前言
首先知道CPU和cahce line,然后基于此了解下CPU如何读取数据信息。
Cache
数据流向:CPU—> L1 cache —> L2 cache —> L3 cache —> 主存
数据查找:CPU先从L1 cache找,找到返回;找不到就L2 cache找,找到返回L1 cache和CPU,以此类推。
Cache Line
Cache由很多的cache line组成,通常64 btye。
CPU每次拉取数据时,会把相邻数据也拉取,存入同一个cache line。
伪共享
当我们有多个变量时,CPU读取时,会把他们放到同一个cache line,虽然这几个变量之前没有太多关系。不同CPU修改这几个变量时,都会导致之前读取的cache line失效。这样没有充分使用缓存行特性的现象,就是伪共享。
解释:
一个cache line可以被多个不同的线程使用,当其他线程修改了cache line中的一个数值时,其他线程将会强制重新加载cache line,虽然并没有修改其他数值,这是CPU对齐cache line导致的。
单CPU情景:
每个cache line读取一些数据,分多个cache line读取。
如果数据超了,会清除原来的数据,进行覆盖填写。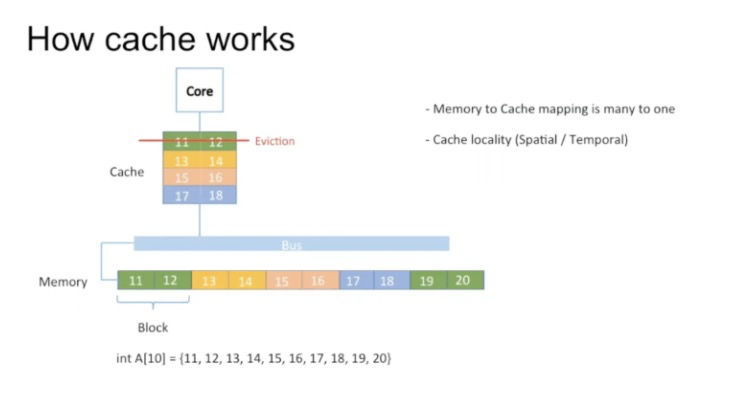
如果数据要修改,只需要对cache line中的数据进行修改即可。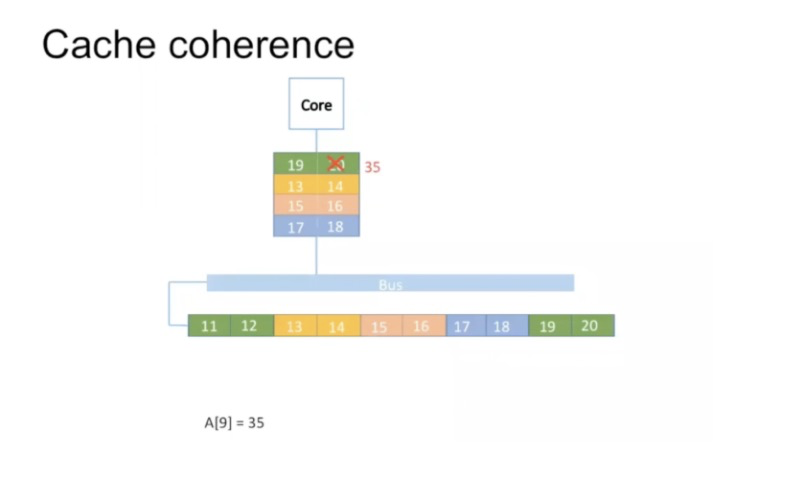
多核CPU:
当有多核CPU时,修改数据了,会造成其他CPU中缓存的数据也失效了。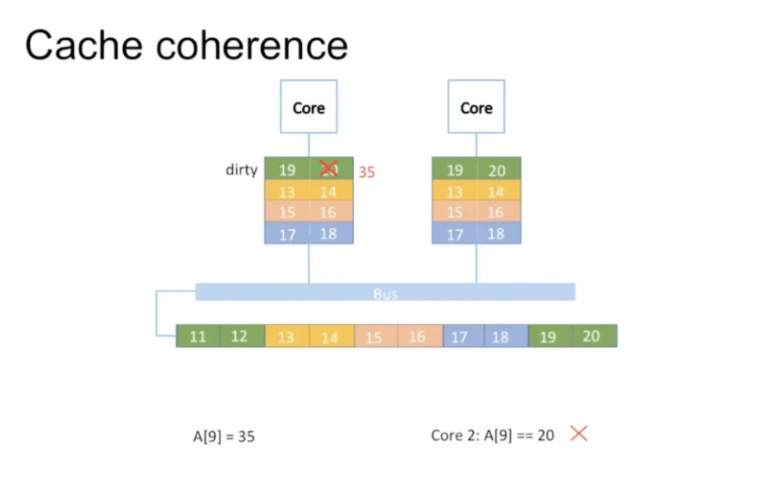
