Training
Changing Landscape
之前的修改learning rate的方法是为了在training过程中进行的更好,本方法是为了在training之前使得Error surface在可预计的范围内更加平整,更加容易进行训练。
如上图,左边的error surface在开始训练的时候横轴和纵轴的方向上,因为参数量级的不同,在training的过程中即使w修改的幅度很小,在两个方向上的变化量也会很不同,甚至天差地别,这个时候搞清楚了error surface形成上图左边的原因,就可以针对性的进行修改。上述这种对原始数据进行修改,却不改变最终结果的方式即被称为Feature Normalization。
Feature Normalization
最直觉的对原始参数的修改方法,便是标准化。既可以使原始参数处于一个量级,还不改变原参数的特征。
如上图, 到
到 %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-78%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-52%22%20x%3D%22809%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=x%5ER&id=GALaT)为所有的训练资料的feature vector,上图绿框中即为同等指标的数据,即一开始那张图中的100,200等数据。标准化公式如下:
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-78%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-52%22%20x%3D%22809%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=x%5ER&id=GALaT)为所有的训练资料的feature vector,上图绿框中即为同等指标的数据,即一开始那张图中的100,200等数据。标准化公式如下:
其中: 表示第i行的训练资料的均值。
表示第i行的训练资料的均值。
 表示标准差(standard deviation)
表示标准差(standard deviation)
然后按照上述公式,将每一行的新的数值填回训练资料,接下来训练的时候就会有如下好处:
- 数据normalize以后dimension(绿框这一行值)的训练资料平均数会变为0,variance(方差)会变为1,整一行数据会在0上下浮动。
- 对所有的dimension进行normalization以后,所有数值都会处于一个量级,更容易制造平缓的error surface。
Considering Deep Learning
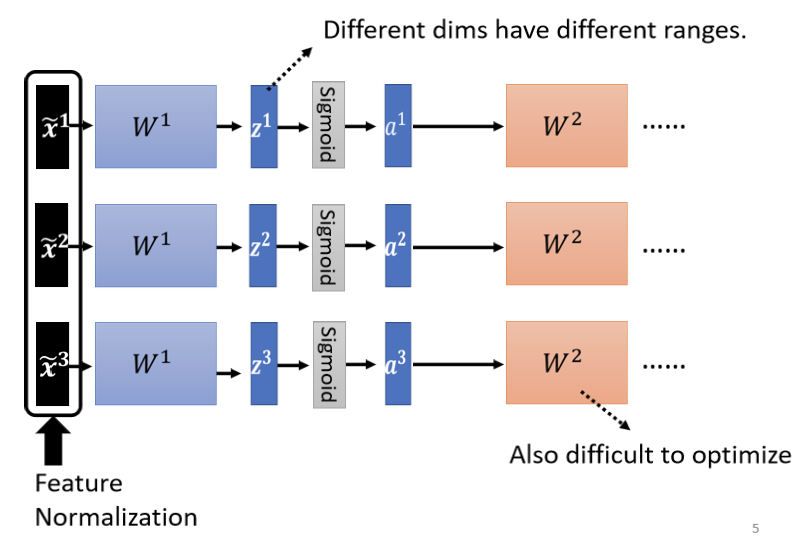
如上图,整个横向结构为深度学习的不同层,因为后面的层数需要运用前面的层数的输出作为输入,黑框里面的数据进行标准化后,经过训练得出Z的值必然分布不会均匀,经过sigmoid函数后a的值同样不会均匀。故在中间层仍需进行一次标准化,至于在Z还是a处进行标准化,由模型的性质决定。
若中间是sigmoid函数,则推荐在Z进行标准化,因为sigmoid函数在0附近,斜率变换幅度最大,如下图: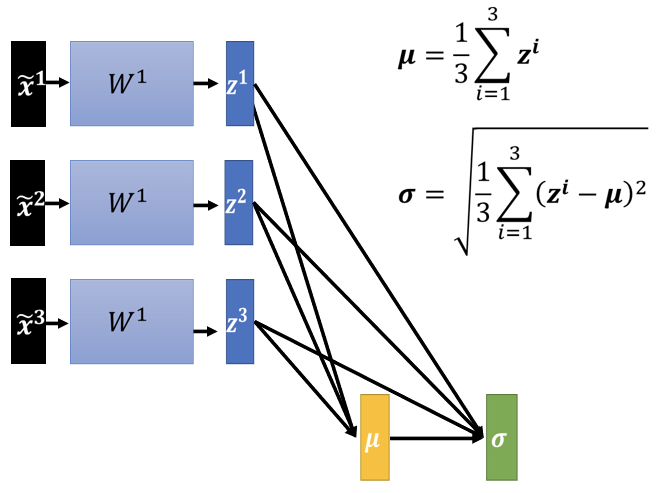

