迭代器模式,它用来遍历集合对象。不过,很多编程语言都将迭代器作为一个基础的类库,直接提供出来了。在平时开发中,特别是业务开发,我们直接使用即可,很少会自己去实现一个迭代器。不过,知其然知其所以然,弄懂原理能帮助我们更好的使用这些工具类,所以,我觉得还是有必要学习一下这个模式。
我们知道,大部分编程语言都提供了多种遍历集合的方式,比如 for 循环、foreach 循环、迭代器等。所以,今天我们除了讲解迭代器的原理和实现之外,还会重点讲一下,相对于其他遍历方式,利用迭代器来遍历集合的优势。
1、什么是迭代器模式?
迭代器模式(Iterator Design Pattern),也叫作游标模式(Cursor Design Pattern)。在开篇中我们讲到,它用来遍历集合对象。这里说的“集合对象”也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如数组、链表、树、图、跳表。迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一。
迭代器是用来遍历容器的,所以,一个完整的迭代器模式一般会涉及容器和容器迭代器两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。对于迭代器模式,我画了一张简单的类图,你可以看一看,先有个大致的印象。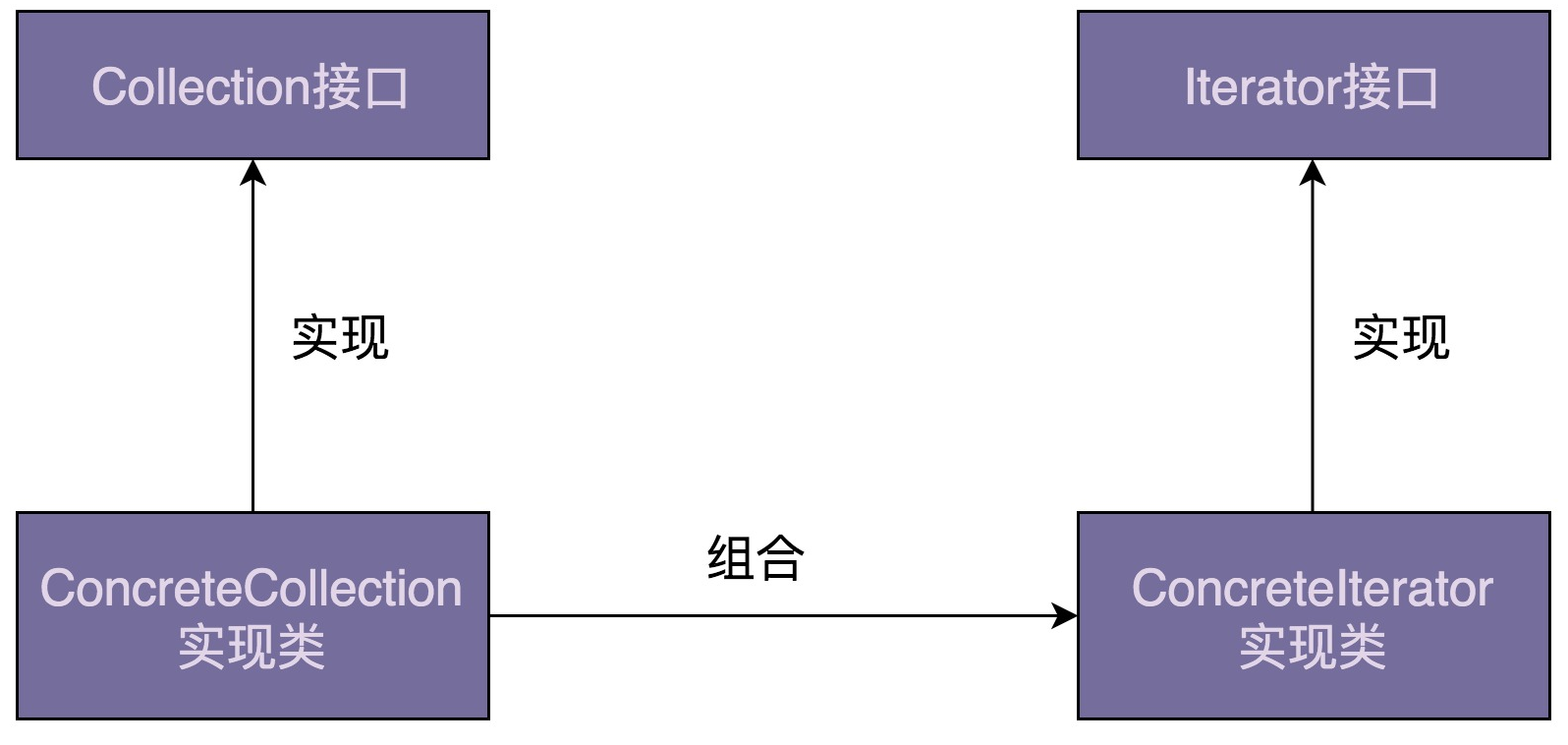
2、为什么要使用迭代器模式?
迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一。
首先,对于类似数组和链表这样的数据结构,遍历方式比较简单,直接使用 for 循环来遍历就足够了。但是,对于复杂的数据结构(比如树、图)来说,有各种复杂的遍历方式。比如,树有前中后序、按层遍历,图有深度优先、广度优先遍历等等。如果由客户端代码来实现这些遍历算法,势必增加开发成本,而且容易写错。如果将这部分遍历的逻辑写到容器类中,也会导致容器类代码的复杂性。
前面也多次提到,应对复杂性的方法就是拆分。我们可以将遍历操作拆分到迭代器类中。比如,针对图的遍历,我们就可以定义 DFSIterator、BFSIterator 两个迭代器类,让它们分别来实现深度优先遍历和广度优先遍历。
其次,将游标指向的当前位置等信息,存储在迭代器类中,每个迭代器独享游标信息。这样,我们就可以创建多个不同的迭代器,同时对同一个容器进行遍历而互不影响。
最后,容器和迭代器都提供了抽象的接口,方便我们在开发的时候,基于接口而非具体的实现编程。当需要切换新的遍历算法的时候,比如,从前往后遍历链表切换成从后往前遍历链表,客户端代码只需要将迭代器类从 LinkedIterator 切换为 ReversedLinkedIterator 即可,其他代码都不需要修改。除此之外,添加新的遍历算法,我们只需要扩展新的迭代器类,也更符合开闭原则。
3、例子
3.1、GoF(简单)
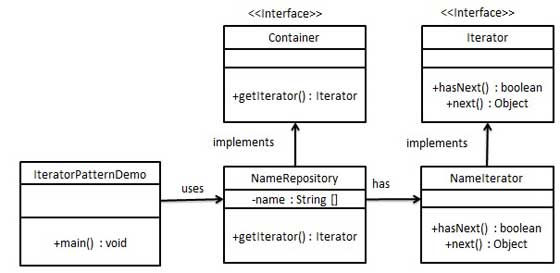
我们将创建一个叙述导航方法的 Iterator 接口和一个返回迭代器的 Container 接口。实现了 Container 接口的实体类将负责实现 Iterator 接口。
IteratorPatternDemo,我们的演示类使用实体类 NamesRepository 来打印 NamesRepository 中存储为集合的 Names。
public class Main {public static void main(String[] args) {NameRepository names = new NameRepository();Iterator iterator = names.getIterator();while (iterator.hasNext()) {String name = (String) iterator.next();System.out.println("Name : " + name);}}}/*** Iterator迭代器抽象类*/interface Iterator {public boolean hasNext();public Object next();}/*** Container 容器抽象类*/interface Container {public Iterator getIterator();}/*** 实现了 Container 接口的实体类。该类有实现了 Iterator 接口的内部类 NameIterator。*/class NameRepository implements Container {public String[] names = {"Robert", "John", "Julie", "Lora"};@Overridepublic Iterator getIterator() {return new NameIterator();}private class NameIterator implements Iterator {int index;@Overridepublic boolean hasNext() {if (index < names.length) {return true;}return false;}@Overridepublic Object next() {if (this.hasNext()) {return names[index++];}return null;}}}
4、总结
4.1、优缺点
1)优点
一般来讲,遍历集合数据有三种方法:for 循环、foreach 循环、iterator 迭代器。对于这三种方式,我拿 Java 语言来举例说明一下。具体的代码如下所示:
List<String> names = new ArrayList<>();names.add("xzg");names.add("wang");names.add("zheng");// 第一种遍历方式:for循环for (int i = 0; i < names.size(); i++) {System.out.print(names.get(i) + ",");}// 第二种遍历方式:foreach循环for (String name : names) {System.out.print(name + ",")}// 第三种遍历方式:迭代器遍历Iterator<String> iterator = names.iterator();while (iterator.hasNext()) {System.out.print(iterator.next() + ",");//Java中的迭代器接口是第二种定义方式,next()既移动游标又返回数据}
