前面我们讲到,大部分设计模式的原理和实现都很简单,不过也有例外,比如今天要讲的访问者模式。它可以算是 23 种经典设计模式中最难理解的几个之一。因为它难理解、难实现,应用它会导致代码的可读性、可维护性变差,所以,访问者模式在实际的软件开发中很少被用到,在没有特别必要的情况下,建议你不要使用访问者模式。
1、什么是访问者模式
访问者者模式的英文翻译是 Visitor Design Pattern。在 GoF 的《设计模式》一书中,它是这么定义的:
Allows for one or more operation to be applied to a set of objects at runtime, decoupling the operations from the object structure.
翻译成中文就是:允许一个或者多个操作应用到一组对象上,解耦操作和对象本身。
访问者模式( Visitor ),表示一个作用于某对象结构中的各元素的操作,它使你可以在不改变各元素的前提下定义作用于这些元素的新操作。
GoF四人中的一个作者就说过:‘大多时候你并不需要访问者模式,但当一旦你需要访问者模式时,那就是真的需要它了。’事实上,我们很难找到数据结构不变化的情况,所以用访问者模式的机会也就不太多了。
2、为什么要使用访问者模式
访问者模式的目的是要把处理从数据结构分离出来 。很多系统可以按照算法和数据结构分开,如果这样的系统有比较稳定的数据结构,又有易于变化的算法的话,使用访问者模式就是比较合适的,因为访问者模式使得算法操作的增加变得容易。 反之,如果这样的系统的数据结构对象易于变化,经常要有新的数据对象增加进来,就不适合使用访问者模式。
一般来说,访问者模式针对的是一组类型不同的对象(PdfFile、PPTFile、WordFile)。不过,尽管这组对象的类型是不同的,但是,它们继承相同的父类(ResourceFile)或者实现相同的接口。在不同的应用场景下,我们需要对这组对象进行一系列不相关的业务操作(抽取文本、压缩等),但为了避免不断添加功能导致类(PdfFile、PPTFile、WordFile)不断膨胀,职责越来越不单一,以及避免频繁地添加功能导致的频繁代码修改,我们使用访问者模式,将对象与操作解耦,将这些业务操作抽离出来,定义在独立细分的访问者类(Extractor、Compressor)中。
3、例子
3.1、GoF(简单)

import java.util.ArrayList;import java.util.List;public class Main {public static void main(String[] args) {ObjectStructure o = new ObjectStructure();o.Attach(new ConcreteElementA());o.Attach(new ConcreteElementB());ConcreteVisitor1 v1 = new ConcreteVisitor1();ConcreteVisitor2 v2 = new ConcreteVisitor2();o.Accept(v1);o.Accept(v2);}}/*** Visitor类,为该对象结构中ConcreteElement的每一个类声明一个Visit操作。*/abstract class Visitor {public abstract void VisitConcreteElementA(ConcreteElementA concreteElementA);public abstract void VisitConcreteElementB(ConcreteElementB concreteElementB);}/*** ConcreteVisitor1 和 ConcreteVisitor2 类,具体访问者,实现每个由* Visitor 声明的操作。每个操作实现算法的一部分,而该算法片断乃是对* 应于结构中对象的类。*/class ConcreteVisitor1 extends Visitor {@Overridepublic void VisitConcreteElementA(ConcreteElementA concreteElementA) {}@Overridepublic void VisitConcreteElementB(ConcreteElementB concreteElementB) {}}class ConcreteVisitor2 extends Visitor {@Overridepublic void VisitConcreteElementA(ConcreteElementA concreteElementA) {}@Overridepublic void VisitConcreteElementB(ConcreteElementB concreteElementB) {}}/*** Element 抽象类,定义一个Accept操作,它以一个访问者为参数。*/abstract class Element {public abstract void accept(Visitor visitor);}/*** ConcreteElementA和ConcreteElementB类,具体元素,实现Accept操作。