如上图进行input的标准化,其中有一个问题,之前的 是根据dimension进行的标准化,此处的标准化使得input的数值有了关联。即只要改变z中的任意一个值,本次的标准化都会不同,故此处的标准化应该是收集一整个process中的数据然后计算
是根据dimension进行的标准化,此处的标准化使得input的数值有了关联。即只要改变z中的任意一个值,本次的标准化都会不同,故此处的标准化应该是收集一整个process中的数据然后计算 。
。
实际操作中因为要一个batch一个bacth训练,故第二次标准化仅针对每一个batch进行操作。即Batch Normalization__,因为方法的特性故这种处理方法仅在batch size比较大的情况下进行。即batch size足够大,里面的data就足以表示整个corpus的分布,原本准备对整个corpus做的Feature Normalization,改成只在一个batch做Feature Normalization,作为approximation。
如上图,在实际的深度学习中在计算出 后通常还会乘以
后通常还会乘以 再加上
再加上 ,其中
,其中 、
、 均为向量,故运算过程中进行的是element wise(对应元素相乘)。
均为向量,故运算过程中进行的是element wise(对应元素相乘)。 、
、 这两个参数也是在训练过程中被learn出来的。
这两个参数也是在训练过程中被learn出来的。
进行如上操作的原因是:
做normalization以后 的平均值一定是 0,考虑到平均值是0的情况可能会给network一些限制,这个限制可能会带来某些负面的影响,所以把
的平均值一定是 0,考虑到平均值是0的情况可能会给network一些限制,这个限制可能会带来某些负面的影响,所以把 、
、 加回去,然后让network自己学习,如果hidden layer的output平均不是0,模型自己去调整输出的分布,调整Z的分布。
加回去,然后让network自己学习,如果hidden layer的output平均不是0,模型自己去调整输出的分布,调整Z的分布。
之前做Batch Normalization是目的为了要让每一个不同的dimension的range都一样,现在对标准化的参数进行操作,有可能会对相同dimension的range有影响。故作如下解释:
实际上在训练的时候, 、
、 的初始值有如下约定:
的初始值有如下约定:
 的初始值设為 1,即全部都是 1 的向量
的初始值设為 1,即全部都是 1 的向量 的初始值是都是0的向量
的初始值是都是0的向量
故network在一开始训练的时候,每一个dimension 的分布是比较接近的,也许训练到后来,模型在训练足够长的时间后,已经找到一个比较好的error surface,在参数更新到比较合适的情况下,再把 、
、 加进去。
加进去。
Testing
testing的部分这个操作又被称作inference__。
假设你真的有系统上线,你是一个真正的线上的 application,比如说你的 batch size 设 64,我一定要等 64 笔资料都进来,我才一次做运算吗,这显然是不行的。
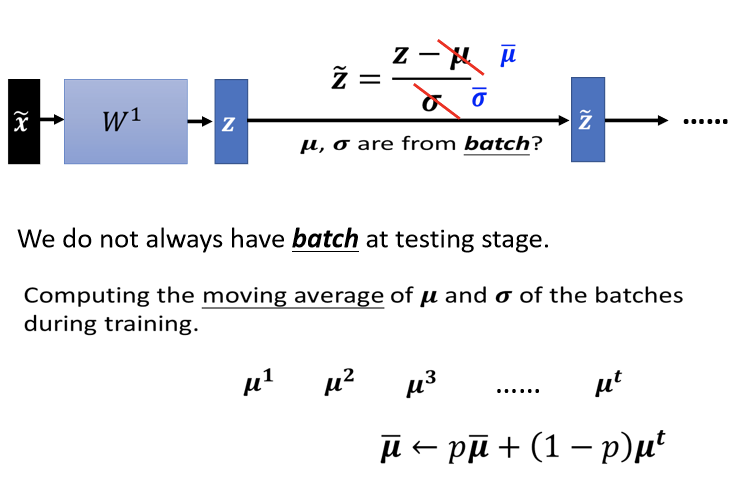
如果在training的时候进行过标准化,则在这个过程中,每次计算 的时候都进行一次moving average。
的时候都进行一次moving average。
每一次取一个 batch 出来的时候会算一个
,取第二个batch出来的时候,会计算
,以此类推。 接下来会算 moving average,会把现在算出来的
