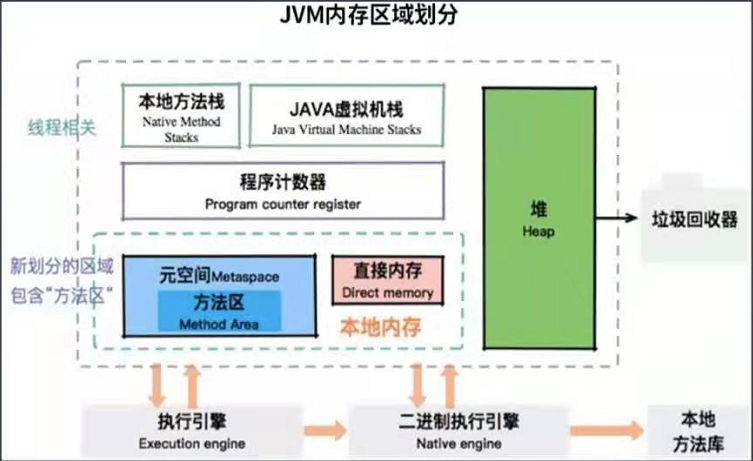
JVM是如何进行内存区域划分的?
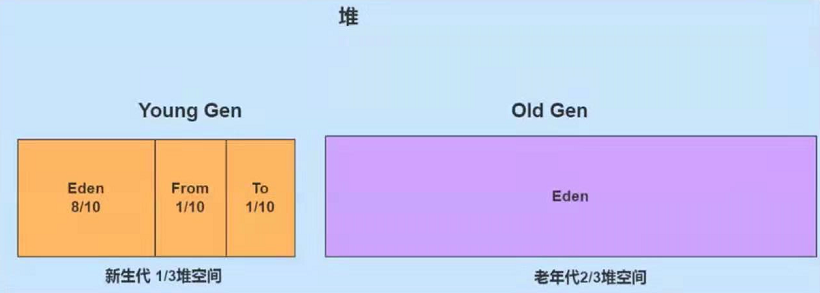
JVM堆中的数据是共享的,是占用内存最大的一块区域。
引擎模块:可以执行字节码的模块。
执行引擎在线程切换时恢复,靠的是程序计数器。
JVM的内存划分与多线程有关。程序运行中的栈,本地方法栈,维度都是线程。
本地内存包含元数据区和一些直接内存。
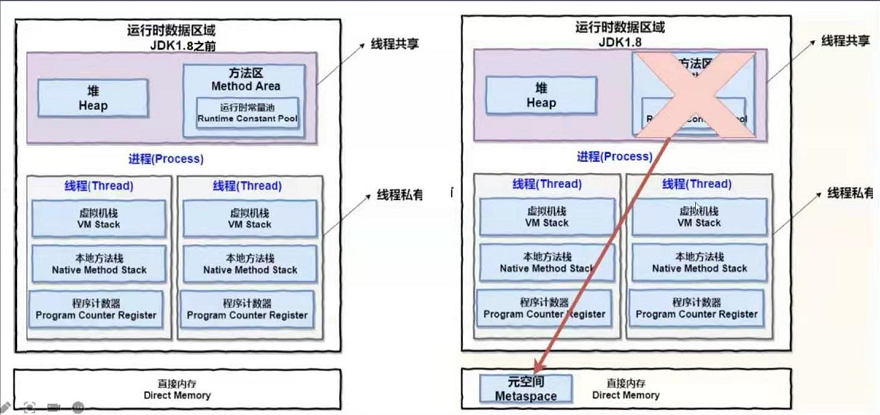
jvm7和jvm8的内存变化:
控制内存区域的参数:
- 堆 -Xmx -Xms
- 元空间 -XX:MaxMetaspaceSize -XX:MetaspaceSize
- 栈 -Xss
- 直接内存 -XX;MaxDirectMemorySize
- 其他堆外内存 无法控制!
