一、Hive概述
HDFS => 海量数据的存储
MapReduce => 海量数据的分析和处理
YARN => 集群资源的管理和作业调度
1. Hive产生背景
直接使用MapReduce处理大数据,将面临以下问题:
- MapReduce 开发难度大,学习成本高(wordCount => Hello World)- Hdfs文件没有字段名、没有数据类型,不方便进行数据的有效管理- 使用MapReduce框架开发,项目周期长,成本高
Hive是基于Hadoop的一个数据仓库工具,可以将 结构化的数据文件 映射为一张表(类似于RDBMS中的表),并提供类SQL查询功能;Hive是由Facebook开源,用于解决海量结构化日志的数据统计。
- Hive本质是:将 SQL 转换为 MapReduce 的任务进行运算
- 底层由HDFS来提供数据存储
- 可以将Hive理解为一个:将** SQL 转换为 MapReduce **任务的工具
数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,主要用于管理决策。(数据仓库之父比尔·恩门,1991年提出)。
- 数据仓库的目的:构建面向分析的、集成的数据集合;为企业提供决策支持
- 数据仓库本身不产生数据,数据来源与外部
- 存储了大量数据,对这些数据的分析和处理不可避免的用到Hive
2. Hive和RDBMS对比
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将Hive 理解为数据库。其实从结构上来看,Hive 和传统的关系数据库除了拥有类似的查询语言,再无类似之处。
查询语言相似。
HQL <=> SQL 高度相似 由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言
HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
数据规模。
Hive存储海量数据;RDBMS只能处理有限的数据集; 由于Hive建立在集群上并可以利用MapReduce进行并行计算,
因此可以支持很大规模的数据;而RDBMS可以支持的数据规模较小。
执行引擎。
Hive的引擎是MR/Tez/Spark/Flink;RDBMS使用自己的执行引擎
Hive中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而RDBMS通常
有自己的执行引擎。
数据存储。
Hive保存在HDFS上;RDBMS保存在本地文件系统 或 裸设备 Hive 的数据都是存储在 HDFS 中的。
而RDBMS是将数据保存在本地文件系统或裸设备中。
执行速度。
Hive相对慢(MR/数据量);RDBMS相对快; Hive存储的数据量大,在查询数据的时候,通常没有索引,
需要扫描整个表;加之Hive使用MapReduce作为执行引擎,这些因素都会导致较高的延迟。
而RDBMS对数据的访问通常 是基于索引的,执行延迟较低。当然这个低是有条件的,即数据规模较小,当数据规模大到
超过数据库的处理能力的时候,Hive的并行计算显然能体现出并行的优势。
可扩展性。
Hive支持水平扩展;通常RDBMS支持垂直扩展,对水平扩展不友好 Hive建立在Hadoop之上,其可扩展性与Hadoop的
可扩展性是一致的(Hadoop集群规模可以轻松超过1000个节点)。而RDBMS由于 ACID 语义的严格限制,扩展行非常
有限。目 前最先进的并行数据库 Oracle 在理论上的扩展能力也只有100台左右。
数据更新。
Hive对数据更新不友好;RDBMS支持频繁、快速数据更新Hive是针对数据仓库应用设计的,数据仓库的内容是读多写少的。
因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而RDBMS中的数据需要频繁、快速的
进行更新。
3. Hive的优缺点
Hive的优点
- 学习成本低。Hive提供了类似SQL的查询语言,开发人员能快速上手;
- 处理海量数据。底层执行的是MapReduce 任务;
- 系统可以水平扩展。底层基于Hadoop;
- 功能可以扩展。Hive允许用户自定义函数;
- 良好的容错性。某个节点发生故障,HQL仍然可以正常完成;
统一的元数据管理。元数据包括:有哪些表、表有什么字段、字段是什么类型
Hive的缺点
HQL表达能力有限;
