对oldFiber和新的ReactElement节点的比对,将会生成新的fiber节点,同时标记上effectTag,这些fiber会被连到workInProgress树中,作为新的WIP节点。
打上effectTag可以标识这个fiber发生了怎样的变化,例如:新增(Placement)、更新(Update)、删除(Deletion),这些被打上flag的fiber会在complete阶段被收集起来,形成一个effectList链表,只包含这些需要操作的fiber,最后在commit阶段被更新掉。
这意味着,在diff过后,workInProgress节点的beginWork节点就完成了。接下来会进入completeWork阶段。
Tip: React Fiber Diff算法是将 Fiber结构(链表)和React Elements(数组)形式进行新旧对比,生成WIP 时间复杂度O(n)
对应fiber的所有子fiber节点:oldFiber
current树中<Example/> fiber||A --sibling---> B --sibling---> C
的render函数的执行结果,newChildren
current fiber 对应的组件render的结果[{$$typeof: Symbol(react.element), type: "div", key: "A" },{$$typeof: Symbol(react.element), type: "div", key: "B" },{$$typeof: Symbol(react.element), type: "div", key: "B" },]
原则
此算法有一些通用的解决方案,即生成将一棵树转换成另一棵树的最小操作次数。然而,即使使用最优的算法,该算法的复杂程度仍为 O(n 3 ),其中 n 是树中元素的数量。
实现到 O(n 3 )是采用了树编辑距离算法,可以简单理解为:传统Diff算法需要找到两个树的最小更新方式,所以需要[两两]对比每个叶子节点是否相同,对比就需要O(n^2)次了,再加上更新(移动、创建、删除)时需要遍历一次,所以是O(n^3)。
Prev LastA A/ \ / \/ \ / \B D ====> D B/ \C C
就上面两树的变化而言,若要达到最小更新,首先要对比每个节点是否相同,也就是:
PA->LAPA->LBPA->LCPA->LDPB->LA...
查找不同就需要O(n^2),找到差异后还要计算最小转换方式,最终结果为O(n^3)
React的Diff算法完全不同,简单到有些粗暴,过程如下。
# 按叶子节点位置比较[0,0] : PA->LA # 相同,不理会[0.0, 0.0]: PB->LD # 不同,删除PB,添加LD[0.1, 0.1]: PD->LB # 不同,更新[0.1.0, 0.1.0]: PC->Null # Last树没有该节点,所以删除PC即可[0.1.2, 0.1.2]: Null->LC # Prev树没有该节点,所以添加C到该位置
标准的O(n),所有的节点只遍历一次。
React认为:一个ReactElement的type不同,那么内容基本不会复用,所以直接删除节点,添加新节点,这是一个非常大的优化,大大减少了对比时间复杂度。
- 两个不同类型的元素会产生出不同的树;
- 开发者可以通过设置 key 属性,来告知渲染哪些子元素在不同的渲染下可以保存不变;
Diff场景
- 单节点更新、单节点增删。
- 多节点更新、多节点增删、多节点移动。
更新:对于DOM节点来说,在前后的节点类型(tag)和key都相同的情况下,节点的属性发生了变化,是节点更新。若前后的节点tag或者key不相同,Diff算法会认为新节点和旧节点毫无关系,直接删除
以下例子中,key为b的新节点的className发生了变化,是节点更新。
旧<div className={'a'} key={'a'}>aa</div><div className={'b'} key={'b'}>bb</div>新<div className={'a'} key={'a'}>aa</div><div className={'bcd'} key={'b'}>bb</div>
以下例子中,新节点的className虽然有变化,但key也变化了,不属于节点更新
旧<div className={'a'} key={'a'}>aa</div><div className={'b'} key={'b'}>bb</div>新<div className={'a'} key={'a'}>aa</div><div className={'bcd'} key={'bbb'}>bb</div>
以下例子中,新节点的className虽然有变化,但tag也变化了,不属于节点更新
旧<div className={'a'} key={'a'}>aa</div><div className={'b'} key={'b'}>bb</div>新<div className={'a'} key={'a'}>aa</div><p className={'bcd'} key={'b'}>bb</p>
入口
beginWork(current,workInporgress,renderLanes)updateClassComponent()reconcileChildrencurrent: Fiber | null, //作为父节点传入,新生成的第一个fiber的return会被指向它。workInProgress: Fiber, //旧fiber节点,diff生成新fiber节点时会用新生成的ReactElement和它作比较。nextChildren: any, //新生成的ReactElement,会以它为标准生成新的fiber节点renderLanes: Lanes, //本次的渲染优先级,最终会被挂载到新fiber的lanes属性上reconcileChildFibers(boolean)//true代表更新//false第一次挂载ChildReconciler(shouldTrackSideEffects)//参数叫shouldTrackSideEffects,//作用是判断是否要增加一些effectTag,主要是用来优化初次渲染的,因为初次渲染没有更新操作。