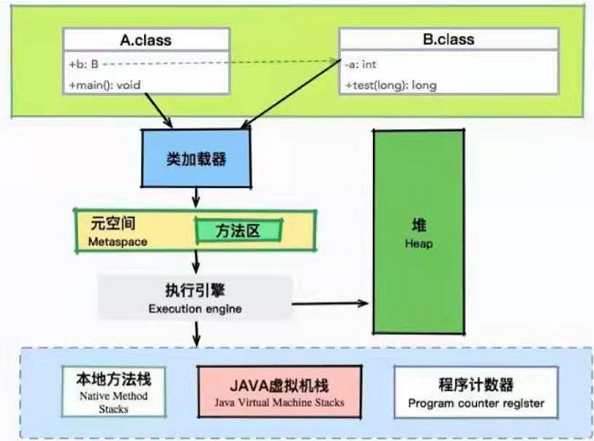
类是如何加载的?如何执行?
执行A代码,在调用private B b = new B()时,类加载了
字节码的执行过程:
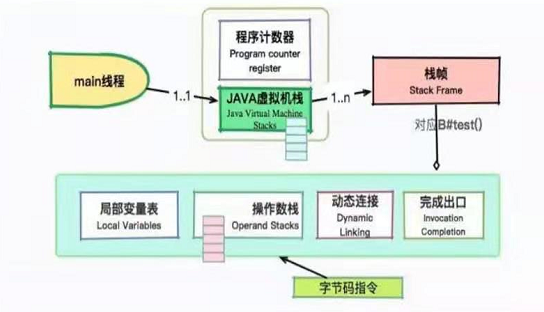
main线程会拥有两个主要的运行时区域: Java虚拟机栈和程序计数器。
虚拟机栈中的每项内容叫做栈帧,栈帧包括:
- 局部变量表
- 操作数栈
- 动态链接
- 完成出口
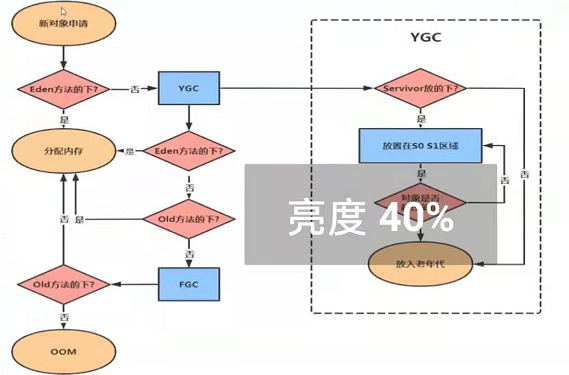
对象是如何分配的?
分配过程:
- new的对象先放在eden区,该区域有大小限制;
- 当eden区填满时,程序又需要创建对象,JVM的垃圾回收器将对eden区预期进行垃圾回收(Minor GC);
- 将eden区中不再被其他对象引用的对象进行销毁,再加载新的对象放入eden区,然后将eden区中的剩余对象移动到幸存者0区(f1);
- 如果再次触发垃圾回收,此时上次幸存下来的放在幸存者0区,如果没有回收,就会放入到幸存者1区
- 如果再次进行垃圾回收,此时会重新返回幸存者0区,接着再去幸存者1区。
- 如果累计次数达到默认的15次,进入老年代。
可以设置参数, 调整阈值 -XX:MaxTenuringThreshold=N
- 老年代内存不足时,会再次触发GC:Major GC进行老年代的内存清理
- 如果老年代执行了Major GC后仍然没有办法进行对象的保存,就会报OOM异常
常见的垃圾收集器及其特点?