- 迭代计算无法表达;
- Hive的执行效率不高(基于MR的执行引擎);
- Hive自动生成的MapReduce作业,某些情况下不够智能;
- Hive的调优困难;
4. Hive架构
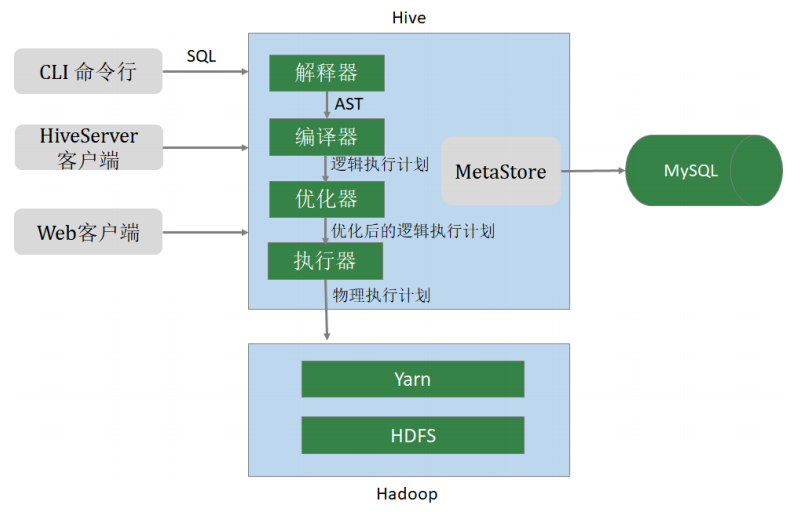
- 用户接口** **CLI(Common Line Interface):
Hive的命令行,用于接收HQL,并返回结果; JDBC/ODBC:是指Hive的java实现,与传统数据库JDBC类似;WebUI:是指可通过浏览器访问Hive;
- Thrift Server
Hive可选组件,是一个软件框架服务,允许客户端使用包括Java、C++、Ruby
和其他很多种语言,通过 编程的方式远程访问Hive;
- 元数据管理**(MetaStore)**
Hive将元数据存储在关系数据库中(如mysql、derby)。Hive的元数据包括:数据库名、表名及类型、字段名称及数据类型、数据所在位置等;
- 驱动程序**(Driver)**
- 解析器 (SQLParser) :使用第三方工具(antlr)将HQL字符串转换成抽象语法树(AST);对AST进行语法分析,比如字段是否存在、SQL语义是否有误、表是否存在;
- 编译器 (Compiler) :将抽象语法树编译生成逻辑执行计划;
- 优化器 (Optimizer) :对逻辑执行计划进行优化,减少不必要的列、使用分区等;
- 执行器 (Executr) :把逻辑执行计划转换成可以运行的物理计划;
三、数据类型与文件格式
Hive支持关系型数据库的绝大多数基本数据类型,同时也支持4种集合数据类型。
1. 基本数据类型及转换
Hive类似和java语言中一样,会支持多种不同长度的整型和浮点类型数据,同时也支持布尔类型、字符串类型,时间戳数据类型以及二进制数组数据类型等。详细信息见下表:
| 大类** ** | 类型 |
|---|---|
| Integers(整型) | TINYINT — 1字节的有符号整数 SAMLINT — 2字节的有符号整数 INT — 4字节的有符号整数 BIGINT — 8字节的有符号整数 |
| Floating point numbers(浮点数) | FLOAT — 单精度浮点数 DOUBLE — 双精度浮点数 |
| Fixed point numbers(定点数) | DECIMAL—用户自定义精度定点数,如 DECIMAL(10,3) |
| String types(字符串) | STRTIMESTAMP — 时间戳 TIMESTAMP WITH LOCAL TIME ZONE — 时间戳,纳秒精度 DATE — 日期类型 |
| Boolean(布尔类型) | BOOLEAN — TRUE / FALSE |
| Binary types(二进制类型) | BINARY — 字节序列 |
这些类型名称都是 Hive 中保留字。这些基本的数据类型都是 java 中的接口进行实现的,因此与 java 中数据类型是基本一致的:
| Hive数据类型 | Java数据类型 | 长度 | 样例 |
|---|---|---|---|
| TINYINT | 1byte有符号整数 | 20 | |
| SMALLINT | 2byte有符号整数 | 30 | |
| INT | 4byte有符号整数 | 40 | |
| BIGINT | 8byte有符号整数 | 50 | |
| BOOLEAN | 布尔类型 | TURE / FALSE | |
| FLOAT | 单精度浮点数 | 3.14159 | |
| DOUBLE | 双精度浮点数 | 3.14159 | |
| STRING | 字符系列,可指定字符 集;可使用单引号或双 引号 |
‘The Apache Hive data warehouse software facilitates’ |
|
| TIMESTAMP | 时间类型 | ||
| BINARY | 字节数组 |
1 数据类型的隐式转换
Hive的数据类型是可以进行隐式转换的,类似于Java的类型转换。如用户在查询中将一种浮点类型和另一种浮点类型的值做对比,Hive会将类型转换成两个浮点类型中值较大的那个类型,即:将FLOAT类型转换成DOUBLE类型;当然如果需要的话,任意整型会转化成DOUBLE类型。 Hive 中基本数据类型遵循以下层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。