如果多核CPU进行数据修改,那么其他的核的数据会被设置为invalid。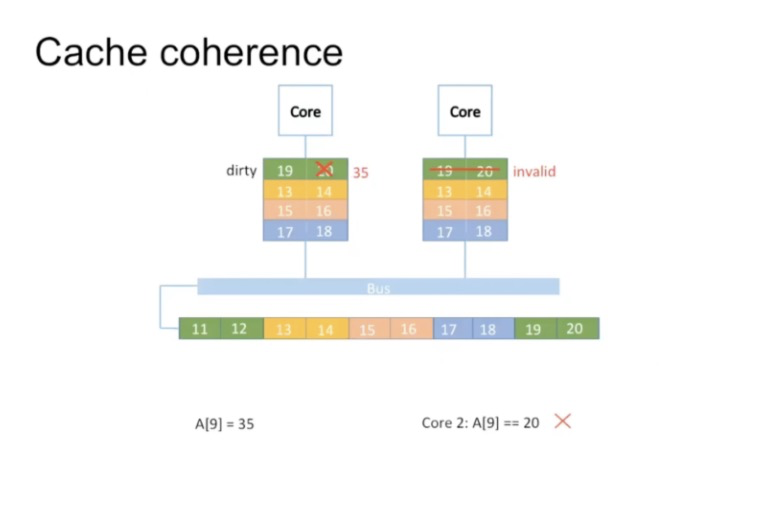
伪共享情况:
同时读取a和b时,cache line都被修改了,互相发生invalid,然后不断读取数据。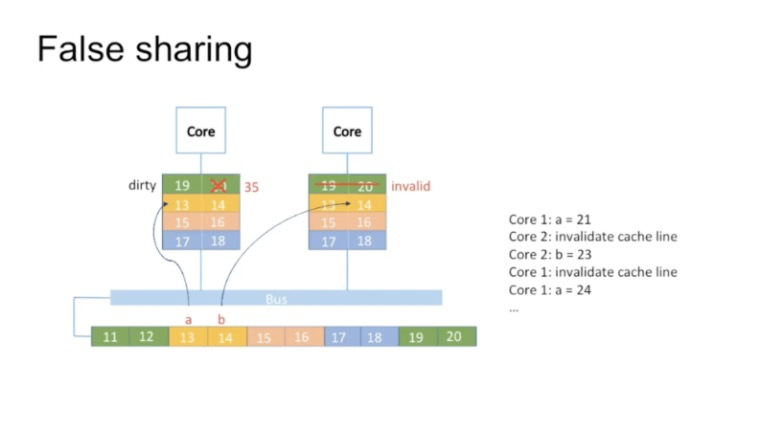
解决办法:Padding
为了减少false sharing,可以采取填充数据结构的形式,构造多个无用的数据,来填充凑够一个cache line。
解决办法:@Contended
Java8中引入了contended注解,可以让他们在不同的cache line。使用这个注解必须在 JVM 启动的时候加上 -XX:-RestrictContended 参数,其实也是用空间换取时间。
jdk6 --- 32 位系统下public final static class VolatileLong{public volatile long value = 0L;public long p1, p2, p3, p4, p5, p6; // 填充字段}jdk7 通过继承public class VolatileLongPadding {public volatile long p1, p2, p3, p4, p5, p6; // 填充字段}public class VolatileLong extends VolatileLongPadding {public volatile long value = 0L;}jdk8 通过注解@Contendedpublic class VolatileLong {public volatile long value = 0L;}
参考

若有收获,就点个赞吧
0 人点赞
