ClickHouse是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),使用C++语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告
文档: https://clickhouse.com/docs/zh/ ClickHouse中文社区:http://www.clickhouse.com.cn 在大数据分析领域中,传统的大数据分析需要不同框架和技术组合才能达到最终的效果,在人力成本,技术能力和硬 件成本上以及维护成本让大数据分析变得成为昂贵的事情。让很多中小型企业非常苦恼,不得不被迫租赁第三方大型 公司的数据分析服务。 ClickHouse开源的出现让许多想做大数据并且想做大数据分析的很多公司和企业耳目一新。ClickHouse 正是以不依 赖Hadoop 生态、安装和维护简单、查询速度快、可以支持SQL等特点在大数据分析领域越走越远。 # ClickHouse的特点 ## 列式存储 以下面的表为例: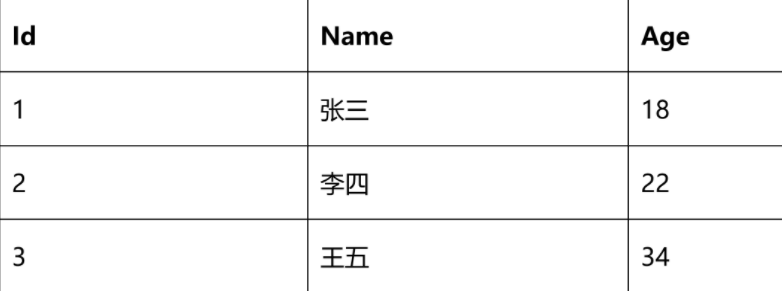
1)采用行式存储时,数据在磁盘上的组织结构为:


3)列式存储的好处:
- 对于列的聚合、计数、求和等统计操作原因优于行式存储
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重
- 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间
DBMS的功能
几乎覆盖了标准SQL的大部分语法,包括DDL和DML,以及配套的各种函数,用户管理及权限管理,数据的备份与恢复
多样化引擎
ClickHouse和MySQL类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类20多种引擎
高吞吐写入能力
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度
数据分区与线程级并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity(索引粒度),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时
所以,ClickHouse即使对于大量数据的查询也能够化整为零并行处理。但是有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高qps的查询业务,ClickHouse并不是强项
sql支持
支持的查询包括GROUP BY, ORDER BY
子查询在FROM,IN,JOIN子句中被支持;
标量子查询支持。
关联子查询不支持。
真是因为ClickHouse提供了标准协议的SQL查询接口,使得现有可视化分析系统能够轻松与他集成对接
数据复制和对数据完整性的支持
使用异步多主复制。写入任何可用的副本后,数据将分发到所有剩余的副本。系统在不同的副本上保持相同的数据。 数据在失败后自动恢复
ClickHouse的不完美:
1.不支持事物。
2.不支持Update/Delete操作。
3.支持有限操作系统。
现在支持ubuntu,centos 需要自己编译,不过有热心人已经编译好了,拿来用就行。对于Windows 不支持
向量化执行引擎
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
- 向量化执行,可以简单地看作一项消除程序中循环的优化。
- 现代计算机系统概念中,向量化执行是通过数据并行以提高性能的一种实现方式(其他的还有指令级并行和线程级并行),它的原理是在CPU寄存器层面实现数据的并行操作。
- 为了实现向量化执行,需要利用CPU的SIMD指令。
- SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据。
- ClickHouse目前利用SSE4.2指令集实现向量化执行
SIMD (Single Instruction Multiple Data) 即单条指令操作多条数据——原理即在CPU 寄存器层面实现数据的并行操作
ClickHouse 目前使用SSE4.2 指令集实现向量化执行
要能够使用 Intel 的 SIMD 指令集,不仅需要当前 Intel 处理器的硬件支持,还需要编译器的支持
如果你的机器支持SSE4.2,那么,将打印:
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
SIMD 的全称是 Single Instruction Multiple Data,中文名“单指令多数据”。顾名思义,一条指令处理多个数据。
SSE 4.2 supported
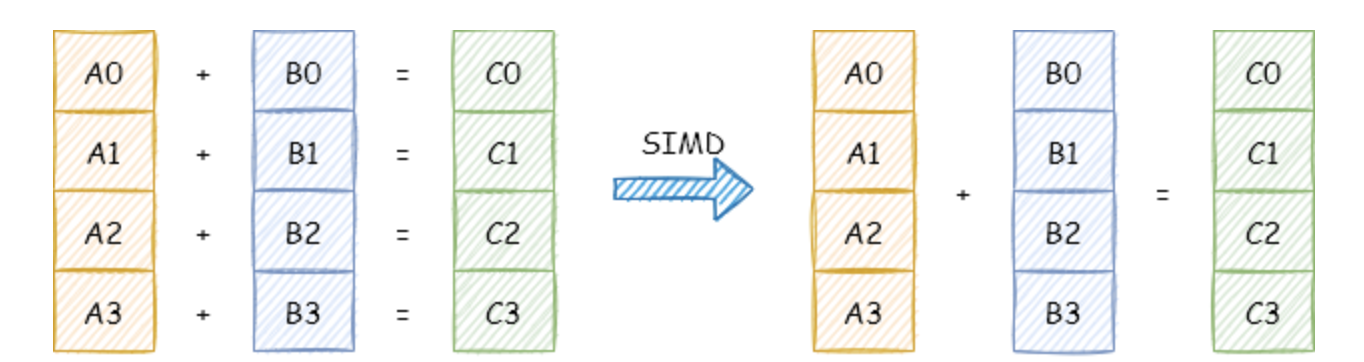
- 一个普通加法指令,一次只能对两个数执行一个加法操作。
- 一个 SIMD 加法指令,一次可以对两个数组(向量)执行加法操作。
利用优点: 频繁调用的基础函数,大量的可并行计算尽量避免: SSE指令集对分支处理能力非常的差,而且从128位的数据中提取某些元素数据的代价又非常的大,因此不适合有复杂逻辑的运算。
