什么是窗口函数
窗口函数也称为OLAP 函数。为了让大家快速形成直观印象,才起 了这样一个容易理解的名称(“窗口”的含义我们将在随后进行说明)。 OLAP 是 OnLine Analytical Processing 的简称,意思是对数据库数据 进行实时分析处理。例如,市场分析、创建财务报表、创建计划等日常性 商务工作。 窗口函数就是为了实现 OLAP 而添加的标准 SQL 功能.窗口函数的语法
接下来,就让我们通过示例来学习窗口函数吧。窗口函数的语法有些 复杂。 窗口函数
语法的基本使用方法——使用RANK函数
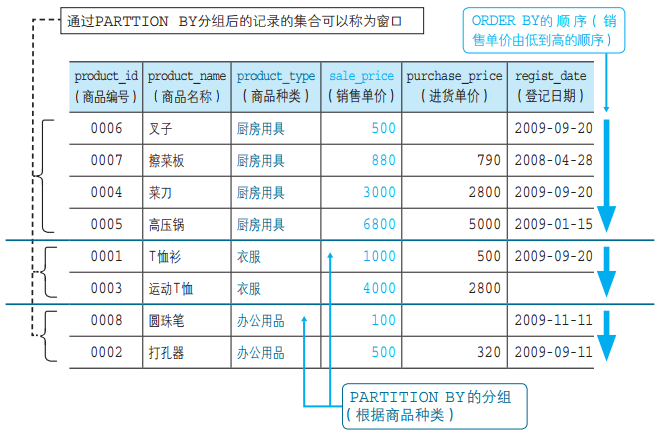
首先让我们通过专用窗口函数 RANK 来理解一下窗口函数的语法吧。 正如其名称所示,RANK 是用来计算记录排序的函数。 例如,对于之前使用过的 Product 表中的 8 件商品,让我们根据不 同的商品种类(product_type),按照销售单价(sale_price)从 低到高的顺序排序,结果如下所示。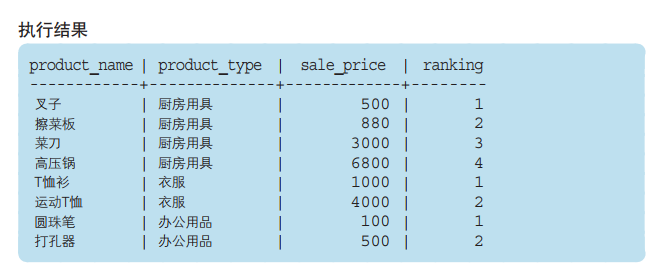


专用窗口函数的种类
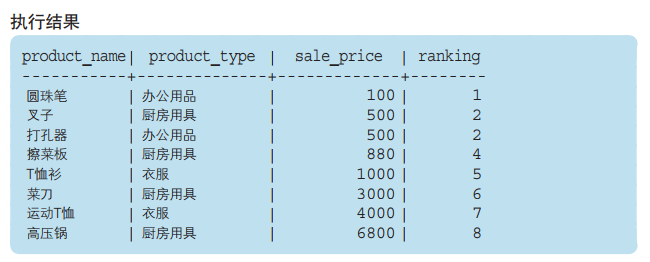
从上述结果中我们可以看到,“打孔器”和“叉子”都排在第 2 位, 而之后的“擦菜板”跳过了第 3 位,直接排到了第 4 位,这也是通常的排 序方法,但某些情况下可能并不希望跳过某个位次来进行排序。 这时可以使用 RANK 函数之外的函数来实现。下面就让我们来总结 一下具有代表性的专用窗口函数吧。 ●RANK函数 计算排序时,如果存在相同位次的记录,则会跳过之后的位次。 例)有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位…… ●DENSE_RANK函数 同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。 例)有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位…… ●ROW_NUMBER函数 赋予唯一的连续位次。 例)有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位…… 比较RANK、DENSE_RANK、ROW_NUMBER的结果
 将结果中的 ranking 列和 dense_ranking 列进行比较可以发 现,dense_ranking 列中有连续 2 个第 2 位,这和 ranking 列的情 况相同。
但是接下来的“擦菜板”的位次并不是第 4 而是第 3。这就是使 用 DENSE_RANK 函数的效果了。
此外,我们可以看到,在 rownum 列中,不管销售单价(sale price)是否相同,每件商品都会按照销售单价从低到高的顺序得到一 个连续的位次。
销售单价相同时,DBMS 会根据适当的顺序对记录进行排 列。想为记录赋予唯一的连续位次时,就可以像这样使用 ROW_NUMBER 来实现。
使用 RANK 或 ROW_NUMBER 时无需任何参数,只需要像 RANK () 或者 ROW_NUMBER() 这样保持括号中为空就可以了。
这也是专用窗口 函数通常的使用方式,请大家牢记。这一点与作为窗口函数使用的聚合函 数有很大的不同,之后我们将会详细介绍。
将结果中的 ranking 列和 dense_ranking 列进行比较可以发 现,dense_ranking 列中有连续 2 个第 2 位,这和 ranking 列的情 况相同。
但是接下来的“擦菜板”的位次并不是第 4 而是第 3。这就是使 用 DENSE_RANK 函数的效果了。
