分布式缓存:
项目中缓存是如何使用的?
为什么要使用缓存?
主要俩用途,高性能、高并发
高性能:处理在大量复杂查询数据库比较耗时的结果,将查询到的数据缓存到redis中,后面请求都使用缓存中的数据即可,大量提升用户体验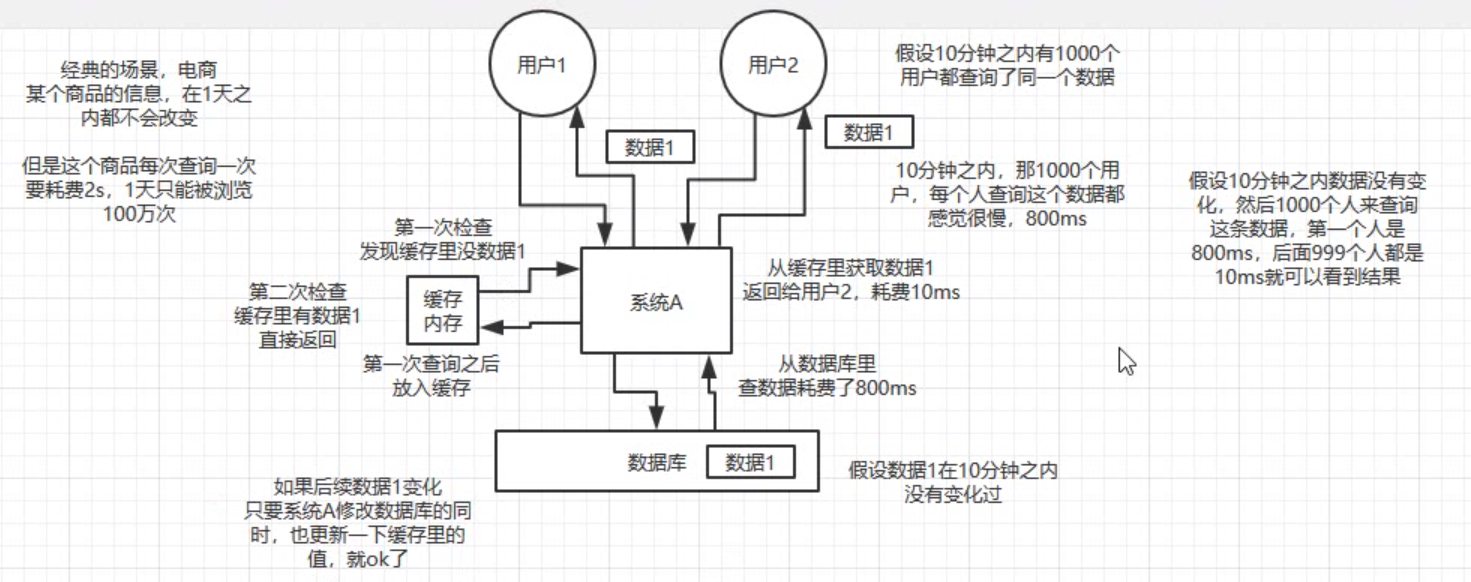
高并发:在高并发的场景下mysql 支持不了那么大的qps,可以把很多数据放在缓存中,少量放在mysq中 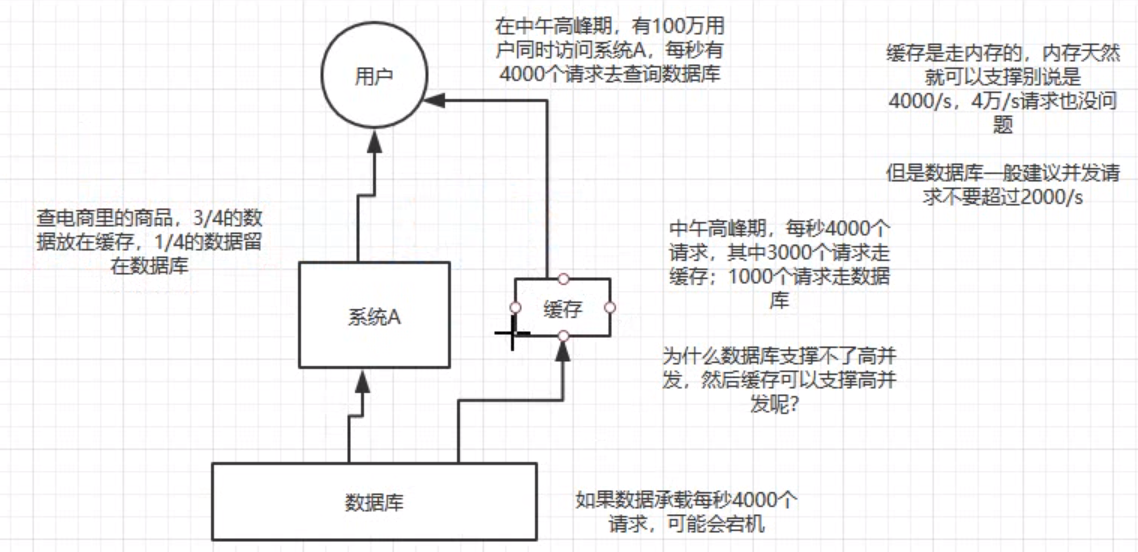
缓存使用不当会造成什么结果?(常见的缓存问题)
- 缓存与数据库双写不一致
- 缓存雪崩
- 缓存穿透
- 缓存并发竞争