*/class ConcreteElementA extends Element {// 充分利用双派发技术,实现处理与数据结构的分离@Overridepublic void accept(Visitor visitor) {visitor.VisitConcreteElementA(this);}// 其他方法public void operationA() {System.out.println("operationA");}}class ConcreteElementB extends Element {// 充分利用双派发技术,实现处理与数据结构的分离@Overridepublic void accept(Visitor visitor) {visitor.VisitConcreteElementB(this);}// 其他方法public void operationB() {System.out.println("operationB");}}/*** ObjectStructure类,能枚举它的元素,可以提供一个高层的接口以允许访问者访问它的元素。*/class ObjectStructure {private List<Element> elements = new ArrayList<>();public void Attach(Element element) {elements.add(element);}public void Detach(Element element) {elements.remove(element);}public void Accept(Visitor visitor) {for (Element e : elements) {e.accept(visitor);}}}
3.2、资源文件处理(困难)
假设我们从网站上爬取了很多资源文件,它们的格式有三种:PDF、PPT、Word。我们现在要开发一个工具来处理这批资源文件。这个工具的其中一个功能是,把这些资源文件中的文本内容抽取出来放到 txt 文件中。如果让你来实现,你会怎么来做呢?
实现这个功能并不难,不同的人有不同的写法,我将其中一种代码实现方式贴在这里。其中,ResourceFile 是一个抽象类,包含一个抽象函数 extract2txt()。PdfFile、PPTFile、WordFile 都继承 ResourceFile 类,并且重写了 extract2txt() 函数。在 ToolApplication 中,我们可以利用多态特性,根据对象的实际类型,来决定执行哪个方法。
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<ResourceFile> resourceFiles = listAllResourceFiles("/xxx");
for (ResourceFile resourceFile : resourceFiles) {
resourceFile.extract2txt();
}
}
/**
* 获取目录下的所有文件
*/
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
/**
* 抽象资源文件类
*/
abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
public abstract void extract2txt();
}
class PPTFile extends ResourceFile {
public PPTFile(String filePath) {
super(filePath);
}
@Override
public void extract2txt() {
//...省略一大坨从PPT中抽取文本的代码...
//...将抽取出来的文本保存在跟filePath同名的.txt文件中...
System.out.println("Extract PPT.");
}
}
class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
@Override
public void extract2txt() {
//...
System.out.println("Extract PDF.");
}
}
class WordFile extends ResourceFile {
public WordFile(String filePath) {
super(filePath);
}
@Override
public void extract2txt() {
//...
System.out.println("Extract WORD.");
}
}
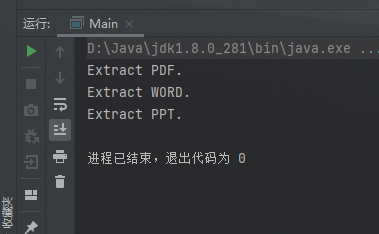
如果工具的功能不停地扩展,不仅要能抽取文本内容,还要支持压缩、提取文件元信息(文件名、大小、更新时间等等)构建索引等一系列的功能,那如果我们继续按照上面的实现思路,就会存在这样几个问题:
- 违背开闭原则,添加一个新的功能,所有类的代码都要修改;
- 虽然功能增多,每个类的代码都不断膨胀,可读性和可维护性都变差了;
- 把所有比较上层的业务逻辑都耦合到 PdfFile、PPTFile、WordFile 类中,导致这些类的职责不够单一,变成了大杂烩。
针对上面的问题,我们常用的解决方法就是拆分解耦,把业务操作跟具体的数据结构解耦,设计成独立的类。这里我们按照访问者模式的演进思路来对上面的代码进行重构。重构之后的代码如下所示。
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
for (ResourceFile resourceFile : resourceFiles) {
extractor.extract2txt(resourceFile);
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
/**
* 资源文件抽象类
*/
abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
}
/**
* 具体资源文件
*/
class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
//...