比如 一个简单的LowerUpperImpl函数为例(这个函数完成大小写转换)就可以利用这个前提条件
首先向量化执行引擎效率的发挥需要数据库能够提供列存表的支持。 对于传统的行存表来说,谈向量化执行是不可能的。通常向量化执行引擎都是用在OLAP数仓类系统,因为通常分析型系统通常都是数据处理密集型负载,基本上都是采用顺序方式来访问表中大部分的数据,然后进行计算,最后将计算结果输出给终端用户。对于典型的OLTP点查询,这种类型的查询执行,使用行存表反而比列存表更好
多线程与分布式
- 多线程
- 分布式
多主架构
ClickHouse 采用了 Multi Master 多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。 多主架构中每个节点对等的角色使系统架构变得更加简单,不用再区分主控节点、数据节点和计算节点,集群中的所有节点功能相同。 多主架构天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景。数据分片与分布式查询
数据分片是将数据进行横向切分,这是一种在面对海量数据的场景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现。 ClickHouse支持分片,而分片则依赖集群。每个集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点,分片的数量上限取决于节点数量 。 ClickHouse提供了本地表(LocalTable)与分布式表(DistributedTable)的概念。- 本地表等同于一份数据的分片。
- 分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
ClickHouse使用场景
Clickhouse 适用于结构良好清晰且不可变的事件或日志流实时查询分析。 如物联网,在线游戏,电子商务,金融数据等场景。ClickHouse 的不足
ClickHouse作为一款高性能OLAP数据库,虽然足够优秀,但也不是万能的。我们不应该把它用于任何OLTP事务性操作的场景,因为它有以下几点不足。- 不支持事务。
- 不擅长根据主键按行粒度进行查询(虽然支持),故不应该把ClickHouse当作KeyValue数据库使用。
- 不擅长按行删除数据(虽然支持)。
ClickHouse与其他 OLAP对比
| 组件 | 说明 |
|---|---|
| Druid | 分布式的、支持实时多维OLAP分析的数据处理系统。 |
| Kylin | 开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据。 |
| Presto | 分布式的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto擅长对海量数据进行复杂的分析。 |
| ClickHouse | 面向 OLAP 的分布式列式数据库,能够使用 SQL 查询生成实时数据报告。 |
| Doris | PB 级联机分析处理引擎,为客户提供稳定、高效、低成本的在线报表和多维分析服务。 |
| OLAP产品 | 数据摄入 | 存储方式 | 查询性能 | 用户友好程度 | 场景 |
|---|---|---|---|---|---|
| Druid | 支持离线 Hdfs 数据摄入和实时 Kafka 数据摄入 | LSM 变种,采用 一层全维度的 roll up 进行预计算,不存储明细 | 查询时在 broker 层面进行更加深层的 聚合计算,毫 秒级到秒级 | 组件繁多,有多种组件和进 程,依赖 ZK 和 MySQL, 运维相对复 杂,维度度量修改支持在线修改,对用户友好,需要时间字段 。 | iot、实时监控指 标产出、实时渠道聚合分析等 |
| Kylin | 支持 Hive 和 Kafka 摄入,由于使用基于 mr 和 spark的计 算引擎进行 cube构建,难以达到分钟级延迟,延迟至少在 十分钟至半小时级别 | 全维度预计算构建 cube,支持 一些策略的剪枝,减少无用计算量,开源版本依赖 HBase 作 为 Storage | 基于全量预计算产 出、亚 秒级 | 依赖 Hadoop 生态,适合维度、度量相对 稳定的 cube 分析,一旦需 要修改维度、 度量需要重新配置,重新构建,不一定需要时间字段 | 维度、度量明确的场景、分析聚合维度多样化,维度 尽量不要 超过 20 维,否则将产生维度爆炸 |
| ClickHouse | 支持离线在线数据录入,但是由于存储设计实时数据摄入千万不 能单条频繁摄入,一定要做 batch 汇总 | 与 kylin、druid 不同,不做预计算,完全是通过索引、列式存储、压缩、向量化、code gen 等充分压榨 cpu 等计算资源达到 快速计算的目的 | 毫秒级至秒级不等 | 单一组件、 sql 支持良 好、分析函数丰富,易上 手,需要时间短 | 渠道漏斗 分析、 app 点 击路径事 件分析 |

若有收获,就点个赞吧
0 人点赞