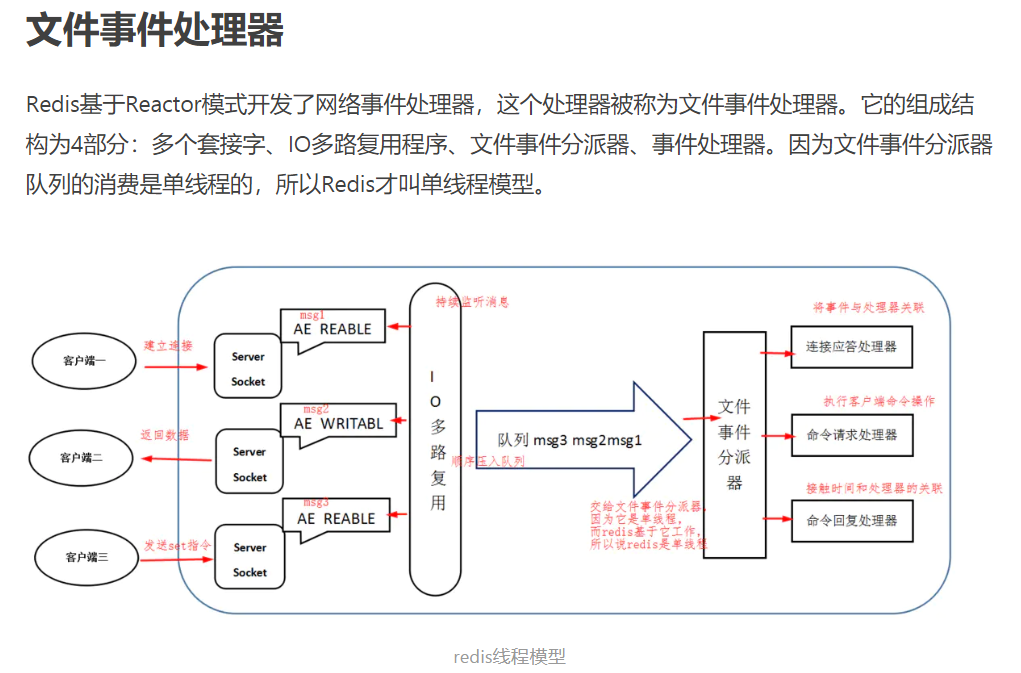
redis线程模型,为啥单线程还能有很高的效率?
纯内存操作、核心是基于非阻塞的IO多路复用机制epoll、单线程可以避免上限文切换问题
线程模型:单线程 nio同步非阻塞 线程模型
Reactor线程负责多路分离套接字,accept新连接,并分派请求到handler。Redis使用单Reactor单线程的模型

redis 与 memcached 主要区别
- redis 的 数据类型更多,支持的功能更多
- redis支持原生集群cluster模式,memcached不支持,需要客户端实现往集群分片中写入数据
redis都有哪些数据类型?分别在哪些场景下使用比较合适?
