分片集群
副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的<font style="color:#E8323C;">横向扩容</font>没有解决。
要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过 Distributed 表引擎把数据拼接起来一同使用。
Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
注意:ClickHouse 的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
集群写入流程(3 分片,2 副本共 6 个节点)
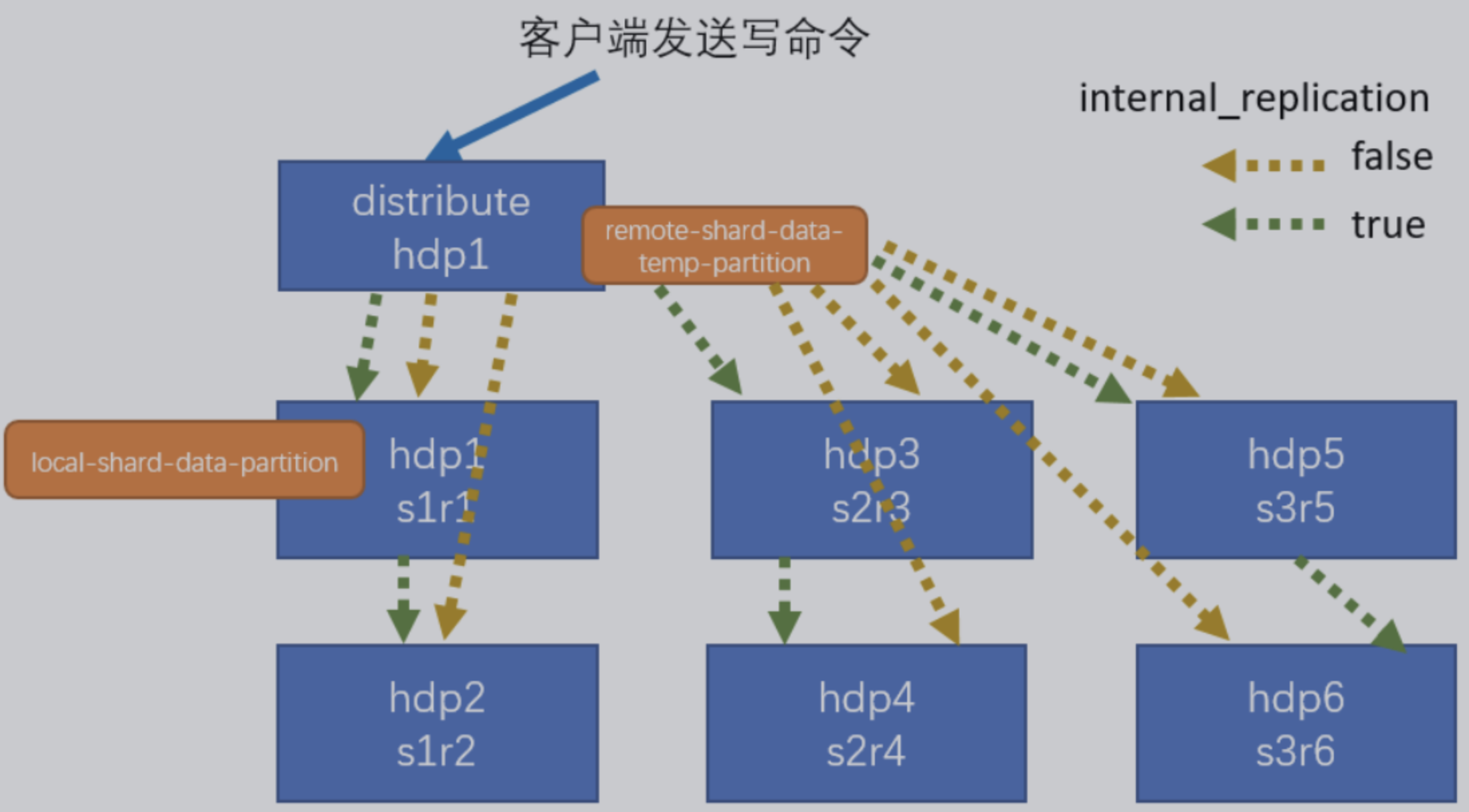
集群读取流程 (3 分片,2 副本共6 个节点)

3分片2 副本共6个节点集群配置
配置的位置还是在之前的/etc/clickhouse-server/config.d/metrika.xml,内容如下注:也可以不创建外部文件,直接在 config.xml 的<remote_servers>中指定
配置三节点版本集群及副本
集群及副本规划(2 个分片,只有第一个分片有副本)


若有收获,就点个赞吧
0 人点赞
