第 4 部分 Impala的使用
Impala的核心开发语言是sql语句,Impala有shell命令行窗口,以及JDBC等方式来接收sql语句执行,对于复杂类型分析可以使用C++或者Java来编写UDF函数。
Impala的sql语法是高度集成了Apache Hive的sql语法,Impala支持Hive支持的数据类型以及部分Hive的内置函数。
需要注意的几点:
- Impala与Hive类似它们的重点都是在与查询,所以像Update,delete等具有更新性质的操作最好不要使用这种工具,对于删除数据的操作可以通过Drop Table,Alter Table Drop Partition来实现,更新可以尝试使用Insert overwrite方式
- 通常使用Impala的方式是数据文件存储在Hdfs文件系统,借助于Impala的表定义来查询和管理Hdfs上的数据文件;
- Impala的使用大多数与Hive相同,比如Impala同样支持内外部表,以及分区等,可以借鉴参考Hive的使用。
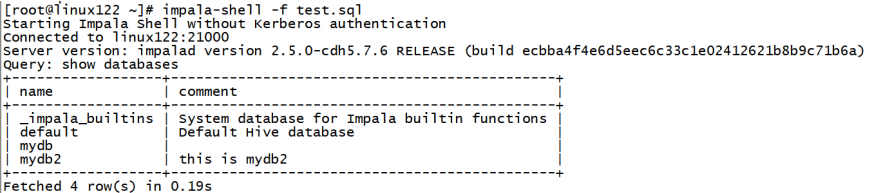
第 1 节 Impala-shell命令参数
1.1 impala-shell外部命令
所谓的外部命令指的是不需要进入到impala-shell交互命令行当中即可执行的命令参数。impala-shell后面执行的时候可以带很多参数。你可以在启动 impala-shell 时设置,用于修改命令执行环境。
impala-shell –h可以帮助我们查看帮助手册。也可以参考课程附件资料。
比如几个常见的:
- impala-shell –r刷新impala元数据,与建立连接后执行 REFRESH 语句效果相同(元数据发生变化的时候)
- impala-shell –f 文件路径 执行指的的sql查询文件。
- impala-shell –i指定连接运行 impalad 守护进程的主机。默认端口是 21000。你可以连接到集群中运行
- impalad 的任意主机。
- impala-shell –o保存执行结果到文件当中去。
展示Impala默认支持的内置函数需要进入Impala默认系统数据库中执行
show functions;
1.2 impala-shell内部命令
所谓内部命令是指,进入impala-shell命令行之后可以执行的语法。
connect hostname 连接到指定的机器impalad上去执行。
