代码
项目地址:https://github.com/xingstarx/crawl-zsxq
import reimport requestsimport jsonimport osimport pdfkitconfig = pdfkit.configuration(wkhtmltopdf=r"C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe")from bs4 import BeautifulSoupfrom urllib.parse import quotehtml_template = """<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"></head><body><h1>{title}</h1><p>{text}</p></body></html>"""htmls = []num = 0def get_data(url):global htmls, numheaders = {'Authorization': '33A1AD5E-D03C-6EE9-1E8C-DDF321294280','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'}rsp = requests.get(url, headers=headers)with open('test.json', 'w', encoding='utf-8') as f: # 将返回数据写入 test.json 方便查看f.write(json.dumps(rsp.json(), indent=2, ensure_ascii=False))with open('test.json', encoding='utf-8') as f:for topic in json.loads(f.read()).get('resp_data').get('topics'):content = topic.get('question', topic.get('talk', topic.get('task', topic.get('solution'))))# print(content)text = content.get('text', '')text = re.sub(r'<[^>]*>', '', text).strip()text = text.replace('\n', '<br>')title = str(num) + text[:9]num += 1if content.get('images'):soup = BeautifulSoup(html_template, 'html.parser')for img in content.get('images'):url = img.get('large').get('url')img_tag = soup.new_tag('img', src=url)soup.body.append(img_tag)html_img = str(soup)html = html_img.format(title=title, text=text)else:html = html_template.format(title=title, text=text)if topic.get('question'):answer = topic.get('answer').get('text', "")soup = BeautifulSoup(html, 'html.parser')answer_tag = soup.new_tag('p')answer_tag.string = answersoup.body.append(answer_tag)html_answer = str(soup)html = html_answer.format(title=title, text=text)htmls.append(html)next_page = rsp.json().get('resp_data').get('topics')if next_page:create_time = next_page[-1].get('create_time')if create_time[20:23] == "000":end_time = create_time[:20]+"999"+create_time[23:]else :res = int(create_time[20:23])-1end_time = create_time[:20]+str(res).zfill(3)+create_time[23:] # zfill 函数补足结果前面的零,始终为3位数end_time = quote(end_time)if len(end_time) == 33:end_time = end_time[:24] + '0' + end_time[24:]next_url = start_url + '&end_time=' + end_timeprint(next_url)get_data(next_url)return htmlsdef make_pdf(htmls):html_files = []for index, html in enumerate(htmls):file = str(index) + ".html"html_files.append(file)with open(file, "w", encoding="utf-8") as f:f.write(html)options = {"user-style-sheet": "test.css","page-size": "Letter","margin-top": "0.75in","margin-right": "0.75in","margin-bottom": "0.75in","margin-left": "0.75in","encoding": "UTF-8","custom-header": [("Accept-Encoding", "gzip")],"cookie": [("cookie-name1", "cookie-value1"), ("cookie-name2", "cookie-value2")],"outline-depth": 10,}try:pdfkit.from_file(html_files, "电子书.pdf", options=options)except Exception as e:#passprint(e)for file in html_files:os.remove(file)print("已制作电子书在当前目录!")if __name__ == '__main__':start_url = 'https://api.zsxq.com/v1.10/groups/5825251554/topics?scope=digests&count=20'make_pdf(get_data(start_url))
效果

遇到的坑
1.No wkhtmltopdf executable found: “b’’”
python中需要安装wkhtmltopdf模块
然后windows系统中还要安装wkhtmltopdf软件
下载地址:https://wkhtmltopdf.org/downloads.html
2.找关键信息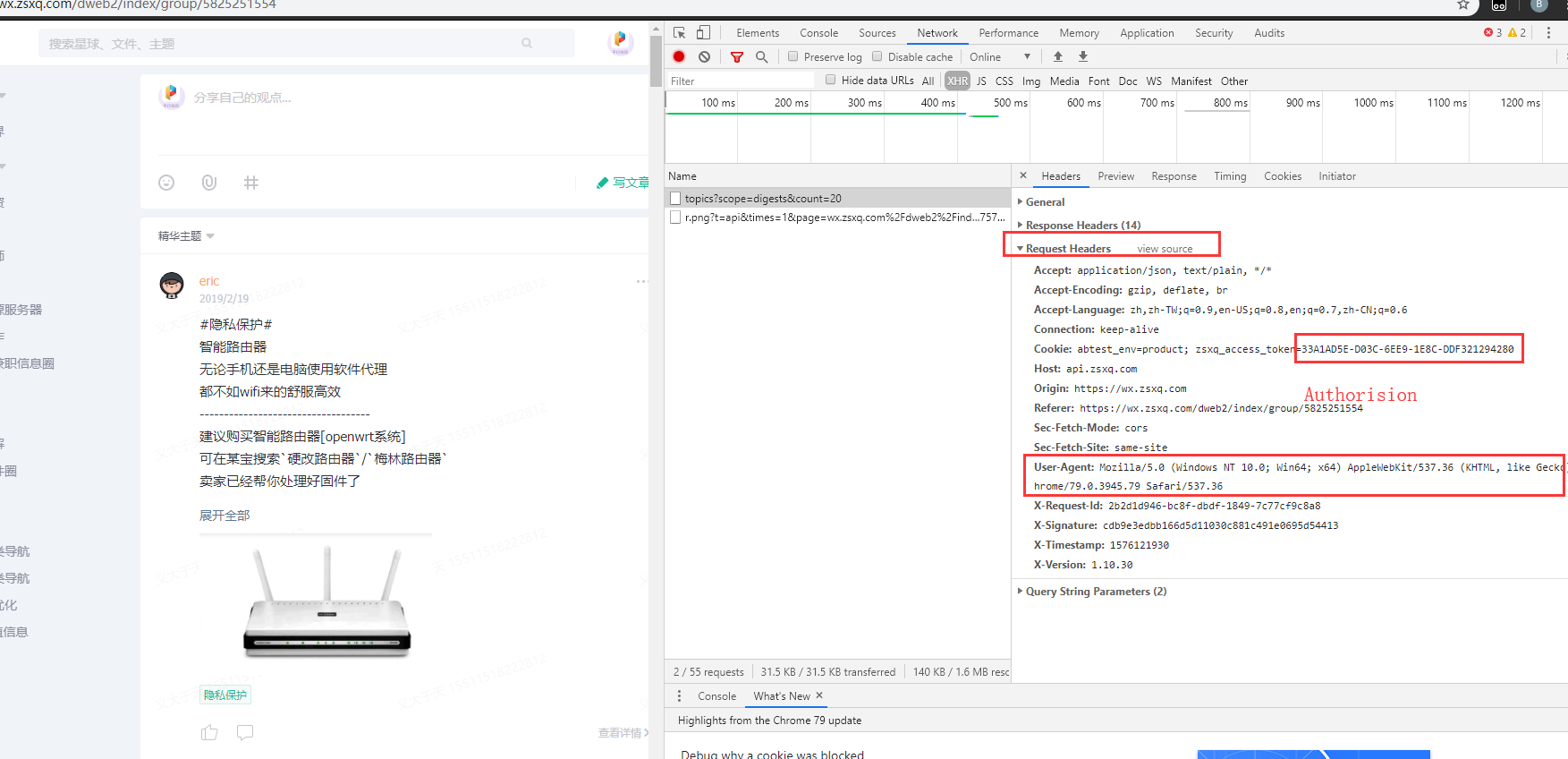
以管理员方式运行pycharm

若有收获,就点个赞吧
0 人点赞