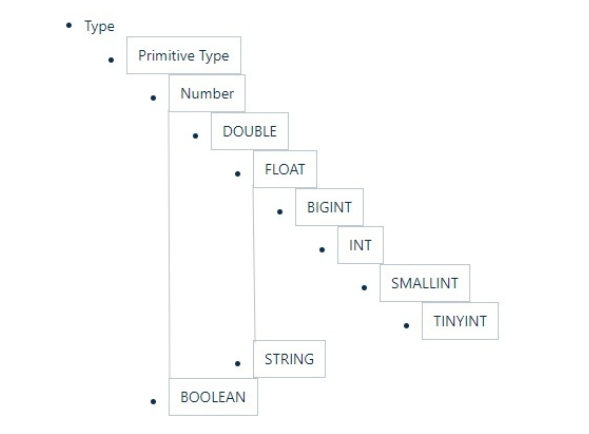
总的来说数据转换遵循以下规律:
hive> select '1.0'+2;
OK
3.0
hive> select '1111' > 10;
hive> select 1 > 0.8;
2 数据类型的显示转换
使用cast函数进行强制类型转换;如果强制类型转换失败,返回NULL
hive> select cast('1111s' as int);
OK
NULL
hive> select cast('1111' as int);
OK
1111
2 . 集合数据类型
Hive支持集合数据类型,包括array**、map、struct、**union
| 类型 | 描述 | 字面量示例 |
|---|---|---|
| ARRAY | 有序的相同数据类型的集合 | array(1,2) |
| MAP | key-value对。key必须是基本数据类型,value不限 | map(‘a’, 1, ‘b’,2) |
| STRUCT | 不同类型字段的集合。类似于C语言的结构体 | struct(‘1’,1,1.0),named_struct(‘col1’, ‘1’, ‘col2’, 1,’clo3’, 1.0) |
| UNION | 不同类型的元素存储在同一字段的不同行中 | create_union(1, ‘a’, 63) |
和基本数据类型一样,这些类型的名称同样是保留字;
ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似;
STRUCT 与 C 语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允
许任意层次的嵌套;
hive> select array(1,2,3)
OK
[1,2,3]
-- 使用 [] 访问数组元素
hive> select arr[0] from (select array(1,2,3) arr) tmp
hive> select map('a', 1, 'b', 2, 'c', 3)
OK
{"a":1,"b":2,"c":3}
-- 使用 [] 访问map元素
hive> select mymap["a"] from (select map('a', 1, 'b', 2, 'c', 3) as mymap) tmp
-- 使用 [] 访问map元素。 key 不存在返回 NULL
hive> select mymap["x"] from (select map('a', 1, 'b', 2, 'c', 3) as mymap) tmp
NULL
hive> select struct('username1', 7, 1288.68)
OK
{"col1":"username1","col2":7,"col3":1288.68}
-- 给 struct 中的字段命名
hive> select named_struct("name", "username1", "id", 7, "salary", 12880.68);
OK
{"name":"username1","id":7,"salary":12880.68}
-- 使用 列名.字段名 访问具体信息
hive> select userinfo.id > from (select named_struct("name", "username1", "id", 7,
"salary", 12880.68) userinfo) tmp;
-- union 数据类型
hive> select create_union(0, "zhansan", 19, 8000.88) uinfo;
3. 文本文件数据编码
Hive表中的数据在存储在文件系统上,Hive定义了默认的存储格式,也支持用户自
定义文件存储格式。
Hive默认使用几个很少出现在字段值中的控制字符,来表示替换默认分隔符的字
符。
Hive默认分隔符
id name age hobby(array) score(map)
字段之间:^A
元素之间: ^B
key-value之间:^C
666^Alisi^A18^Aread^Bgame^Ajava^C97^Bhadoop^C87
create table s1(
id int,
name string,