function ChildReconciler(shouldTrackSideEffects) {...function reconcileSingleElement(returnFiber: Fiber,currentFirstChild: Fiber | null,element: ReactElement,lanes: Lanes,): Fiber {// 单节点diff}function reconcileChildrenArray(returnFiber: Fiber,currentFirstChild: Fiber | null,newChildren: Array<*>,lanes: Lanes,): Fiber | null {// 多节点diff}...function reconcileChildFibers(returnFiber: Fiber,currentFirstChild: Fiber | null,newChild: any,lanes: Lanes,): Fiber | null {const isObject = typeof newChild === 'object' && newChild !== null;if (isObject) {// 处理单节点switch (newChild.$$typeof) {case REACT_ELEMENT_TYPE:return placeSingleChild(reconcileSingleElement(returnFiber,currentFirstChild,newChild,lanes,),);case REACT_PORTAL_TYPE:...case REACT_LAZY_TYPE:...}}if (typeof newChild === 'string' || typeof newChild === 'number') {// 处理文本节点}if (isArray(newChild)) {// 处理多节点return reconcileChildrenArray(returnFiber,currentFirstChild,newChild,lanes,);}...}return reconcileChildFibers;}
可以看到 通过判断newChild是否是数组来判断是多节点还是单节点
如果是单节点,返回的JSX是对象
<div key="a">aa</div>{$$typeof: Symbol(react.element),type: "div",key: "a"...}
如果是多节点,返回的是数组
<div key="a">aa</div><div key="b">bb</div><div key="c">cc</div><div key="d">dd</div>[{$$typeof: Symbol(react.element), type: "div", key: "a" },{$$typeof: Symbol(react.element), type: "div", key: "b" },{$$typeof: Symbol(react.element), type: "div", key: "c" },{$$typeof: Symbol(react.element), type: "div", key: "d" }]
单节点
单节点指newChildren为单一节点,但是oldFiber的数量不一定,单节点不涉及到移动位置,只存在更新
要考虑到oldFiber多节点情况把oldFiber对应父级Fiber打ChildDeletion标记
旧: --新: A**************旧: A - B - C新: B**************旧: A新: A
// 只保留主杆逻辑function reconcileSingleElement(returnFiber: Fiber,currentFirstChild: Fiber | null,element: ReactElement,lanes: Lanes,): Fiber {const key = element.key;let child = currentFirstChild;// oldFiber链非空while (child !== null) {// currentFirstChild !== null, 表明是对比更新阶段if (child.key === key) {// 1. key相同, 进一步判断 child.elementType === element.typeswitch (child.tag) {// 只看核心逻辑default: {if (child.elementType === element.type) {// 1.1 已经匹配上了, 如果有兄弟节点, 需要给兄弟节点打上Deletion标记deleteRemainingChildren(returnFiber, child.sibling);// 1.2 构造fiber节点, 新的fiber对象会复用current.stateNode, 即可复用DOM对象const existing = useFiber(child, element.props);existing.ref = coerceRef(returnFiber, child, element);existing.return = returnFiber;return existing;}break;}}// Didn't match. 给当前节点点打上Deletion标记deleteRemainingChildren(returnFiber, child);break;} else {// 2. key不相同, 匹配失败, 给当前节点打上Deletion标记deleteChild(returnFiber, child);}child = child.sibling;}{// ...省略部分代码, 只看核心逻辑}// 当oldFiber为空,新建fiber节点并返回// 新建节点const created = createFiberFromElement(element, returnFiber.mode, lanes);created.ref = coerceRef(returnFiber, currentFirstChild, element);created.return = returnFiber;return created;}
- 如果是新增节点, 直接新建 fiber, 没有多余的逻辑
- 如果是对比更新
- 如果key和type都相同(即: ReactElement.key === Fiber.key 且 Fiber.elementType === ReactElement.type), 则复用
- 否则新建
注意: 复用过程是调用useFiber(child, element.props)创建新的fiber对象, 这个新fiber对象.stateNode = currentFirstChild.stateNode, 即stateNode属性得到了复用, 故 DOM 节点得到了复用.
