Elasticsearch索引
为了创建倒排索引,通过分词器将每个文档的内容拆分成单独的词(词条Term),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档,
这种由属性值来确定记录的位置的结构就是倒排索引
带有倒排索引的文件称为倒排文件
核心术语:
词条(Term)
索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说指分词后的一个单词
词典(Term Dictionary)
是词条Term的集合,搜索引擎的通常索引单位是词条,单词词典时有文档集合中出现过所有单词构成的字符串集合,
单词词典内每条索引项记载单词本身的一些信息和指向“倒排列表”的指针
倒排列表(Post list)
一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置,
倒排项(Posting)
倒排表中的每条记录称为倒排项。倒排表记录的不单是文档编号,还存储了词频等信息
倒排文件(Inverted File)
所有单词的倒排列表往往顺序的存储在磁盘的某个文件里,这个文件被称为倒排文件,
倒排文件是存储倒排索引的物理文件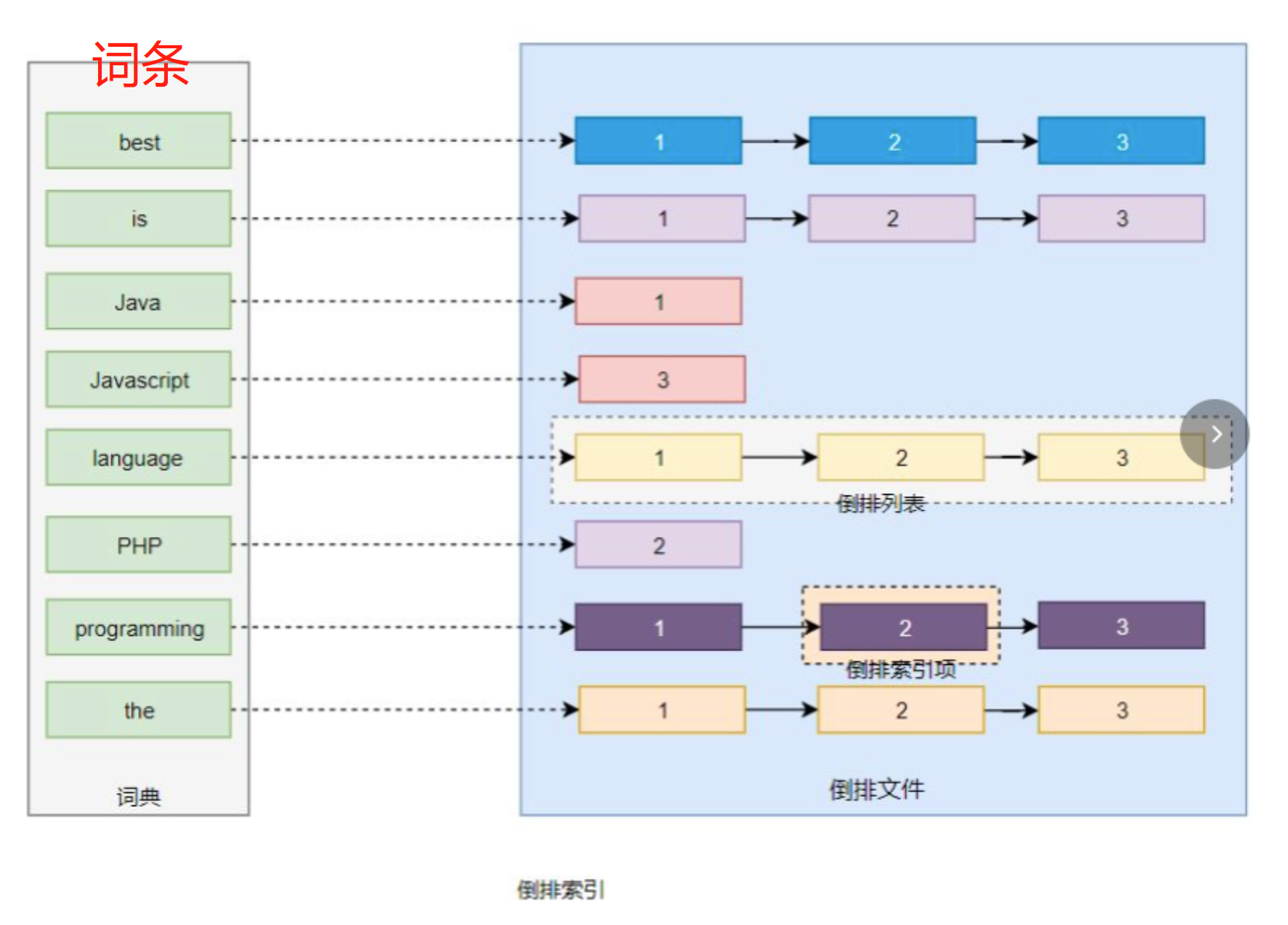
Elasticsearch分片
ES支持PB级全文搜索,当索引上的数据量太大的时候,ES通过水平拆分的方式将一个索引上的数据拆分出来分配到不同的数据块上,拆分出来的数据库块称之为一个分片,通过不同的分片规则访问不同的数据分片,从而提升ES的搜索的吞吐量
在一个多分片的索引中写入数据时,通过路由确定写入哪一个分片,所以在创建索引的时候需要指定分片的数量,并且分片的数量一旦确定就不能修改。如下图:5个分片和每个分片创建一个副本
Elasticsearch副本
副本就是分片的拷贝,一个主分片有一个或者多个副本分片,当主分片异常时,副本可以提供数据的查询等操作,
主分片和对应的副本分片在es集群部署时 是不会在同一个节点上的,所以副本分片数的最大值是N-1(N是节点数)
创建索引、创建文档、更新文档、删除文档这些请求都是写操作,必须在主分片上面完成后才能被复制到相关分片上
es为了提高写入的能力这个过程是并发写的,也就是说更新文档和删除文档不互斥,
es底层为了解决并发写的数据冲突问题,通过乐观锁的方式控制,每个文档都有一个_version的版本号
当文档被修改时版本号递增
一旦所有的副本分片都报告写成功才会向协调节点报告写操作成功,协调节点向客户端报告成功

若有收获,就点个赞吧
0 人点赞