age int,
hobby array<string>,
score map<string, int>
);
load data local inpath '/home/hadoop/data/s1.dat' into table s1;
select * from s1;
| 分 隔 符 |
名称 | 说明 |
|---|---|---|
| \n | 换行符 | 用于分隔行。每一行是一条记录,使用换行符分割数据 |
| ^A | < Ctrl >+A | 用于分隔字段。在CREATE TABLE语句中使用八进制编码\\001表示 |
| ^B | < Ctrl >+B | 用于分隔 ARRAY、MAP、STRUCT 中的元素。在CREATE TABLE语句中使用八进制编码\002表示 |
| ^C | < Ctrl +C> | Map中 key、value之间的分隔符。在CREATE TABLE语句中使用八进制编码\003表示 |
Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001”)、行分隔符(”\n”)以及读取文件数据的方法。
在加载数据的过程中,Hive 不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。
将 Hive 数据导出到本地时,系统默认的分隔符是^A、^B、^C 这些特殊字符,使用cat 或者 vim 是看不到的;
在 vi 中输入特殊字符:
- (Ctrl + v) + (Ctrl + a) => ^A
- (Ctrl + v) + (Ctrl + b) => ^B
- (Ctrl + v) + (Ctrl + c) => ^C
^A / ^B / ^C 都是特殊的控制字符,使用 more 、 cat 命令是看不见的;可以使用cat **-**A file.dat
4. 读时模式
在传统数据库中,在加载时发现数据不符合表的定义,则拒绝加载数据。数据在写入数据库时对照表模式进行检查,这种模式称为”写时模式”(schema on write)。
写时模式 -> 写数据检查 -> RDBMS;
Hive中数据加载过程采用”读时模式” (schema on read),加载数据时不进行数据格式的校验,读取数据时如果不合法则显示NULL。这种模式的优点是加载数据迅速。
读时模式 -> 读时检查数据 -> Hive;好处:加载数据快;问题:数据显示NULL
九、 元数据管理与存储
1. Metastore
在Hive的具体使用中,首先面临的问题便是如何定义表结构信息,跟结构化的数据映射成功。所谓的映射指的是一种对应关系。在Hive中需要描述清楚表跟文件之间的映射关系、列和字段之间的关系等等信息。这些描述映射关系的数据的称之为Hive的元数据。该数据十分重要,因为只有通过查询它才可以确定用户编写sql和最终操作文件之间的关系。
Metadata即元数据。元数据包含用Hive创建的database、table、表的字段等元信息。元数据存储在关系型数据库中。如hive内置的Derby、第三方如MySQL等。
Metastore即元数据服务,是Hive用来管理库表元数据的一个服务。有了它上层的服务不用再跟裸的文件数据打交道,而是可以基于结构化的库表信息构建计算框架。
通过metastore服务将Hive的元数据暴露出去,而不是需要通过对Hive元数据库mysql的访问才能拿到Hive的元数据信息;metastore服务实际上就是一种thrift服务,通过它用户可以获取到Hive元数据,并且通过thrift获取元数据的方式,屏蔽了数据库访问需要驱动,url,用户名,密码等细节。
**
metastore三种配置方式
1**、内嵌模式**
内嵌模式使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。数据库和Metastore服务都嵌入在主Hive Server进程中。这个是默认的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。
优点:配置简单,解压hive安装包 bin/hive 启动即可使用;
缺点:不同路径启动hive,每一个hive拥有一套自己的元数据,无法共享。
2**、本地模式