多节点
多节点情况一定属于以下之一
******* 更新节点 ********
旧: A - B - C
新: `A - B - C`
******* 新增节点 ********
旧: A - B - C
新: A - B - C - `D - E`
******* 删除节点 ********
旧: A - B - C - `D - E`
新: A - B - C
******* 移除节点 ********
旧: A - B - C - D - E
新: A - B - `D - C - E`
该算法十分巧妙, 其核心逻辑把newChildren序列分为 2 轮遍历, 先遍历公共序列, 再遍历非公共部分, 同时复用oldFiber序列中的节点.
通过形参, 首先明确比较对象是currentFirstChild: Fiber | null和newChildren: Array<*>:
- currentFirstChild: 是一个fiber节点, 通过fiber.sibling可以将兄弟节点全部遍历出来. 所以可以将currentFirstChild理解为链表头部, 它代表一个序列, 源码中被记为oldFiber.
newChildren: 是一个数组, 其中包含了若干个ReactElement对象. 所以newChildren也代表一个序列. ```javascript function reconcileChildrenArray( returnFiber: Fiber, currentFirstChild: Fiber | null, newChildren: Array<*>, lanes: Lanes, ): Fiber | null { let resultingFirstChild: Fiber | null = null; let previousNewFiber: Fiber | null = null;
let oldFiber = currentFirstChild; let lastPlacedIndex = 0; let newIdx = 0; let nextOldFiber = null; // 1. 第一次循环: 遍历最长公共序列(key相同), 公共序列的节点都视为可复用 for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) { // 后文分析 }
if (newIdx === newChildren.length) { // 如果newChildren序列被遍历完, 那么oldFiber序列中剩余节点都视为删除(打上Deletion标记) deleteRemainingChildren(returnFiber, oldFiber); return resultingFirstChild; }
if (oldFiber === null) { // 如果oldFiber序列被遍历完, 那么newChildren序列中剩余节点都视为新增(打上Placement标记) for (; newIdx < newChildren.length; newIdx++) {
// 后文分析} return resultingFirstChild; }
// ==================分割线================== const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
// 2. 第二次循环: 遍历剩余非公共序列, 优先复用oldFiber序列中的节点 for (; newIdx < newChildren.length; newIdx++) {}
if (shouldTrackSideEffects) { // newChildren已经遍历完, 那么oldFiber序列中剩余节点都视为删除(打上Deletion标记) existingChildren.forEach(child => deleteChild(returnFiber, child)); }
return resultingFirstChild; }
所以reconcileChildrenArray实际就是 2 个序列之间的比较(链表oldFiber和数组newChildren), 最后返回合理的fiber序列.
上述代码中, 以注释分割线为界限, 整个核心逻辑分为 2 步骤:
1. 第一次循环: 遍历最长公共序列(key 相同), 公共序列的节点都视为可复用
1. 如果newChildren序列被遍历完, 那么oldFiber序列中剩余节点都视为删除(打上Deletion标记)
1. 如果oldFiber序列被遍历完, 那么newChildren序列中剩余节点都视为新增(打上Placement标记)
2. 第二次循环: 遍历剩余非公共序列, 优先复用 oldFiber 序列中的节点
```javascript
// 1. 第一次循环: 遍历最长公共序列(key相同), 公共序列的节点都视为可复用
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
if (oldFiber.index > newIdx) {
nextOldFiber = oldFiber;
oldFiber = null;
} else {
nextOldFiber = oldFiber.sibling;
}
// 如果key不同, 返回null
// key相同, 比较type是否一致. type一致则执行useFiber(update逻辑), type不一致则运行createXXX(insert逻辑)
const newFiber = updateSlot(
returnFiber,
oldFiber,
newChildren[newIdx],
lanes,
);
if (newFiber === null) {
// 如果返回null, 表明key不同. 无法满足公共序列条件, 退出循环
if (oldFiber === null) {
oldFiber = nextOldFiber;
}
break;
}
if (shouldTrackSideEffects) {
// 若是新增节点, 则给老节点打上Deletion标记
if (oldFiber && newFiber.alternate === null) {
deleteChild(returnFiber, oldFiber);
}
}
// lastPlacedIndex 记录被移动的节点索引
// 如果当前节点可复用, 则要判断位置是否移动.