垃圾回收器介绍:
CMS 将再java14移除
G1 主流应用的垃圾回收器
ZGC 大容量(16TB) , 低延迟(10MS)的垃圾回收器
-XX:+UseG1GC \-XX:MaxGCPauseMillis=100 \-XX:InitiatingHeapOccupancyPercent=45 \-XX:G1HeapRegionSize=16m \
MaxGCPauseMilli 预定目标,自动调整
G1HeapRegionSize 小堆区大小
InitiatingHeapOccupancyPercent 堆内存比例阈值,启动并发标记
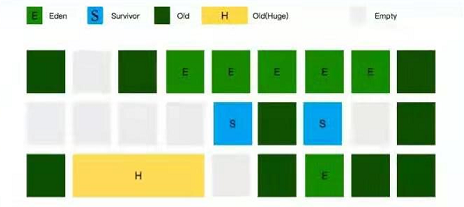
对象提升(Promotion):
Reference Chain
可达性分析法
GC过程:找到活跃的对象,然后清理其他对象
引用级别:
- 强引用:
属于最普通最强硬的一种存在,只有在和GC Roots断绝关系后,才会被消灭掉
- 软引用:
只有在内存不足时,系统会回收软引用对象
- 弱引用:
当JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象
- 虚引用:
用来跟踪对象被垃圾回收的活动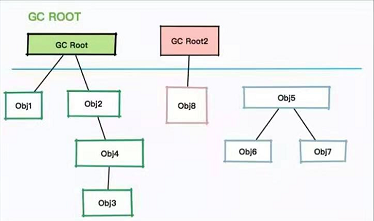
常见的内存问题有哪些?OOM发生的场景有哪些?
常见的内存问题:
- 内存溢出(OutOfMemoryError, OOM)
- 堆时最常见的情况
- 堆外内存排查困难
- 内存泄漏(Memory Leak, ML)
- 分配的内存没有得到释放
- 内存一直在增长,有OOM风险
- GC时该回收的回收不掉
- 能够回收掉但是很快又占满,产生压力
OOM到底是什么引起的?
- 内存的容量小,需要扩容,或者需要调整堆的空间
- 错误的引用方式,发生了内存泄漏,没有及时切断与GC Roots的关系。 比如线程池里的线程,在复用的情况下忘记清理ThreadLocal的内容
- 接口没有进行范围校验,外部传参超出范围。比如数据库查询时的每页条数等
- 对堆外内存无限制的使用。这种情况一旦发生更加验严重,会造成操作系统内存耗尽
典型的OOM场景:
典型的内存泄露场景,原因在于对象没有及时的释放自己的引用,比如一个局部变量,被外部的静态集合引用。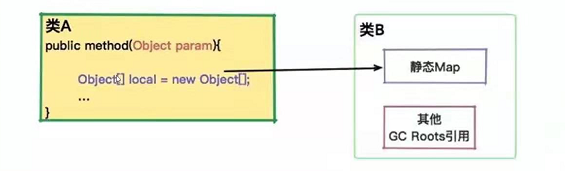
平常写代码时,不要为了方便把对象到处引用,及时引用了,要在合适的时候释放掉。
内存问题的影响:
GC时间变长、内存占用居高不下、服务卡顿、进程死亡。
- 发生OOM Error , 应用停止(最严重)
- 频繁GC,GC时间长,GC线程时间片占用高
- 服务卡顿,请求响应时间变长
排查困难:
- 问题时间跨度大
- 问题解决耗费精力
- 现场保护意识不足
优化的目标及指标:
将目标归为三点:
- 系统容量(Capacity)
- 每个月运维费用不能超过x万,那就决定了机器最多2C4G的。
- 延迟(Latency)
- 吞吐量(Throughput)
选择垃圾回收器:应用场景
- 如果堆大小不是很大(100M),选择串行收集器一般是效率最高的。
参数:-XX:+UseSerialGC。
- 如果应用运行在单核机器上,或者虚拟机核数只有1C,选择串行收集器依然是合适的,这时候启用一些并行收集器没有任何收益。
参数:-XX:+UseSerialGC。
- 如果应用是”吞吐量”优先。并且对较长时间的停顿没有什么特别的要求。选择并行收集器是比较好的。
参数: -XX:+UseParallelGC。 - 如果应用对响应时间要求较高,想要较少的停顿。甚至1秒的停顿都会引起大量的请求失败,那么选择G1、ZGC、CMS都是合理的。虽然这些收集器的GC停顿通常都比较短,但它需要一些额外的资源去处理这些工作,通常吞吐量会低一些。
参数: -XX:+UseConcMarkSweepGC、—XX:+UseG1GC、—XX:+UseZGC等。
大流量应用的特点:
一般是社交、电商、游戏、支付场景等,要求 短、平、快。 长时间的停顿会堆积海量的请求,所以停顿发生时,表现非常明显。
- 每秒处理的事务数量(TPS);
- 平均响应时间(AVG);
- TP值,比如TP90代表有90%的请求响应时间小于x ms(毫秒);
TP值越大,最能代表系统中到底有多少长尾请求,这部分请求才是影响系统稳定性的元凶。
大多数情况下,GC增加,长尾请求的数量也会增加。 目的: 减少这些停顿
ps:长尾请求的危害:
假设,一个服务B,有1%的可能性响应时间大于1s。如果此刻一个上海服务器A需要完成一次查询,需要同时在查询100次的话,那么服务A响应时间超过1%的概率时63%,0.99的概率时小于1s,100次这样的概率时0.99^100=0.37,小于1s响应的时间时37%的概率。
优化策略-估算:
接口每天有10亿次请求,加入每次请求的大小时20K,那么一天的流量就有18T,假如高峰请求6w/s,我们部署10台机器,那么每个JVM的流量就可以达到120M/S,这个速度比较快了, 不知道怎么去估算这个数字,就按照峰值的2倍进行准备。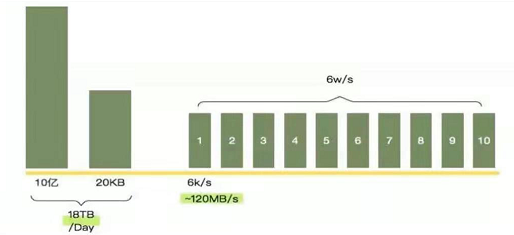
调优:
环境:
机器是4C8G的,分配了JVM 10248G/32=5460MB的空间
年轻代的大小是 5460M/3=1820M
eden区的大小约为1456M,Survivor区大小,大约是182M左右
每12秒,就会发生一次Minor GC; 每个半小时,会发生一次Major GC。
问题:
不管是年轻代还是老年代,这个GC的频率都有点频繁了。
原因:
survivor区就已经装不下Minor GC后的内容了。 总有一部分超出的容量,需要老年代补齐。这些垃圾信息就要保存更长时间,知道老年代内存不足。
分析:
大多数都在年轻代就销毁了。如果我们加大年轻代的大小,由于GC时间受到活跃都西昂数的影响,回收时间并不会增加太多,我们把一半空间给年轻代。
-XX:+UseConcMarkSweepGC -Xmx5460M -Xms5460M -Xmn2760M
重新估算,发现Minor GC的间隔,由12秒变为18秒
线上观察:
[ParNew:2292326K - > 243160K(2795520K), 0.1021743 secs] 3264966K - > 10880154K(1215800K), 0.1021417 secs]
(Times:user=0.52 sys=0.02, real=0.2 secs)
Minor GC有所改善,但是并没有得到显著提升。相比较而言,Major GC的时间间隔却增加了3个小时,是一个非常大的性能优化。这就是在容量限制下的初步调优方案。
这种场景下,我们更加激进一些,调大年轻代(也调大幸存者),让对象在年轻代停留的时间更长一些。有更多的buffer空间,这样Minor GC间隔提高到23秒。
参数配置:
-XX:+UseConcMarkSweepGC -Xmx5460M -Xms5460M -Xmn3460M
看起来很好,但是有瑕疵
由于每秒的请求非常大, 如果应用重启或更新,流量瞬间打过来,JVM还没有预热完毕,这是就有大量的用户请求超时、失败。
为了解决这个问题,通常需要把新发布的机器进行放量预热。比如第一秒100,第二秒200,第三秒5000.大型的应用都会有这个预热过程。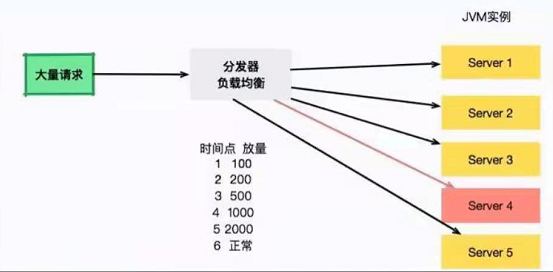
负载均衡负责服务的放量,server4将在6秒之后流量正常流通。但是,每次重启大概20秒,就会发生一次诡异的Full GC。
一般。Full GC实在老年代空间不足的时候执行,我们还有一个区域叫Metaspace,它的容量没有上限,每当它扩容时,就会Full GC。
按照经验,一般调整成256M足够了,同时,为了避免无限制使用造成操作系统内存溢出,我们同时设置上限。
-XX:+UseConcMarkSweepGC -Xmx5460M -Xms5460M -Xmn3460M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