本地模式采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server。教学中实际采用的是MySQL。本地模式不需要单独起metastore服务,用的是跟Hive在同一个进程里的metastore服务。也就是说当启动一个hive 服务时,其内部会启动一个metastore服务。Hive根据 hive.metastore.uris 参数值来判断,如果为空,则为本地模式。
缺点:每启动一次hive服务,都内置启动了一个metastore;在hive-site.xml中暴露的数据库的连接信息;
优点:配置较简单,本地模式下hive的配置中指定mysql的相关信息即可。
3、 **远程模式
远程模式下,需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程模式的metastore服务和hive运行在不同的进程里。
在生产环境中,建议用远程模式来配置**Hive Metastore**。
在这种模式下,其他依赖hive的软件都可以通过Metastore访问Hive。此时需要配置hive.metastore.uris 参数来指定 metastore 服务运行的机器ip和端口,并且需要单独手动启动metastore服务。metastore服务可以配置多个节点上,避免单节点故障导致整个集群的hive client不可用。同时hive client配置多个metastore地址,会自动选择可用节点。
metastore**内嵌模式配置**
1、下载软件解压缩
2、设置环境变量,并使之生效
3、初始化数据库。
schematool -dbType derby -initSchema
4、进入hive命令行
5、再打开一个hive命令行,发现无法进入
metastore**远程模式配置
配置规划:
| 节点 | metastore | client |
|---|---|---|
| linux121 | √ | |
| linux122 | √ | |
| linux123 | √ |
配置步骤:
配置步骤:**
1、将 linux123 的 hive 安装文件拷贝到 linux121、linux122
2、在linux121、linux123上分别启动 metastore 服务
# 启动 metastore 服务
nohup hive --service metastore &
# 查询9083端口(metastore服务占用的端口)
lsof -i:9083
# 安装lsof
yum install lsof
3、修改 linux122 上hive-site.xml。删除配置文件中:MySQL的配置、连接数据库的用户名、口令等信息;增加连接metastore的配置:
<!-- hive metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop01:9083,thrift://hadoop03:9083</value>
</property>
4、启动hive。此时client端无需实例化hive的metastore,启动速度会加快。
# 分别在linux121、linux123上执行以下命令,查看连接情况
lsof -i:9083
5、高可用测试。关闭已连接的metastore服务,发现hive连到另一个节点的服务上,仍然能够正常使用。
**
2. HiveServer2
HiveServer2是一个服务端接口,使远程客户端可以执行对Hive的查询并返回结果。
目前基于Thrift RPC的实现是HiveServer的改进版本,并支持多客户端并发和身份验证,启动hiveServer2服务后,就可以使用jdbc、odbc、thrift 的方式连接。
Thrift是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。它被当作一个远程过程调用(RPC)框架来使用,是由Facebook为“大规模跨语言服务开发”而开发的。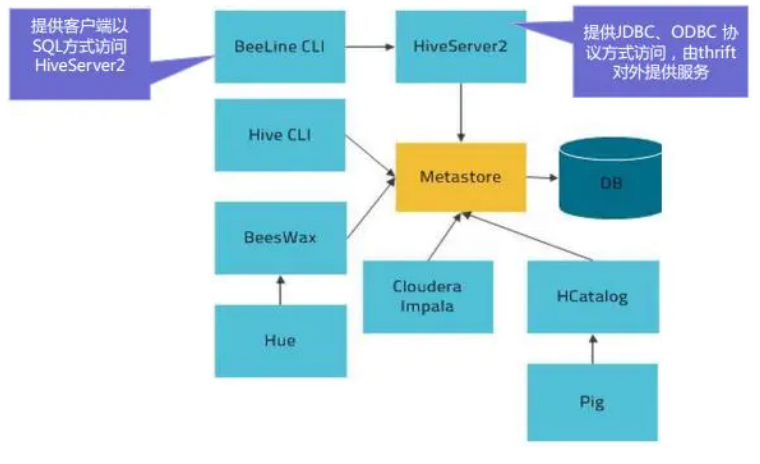
HiveServer2(HS2)是一种允许客户端对Hive执行查询的服务。HiveServer2是HiveServer1的后续 版本。HS2支持多客户端并发和身份验证,旨在为JDBC、ODBC等开放API客户端提供更好的支持。
HS2包括基于Thrift的Hive服务(TCP或HTTP)和用于Web UI 的Jetty Web服务器。
HiveServer2作用:
- 为Hive提供了一种允许客户端远程访问的服务
