Mapping:
商品索引结构:
PUT /career_plan_sku_index_15{"settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {"properties": {"skuId": {"type": "keyword"},"skuName": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"category": {"type": "keyword"},"basePrice": {"type": "integer"},"vipPrice": {"type": "integer"},"saleCount": {"type": "integer"},"commentCount": {"type": "integer"},"skuImgUrl": {"type": "keyword","index": false},"createTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"updateTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"}}}}
suggest索引
索引2:
PUT /career_plan_sku_suggest_15{"settings": {"number_of_shards": 3,"number_of_replicas": 1,"analysis": {"analyzer": {"ik_and_pinyin_analyzer": {"type": "custom","tokenizer": "ik_smart","filter": "my_pinyin"}},"filter": {"my_pinyin": {"type": "pinyin","keep_first_letter": true,"keep_full_pinyin": true,"keep_original": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"word1": {"type": "completion","analyzer": "ik_and_pinyin_analyzer"},"word2": {"type": "text"}}}}
package mainimport ("context""fmt""github.com/davecgh/go-spew/spew""github.com/olivere/elastic/v7""log""os")//https://www.cnblogs.com/gwyy/p/13356345.html 参数解释//tracelog 实现 elastic.Logger 接口type tracelog struct{}//实现输出func (tracelog) Printf(format string, v ...interface{}) {fmt.Printf(format, v...)}type Person struct {Name string `json:"name"`Age int `json:"age"`Married bool `json:"married"`}type Goods struct {SkuId int `json:"sku_id,omitempty"`SkuName string `json:"sku_name,omitempty"`Category string `json:"category,omitempty"`BasePrice float64 `json:"base_price,omitempty"`VipPrice int `json:"vip_price,omitempty"`SaleCount int `json:"sale_count,omitempty"`CommentCount int `json:"comment_count,omitempty"`SkuImgUrl string `json:"sku_img_url,omitempty"`CreateTime string `json:"create_time,omitempty"`UpdateTime string `json:"update_time,omitempty"`}func main() {client, err := elastic.NewClient(elastic.SetURL("http://127.0.0.1:9200"),elastic.SetInfoLog(log.New(os.Stdout, "", log.LstdFlags)),elastic.SetTraceLog(new(tracelog)))if err != nil {panic(err)}fmt.Println("connect es success", client)p1 := Person{Name: "lmh", Age: 18, Married: false}put1, err := client.Index().Index("user").BodyJson(p1).Do(context.Background())if err != nil {// Handle errorpanic(err)}fmt.Printf("Indexed user %s to index %s, type %s\n", put1.Id, put1.Index, put1.Type)spew.Dump(put1)// 批量操作//10001, 房屋卫士自流平美缝剂瓷砖地砖专用双组份真瓷胶防水填缝剂镏金色, 品质建材, 398.00, 上海, 540785126782//10002, 艾瑞泽手工大号小号调温热熔胶枪玻璃胶枪硅胶条热溶胶棒20W-100W, 品质建材,21.80, 山东青岛, 24727352473var AllGoods = []Goods{{SkuId: 10004,SkuName: "艾瑞泽手工大号小号调温热熔胶枪玻璃胶枪硅胶条热溶胶棒20W-100W",Category: "品质建材",BasePrice: 21.80,VipPrice: 0,SaleCount: 0,CommentCount: 0,SkuImgUrl: "www.baidu.com",CreateTime: "2022-02-22 22:22:22",UpdateTime: "2022-02-22 22:22:22",}, {SkuId: 10005,SkuName: "房屋卫士自流平美缝剂瓷砖地砖专用双组份真瓷胶防水填缝剂镏金色",Category: "品质建材",BasePrice: 398.00,VipPrice: 0,SaleCount: 0,CommentCount: 0,SkuImgUrl: "www.baidu.com",CreateTime: "2022-02-22 22:22:22",UpdateTime: "2022-02-22 22:22:22",}}bulkRequest := client.Bulk().Index("career_plan_sku_index_15")for _, goods := range AllGoods {// index 设置在bulk上 或者 设置在indexrequest上 都可以//doc := elastic.NewBulkIndexRequest().Index("career_plan_sku_index_15").Doc(goods)doc := elastic.NewBulkIndexRequest().Doc(goods)bulkRequest.Add(doc)}response, err := bulkRequest.Refresh("false").Do(context.Background())if err != nil {panic(err)}fmt.Println("response")spew.Dump(response)//failed := response.Failed()//l := len(failed)//if l > 0 {// fmt.Printf("Error(%d)", l, response.Errors)//}}
试试这个代码 是否可以 阻止 多个协成 降低 cpu
quit := make(chan bool)for i := 0; i < 100 ; i++ {go func() {for {select {case v,ok<-quit:if ok{dosomething}else{brek}}}}()}time.Sleep(time.Second * 15)for i := 0; i != 5; i++ {quit <- true}
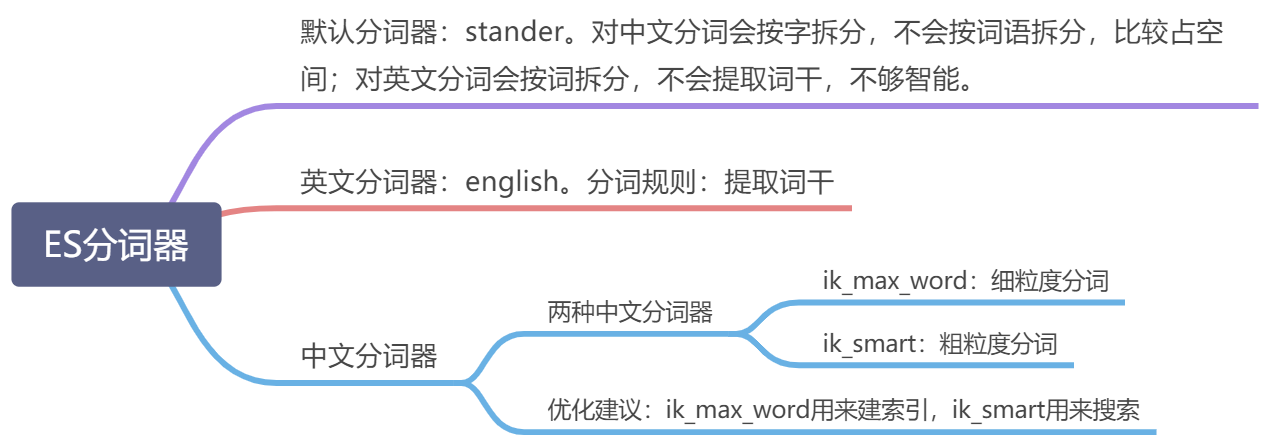
es 分词器
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
测试用法:
GET/POST /index_name/_analyze
GET /career_plan_sku_index_15/_analyze{"field": "name", //指定分词的字段"text": ["我是中国人"], // 需要被分词的内容文本"analyzer":"stander" // 指定分词器}POST _analyze{"field": "name","text": "我是中国人","analyzer": "english"}POST _analyze{"text":"eating","analyzer":"english"}
TODO: 创建索引时 指定字段的相关分词及分词器 的写法
查询内容时,可以指定分词器么?
suggest 分词 是要单独写一个 索引 还是在原来的索引上 添加即可

若有收获,就点个赞吧
0 人点赞