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
// 更新resultingFirstChild结果序列
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
oldFiber = nextOldFiber;
}
针对第一轮遍历,有几种结果
- newChildren和oldFiber同时遍历完:这种是最理想的情况,只需要一轮遍历只进行组件更新,Diff结束
- newChildren没遍历完,oldFiber遍历完:意味着newChildren剩余的节点是新插入的,我们只需要遍历剩余的节点为生成WIP fiber标记为Placement
- newChildren遍历完,oldFiber没有遍历完:意味着oldFiber剩余的节点需要删除掉,依次遍历剩余的oldFiber,标记为Deletion
- newChildren和oldFiber都没有遍历完:意味着有节点在本次更新中改变了位置。
处理移动的节点
节点位置发生了改变,不能用索引对比前后的节点,使用key来进行对比
// 1. 将第一次循环后, oldFiber剩余序列加入到一个map中. 目的是为了第二次循环能顺利的找到可复用节点
const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
// 2. 第二次循环: 遍历剩余非公共序列, 优先复用oldFiber序列中的节点
for (; newIdx < newChildren.length; newIdx++) {
const newFiber = updateFromMap(
existingChildren,
returnFiber,
newIdx,
newChildren[newIdx],
lanes,
);
if (newFiber !== null) {
if (shouldTrackSideEffects) {
if (newFiber.alternate !== null) {
// 如果newFiber是通过复用创建的, 则清理map中对应的老节点
existingChildren.delete(newFiber.key === null ? newIdx : newFiber.key);
}
}
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
