# https://blog.csdn.net/qq_40821402/article/details/88178359from lxml import htmlimport timefrom selenium import webdriverimport reimport csvimport pymysqlclass Demo:comment_list = [] # 定义评论列表文件writer_list = [] # 定义评论者列表# 写入数据库conn = pymysql.connect(host='localhost' ,user = 'root',passwd = 'root',db= 'wyy' ,charset = 'utf8mb4')curs = conn.cursor()def __init__(self,browser,url):self.browser = browsertime.sleep(2)self.browser.get(url)self.browser.implicitly_wait(65)try:self.browser.switch_to.frame('contentFrame') # 进入frameexcept Exception as e:print(e)def all_pages(self):etree = html.etreehtmls = self.browser.page_sourcecodes = etree.HTML(htmls)texts = codes.xpath("//a[@href='#']")# for te in texts: #记录一下总的文本数量13个#print(te.text)s = 4while (s<=13):pa = texts[len(texts) - s].textif pa == None:s = s+1else:last_page = int(pa)return last_pagedef get_comment(self, pages):for x in range(pages): #64是需要抓取的页面总数***button = self.browser.find_element_by_link_text('下一页') # 通过找到‘下一页’的按钮进行翻页time.sleep(2)# print(button.text)aa = self.browser.find_elements_by_xpath('//div/div[2]/div[1]/div[1]') # 定位评论文字for i in aa:# print(i.text)a = re.search(':', i.text) # 通过正则表达式进行“:”定位,得出左边是评论者,这个要去掉# print(a)if a:n = i.text.index(':') + 1writ = i.text[:n].replace(':', '') # 只保留从“:”左边的文字,就是纯正的作者名comm = i.text[n:] # 只保留从“:”右边的文字,就是纯正的评论文字self.curs.execute("insert into data (writer,comment) values (%s,%s) " ,(writ, comm))self.conn.commit()else:#comment_list.append('')print('')self.conn.commit()print('抓取了>>>>' + str(x+1) + '<<<<页')try :button.click() # 自动进行“下一页”的按钮except Exception as e:print(e)if __name__ == '__main__':id = open('F:/music/网易云音乐歌曲信息.csv', 'r', encoding='utf-8-sig')id_reader = csv.DictReader(id)columns = [row for row in id_reader]#columns = [439646311,1348918118,541076059,1303464240] # 测试切换idchrome_options = webdriver.ChromeOptions()prefs = {"profile.managed_default_content_settings.images": 2}chrome_options.add_experimental_option("prefs", prefs)browser = webdriver.Chrome(options= chrome_options)for id_new in columns:new_id = id_new['id']url = 'https://music.163.com/#/song?id=' + str(new_id) # 测试的时候换成id_newdd = Demo(browser=browser, url = url)pages = dd.all_pages()dd.get_comment(pages)print('********************************进入下一个************************************')time.sleep(3)dd.browser.close()
效果图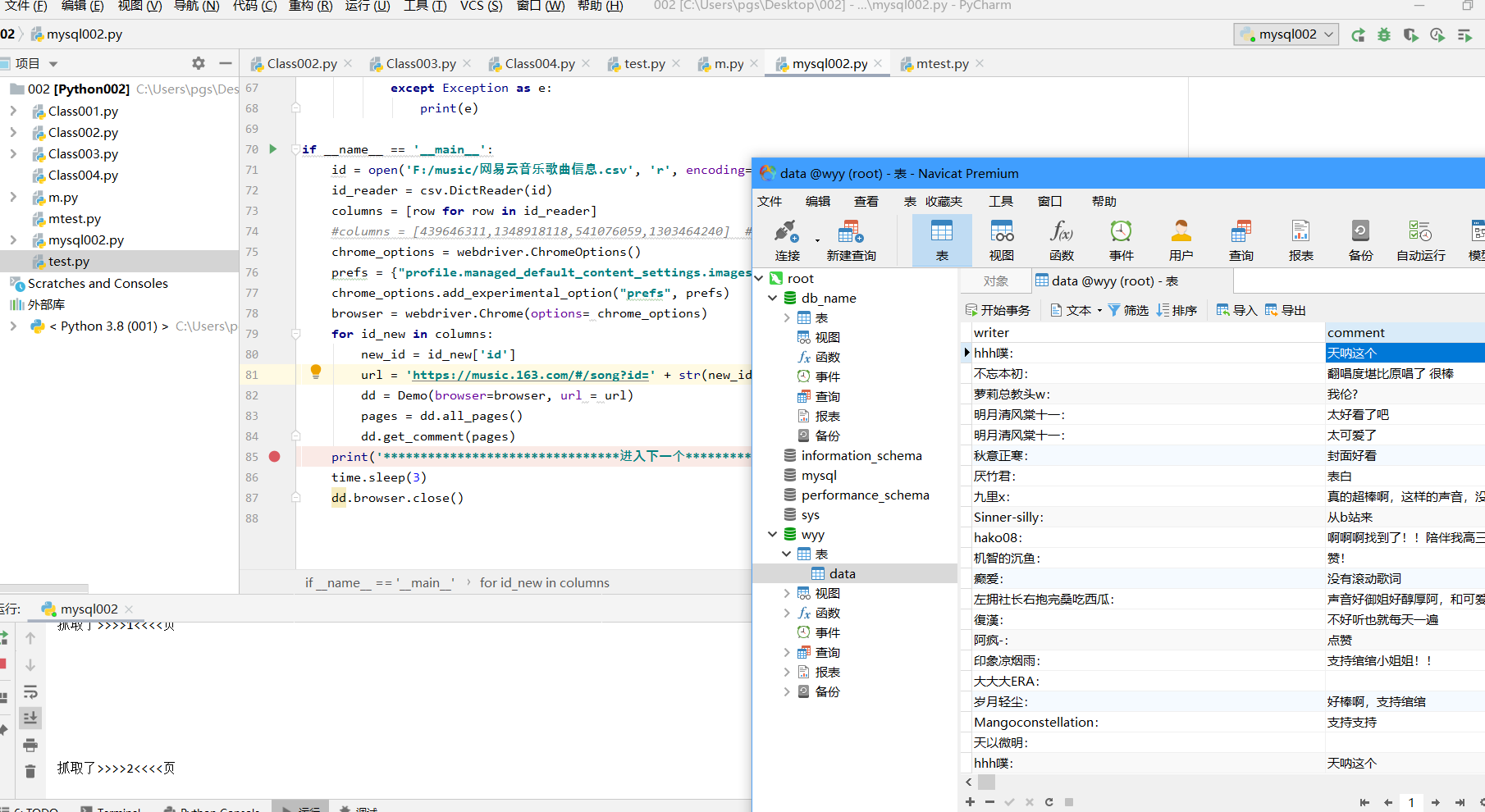

若有收获,就点个赞吧
0 人点赞