实际上,foreach 循环只是一个语法糖而已,底层是基于迭代器来实现的。也就是说,上面代码中的第二种遍历方式(foreach 循环代码)的底层实现,就是第三种遍历方式(迭代器遍历代码)。这两种遍历方式可以看作同一种遍历方式,也就是迭代器遍历方式。
从上面的代码来看,for 循环遍历方式比起迭代器遍历方式,代码看起来更加简洁。那我们为什么还要用迭代器来遍历容器呢?为什么还要给容器设计对应的迭代器呢?原因有以下三个。
首先,对于类似数组和链表这样的数据结构,遍历方式比较简单,直接使用 for 循环来遍历就足够了。但是,对于复杂的数据结构(比如树、图)来说,有各种复杂的遍历方式。比如,树有前中后序、按层遍历,图有深度优先、广度优先遍历等等。如果由客户端代码来实现这些遍历算法,势必增加开发成本,而且容易写错。如果将这部分遍历的逻辑写到容器类中,也会导致容器类代码的复杂性。
前面也多次提到,应对复杂性的方法就是拆分。我们可以将遍历操作拆分到迭代器类中。比如,针对图的遍历,我们就可以定义 DFSIterator、BFSIterator 两个迭代器类,让它们分别来实现深度优先遍历和广度优先遍历。
其次,将游标指向的当前位置等信息,存储在迭代器类中,每个迭代器独享游标信息。这样,我们就可以创建多个不同的迭代器,同时对同一个容器进行遍历而互不影响。
最后,容器和迭代器都提供了抽象的接口,方便我们在开发的时候,基于接口而非具体的实现编程。当需要切换新的遍历算法的时候,比如,从前往后遍历链表切换成从后往前遍历链表,客户端代码只需要将迭代器类从 LinkedIterator 切换为 ReversedLinkedIterator 即可,其他代码都不需要修改。除此之外,添加新的遍历算法,我们只需要扩展新的迭代器类,也更符合开闭原则。
2)缺点
4.2、问题
1)在遍历的同时增删集合元素会发生什么?
2)如何应对遍历时改变集合导致的未决行为?
3)如何在遍历的同时安全地删除集合元素?
4)如何设计实现一个支持“快照”功能的iterator?
方案1:
我们先来看最简单的一种解决办法。在迭代器类中定义一个成员变量 snapshot 来存储快照。每当创建迭代器的时候,都拷贝一份容器中的元素到快照中,后续的遍历操作都基于这个迭代器自己持有的快照来进行。具体的代码实现如下所示:
方案2:
我们可以在容器中,为每个元素保存两个时间戳,一个是添加时间戳 addTimestamp,一个是删除时间戳 delTimestamp。当元素被加入到集合中的时候,我们将 addTimestamp 设置为当前时间,将 delTimestamp 设置成最大长整型值(Long.MAX_VALUE)。当元素被删除时,我们将 delTimestamp 更新为当前时间,表示已经被删除。
注意,这里只是标记删除,而非真正将它从容器中删除。
同时,每个迭代器也保存一个迭代器创建时间戳 snapshotTimestamp,也就是迭代器对应的快照的创建时间戳。当使用迭代器来遍历容器的时候,只有满足 addTimestamp<snapshotTimestamp<delTimestamp 的元素,才是属于这个迭代器的快照。
如果元素的 addTimestamp>snapshotTimestamp,说明元素在创建了迭代器之后才加入的,不属于这个迭代器的快照;如果元素的 delTimestamp<snapshotTimestamp,说明元素在创建迭代器之前就被删除掉了,也不属于这个迭代器的快照。
这样就在不拷贝容器的情况下,在容器本身上借助时间戳实现了快照功能。具体的代码实现如下所示。注意,我们没有考虑 ArrayList 的扩容问题,感兴趣的话,你可以自己完善一下。
实际上,上面的解决方案相当于解决了一个问题,又引入了另外一个问题。ArrayList 底层依赖数组这种数据结构,原本可以支持快速的随机访问,在 O(1) 时间复杂度内获取下标为 i 的元素,但现在,删除数据并非真正的删除,只是通过时间戳来标记删除,这就导致无法支持按照下标快速随机访问了。如果你对数组随机访问这块知识点不了解,可以去看《数据结构与算法之美》专栏,这里我就不展开讲解了。
现在,我们来看怎么解决这个问题:让容器既支持快照遍历,又支持随机访问?
解决的方法也不难,我稍微提示一下。我们可以在 ArrayList 中存储两个数组。一个支持标记删除的,用来实现快照遍历功能;一个不支持标记删除的(也就是将要删除的数据直接从数组中移除),用来支持随机访问。对应的代码我这里就不给出了,感兴趣的话你可以自己实现一下。

若有收获,就点个赞吧
0 人点赞
