算完了beta, gamma后,可以用任意gradient descent优化法来优化,比如Momentum,Adam,RMSProp等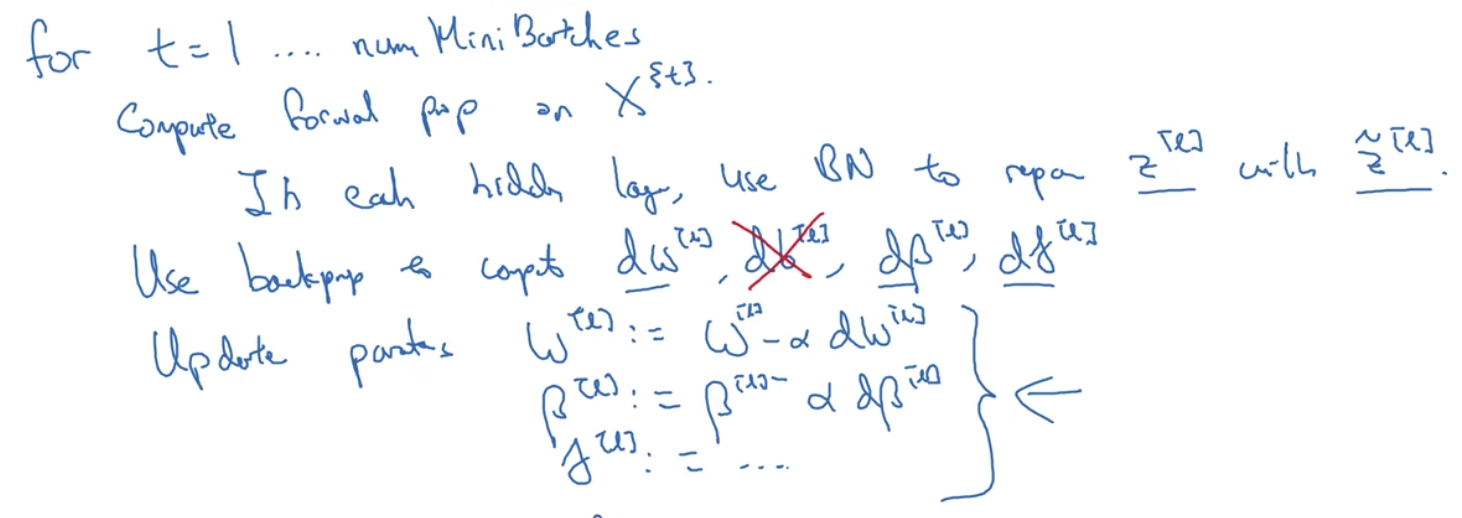
Batch Norm means that, especially from the perspective of one of the later layers of the neural network, the earlier layers don’t get to shift around as much, because they’re constrained to have the same mean and variance. And so this makes the job of learning on the later layers easier. 加速了学习速度
batch normalization有一点regularization副作用,因为它仅仅作用于一个mini batch而不是整个batch
batch normalization只是作用于training process中某一个Mini batch,所以test的时候是不一样的
为了测试,在训练的时候keep a running average of the mu and the sigma squared that you’re
seeing for each layer as you train the neural network across different mini batches.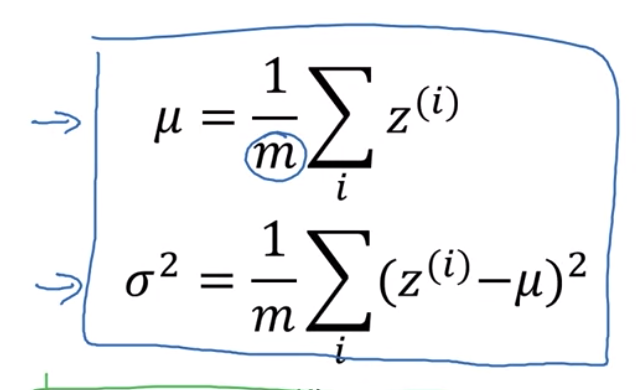
And then you would compute Z tilta on your one test example using that Z norm that we just computed on the left and using the beta and gamma parameters that you have learned during your neural network training process

若有收获,就点个赞吧
0 人点赞