我们把部分机器升级到8C16G的机器,使用如下参数:
-XX:+UseConcMarkSweepGC -Xmx10920M -Xms10920M -Xmn5460M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
相比较其他实例,系统运行的还不错,平均1分钟左右发生一次Minor GC, 老年代1天发生GC,响应水平明显提高。
日志信息:
- 业务日志
- GC日志(http:gceasy.io/)
LOG_OIR="/tmp/logs"
JAVA_OPT_LOG=" -verbose:gc"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCDetails"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCDateStamps"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCApplicationStoppedTime"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintTenuringDistribution"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+Xloggc:${LOG_OIR}/gc_%p.log"
grafana是一个监控展示组件,支持非常多的数据源类型,对influxdb的集成度也高
wget -c https://dl.grafana.com/oss/release/grafana-6.5.3.linux-amd64.tar.gztar -zxvf \
grafana-6.5.3.linux-amd64.tar.gz
# 排查工具示例
ss -antp > $DUMP_DIR/ss.dump 2>&1
netstat -s > $DUMP_DIR/netstat-s.dump 2>&1
top -Hp $PID -b -n 1 -c > $DUMP_DIR/top-$PID.dump 2>&1
sar -n DEV 1 2 > $DUMP_DIR/sar-traffic.dump 2>&1
lsof -p $PID > $DUMP_DIR/lsof-$PID.dump 2>&1
iostat -x > $DUMP_DIR/iostat.dump 2>&1
free -h > $DUMP_DIR/free.dump 2>&1
jstat -gcutil $PID > $DUMP_DIR/njstat-gcutil.dump 2>&1
jstack $PID > $DUMP_DIR/jstack.dump 2>&1
jmap -histo $PID > $DUMP_DIR/JMAP-histo.dump 2>&1
jmap -dump:format=b,file=$DUMP_DIR/heap.bin > dev/null 2>&1
一个高死亡率的报表系统的优化之路
传统观念上的报表系统,可能访问量不是特别多,点击一个查询按钮,后台sql语句的执行需要等数秒。如果使用jstack来查看执行线程,会发现大多数的线程都阻塞在数据库的i/o上。
还有一种类似于大屏监控一类的实时报表,这种报表的并发量也是比较可观的,但由于它的结果集都比较小,所以我们可以像对待一个高并发系统一样对待它,问题不大。
有一个报表系统,频繁发生内存溢出,在高峰期间使用时,还会频繁发生拒绝服务,这是不能忍受的。
本次要优化的是一个SaaS服务,使用SpingBoot编写,采用的是CMS垃圾回收器,有些接口会从Mysql中获取数据,有些则从MongoDB中获取数据,设计的结果集合比较大。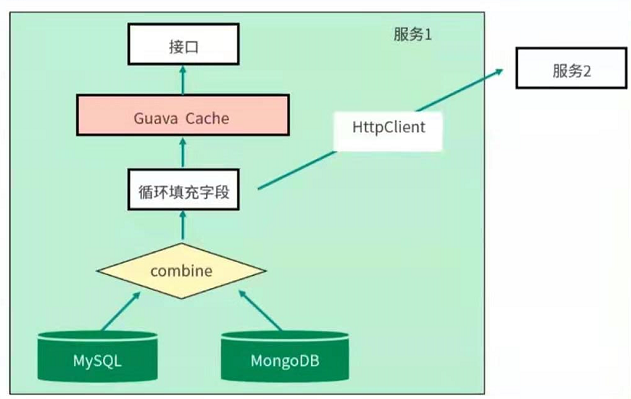
问题排查:
初步排查,JVM的资源太少
