一、简介
Neo4j-CQL是声明性模式匹配语言,遵循SQL语法,简单可读,相关命令如下

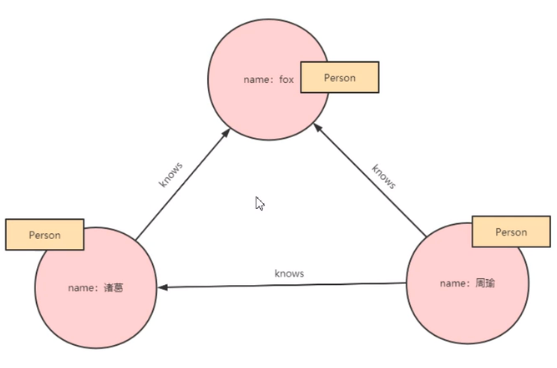
cypher语言描述实例
- 官方文档https://neo4j.com/docs/cypher-manual/current/clauses/
load csv:load csv from 'file:///name.csv' as linecreate (:labelName { from:line[a], relation:line[b], to:line[c]})- 将
Path路径下的csv文件按行读入,对每一行创建关系line[a]-[:line[b]]->line[c],标签为labelName name.csv应该放在D:\Neo4j\neo4j-community-3.5.31\import目录下
- 将
create:- 创建节点:
create (l:LabelName{property1:value1,...,propertyn:valuen})LabelName为标签名,property为属性名
- 创建关系:
create (nodeA)-[:RelationType{relation:value,...}]->(nodeB)- 创建节点
A和节点B之间的RelationType关系
- 创建节点
- 创建节点属于多个标签:
create (l:LabelNameA:LabelNameB:,...{property1:value1,...,propertyn:valuen})
- 创建节点:
match:- 查询节点:
match (l:LabelName) return l- 查询节点标签为
LabelName的所有节点
- 查询节点标签为
- 查询特定节点:
match (l:LabelName{property:value,...}) return l- 查询节点类型为
LabelName且满足property限制的节点 - 也可以使用
where关键字代替property限制match (l:LabelName) where l.property=value,... return l
- 查询节点类型为
- 查询关系:
match l=(:LabelName{property:value,...})->[r:RelationType]->() return l
- 查询节点:
return:- 在使用
match命令后,若需要将特定的property返回,则添加return关键字match (l:LabelName) return l.property,...- 在返回节点的
id时需要使用id(l)的方式,即match (l:LabelName) return id(l),因为id属性是由Neo4j自动创建的
- 在使用
delete:- 删除节点:
match(l:LabelName{l.property:value,...}) delete l- 如果当前删除的节点
l存在与其他节点的关系,则需要先删除对应的关系
- 如果当前删除的节点
- 删除关系:
match(lA:LabelName{lA.property:value,...})-[r:RelationType]->(lB:LabelName{lB.property:value,...}) delete r
- 删除节点:
skip, limit:limit n:限制只返回前n个结果skip n:限制忽略前n个结果
remove:- 删除属性:
match(l:LabelName{property:value,...}) remove l.property,... return l - 删除节点特定标签:
match(l:LabelName:...{property:value,...}) remove l:LabelName return l- 节点有多个标签时使用
- 删除属性:
set:- 修改属性值:
match(l:LabelName{property:value,...}) set l.property=value,... return l
- 修改属性值:
order by:- 按照
id排序:match(l:LabelName{property:value,...}) return l order by id(l) desc/asc - 按照特定属性排序:
match(l:LabelName{property:value,...}) return l order by l.property desc/asc
- 按照
null:- 根据特定属性是否为
null区分重名节点:match(l:LabelName{property:value,...}) where l.property is/is not null return l
- 根据特定属性是否为
in:- 查询属性在特定列表中的节点:
match(l:LabelName) where l.property in[valueA,...,valueN] return l
- 查询属性在特定列表中的节点:
index索引:- 创建索引:
create index on :LabelName(property)- 为标签
LabelName对应的节点的property属性添加索引
- 为标签
- 删除索引:
drop index on :LabelName(property)- 删除标签
LabelName对应的节点的property属性的索引
- 删除标签
- 创建索引:
unique约束:- 创建唯一约束:
create constraint on (l:LabelName) assert l.property is unique- 约束标签为
LabelName的节点的property属性必须唯一
- 约束标签为
- 删除唯一约束:
drop constraint on (l:LabelName) assert l.property is unique
- 创建唯一约束:
distinct:- 保证返回值不存在重复值:
match(l:LabelName) return distinct(l.property)
- 保证返回值不存在重复值:
-
三、常用函数
String字符串:用于使用String自变量upper:将所有字母换为大写lower:将所有字母换为小写substring:截取字符串match (l:LabelName) return substring(l.property, start, end)- 如
substring("abcde", 0, 2)->ab
- 如
replace:替换字符串中的特定字符
Aggregation聚合:用于对CQL查询结果执行一些聚合操作count:返回match结果行数match (l:LabelName) return count(l)
max:返回match结果行的最大值min:返回match结果行的最小值sum:返回match结果行的和avg:返回match结果行的平均值
Relationship关系:用于获取关系的细节,如startnode、endnode数据库备份:对数据进行备份,还原,迁移操作时要关闭
neo4jcd %NEO4J_HOME%/bin# 关闭 neo4jneo4j stop# 备份neo4j-admin dump --datebase=databaseName.db --to=/path/databaseName_backup.dump
数据库恢复:
# 数据导入neo4j-admin load --from=/path/databaseName_backup.dump --database=databaseName.db --force# 重启服务neo4j start

若有收获,就点个赞吧
0 人点赞