- string:key-value
hash: 类似map一种结构、可以将结构化数据放在缓存里,每次读写缓存可以操作hash里的某个字段
key=order:12345678value = {"name":haha,"city":北京}
list:有序列表
可以存储一些列表形式的数据、例如粉丝列表、文章评论列表 等
list = [zhangsan,lisi,wangwu,zhaoliu,zhengqi]通过lrange命令可以实现对粉丝的高性能分页查询也可以做类似微博下拉不断分页的东西也可以搞个简单的消息队列,头进 尾出
- set:无序集合、自动去重
对于某些数据进行全局去重,需要扔进redis 的set里面
也可以基于set 使用交集、并集、差集的操作,可以将两个人的粉丝好友整一个交集、查看共同好友
- sorted set:排序set、根据塞进去的分数进行排序 ,可以获取排名等
例如排行榜:
zadd board score usernamezrevrange board 0 99 获取前100名用户zrank borad username 可以查询到用户排名zadd board 85 li1zadd board 86 li2zadd board 87 li3zadd board 88 li4
redis 过期策略,内存淘汰机制,手写LRU
- 过期策略:
- 定期删除+过期删除
- 内存淘汰机制:
- 手写LRU:Least Recently Used
实现原理:一个双向链表+字典 (保证插入的有序(或说是借助列表来记录插入的顺序))
实现方式1:通过collections.OrderedDict类来实现,首先要说明的是OrderedDict是在普通字典的方法保证了插入的有序,同时要强调的是这个类还有一个特殊的方法popitem(Last=False),当Last参数为False时,说明其是以队列先进先出方式弹出第一个插入字典的键值对,而当Last参数为True时,则是以堆栈方式弹出键值对。
实现方式2:借助于普通dict和list来实现,其实就是自己来实现一个OrdereDict,保证插入的有序(或说是借助列表来记录插入的顺序)
from collections import OrderedDictclass LRUCache(OrderedDict):def __init__(self, size):self.size = sizeself.cache = OrderedDict()def get(self, key):if key in self.cache:value = self.cache.pop(key)self.cache[key] = valuereturn valueelse:return Nonedef set(self, key, value):if key in self.cache:self.cache.pop(key)self.cache[key] = valueelif self.size == len(self.cache):self.cache.popitem(last=False) # if last = false, FIFO order popself.cache[key] = valueelse:self.cache[key] = valuelru_test = LRUCache(5)lru_test.set("ha1",11)lru_test.set("ha2",12)lru_test.set("ha3",13)lru_test.set("ha4",14)lru_test.set("ha5",15)print(lru_test.cache.items())lru_test.get("ha2")print(lru_test.cache.items())lru_test.set("ha6",16)print(lru_test.cache.items())odict_items([('ha1', 11), ('ha2', 12), ('ha3', 13), ('ha4', 14), ('ha5', 15)])odict_items([('ha1', 11), ('ha3', 13), ('ha4', 14), ('ha5', 15), ('ha2', 12)])odict_items([('ha3', 13), ('ha4', 14), ('ha5', 15), ('ha2', 12), ('ha6', 16)])
# 基于普通dict和list实现class LRUCache:def __init__(self, size=5):self.size = sizeself.cache = {}self.key = []def get(self, key):if key in self.cache: # 获取k-v,如果key存在,则将key放到前面,并返回vself.key.remove(key)self.key.insert(0, key)return self.cache[key]else:return Nonedef set(self, key, value):if key in self.cache: # key 在缓存中,更新k-v,删除list中的该key,并插入list的头部self.cache.pop(key)self.cache[key] = valueself.key.remove(key)self.key.insert(0, key)elif len(self.cache) == self.size: # 如果当前缓存容量 等于 给定容量,则删除old_key,然后插入新k-vold_key = self.key.pop() # 删除list最后一个keyself.cache.pop(old_key) # 删除字典中得keyself.key.insert(0, key)self.cache[key] = valueelse: # key不存在,则直接存放self.cache[key] = valueself.key.insert(0, key)lru_test = LRUCache(5)lru_test.set("ha1", 11)lru_test.set("ha2", 12)lru_test.set("ha3", 13)lru_test.set("ha4", 14)lru_test.set("ha5", 15)print(lru_test.key)lru_test.get("ha2")print(lru_test.key)lru_test.set("ha6", 16)print(lru_test.key)['ha5', 'ha4', 'ha3', 'ha2', 'ha1']['ha2', 'ha5', 'ha4', 'ha3', 'ha1']['ha6', 'ha2', 'ha5', 'ha4', 'ha3']
redis如何通过读写分离承载读请求qps超过10W+?
redis单机高并发请求也就达到几万,当10w+打到单机上肯定会挂掉的
解决方法:主从架构读写分离,对缓存一般都是用来支持读高并发的,写比较少
主从架构:一主多从,主写从读,主将数据同步复制到从节点,所有读请求全部走从节点,写请求写master
每台从机器可以承载几万,多个从机器就可以承载几十万,可以水平扩容,增加机器就可以应对更高的并发
主从架构->读写分离-> 支撑10W+读qps请求
redis replication 复制以及master持久化对主从架构的安全意义?
master一定要开持久化rdb和aof,否则一旦宕机,所有数据清空丢失
redis 主从复制原理
断点续传
master里面有一个backlog ,master和slave里面都有保存一个复制的offset,如果没有记录offset则就传一遍全量,有的话,就从上一次的offset处进行开始同步
无磁盘化复制
就是master向slave同步数据的时候,要不要写rdb文件,默认是无磁盘化的,就是写在内存中的,直接发送给slave,也可以打开,就是先写rdb再发给slave
过期key处理
slave是没有key过期自动处理机制的,依靠master的key过期后发送给slave对应的删除命令
redis 高可用:
使用 哨兵机制 建立主从同步集群从切换 实现redis 高可用
sentinal 哨兵
哨兵是redis集群架构中非常重要的组件
- 集群监控:负责监控redis maser和slave进程是否正常工作
- 消息通知:如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
- 故障转移:如果master node 挂掉了,会自动转移到slave node上
- 配置中心,如果故障转移发生了,通知client客户端新的master地址

若有收获,就点个赞吧
0 人点赞