- 基于thrift协议,支持跨平台,跨编程语言对Hive访问
- 允许远程访问Hive
HiveServer2配置
配置规划: | 节点 | HiveServer2 | client | | —- | —- | —- | | hadoop01 | | | | hadoop02 | | √ | | hadoop03 | √ | |
配置步骤:
1、修改集群上的 core-site.xml,增加以下内容:
<!-- HiveServer2 连不上10000;hadoop为安装用户 -->
<!-- root用户可以代理所有主机上的所有用户 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
2、修改 集群上的 hdfs-site.xml,增加以下内容:
<!-- HiveServer2 连不上10000;启用 webhdfs 服务 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
3、启动hadoop03上的 HiveServer2 服务
# 启动 hiveserver2 服务
nohup hiveserver2 &
# 检查 hiveserver2 端口
lsof -i:10000
# 从2.0开始,HiveServer2提供了WebUI
# 还可以使用浏览器检查hiveserver2的启动情况。http://hadoop03:10002/
4、启动hadoop02 节点上的 beeline
Beeline是从 Hive 0.11版本引入的,是 Hive 新的命令行客户端工具。
Hive客户端工具后续将使用Beeline 替代 Hive 命令行工具 ,并且后续版本也会废弃掉 Hive 客户端工具。
!connect jdbc:hive2://hadoop03:10000
use mydb;
show tables;
select * from emp;
create table tabtest1 (c1 int, c2 string);
!connect jdbc:mysql://hadoop03:3306
!help
!quit
3. HCatalog
HCatalog 提供了一个统一的元数据服务,允许不同的工具如 Pig、MapReduce 等通过 HCatalog 直接访问存储在 HDFS 上的底层文件。HCatalog是用来访问Metastore的Hive子项目,它的存在给了整个Hadoop生态环境一个统一的定义。
HCatalog 使用了 Hive 的元数据存储,这样就使得像 MapReduce 这样的第三方应用可以直接从 Hive 的数据仓库中读写数据。同时,HCatalog 还支持用户在MapReduce 程序中只读取需要的表分区和字段,而不需要读取整个表,即提供一种逻辑上的视图来读取数据,而不仅仅是从物理文件的维度。
HCatalog 提供了一个称为 hcat 的命令行工具。这个工具和 Hive 的命令行工具类似,两者最大的不同就是 hcat 只接受不会产生 MapReduce 任务的命令。
# 进入 hcat 所在目录。$HIVE_HOME/hcatalog/bin
cd $HIVE_HOME/hcatalog/bin
# 执行命令,创建表
./hcat -e "create table default.test1(id string, name string, age int)"
# 长命令可写入文件,使用 -f 选项执行
./hcat -f createtable.txt
# 查看元数据
./hcat -e "use mydb; show tables"
# 查看表结构
./hcat -e "desc mydb.emp"
# 删除表
./hcat -e "drop table default.test1"
4. 数据存储格式
Hive支持的存储数的格式主要有:TEXTFILE(默认格式) 、SEQUENCEFILE、RCFILE、ORCFILE、PARQUET。
- textfile为默认格式,建表时没有指定文件格式,则使用TEXTFILE,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;
- sequencefile,rcfile,orcfile格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中, 然后再从表中用insert导入sequencefile、rcfile、orcfile表中。