refresh dbname.tablename增量刷新,刷新某一张表的元数据,主要用于刷新hive当中数据表里面的数据改变的情况。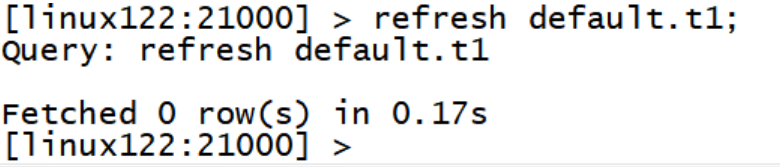
invalidate metadata全量刷新,性能消耗较大,主要用于hive当中新建数据库或者数据库表的时候来进行刷新。
quit/exit命令 从Impala shell中退出
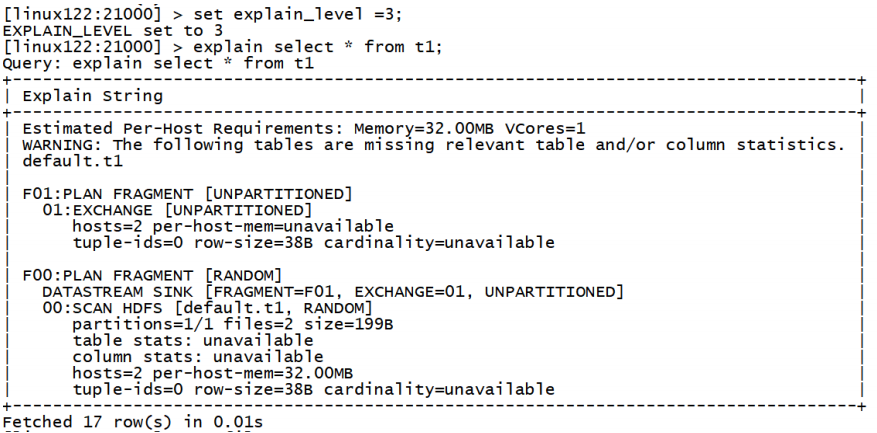
explain 命令 用于查看sql语句的执行计划。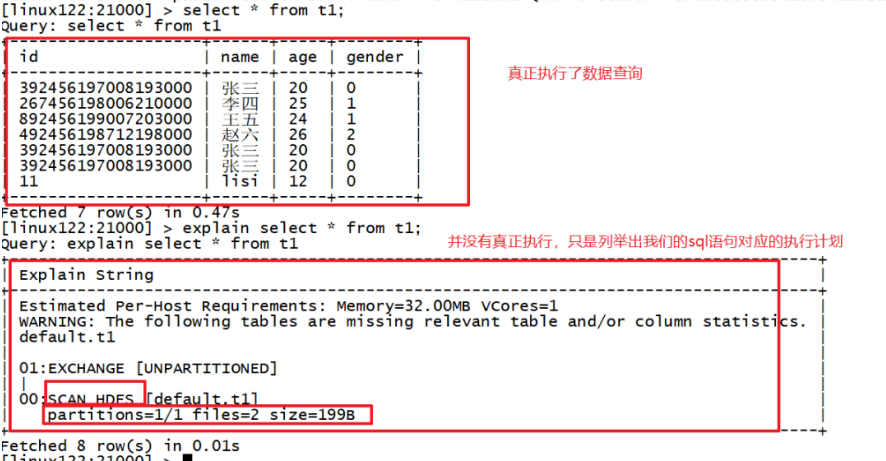
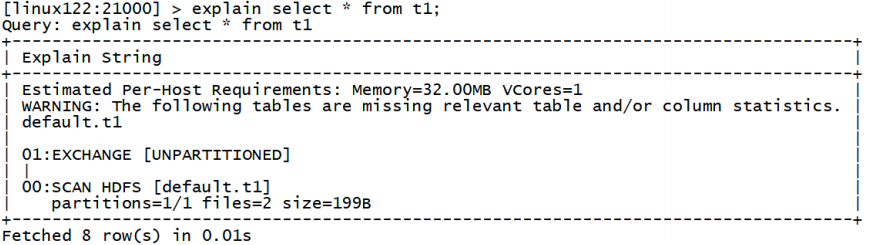
explain的值可以设置成0,1,2,3等几个值,其中3级别是最高的,可以打印出最全的信息
set explain_level=3;
profile命令执行sql语句之后执行,可以
打印出更加详细的执行步骤,主要用于查询结果的查看,集群的调优等。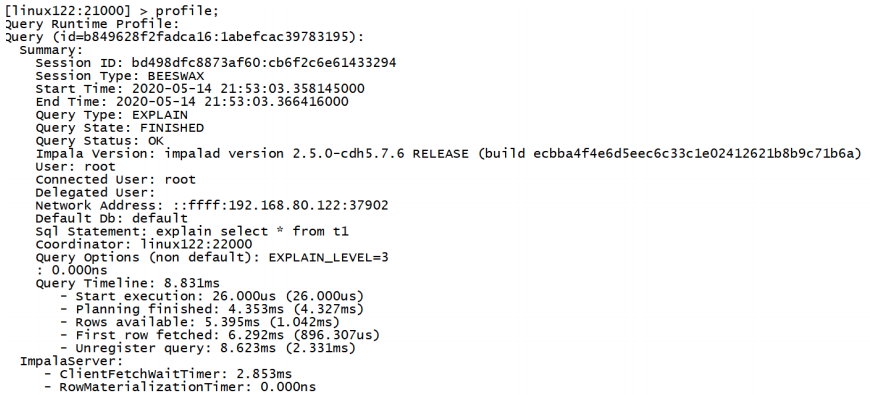
expalin:可以不真正执行任务,只是展示任务的执行计划;
profile:需要任务执行完成后调用,可以从更底层以及更详细的层面来观察我们运行impala的任务,进
行调优。
第 2 节 Impala sql语法
2.1 数据库特定语句
- 创建数据库
**
CREATE DATABASE语句用于在Impala中创建新数据库。
CREATE DATABASE IF NOT EXISTS database_name;
这里,IF NOT EXISTS是一个可选的子句。如果我们使用此子句,则只有在没有具有相同名称的现有数据库时,才会创建具有给定名称的数据库。
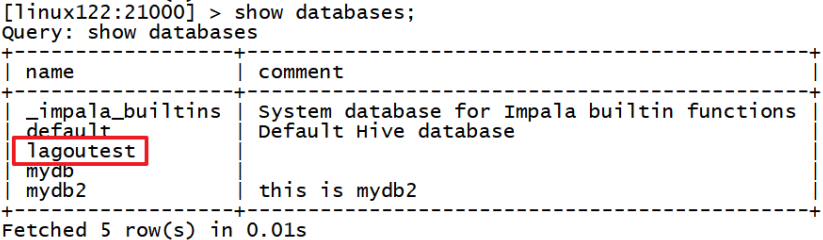
默认就会在hive的数仓路径下创建新的数据库名文件夹
/user/hive/warehouse/lagoutest.db
- **删除数据库**
Impala的DROP DATABASE语句用于从Impala中删除数据库。 在删除数据库之前,建议从中删除所有表。
如果使用级联删除,Impala会在删除指定数据库中的表之前删除它。
drop database sample cascade;
2.2 **表特定语句**
- create table**语句**
CREATE TABLE语句用于在Impala中的所需数据库中创建新表。 需要指定表名字并定义其列和每列的数据类型。
impala支持的数据类型和hive类似.