此外,我们可以看到,在 rownum 列中,不管销售单价(sale price)是否相同,每件商品都会按照销售单价从低到高的顺序得到一 个连续的位次。
销售单价相同时,DBMS 会根据适当的顺序对记录进行排 列。想为记录赋予唯一的连续位次时,就可以像这样使用 ROW_NUMBER 来实现。
使用 RANK 或 ROW_NUMBER 时无需任何参数,只需要像 RANK () 或者 ROW_NUMBER() 这样保持括号中为空就可以了。
这也是专用窗口 函数通常的使用方式,请大家牢记。这一点与作为窗口函数使用的聚合函 数有很大的不同,之后我们将会详细介绍。
窗口函数的适用范围
目前为止我们学过的函数大部分都没有使用位置的限制,最多也就是 在 WHERE 子句中使用聚合函数时会有些注意事项。 但是,使用窗口函数 的位置却有非常大的限制。更确切地说,窗口函数只能书写在一个特定的 位置。 在 DBMS 内部,窗口函数是对 WHERE 子句或者 GROUP BY 子句处理后的“结果”进行的操作。 大家仔细想一想就会明白,在得 到用户想要的结果之前,即使进行了排序处理,结果也是错误的。 在得到 排序结果之后,如果通过 WHERE 子句中的条件除去了某些记录,或者使 用 GROUP BY 子句进行了汇总处理,那好不容易得到的排序结果也无法 使用了。 正是由于这样的原因,在 SELECT 子句之外“使用窗口函数是没有 意义的”,所以在语法上才会有这样的限制。作为窗口函数使用的聚合函数
所有的聚合函数都能用作窗口函数,其语法和专用窗口函数完全相同。 但大家可能对所能得到的结果还没有一个直观的印象,所以我们还是通过 具体的示例来学习。 将SUM函数作为窗口函数使用
 使用 SUM 函数时,并不像 RANK 或者 ROW_NUMBER 那样括号中 的内容为空,而是和之前我们学过的一样,需要在括号内指定作为汇总 对象的列。
本例中我们计算出了销售单价(sale_price)的合计值 (current_sum)。
但是我们得到的并不仅仅是合计值,而是按照 ORDER BY 子句指定 的 product_id 的升序进行排列,计算出商品编号“小于等于自己”的商品 的销售单价的合计值。
因此,计算该合计值的逻辑就像金字塔堆积那样, 一行一行逐渐添加计算对象。
在按照时间序列的顺序,计算各个时间的销 售额总额等的时候,通常都会使用这种称为累计的统计方法。
使用其他聚合函数时的操作逻辑也和本例相同。
将AVG函数作为窗口函数使用
使用 SUM 函数时,并不像 RANK 或者 ROW_NUMBER 那样括号中 的内容为空,而是和之前我们学过的一样,需要在括号内指定作为汇总 对象的列。
本例中我们计算出了销售单价(sale_price)的合计值 (current_sum)。
但是我们得到的并不仅仅是合计值,而是按照 ORDER BY 子句指定 的 product_id 的升序进行排列,计算出商品编号“小于等于自己”的商品 的销售单价的合计值。
因此,计算该合计值的逻辑就像金字塔堆积那样, 一行一行逐渐添加计算对象。
在按照时间序列的顺序,计算各个时间的销 售额总额等的时候,通常都会使用这种称为累计的统计方法。
使用其他聚合函数时的操作逻辑也和本例相同。
将AVG函数作为窗口函数使用

 从结果中我们可以看到,current_avg 的计算方法确实是计算平 均值的方法,但作为统计对象的却只是“自己和排在自己之上”的记录。
像这样 以“自身记录(当前记录)”作为基准进行统计,就是将聚合函数当作窗 口函数使用时的最大特征。
从结果中我们可以看到,current_avg 的计算方法确实是计算平 均值的方法,但作为统计对象的却只是“自己和排在自己之上”的记录。
像这样 以“自身记录(当前记录)”作为基准进行统计,就是将聚合函数当作窗 口函数使用时的最大特征。