}
class PPTFile extends ResourceFile {
public PPTFile(String filePath) {
super(filePath);
}
//...
}
class WordFile extends ResourceFile {
public WordFile(String filePath) {
super(filePath);
}
//...
}
/**
* 导出者
*/
class Extractor {
public void extract2txt(PPTFile pptFile) {
//...
System.out.println("Extract PPT.");
}
public void extract2txt(PdfFile pdfFile) {
//...
System.out.println("Extract PDF.");
}
public void extract2txt(WordFile wordFile) {
//...
System.out.println("Extract WORD.");
}
}
这其中最关键的一点设计是,我们把抽取文本内容的操作,设计成了三个重载函数。函数重载是 Java、C++ 这类面向对象编程语言中常见的语法机制。所谓重载函数是指,在同一类中函数名相同、参数不同的一组函数。
不过,如果你足够细心,就会发现,上面的代码是编译通过不了的,第 9 行会报错。这是为什么呢?
我们知道,多态是一种动态绑定,可以在运行时获取对象的实际类型,来运行实际类型对应的方法。而函数重载是一种静态绑定,在编译时并不能获取对象的实际类型,而是根据声明类型执行声明类型对应的方法。
在上面代码的第 7~10 行中,resourceFiles 包含的对象的声明类型都是 ResourceFile,而我们并没有在 Extractor 类中定义参数类型是 ResourceFile 的 extract2txt() 重载函数,所以在编译阶段就通过不了,更别说在运行时根据对象的实际类型执行不同的重载函数了。那如何解决这个问题呢?
解决的办法稍微有点难理解,我们先来看代码,然后我再来给你慢慢解释。
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles("/xxx");
for (ResourceFile resourceFile : resourceFiles) {
resourceFile.accept(extractor);
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
/**
* 抽象资源类
*/
abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
abstract public void accept(Extractor extractor);
}
/**
* 具体资源类
*/
class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
@Override
public void accept(Extractor extractor) {
extractor.extract2txt(this);
}
//...
}
class PPTFile extends ResourceFile {
public PPTFile(String filePath) {
super(filePath);
}
@Override
public void accept(Extractor extractor) {
extractor.extract2txt(this);
}
//...
}
class WordFile extends ResourceFile {
public WordFile(String filePath) {
super(filePath);
}
@Override
public void accept(Extractor extractor) {
extractor.extract2txt(this);
}
//...
}
/**
* 导出者
*/
class Extractor {
public void extract2txt(PPTFile pptFile) {
//...
System.out.println("Extract PPT.");
}
public void extract2txt(PdfFile pdfFile) {
//...
System.out.println("Extract PDF.");
}
public void extract2txt(WordFile wordFile) {
//...
System.out.println("Extract WORD.");
}
}

在执行第 9 行的时候,根据多态特性,程序会调用实际类型的 accept 函数,比如 PdfFile 的 accept 函数,也就是第 48 行代码。而 48 行代码中的 this 类型是 PdfFile 的,在编译的时候就确定了,所以会调用 extractor 的 extract2txt(PdfFile pdfFile) 这个重载函数。这个实现思路是不是很有技巧?这是理解访问者模式的关键所在,也是我之前所说的访问者模式不好理解的原因。
现在,如果要继续添加新的功能,比如前面提到的压缩功能,根据不同的文件类型,使用不同的压缩算法来压缩资源文件,那我们该如何实现呢?我们需要实现一个类似 Extractor 类的新类 Compressor 类,在其中定义三个重载函数,实现对不同类型资源文件的压缩。除此之外,我们还要在每个资源文件类中定义新的 accept 重载函数。具体的代码如下所示:
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles("/xxx");
for (ResourceFile resourceFile : resourceFiles) {
resourceFile.accept(extractor);
}
Compressor compressor = new Compressor();
for (ResourceFile resourceFile : resourceFiles) {
resourceFile.accept(compressor);
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
/**
* 抽象资源文件
*/
abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
abstract public void accept(Visitor vistor);
}
/**
* 具体资源文件
*/
class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
//...
