- https://zhuanlan.zhihu.com/p/377433737">https://zhuanlan.zhihu.com/p/377433737
- https://zhuanlan.zhihu.com/p/75288695">https://zhuanlan.zhihu.com/p/75288695
- https://blog.csdn.net/lln_avaj/article/details/59636647">https://blog.csdn.net/lln_avaj/article/details/59636647
- https://elasticsearch.cn/question/8090">https://elasticsearch.cn/question/8090
https://zhuanlan.zhihu.com/p/377433737
二 、ik分词器2种模式
ik_smart 最粗粒度的拆分
ik_max_word 最细粒度的拆分
它们其实就是2中分词算法,其区别直接通过测试观察
三、测试
ik_smart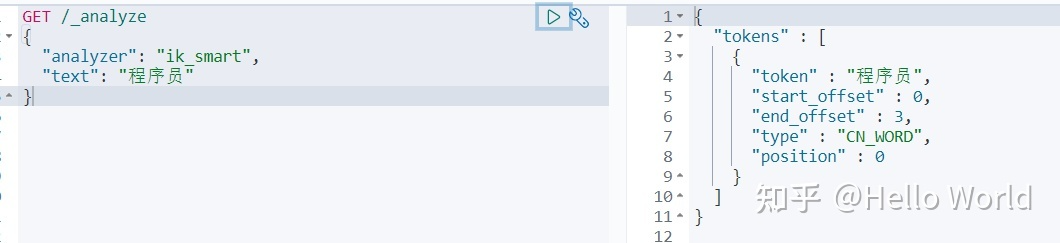
ik_max_word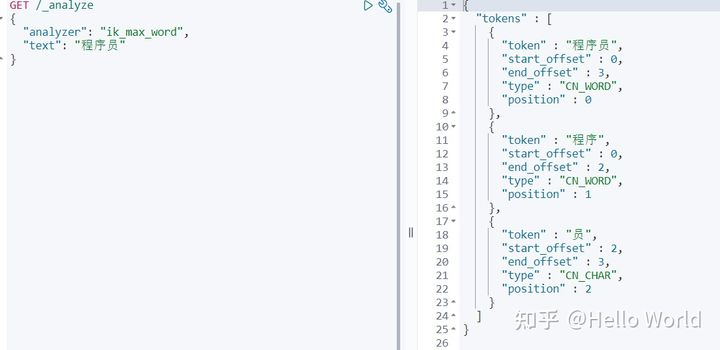
可以看出 ik_max_word 比 ik_smart 划分的词条更多,这就是它们为什么叫做最细粒度和最粗粒度。
四、自定义字典
问题:如何把 金毛狮王 拆分成“金毛”“狮王”“金毛狮王”三个词条?
默认2种模式都会拆分成 “金”“毛”“狮王”三个词条。不符合我们的要求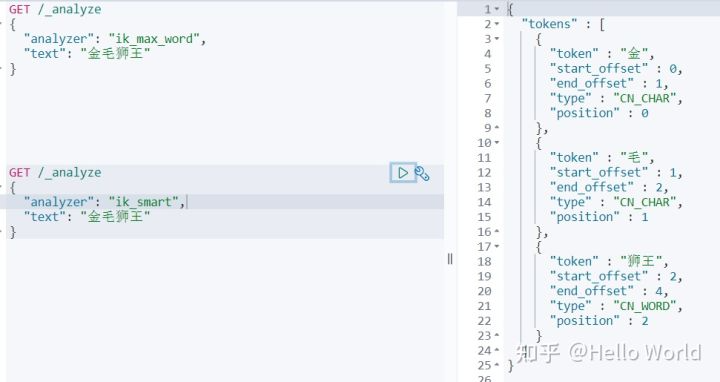
根据默认拆分的结果,发现我们需要增加“金毛”和“金毛狮王”2个词条并删除“金”和“毛”2个词条。这里就可以用自定义字典来实现
打开 ..\elasticsearch-7.12.1\plugins\ik\config\IKAnalyzer.cfg