// 更新resultingFirstChild结果序列
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
}
}
Q: 我们的目标是要找到移动的节点,那么需要明确:节点移动的参照物是什么?
A: 最后一个可复用的节点在oldFiber中的位置索引(lastPlacedIndex)
W: 我们是遍历newChildren,在遍历过程中,每个遍历到的可复用的节点,一定是当前遍历到的 所有可复用节点 中最靠右的那个(也就是在newChildren中newIndex最大的,那么我们只需要比较 遍历到的可复用的节点 在上次更新时是否也在lastPlacedIndex对应的oldFiber后面。
我们用变量 oldIndex表示遍历到的可复用节点在oldFiber 中的位置索引。
如果 oldIndex >= lastPlacedIndex 代表该可复用节点不需要移动 并将 lastPlacedIndex = oldIndex;
如果 oldIndex < lastplacedIndex 该可复用节点之前插入的位置索引小于这次更新需要插入的位置索引,代表该节点需要向右移动
placeChild中可以看到,新增节点和移动节点都打了Placement标记
placeChild中会判断newFiber的alternate,根据alternate是否为空判断是新增还是移动位置
function placeChild(
newFiber: Fiber,
lastPlacedIndex: number,
newIndex: number,
): number {
newFiber.index = newIndex;
if (!shouldTrackSideEffects) {
// Noop.
return lastPlacedIndex;
}
//placeChild中会判断newFiber的alternate,根据alternate是否为空判断是新增还是移动位置
const current = newFiber.alternate;
if (current !== null) {
const oldIndex = current.index;
if (oldIndex < lastPlacedIndex) {
// This is a move.
newFiber.flags |= Placement;
return lastPlacedIndex;