当接口A每次进行报表计算时,都要涉及几百兆的内存,而且内存里驻留很长时间,同时有些计算非常耗CPU,特别的”吃”资源,而我们分配给JVM的内存只有3GB,在多人访问这些接口的时候,内存就不够用了。进而发生OOM,这种情况下,即使最简单的报表都不能用了。
升级机器
把机器配置升级到4C8G,给JVM分配6G的内存,这样OOM问题就消失了。但随之而来的是频繁的GC问题和超长的GC时间。平均GC时间竟然有5秒多。。。
初步优化:
6G内存,年轻代大约2G,在高峰期,每几秒需要进行一次MinorGC。报表系统和高并发系统不一样。它的对象存活时间比较长,不能仅仅通过增加年轻代来解决;而且,如果增加年轻代,那么必然减少了老年代的大小,由于CMS的碎片和浮动垃圾问题,我们可用的空间变少了。
- 了解了程序中有很多的缓存数据和静态统计数据,为了减少MinorGC的次数,通过分析GC日志打印的对象年龄分布,把MaxTenuringThreshold参数调整到了3。这个参数是让年轻代的这些对象,赶紧回到老年代去,不要老呆在年轻代。
- 我们的GC时间比较长,就一块开了参数CMSScavengeBeforeRemark,使得CMS remark前,先执行一次Minor GC将新生代清理掉。同时配合上个参数,其效果还是不错。
- 对象很快进入老年代
- 年轻代的对象在这种情况下是有限的,在整个MajorGC中占的时间也有限。
由于缓存的使用,有大量的弱引用,拿一次长达10秒的GC,发现在GC日志中,处理weak refs的时间长,达到了4.5秒。
加入了参数ParallelRefProcEnabled来并行处理Reference,以加快处理速度,缩短耗时,调整触发GC的参数来优化:
-Xmx6g -Xms6g -XX:MaxTenuringThreshold=3 \
-XX:+AlwaysPreTouch -XX:+ParallelRefProcEnabled \
-XX:+CMSScavengeBeforeRemark \
-XX:+UseConcMarkSweepGC \
-XX:CMSInitiatingOccupancyFraction=80 \
-XX:+UseCMSInitiatingOccupancyOnly
高性能的机器带来了非常大的服务吞吐量
通过jstat进行监控,能够看到年轻代的分配速率明显提高,但随之而来的MinorGC时间却变的不可控,有时候会超过1秒。累积的请求造成了更加严重的后果。
-Xmx12g -Xms12g -XX:UseG2GC \
-XX:InitiatingHeapOccupancyPercent=45 \
-XX:MaxGCPauseMillis=200 \
-XX:G1HeapRegionSize=16m \
-XX:MetaspaceSize=256m \
-XX:MaxMetaspaceSize=256m
代码优化:
减少内存占用,清理到无用的信息, 改造sql查询语句。
- 很多接口,其实并不需要把数据库的每个字段都查询出来,当你在计算和解析的时候,他们会吃掉内存,所以只需要获取所需要的数据就ok了,把select * 改为查询具体的字段;
- Cache问题,通过排查代码,会发现一些命中率特别低,占用内存又大的对象,放到了JVM的Cache中,造成了无用的浪费。
解决:
把Guava的Cache引用级别改为弱引用(WeakKeys),尽量去掉无用的应用缓存,对于某些使用特别频繁的小key,使用分布式redis进行改造。
为了找到更多影响因子大的问题,我们部署了独立的环境,然后部署了JVM的监控。在回放某个问题请求后,观察JVM的响应,发现更多优化可能。
报表系统使用POI组件进行导入导出功能开发,结果客户在没有限制的情况下上传、下载了条数非常多的文件,直接让堆内存飙升。
解决:
在导入功能加入了文件大小限制,强制客户进行拆分;在下载的时候指定范围,严禁跨度非常大的请求。
完成代码改造后,把机器配置降级 4C8G,依然采用G1垃圾回收器,再也没有发生OOM问题。GC问题得到了明显的缓解。

若有收获,就点个赞吧
0 人点赞