}
class PPTFile extends ResourceFile {
public PPTFile(String filePath) {
super(filePath);
}
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
//...
}
class WordFile extends ResourceFile {
public WordFile(String filePath) {
super(filePath);
}
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
//...
}
/**
* 访问者
*/
interface Visitor {
void visit(PdfFile pdfFile);
void visit(PPTFile pdfFile);
void visit(WordFile pdfFile);
}
/**
* 具体访问者
*/
class Extractor implements Visitor {
@Override
public void visit(PPTFile pptFile) {
//...
System.out.println("Extract PPT.");
}
@Override
public void visit(PdfFile pdfFile) {
//...
System.out.println("Extract PDF.");
}
@Override
public void visit(WordFile wordFile) {
//...
System.out.println("Extract WORD.");
}
}
class Compressor implements Visitor {
@Override
public void visit(PPTFile pptFile) {
//...
System.out.println("Compress PPT.");
}
@Override
public void visit(PdfFile pdfFile) {
//...
System.out.println("Compress PDF.");
}
@Override
public void visit(WordFile wordFile) {
//...
System.out.println("Compress WORD.");
}
}
实际上,在上面例子中,经过层层重构之后的最终代码,就是标准的访问者模式的实现代码。这里,我又总结了一张类图,贴在了下面,你可以对照着前面的例子代码一块儿来看一下。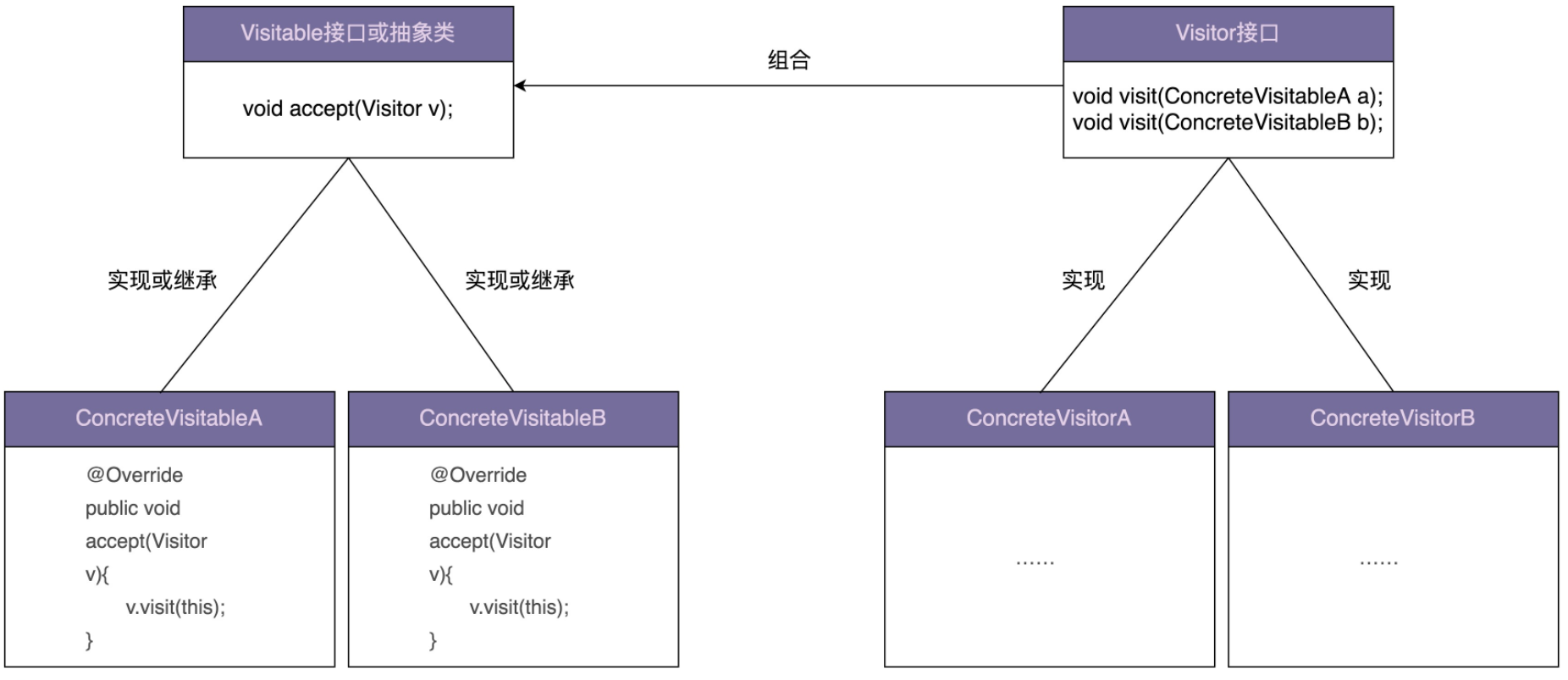
最后,我们再来看下,访问者模式的应用场景。
一般来说,访问者模式针对的是一组类型不同的对象(PdfFile、PPTFile、WordFile)。不过,尽管这组对象的类型是不同的,但是,它们继承相同的父类(ResourceFile)或者实现相同的接口。在不同的应用场景下,我们需要对这组对象进行一系列不相关的业务操作(抽取文本、压缩等),但为了避免不断添加功能导致类(PdfFile、PPTFile、WordFile)不断膨胀,职责越来越不单一,以及避免频繁地添加功能导致的频繁代码修改,我们使用访问者模式,将对象与操作解耦,将这些业务操作抽离出来,定义在独立细分的访问者类(Extractor、Compressor)中。
4、总结
访问者模式允许一个或者多个操作应用到一组对象上,设计意图是解耦操作和对象本身,保持类职责单一、满足开闭原则以及应对代码的复杂性。
对于访问者模式,学习的主要难点在代码实现。而代码实现比较复杂的主要原因是,函数重载在大部分面向对象编程语言中是静态绑定的。也就是说,调用类的哪个重载函数,是在编译期间,由参数的声明类型决定的,而非运行时,根据参数的实际类型决定的。
正是因为代码实现难理解,所以,在项目中应用这种模式,会导致代码的可读性比较差。如果你的同事不了解这种设计模式,可能就会读不懂、维护不了你写的代码。所以,除非不得已,不要使用这种模式。
4.1、优缺点
4.2、问题
1)为什么支持双分派的语言不需要访问者模式呢?
实际上,讲到访问者模式,大部分书籍或者资料都会讲到 Double Dispatch,中文翻译为双分派。虽然学习访问者模式,并不用非得理解这个概念,我们前面的讲解就没有提到它,但是,为了让你在查看其它书籍或者资料的时候,不会卡在这个概念上,我觉得有必要在这里讲一下。
除此之外,我觉得,学习 Double Dispatch 还能加深你对访问者模式的理解,而且能一并帮你搞清楚今天文章标题中的这个问题:为什么支持双分派的语言就不需要访问者模式?这个问题在面试中可是会被问到的哦!