} else {
// This item can stay in place.
return oldIndex;
}
} else {
// This is an insertion.
newFiber.flags |= Placement;
return lastPlacedIndex;
}
}
举例说明,如下:
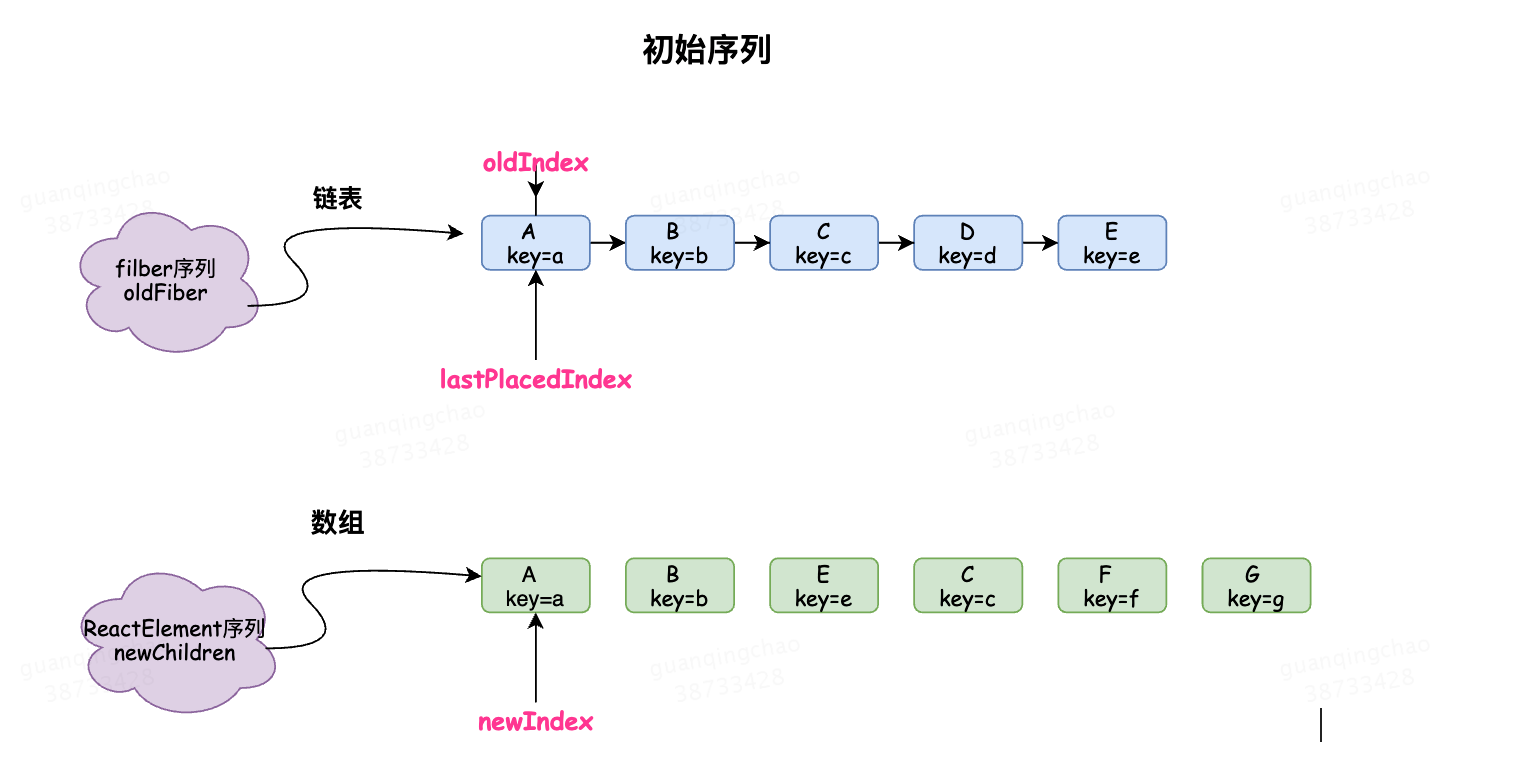
A B C D E
A B E C F G
初始序列如上,newIndex遍历newChildren,初始为0
oldIndex表示遍历到的oldFiber中节点的索引,初始指向oldFiber中第一个节点
lastPlacedIndex初始为0
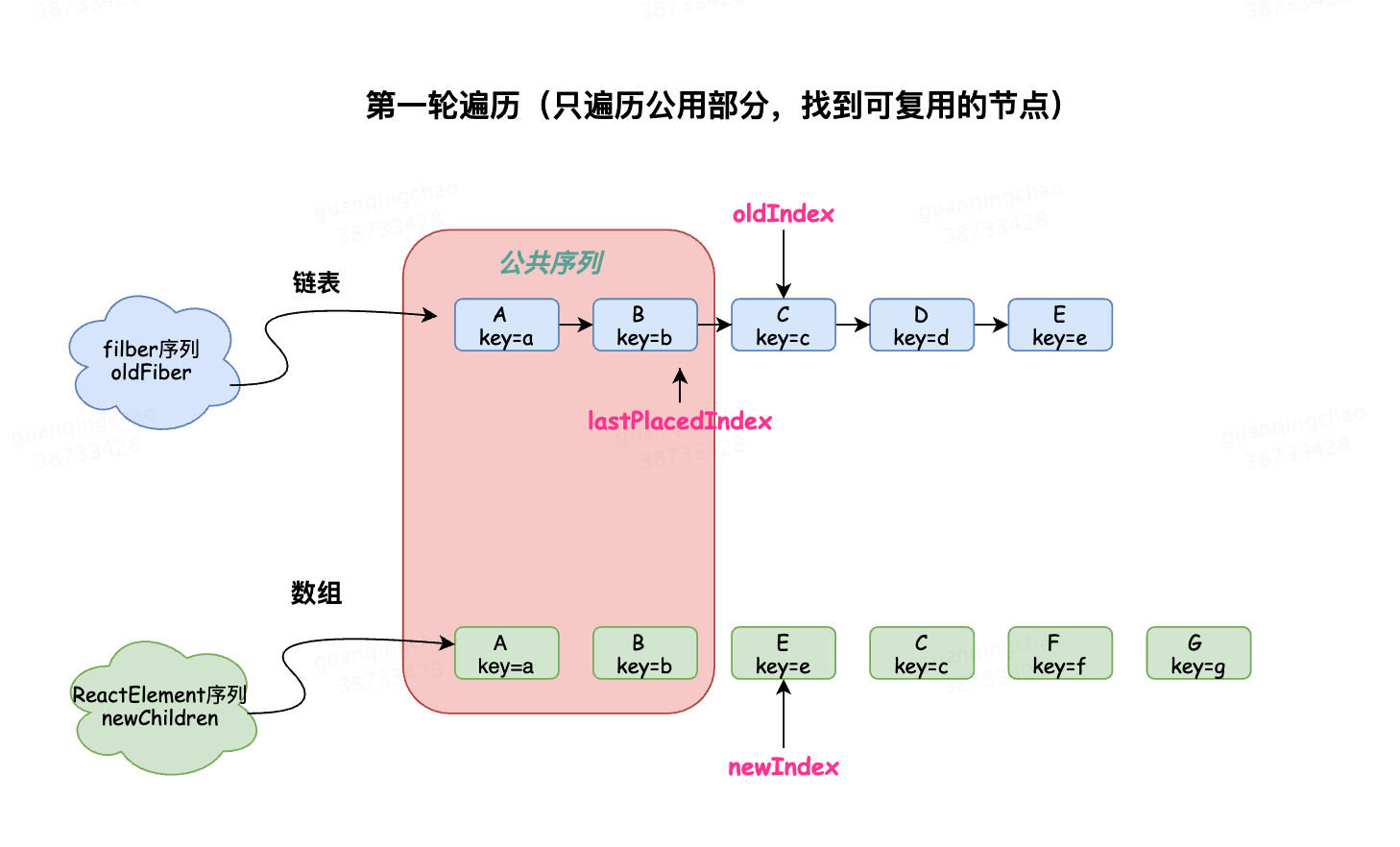
第一轮遍历会找到可以复用的节点,并将可以复用的节点连接到resultingFirstChild链表上
直至找到不可复用的节点 ,跳出循环,进行第二轮遍历
例子中,依次遍历AB
A key和type相同,可以复用,newIndex为0,
B key和type相同,可以复用,newIndex为1,
E key和type不同,不可以复用,跳出第一轮遍历
至此,AB都可以可以复用,所以lastPlacedIndex不变一直是0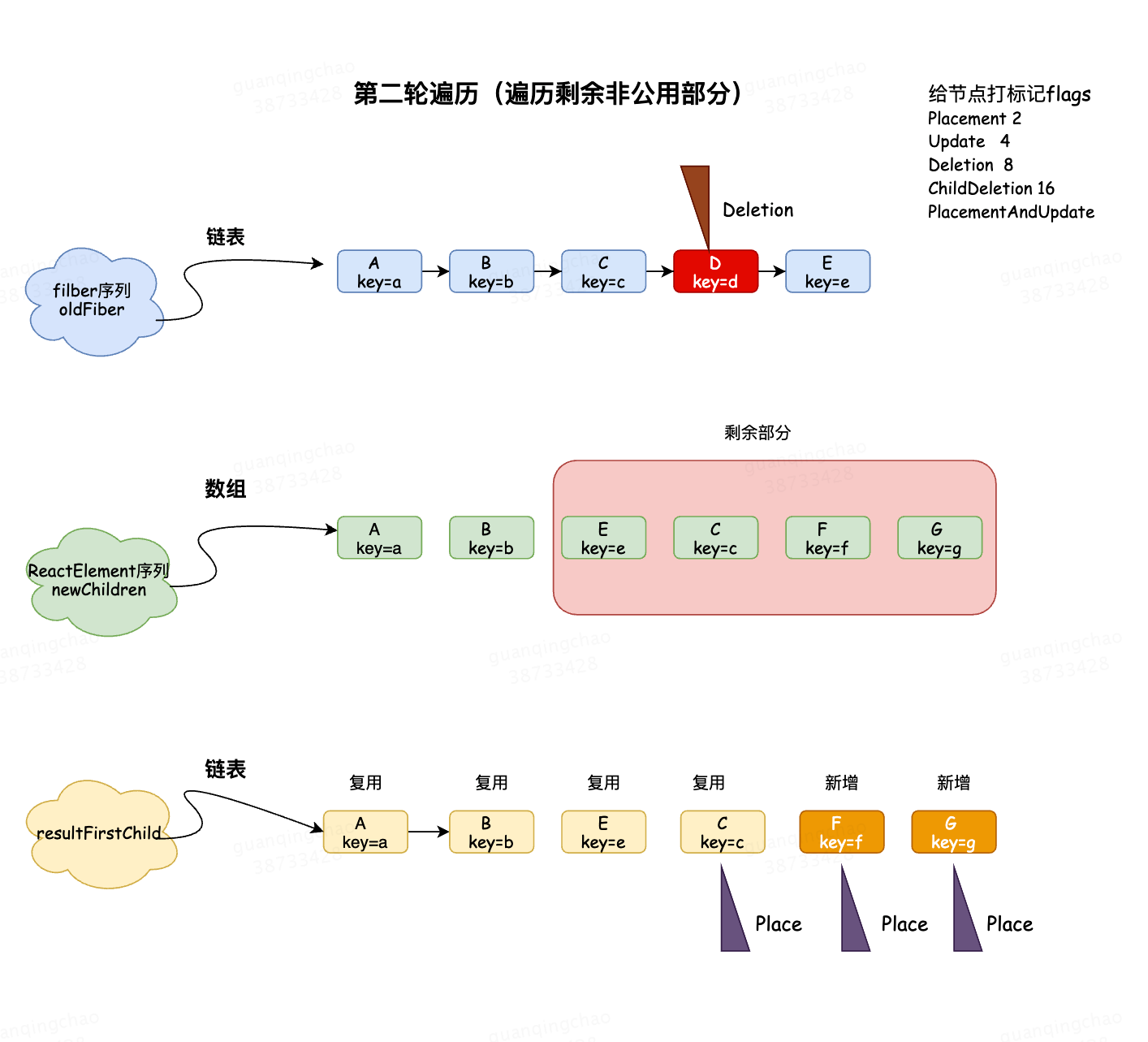
第二轮开始遍历,依次遍历ECFG
oldFiber CDE
newChildren ECFG
oldFiber和newChildren都没有遍历完,将剩余的oldFiber(CDE)通过map映射为existingChildren中
继续遍历剩余的newChildren
如果 oldIndex >= lastPlacedIndex 代表该可复用节点不需要移动 并将 lastPlacedIndex = oldIndex; 如果 oldIndex < lastplacedIndex 该可复用节点之前插入的位置索引小于这次更新需要插入的位置索引,代表该节点需要向右移动
- E key=e 在oldFiber节点中存在,可复用;
在existingChildren中删除oldFiber中对应的E节点
oldIndex = E(oldFiber).index = 4, oldIndex > lastPlacedIndex(0), 不需要移动 lastPlacedIndex = 4; - C key=c 在oldFiber节点中存在,可复用的;
