在IDLE中执行下面代码,中文显示正常:
# -- coding:utf-8 --
st=raw_input(“请输入内容”)
print st
但在CMD中执行e:\hello.py,则中文会出现乱码,是什么原因呢?
从下图可以看出utf-8和gbk都可以通过编码和解码与unicode进行转换,那么如果utf-8转化为gbk该怎么办呢?首先,utf-8通过解码转化为unicode,然后通过unicode编码转化为gbk
现在回答上面的问题,为什么CMD会出现乱码呢?这是因为我们写的py程序是utf-8编码的,通过python程序编译后,也是编译为utf-8编码,而这时cmd是通过gbk进行解析的,gbk解析utf-8,当然会出现乱码了。
知道原因后,我们来看解决方案:
1、2.7中把程序中的汉字转为gbk编码:
# -*- coding:utf-8 -*-concent = "请输入内容:"#将字符串由utf-8解码为unicodec_unicode = concent.decode("utf-8")#将解码后的字符串编码为gbkc_gbk = c_unicode.encode("gbk")st=raw_input(c_gbk)print st
其实只需要把utf-8转化为unicode编码就可以,因为当windows的CMD遇到unicode编码时,会自动给你转化为gbk编码,所以程序也可以这样:
# -*- coding:utf-8 -*-concent = "请输入内容:"#将字符串由utf-8解码为unicodec_unicode = concent.decode("utf-8")st=raw_input(c_unicode)print st
另外python3x中没有unicode类型,但可以支持从utf-8直接解码转换为gbk,代码如下:
# -*- coding:utf-8 -*-concent = "请输入内容:"#将字符串由utf-8解码为gbkc_gbk = concent.decode("gbk")st=raw_input(gbk)print(st)
2、将CMD终端改为UTF-8格式
命令介绍:
chcp 65001 #换成utf-8代码页
chcp 936 #换成默认的gbk
chcp 437 #美国英语
一般默认为gbk,若要修改成 utf-8,则需要:
1)、cmd窗口输入:
chcp 65001
2)、修改cmd属性:
选择字体为“Lucida Console”
3、改为UTF-8后可能出现字符重叠或不能输入中文的现象,调整回GBK格式的方法
1.右击cmd窗口,点默认值。
在选项中默认代码页,选择936。
2.

在cmd中输入:
chcp 936
注:chcp命令用于显示或设置活动代码页编号。

3. 新建文本,复制粘贴以下代码,把文件类型改成reg :Windows Registry Editor Version 5.00 [HKEY_CURRENT_USER\Console\%SystemRoot%_system32_cmd.exe] “CodePage”=dword:000003a8
之后双击运行。点是。
4. 运行regedit,打开注册表。
在HKEY_CURRENT_USER\Console\%SystemRoot%_system32_cmd.exe中找到CodePage。
双击打开CodePage,输入3a8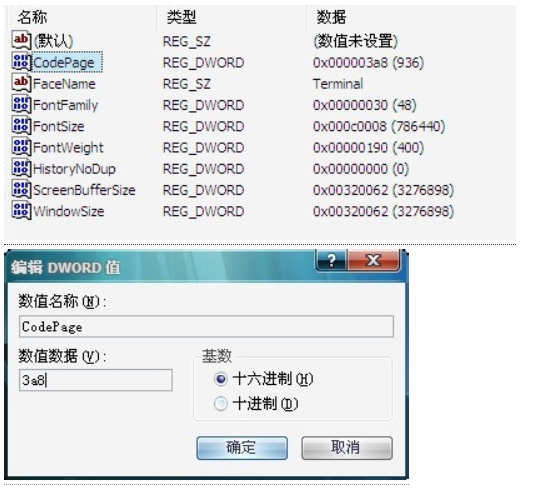

若有收获,就点个赞吧
0 人点赞