create table IF NOT EXISTS database_name.table_name (
column1 data_type,
column2 data_type,
column3 data_type,
………
columnN data_type
);
CREATE TABLE IF NOT EXISTS my_db.student(
name STRING,
age INT,
contact INT
);
默认建表的数据存储路径跟hive一致。也可以在建表的时候通过location指定具体路径。
- insert **语句**
Impala的INSERT语句有两个子句: into和overwrite。into用于插入新记录数据,overwrite用于覆盖已
有的记录。
insert into table_name (column1, column2, column3,...columnN)
values (value1, value2, value3,...valueN);
insert into table_name values (value1, value2, value2);
这里,column1,column2,… columnN是要插入数据的表中的列的名称。还可以添加值而不指定列名,但是,需要确保值的顺序与表中的列的顺序相同。
例子
create table employee (
id INT,
name STRING,
age INT,
address STRING,
salary BIGINT
);
insert into employee VALUES (1, 'Ramesh', 32, 'Ahmedabad', 20000 );
insert into employee values (2, 'Khilan', 25, 'Delhi', 15000 );
insert into employee values (3, 'kaushik', 23, 'Kota', 30000 );
insert into employee values (4, 'Chaitali', 25, 'Mumbai', 35000 );
insert into employee values (5, 'Hardik', 27, 'Bhopal', 40000 );
insert into employee values (6, 'Komal', 22, 'MP', 32000 );
overwrite覆盖子句覆盖表当中全部记录。 覆盖的记录将从表中永久删除。
insert overwrite employee values (1, 'Ram', 26, 'Vishakhapatnam', 37000 );
- select**语句**
Impala SELECT语句用于从数据库查询数据, 此查询以表的形式返回数据。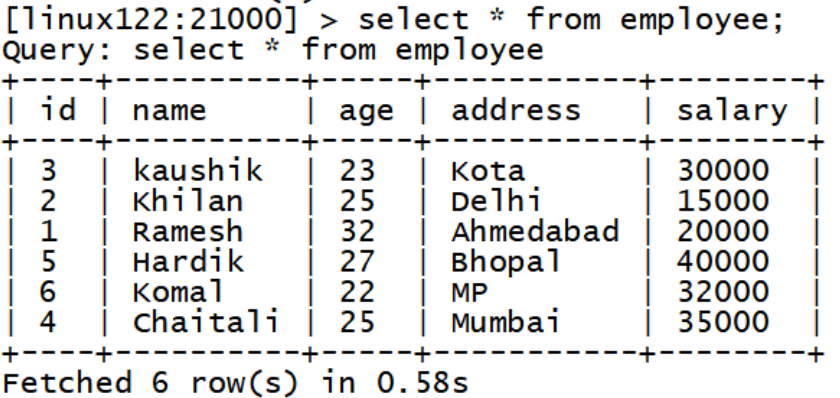
- describe **语句**
Impala中的describe语句用于提供表的描述。 此语句的结果包含有关表的信息,例如列名称及其数据类型。
describe table_name;
- alter table
Impala中的Alter table语句用于对给定表执行更改。使用此语句,我们可以添加,删除或修改现有表中的列,也可以重命名它们。
参考Hive实现。
- delete**、**truncate table
Impala drop table语句用于删除Impala中的现有表。此语句还会删除内部表的底层HDFS文件。
注意:使用此命令时必须小心,因为删除表后,表中可用的所有信息也将永远丢失。
drop table database_name.table_name;
Impala的Truncate Table语句用于从现有表中删除所有记录。保留表结构。
您也可以使用DROP TABLE命令删除一个完整的表,但它会从数据库中删除完整的表结构,如果您希望存储一些数据,您将需要重新创建此表。
truncate table_name;
Impala对复杂数据类型的支持
对于Text存储格式中的复杂类型不支持,复杂类型要使用parquet格式。
- view视图
视图仅仅是存储在数据库中具有关联名称的Impala查询语言的语句。 它是以预定义的SQL查询形式的表的组合。
视图可以包含表的所有行或选定的行。
create view if not exists view_name as select statement
创建视图view、查询视图view
create view if not exists employee_view AS select name, age from employee;
修改视图
alter view database_name.view_name as Select语句
删除视图
drop view database_name.view_name;
- order by子句
Impala ORDER BY子句用于根据一个或多个列以升序或降序对数据进行排序。 默认情况下,一些数据库按升序对查询结果进行排序。
select *
from table_name
ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]
可以使用关键字ASC或DESC分别按升序或降序排列表中的数据。
如果我们使用NULLS FIRST,表中的所有空值都排列在顶行; 如果我们使用NULLS LAST,包含空值的行将最后排列。
- group by**子句**
Impala GROUP BY子句与SELECT语句协作使用,以将相同的数据排列到组中。
select name, sum(salary) from employee group by name;