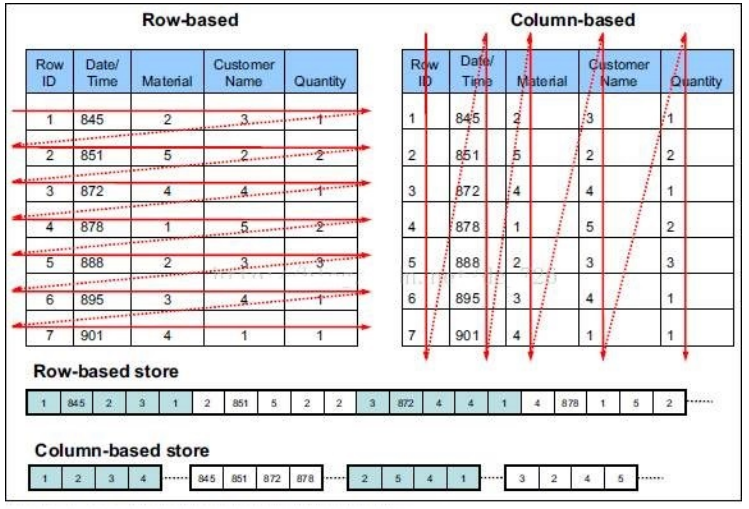
行存储与列存储
行式存储下一张表的数据都是放在一起的,但列式存储下数据被分开保存了。
行式存储:
优点:数据被保存在一起,insert和update更加容易
缺点:选择(selection)时即使只涉及某几列,所有数据也都会被读取
列式存储:
优点:查询时只有涉及到的列会被读取,效率高
缺点:选中的列要重新组装,insert/update比较麻烦
TEXTFILE、SEQUENCEFILE 的存储格式是基于行存储的;
ORC和PARQUET 是基于列式存储的。
TextFile
Hive默认的数据存储格式,数据不做压缩,磁盘开销大,数据解析开销大。 可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
create table if not exists uaction_text(
userid string,
itemid string,
behaviortype int,
geohash string,
itemcategory string,
time string
)
row format delimited fields terminated by ','
stored as textfile;
load data local inpath '/home/hadoop/data/useraction.dat'
overwrite into table uaction_text;
SEQUENCEFILE
SequenceFile是Hadoop API提供的一种二进制文件格式,其具有使用方便、可分割、可压缩的特点。 SequenceFile支持三种压缩选择:none**,record,**block。
Record压缩率低,一般建议使用BLOCK压缩。
RCFile
RCFile全称Record Columnar File,列式记录文件,是一种类似于SequenceFile的键值对数据文件。RCFile结合列存储和行存储的优缺点,是基于行列混合存储的RCFile。
RCFile遵循的“先水平划分,再垂直划分”的设计理念。先将数据按行水平划分为行组,这样一行的数据就可以保证存储在同一个集群节点;然后在对行进行垂直划分。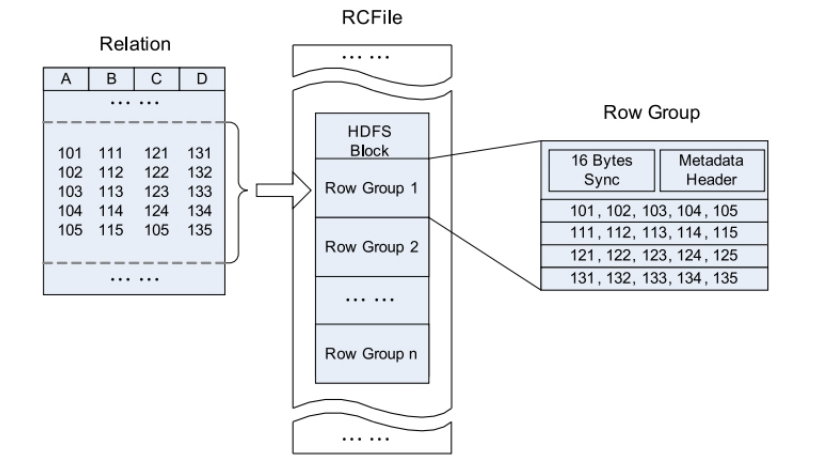
- 一张表可以包含多个HDFS block
- 在每个block中,RCFile以行组为单位存储其中的数据
- row group又由三个部分组成
- 用于在block中分隔两个row group的16字节的标志区
- 存储row group元数据信息的header
- 实际数据区,表中的实际数据以列为单位进行存储
ORCFile
ORC File,它的全名是Optimized Row Columnar (ORC) file,其实就是对RCFile做了一些优化,在hive 0.11中引入的存储格式。这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、写以及处理数据的性能。ORC文件结构由三部分组成:
- 文件脚注(file footer):包含了文件中 stripe 的列表,每个stripe行数,以及每个列的数据类型。还包括每个列的最大、最小值、行计数、求和等信息
- postscript:压缩参数和压缩大小相关信息
- 条带(stripe):ORC文件存储数据的地方。在默认情况下,一个stripe的大小为250MB
- Index Data:一个轻量级的index,默认是每隔1W行做一个索引。包括该条带的一些统计信息,以及数据在stripe中的位置索引信息
- Rows Data:存放实际的数据。先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个stream来存储
- Stripe Footer:存放stripe的元数据信息
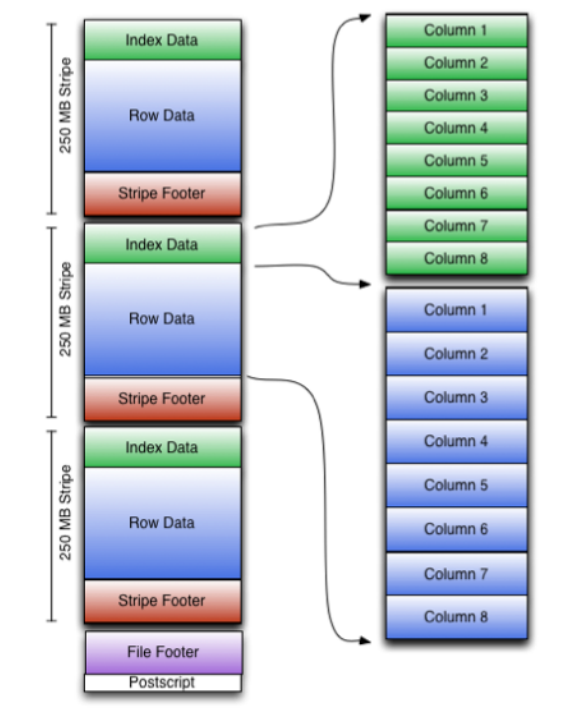
ORC在每个文件中提供了3个级别的索引:文件级、条带级、行组级。借助ORC提供的索引信息能加快数据查找和读取效率,规避大部分不满足条件的查询条件的文件和数据块。使用ORC可以避免磁盘和网络IO的浪费,提升程序效率,提升整个集群的工作负载。