可以看到有2个配置 ext_dict 和 ext_stopwords。分别是扩展和停用字典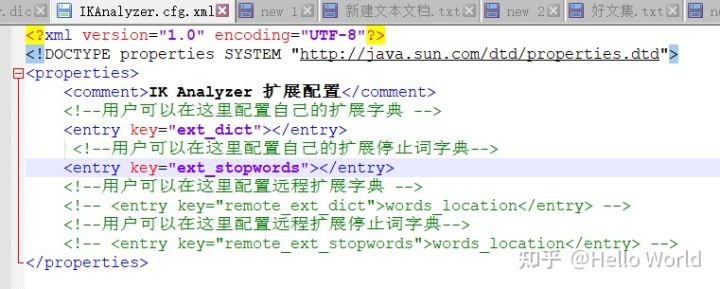
参照默认的dic文件,在config目录新建 my_ext.dic 和 my_stop.dic
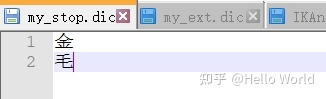
然后配置到 IKAnalyzer.cfg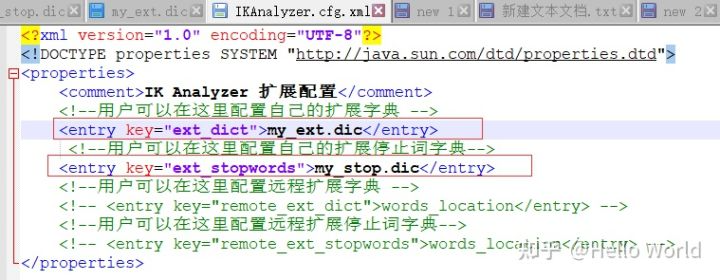
重启ES。启动日志可以看到加载了我们的字典
测试
ik_max_word 正是我们想要的效果
ik_smart 只有金毛狮王一个词条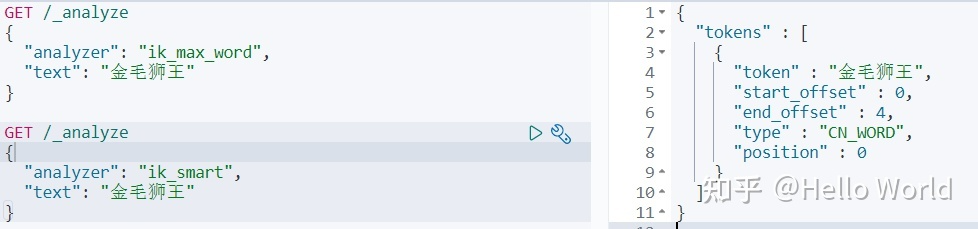
注意:配置好重启后可能发现并没有效果,不慌,检查下文件的编码格式是否UTF-8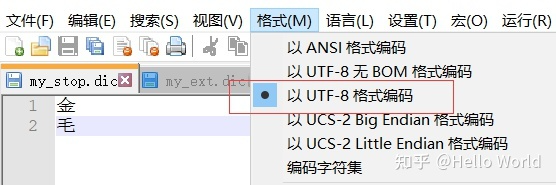
https://zhuanlan.zhihu.com/p/75288695
一、ElasticSearch Index Settings
https://blog.csdn.net/lln_avaj/article/details/59636647
1)standard分词器
es默认的分词器,对中文支持不友好,会将中文分成单字,这样在查询多个汉字时就匹配不到doc,所以针对中文字段可使用ik
2)ik分词器
需要单独安装ik插件,有ik_smart和ik_max_word两种分词粒度,其中ik_max_word粒度更细,但如果ik识别不出的词,就不会分出导致上边的全局检索例子查询“西”时匹配不到数据
3)pinyin分词器
需要安装插件,可支持拼音全拼、简拼和首字母查询
https://elasticsearch.cn/question/8090
ES可不可以在一个字段中指定多个分词器 - Elastic 中文社区

若有收获,就点个赞吧
0 人点赞