的一个平均值,叫做
,乘上某一个 factor,那这也是一个constant(常数),这也是hyper parameter。 在 PyTorch 裡面,这个值设 0.1,然后加上 1 减 P乘上
,然后来更新
的平均值,最后会在 testing的时候使用这个值。 因为testing的时候,在真正的application上,不会有batch操作,故直接使用
,也就是在训练的时候,得到的moving average,这就是Batch Normalization在testing时候的运作方式。
Comparison
下图是从Batch Normalization原始的文件上面截出来的一个实验结果,在原始的文件上还讲了很多其他的东西,举例来说,Batch Normalization 用如何运用在 CNN 上。
这个是原始文献上面截出来的一个数据
- 横轴呢代表的是训练的过程,纵轴代表的是 validation set 上面的 accuracy
- 黑色的虚线是没有做 Batch Normalization 的结果,它用的是 inception 的 network,是以 CNN 为基础的 network 架构
- 做了Batch Normalization,会得到红色的这一条虚线,它训练的速度,显然比黑色的虚线还要快很多,只要给它足够的训练的时间,两个结果可能都跑到差不多的 accuracy,但是红色这一条虚线,可以在比较短的时间内就跑到一样的 accuracy
- 粉红色的线是 sigmoid function,因为 sigmoid function的 training 是比较困难的,上图想要强调的点是说,就算是 sigmoid 比较难搞的,假如进行Batch Normalization,还是 train 的起来。作者有提到sigmoid 不加 Batch Normalization,根本连 train 都 train 不起来
- 蓝色的实线跟这个蓝色的虚线,是把 learning rate 设大一点。乘5就是 learning rate 变原来的 5 倍,如果做Batch Normalization 的话,error surface会比较平滑,比较容易训练,所以可以把learning rate设大一点,这边有个不好解释的奇怪的地方,就是不知道为什么,learning rate 设 30 倍的时候比 5 倍差,作者也没有解释具体原因。Emmmm大家都知道的,deep learning有时候会產生这种怪怪的,不知道怎麼解释的现象,玄学的很。
To learn more……
其实Batch Normalization,不是唯一的normalization,normalization 的方法有很多,下边是列出了比较知名的描写normalization的Paper。
Batch Renormalizationhttps://arxiv.org/abs/1702.03275Layer Normalizationhttps://arxiv.org/abs/1607.06450Instance Normalizationhttps://arxiv.org/abs/1607.08022Group Normalizationhttps://arxiv.org/abs/1803.08494Weight Normalizationhttps://arxiv.org/abs/1602.07868Spectrum Normalizationhttps://arxiv.org/abs/1705.10941

若有收获,就点个赞吧
0 人点赞