create table if not exists uaction_orc(
userid string,
itemid string,
behaviortype int,
geohash string,
itemcategory string,
time string
)
stored as orc;
insert overwrite table uaction_orc select * from uaction_text;
Parquet
Apache Parquet是Hadoop生态圈中一种新型列式存储格式,它可以兼容Hadoop生态圈中大多数计算框架(Mapreduce、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),与语言和平台无关的。
Parquet文件是以二进制方式存储的,不能直接读取的,文件中包括实际数据和元数据,Parquet格式文件是自解析的。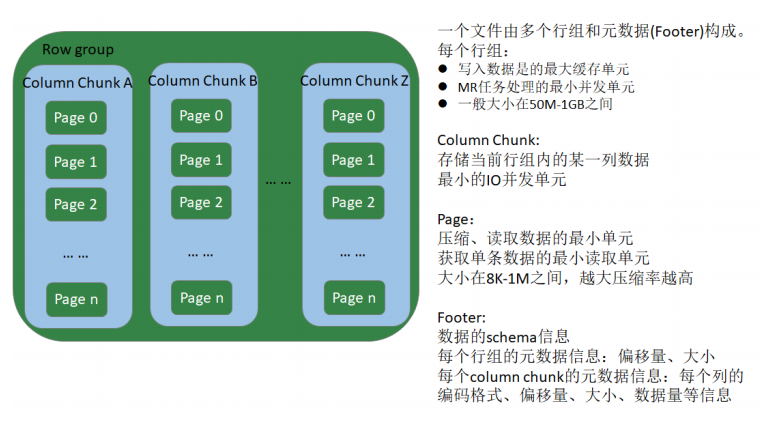
Row group:
- 写入数据时的最大缓存单元
- MR任务的最小并发单元
- 一般大小在50MB-1GB之间
Column chunk**:
- 存储当前Row group内的某一列数据
- 最小的IO并发单元
Page**:**
- 压缩、读数据的最小单元
- 获得单条数据时最小的读取数据单元
- 大小一般在8KB-1MB之间,越大压缩效率越高
Footer**:**
- 数据Schema信息
- 每个Row group的元信息:偏移量、大小
- 每个Column chunk的元信息:每个列的编码格式、首页偏移量、首索引页偏移
- 量、个数、大小等信息 ```sql create table if not exists uaction_parquet( userid string, itemid string, behaviortype int, geohash string, itemcategory string, time string ) stored as parquet;
insert overwrite table uaction_parquet select * from uaction_text;
<br />
<a name="bcFcR"></a>
#### 文件存储格式对比测试
说明:<br />1、给 linux123 分配合适的资源。2core;2048G内存<br />2、适当减小文件的数据量(现有数据约800W,根据自己的实际选择处理100-300W条数据均可)
```sql
# 检查文件行数
wc -l uaction.dat
#
head -n 1000000 uaction.dat > uaction1.dat
tail -n 1000000 uaction.dat > uaction2.dat
文件压缩比
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/ua*;
13517070 /user/hive/warehouse/mydb.db/uaction_orc/000000_1000
34867539 /user/hive/warehouse/mydb.db/uaction_parquet/000000_1000
90019734 /user/hive/warehouse/mydb.db/uaction_text/useraction.dat
ORC > Parquet > text
执行查询
SELECT COUNT(*) FROM uaction_text;
SELECT COUNT(*) FROM uaction_orc;
SELECT COUNT(*) FROM uaction_parquet;
-- text : 14.446
-- orc: 0.15
-- parquet : 0.146
orc 与 parquet类似 > txt
在生产环境中,Hive表的数据格式使用最多的有三种:TextFile、ORCFile、Parquet。
- TextFile文件更多的是作为跳板来使用(即方便将数据转为其他格式)
- 有update、delete和事务性操作的需求,通常选择ORCFile
- 没有事务性要求,希望支持Impala、Spark,建议选择Parquet

若有收获,就点个赞吧
0 人点赞