计算移动平均
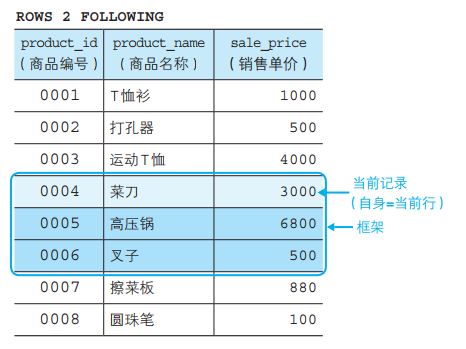
窗口函数就是将表以窗口为单位进行分割,并在其中进行排序的函数。 其实其中还包含在窗口中指定更加详细的汇总范围的备选功能,该备选功能中的汇总范围称为框架。 其语法如下列代码清单所示,需要在ORDER BY子句之后使用指定范围的关键字。 指定“最靠近的3行”作为汇总对象
 ●指定框架(汇总范围)
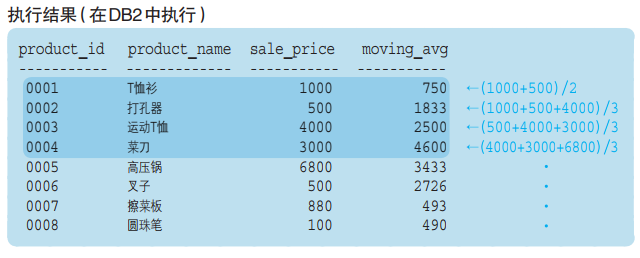
我们将上述结果与之前的结果进行比较,可以发现商品编号为“0004” 的“菜刀”以下的记录和窗口函数的计算结果并不相同。
这是因为我们指定了框架,将汇总对象限定为了“最靠近的 3 行”。
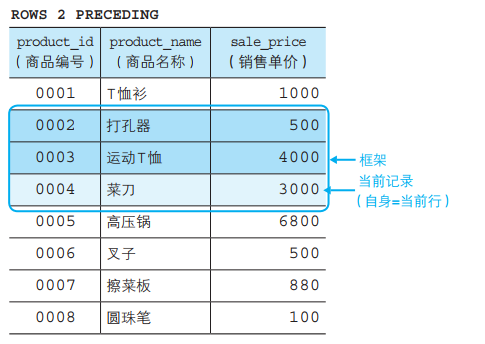
这里我们使用了 ROWS(“行”)和 PRECEDING(“之前”)两个关键字,将框架指定为“截止到之前 ~ 行”,因此“ROWS 2 PRECEDING”
就是将框架指定为“截止到之前 2 行”,也就是将作为汇总对象的记录限定为如下的“最靠近的 3 行”。
● 自身(当前记录)
● 之前 1行的记录
● 之前 2行的记录
也就是说,由于框架是根据当前记录来确定的,因此和固定的窗口不 同,其范围会随着当前记录的变化而变化。
将框架指定为截止到当前记录之前2行(最靠近的3行)
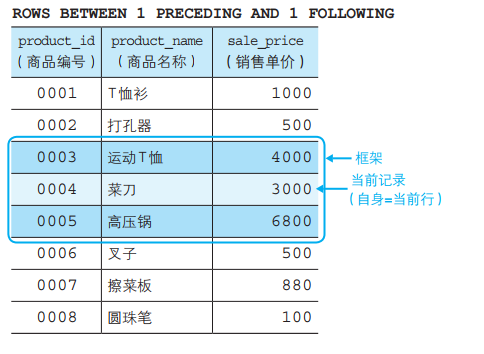
●指定框架(汇总范围)
我们将上述结果与之前的结果进行比较,可以发现商品编号为“0004” 的“菜刀”以下的记录和窗口函数的计算结果并不相同。
这是因为我们指定了框架,将汇总对象限定为了“最靠近的 3 行”。
这里我们使用了 ROWS(“行”)和 PRECEDING(“之前”)两个关键字,将框架指定为“截止到之前 ~ 行”,因此“ROWS 2 PRECEDING”
就是将框架指定为“截止到之前 2 行”,也就是将作为汇总对象的记录限定为如下的“最靠近的 3 行”。
● 自身(当前记录)
● 之前 1行的记录
● 之前 2行的记录
也就是说,由于框架是根据当前记录来确定的,因此和固定的窗口不 同,其范围会随着当前记录的变化而变化。
将框架指定为截止到当前记录之前2行(最靠近的3行)


 那么,如何才能让记录切实按照 ranking 列的升序进行排列呢?
答案非常简单。那就是在 SELECT 语句的最后,使用 ORDER BY 子句进行指定。
这样就能保证 SELECT 语句的结果中记 录的排列顺序了,除此之外也没有其他办法了。
在语句末尾使用ORDER BY子句对结果进行排序
那么,如何才能让记录切实按照 ranking 列的升序进行排列呢?
答案非常简单。那就是在 SELECT 语句的最后,使用 ORDER BY 子句进行指定。
这样就能保证 SELECT 语句的结果中记 录的排列顺序了,除此之外也没有其他办法了。
在语句末尾使用ORDER BY子句对结果进行排序

dence_rank()
排名样式:1、2、2、3 会产生重复排名,但排名不延续。 语法: dence_rank() over(partition by 分组字段 order by 排序字段 desc或asc)rank()
排名样式:1、2、2、4会产生重复排名,但排名延续。 语法: rank() over(partition by 分组字段 order by 排序字段 desc或asc)row_number()
排名样式:1、2、3、4不重复排名 语法: row_number() over(partition by 分组字段 order by 排序字段 desc或asc)
若有收获,就点个赞吧
0 人点赞