既然有 Double Dispatch,对应的就有 Single Dispatch。所谓 Single Dispatch,指的是执行哪个对象的方法,根据对象的运行时类型来决定;执行对象的哪个方法,根据方法参数的编译时类型来决定。所谓 Double Dispatch,指的是执行哪个对象的方法,根据对象的运行时类型来决定;执行对象的哪个方法,根据方法参数的运行时类型来决定。
如何理解“Dispatch”这个单词呢? 在面向对象编程语言中,我们可以把方法调用理解为一种消息传递,也就是“Dispatch”。一个对象调用另一个对象的方法,就相当于给它发送一条消息。这条消息起码要包含对象名、方法名、方法参数。
如何理解“Single”“Double”这两个单词呢?“Single”“Double”指的是执行哪个对象的哪个方法,跟几个因素的运行时类型有关。我们进一步解释一下。Single Dispatch 之所以称为“Single”,是因为执行哪个对象的哪个方法,只跟“对象”的运行时类型有关。Double Dispatch 之所以称为“Double”,是因为执行哪个对象的哪个方法,跟“对象”和“方法参数”两者的运行时类型有关。
具体到编程语言的语法机制,Single Dispatch 和 Double Dispatch 跟多态和函数重载直接相关。当前主流的面向对象编程语言(比如,Java、C++、C#)都只支持 Single Dispatch,不支持 Double Dispatch。
接下来,我们拿 Java 语言来举例说明一下。
Java 支持多态特性,代码可以在运行时获得对象的实际类型(也就是前面提到的运行时类型),然后根据实际类型决定调用哪个方法。尽管 Java 支持函数重载,但 Java 设计的函数重载的语法规则是,并不是在运行时,根据传递进函数的参数的实际类型,来决定调用哪个重载函数,而是在编译时,根据传递进函数的参数的声明类型(也就是前面提到的编译时类型),来决定调用哪个重载函数。也就是说,具体执行哪个对象的哪个方法,只跟对象的运行时类型有关,跟参数的运行时类型无关。所以,Java 语言只支持 Single Dispatch。
这么说比较抽象,我举个例子来具体说明一下,代码如下所示:
public class ParentClass {
public void f() {
System.out.println("I am ParentClass's f().");
}
}
public class ChildClass extends ParentClass {
public void f() {
System.out.println("I am ChildClass's f().");
}
}
public class SingleDispatchClass {
public void polymorphismFunction(ParentClass p) {
p.f();
}
public void overloadFunction(ParentClass p) {
System.out.println("I am overloadFunction(ParentClass p).");
}
public void overloadFunction(ChildClass c) {
System.out.println("I am overloadFunction(ChildClass c).");
}
}
public class DemoMain {
public static void main(String[] args) {
SingleDispatchClass demo = new SingleDispatchClass();
ParentClass p = new ChildClass();
demo.polymorphismFunction(p);//执行哪个对象的方法,由对象的实际类型决定
demo.overloadFunction(p);//执行对象的哪个方法,由参数对象的声明类型决定
}
}
//代码执行结果:
I am ChildClass's f().
I am overloadFunction(ParentClass p)
在上面的代码中,第 31 行代码的 polymorphismFunction() 函数,执行 p 的实际类型的 f() 函数,也就是 ChildClass 的 f() 函数。第 32 行代码的 overloadFunction() 函数,匹配的是重载函数中的 overloadFunction(ParentClass p),也就是根据 p 的声明类型来决定匹配哪个重载函数。
假设 Java 语言支持 Double Dispatch,那下面的代码(摘抄自上节课中第二段代码,建议结合上节课的讲解一块理解)中的第 37 行就不会报错。代码会在运行时,根据参数(resourceFile)的实际类型(PdfFile、PPTFile、WordFile),来决定使用 extract2txt 的三个重载函数中的哪一个。那下面的代码实现就能正常运行了,也就不需要访问者模式了。这也回答了为什么支持 Double Dispatch 的语言不需要访问者模式。
public abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
}
public class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
//...
}
//...PPTFile、WordFile代码省略...
public class Extractor {
public void extract2txt(PPTFile pptFile) {
//...
System.out.println("Extract PPT.");
}
public void extract2txt(PdfFile pdfFile) {
//...
System.out.println("Extract PDF.");
}
public void extract2txt(WordFile wordFile) {
//...
System.out.println("Extract WORD.");
}
}
public class ToolApplication {
public static void main(String[] args) {
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
for (ResourceFile resourceFile : resourceFiles) {
extractor.extract2txt(resourceFile);
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}

若有收获,就点个赞吧
0 人点赞
