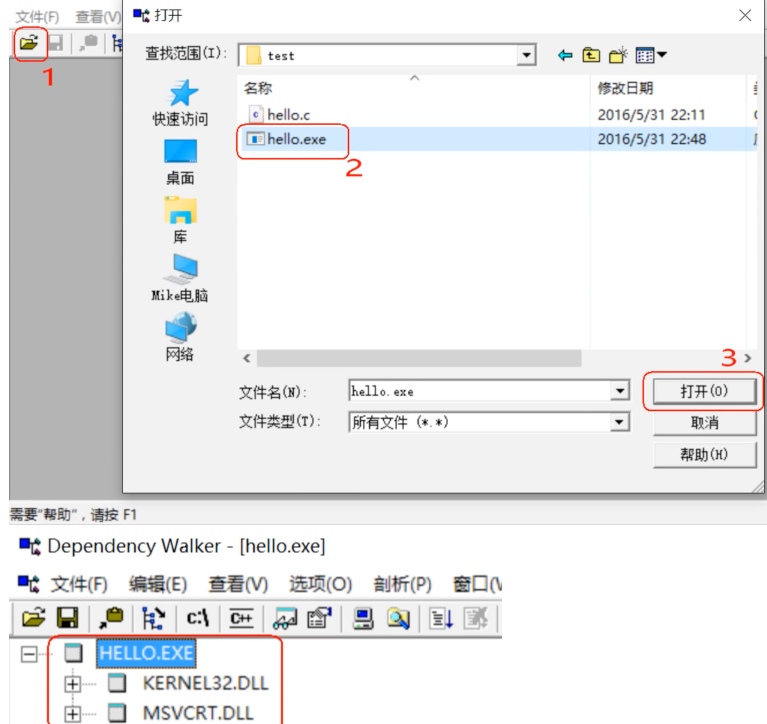
查看是多少位
- 寄存器是CPU内部最基木的存储单元
- CPU对外是通过总线(地址、控制、数据)来和外部设备交互的,总线的宽度是8位,同时CPU的寄存器也是8位,那么这个CPU就叫8位CPU
- 如果总线是32位,寄存器也是32位的,那么这个CPU就是32位CPU
- 有一种CPU内部的寄存器是32位的,但总线是16位,准32为CPU
- 所有的64位CPU兼容32位的指令,32位要兼容16位的指令,所以在64位的CPU上是可以识别32位的指令
- 在64位的CPU构架上运行了64位的软件操作系统,那么这个系统是64位
- 在64位的CPU构架上,运行了32位的软件操作系统,那么这个系统就是32位
- 64位的软件不能运行在32位的CPU之上
# 会显示位数 file 编译后的文件scanf键盘录入
输出单个字符char a = 0; scanf("%c", &a); printf("ch1 = %c\n", a); //把换行吃掉 scanf("%c", &a); char e; scanf("%c", &e); printf("ch2 = %c\n", e); system("pause"); // getchar(); return EXIT_SUCCESS; // return 0;

若有收获,就点个赞吧
0 人点赞