- having**子句**
容易与where过滤进行混淆,
如何区分:
where:过滤的数据是原始数据,表中本来就存在的数据;
having:过滤的是查询结果数据;
按年龄对表进行分组,并选择每个组的最大工资,并显示大于20000的工资
select max(salary) from employee group by age having max(salary) > 20000;
- limit**、**offset
Impala中的limit子句用于将结果集的行数限制为所需的数,即查询的结果集不包含超过指定限制的记录。
一般来说,select查询的resultset中的行从0开始。使用offset子句,我们可以决定从哪里考虑输出。
select * from employee order by salary limit 2 offset 2;
第 3 节 Impala导入数据
1. insert into values
这种方式非常类似于RDBMS的数据插入方式。
create table t_test2(id int,name string);
insert into table t_test2 values(1,”zhangsan”);
- insert into select
插入一张表的数据来自于后面的select查询语句返回的结果。
- create table as select
建表的字段个数、类型、数据来自于后续的select查询语句。
load data方式,这种方式不建议在Impala中使用,先使用load data方式把数据加载到Hive表中,然后使用以上方式插入Impala表中。
第 5 部分 Impala的JDBC方式查询
在实际工作当中,因为impala的查询比较快,所以可能有会使用到impala来做数据库查询的情况,我们可以通过java代码来进行操作impala的查询
1. 导入jar包
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-common -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-common</artifactId>
<version>2.3.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-metastore -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>2.3.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-service -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service</artifactId>
<version>2.3.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.7</version>
</dependency>
</dependencies>
2. java代码开发
package com.lagou.impala.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class ImpalaTest {
public static void main(String[] args) throws Exception {
//定义连接impala的驱动和连接url
String driver = "org.apache.hive.jdbc.HiveDriver";
String driverUrl = "jdbc:hive2://linux122:21050/default;auth=noSasl";
//查询的sql语句
String querySql = "select * from t1";
//获取连接
Class.forName(driver);
//通过Drivermanager获取连接
final Connection connection = DriverManager.getConnection(driverUrl);
final PreparedStatement ps = connection.prepareStatement(querySql);
//执行查询
final ResultSet resultSet = ps.executeQuery();
//解析返回结果
//获取到每条数据的列数
final int columnCount = resultSet.getMetaData().getColumnCount();
//遍历结果集
while (resultSet.next()) {
for (int i = 1; i <= columnCount; i++) {
final String string = resultSet.getString(i);
System.out.print(string + "\t");
}
System.out.println();
}
//关闭资源
ps.close();
connection.close();
}
}
第 6 部分 Impala进阶
第 1 节 Impala的负载均衡
Impala主要有三个组件,分别是statestore,catalog和impalad,对于Impalad节点,每一个节点都可以接收客户端的查询请求,并且对于连接到该Impalad的查询还要作为Coordinator节点(需要消耗一定的内存和CPU)存在,为了保证每一个节点的资源开销的平衡需要对于集群中的Impalad节点做一下负载均衡.
- Cloudera官方推荐的代理方案:HAProxy
- DNS做负载均衡
DNS做负载均衡方案是最简单的,但是性能一般,所以这里我们按照官方的建议使用HAProxy实现负载均衡。
生产中应该选择一个非Impalad节点作为HAProxy的安装节点
1.1 HAProxy方案
安装**haproxy**
yum install haproxy -y
配置文件
vim /etc/haproxy/haproxy.cfg
具体配置内容
#---------------------------------------------------------------------
# Example configuration for a possible web application. See the
# full configuration options online.
#
# http://haproxy.1wt.eu/download/1.4/doc/configuration.txt
#
#---------------------------------------------------------------------
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http#mode { tcp|http|health },tcp 表示4层,http表示7 层,health仅作为健康检查使用
log global
option httplog
option dontlognull
#option http-server-close
#option forwardfor except 127.0.0.0/8
#option abortonclose##连接数过大自动关闭
option redispatch#如果失效则强制转换其他服务器
retries 3#尝试3次失败则从集群摘除
timeout http-request 10s
timeout queue 1m
#timeout connect 10s
#timeout client 1m
#timeout server 1m
timeout connect 1d#连接超时时间,重要,hive查询数据能返回结果的保证
timeout client 1d#同上
timeout server 1d#同上
timeout http-keep-alive 10s
timeout check 10s#健康检查时间
maxconn 3000#最大连接数
listen status#定义管理界面
bind 0.0.0.0:1080#管理界面访问IP和端口
mode http#管理界面所使用的协议
option httplog
maxconn 5000#最大连接数
stats refresh 30s#30秒自动刷新
stats uri /stats
listen impalashell
bind 0.0.0.0:25003#ha作为proxy所绑定的IP和端口
mode tcp#以4层方式代理,重要
option tcplog
balance roundrobin#调度算法 'leastconn' 最少连接数分配,或者 'roundrobin',轮询分
server impalashell_1 linux121:21000 check
server impalashell_2 linux122:21000 check
server impalashell_3 linux123:21000 check
listen impalajdbc
bind 0.0.0.0:25004#ha作为proxy所绑定的IP和端口
mode tcp#以4层方式代理,重要
option tcplog
balance roundrobin #调度算法 'leastconn' 最少连接数分配,或者 'roundrobin',轮询分
server impalajdbc_1 linux121:21050 check
server impalajdbc_2 linux122:21050 check
server impalajdbc_3 linux122:21050 check
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend main *:5000
acl url_static path_beg -i /static /images /javascript /stylesheets
acl url_static path_end -i .jpg .gif .png .css .js
use_backend static if url_static
default_backend app
#---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
backend static
balance roundrobin
server static 127.0.0.1:4331 check
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend app
balance roundrobin
server app1 127.0.0.1:5001 check
server app2 127.0.0.1:5002 check
server app3 127.0.0.1:5003 check
server app4 127.0.0.1:5004 check
启动
开启: service haproxy start
关闭: service haproxy stop
重启: service haproxy restart
使用
Impala-shell访问方式
impala-shell -i linux123:25003
使用起来十分方便,区别仅仅相当于是修改了一个ip地址和端口而已,其余不变。
jdbc:hive2://linux123:25004/default;auth=noSasl
Impala集群在操作过程中尽量多给内存,如果内存不能满足使用要求,Impala的执行很可能会报错!!
第 2 节 Impala优化
cloudera官网上的Impala文档,原名为《Impala Performance Guidelines and Best Practices》。主要介绍了为了提升impala性能应该考虑的一些事情,结合实际考虑:
1. 基本优化策略
- 文件格式
对于大数据量来说,Parquet文件格式是最佳的
- 避免小文件
insert … values 会产生大量小文件,避免使用
合理分区粒度
利用分区可以在查询的时候忽略掉无用数据,提高查询效率,通常建议分区数量在3万以下(太 多的分区也会造成元数据管理的性能下降)
获取表的统计指标:在追求性能或者大数据量查询的时候,要先获取所需要的表的统计指标(如:执行 compute stats )
- 减少传输客户端数据量
聚合(如 count、sum、max 等)
过滤(如 WHERE )
limit限制返回条数
返回结果不要使用美化格式进行展示(在通过impala-shell展示结果时,添加这些可选参数: -B、 —output_delimiter )
- 在执行之前使用EXPLAIN来查看逻辑规划,分析执行逻辑
- Impala join自动的优化手段就是通过使用COMPUTE STATS来收集参与Join的每张表的统计信息,然后由Impala根据表的大小、列的唯一值数目等来自动优化查询。为了更加精确地获取每张表的统计信息,每次表的数据变更时(如执行Insert,add partition,drop partition等)最好都要执行一遍COMPUTE STATS获取到准确的表统计信息。

若有收获,就点个赞吧
0 人点赞