在existingChildren中删除oldFiber中对应的C节点
oldIndex = C(oldFiber).index = 2, oldIndex < lastPlaceIndex(4), 需要移动,打上Placement标记; F key=f 在oldFiber中不存在,不可以复用,会创建一个新的newFiber;
alternate为空说明是新增节点,打上Placement标记;<br /> lastPlaceIndex不变为4;G key=g 在oldFiber中不存在,不可以复用,会创建一个新的newFiber;
alternate为空说明是新增节点,打上Placement标记;
lastPlaceIndex不变为4;- newChidren遍历完了,遍历existingChildren删除剩余的节点,existingChildren中只剩下D节点,给D节点并打上Deletion标记
key
react根据key来决定是销毁重新创建组件还是更新组件,原则是:
- key相同,属性变化,react会只更新组件对应变化的属性。
- key不同,组件会销毁之前的组件,将整个组件重新渲染。
使用key的建议:
- 不要使用random来作为key
- 不要使用索引作为key
- 尽量不要讲元素从最后位置往前移动
Q1: 为什么不传入key的时候控制台会有警告?不传入key会怎样?
Q2:为什么不建议用索引作为key?会有什么影响
key值必须要唯一,这里的唯一指的是相同的节点,在newChildren和oldFiber中key值唯一。
A1:
通过以上例子分析可以看出,key的主要作用就是用来区分节点是否可以复用。如果key值相同,代表节点可以复用,仅仅移动节点就好了。这是一种优化手段。
那么如果不传key值,那么无法知道节点是否可以复用,oldFiber中节点会被删除,newChildren中的节点会被新建。
oldFiber A B C
newChildren C A B
resultingFirstChild C” A” B”
在进行diff的时候,对比C和A,没有key,默认没有可复用的节点,那么就要新建C”节点
同理 A” B”,如果有大量的节点,这样的删除新建节点操作会影响性能。
A2:
同级多个节点中,通常是会对data的数组进行map渲染,React官方不建议用index作为key,为什么呢?
我们来看下面的例子(通常发生在非受控组件中 input label等):
{this.state.data.map((v,index) => <Item key={index} v={v} />)}
// At the beginning of the :['a','b','c']=>
<ul>
<li key="0">a <input type="text"/></li>
<li key="1">b <input type="text"/></li>
<li key="2">c <input type="text"/></li>
</ul>
// Array rearrangement -> ['c','b','a'] =>
<ul>
<li key="0">c <input type="text"/></li>
<li key="1">b <input type="text"/></li>
<li key="2">a <input type="text"/></li>
</ul>
变换顺序的节点是相同类型li节点,textNode是不同的。这种情况用index作为key,新旧在进行diff对比的时候:
oldFiber a(0) b(1) c(2)
newChildren c(0) b(1) a(2)
- 首先对比c和a, key相同,type相同,会认为是相同的节点,不会卸载组件,只需要更新改变属性;
- 然后去对比对应的children,发现文本不一样( from a—->c),input框中的值没有更新,不会重新渲染input,只会触发componentWillReceiveProps更新子组件的text content;
key The disadvantages of the mechanism
A B C D
D A B C
ABC顺序相对不变,将D从最后挪到第一位置。
我们以为从 abcd 变为 dabc,只需要将d移动到前面。
但实际上React保持d不变,将abc分别移动到了d的后面。
从这点可以看出,考虑性能,我们要尽量减少将节点从后面移动到前面的操作。
// 之前
abcd
// 之后
dabc
===第一轮遍历开始===
d(之后)vs a(之前)
key改变,不能复用,跳出遍历
===第一轮遍历结束===
===第二轮遍历开始===
newChildren === dabc,没用完,不需要执行删除旧节点
oldFiber === abcd,没用完,不需要执行插入新节点
将剩余oldFiber(abcd)保存为map
继续遍历剩余newChildren
// 当前oldFiber:abcd
// 当前newChildren dabc
key === d 在 oldFiber中存在
const oldIndex = d(之前).index;
此时 oldIndex === 3; // 之前节点为 abcd,所以d.index === 3
比较 oldIndex 与 lastPlacedIndex;
oldIndex 3 > lastPlacedIndex 0
则 lastPlacedIndex = 3;
d节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:abc
// 当前newChildren abc
key === a 在 oldFiber中存在
const oldIndex = a(之前).index; // 之前节点为 abcd,所以a.index === 0
此时 oldIndex === 0;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 0 < lastPlacedIndex 3
则 a节点需要向右移动
继续遍历剩余newChildren
// 当前oldFiber:bc
// 当前newChildren bc
key === b 在 oldFiber中存在
const oldIndex = b(之前).index; // 之前节点为 abcd,所以b.index === 1
此时 oldIndex === 1;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 1 < lastPlacedIndex 3
则 b节点需要向右移动
继续遍历剩余newChildren
// 当前oldFiber:c
// 当前newChildren c
key === c 在 oldFiber中存在
const oldIndex = c(之前).index; // 之前节点为 abcd,所以c.index === 2
此时 oldIndex === 2;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 2 < lastPlacedIndex 3
则 c节点需要向右移动
===第二轮遍历结束===
分别为 展示使用下标作为 key 时导致的问题,以及不使用下标作为 key 的例子的版本,修复了重新排列,排序,以及在列表头插入的问题。
DEMO:
以下demo是分别用id、index、random作为key
- random:会发现每次添加 input被清空,原因是前后key都不一样,会将组件卸载 然后重新渲染 ```javascript import React from ‘react’; import ‘./style.css’;
class ToDo extends React.Component { constructor(props) { super(props); console.log(‘constructor……’); } componentDidMount() { console.log(‘componentDidMount……’); } componentWillReceiveProps(nextProps) { console.log(‘componentWillReceiveProps……’, nextProps, this.props); } componentDidUpdate() { console.log(‘componentDidUpdate……’); } componentWillUnmount() { console.log(‘componentWillUnmount……’); } render() { console.log(‘render……’, this.props); return ( ); } }
class ToDoList2 extends React.Component { constructor() { super(); const date = new Date(); const toDoCounter = 1; this.state = { list: [ { id: toDoCounter, createdAt: date } ], toDoCounter: toDoCounter }; }
sortByEarliest() { const sortedList = this.state.list.sort((a, b) => { return a.createdAt - b.createdAt; }); this.setState({ list: […sortedList] }); }
sortByLatest() { const sortedList = this.state.list.sort((a, b) => { return b.createdAt - a.createdAt; }); this.setState({ list: […sortedList] }); }
addToEnd() { const date = new Date(); const nextId = this.state.toDoCounter + 1; const newList = […this.state.list, { id: nextId, createdAt: date }]; this.setState({ list: newList, toDoCounter: nextId }); }
addToStart() { const date = new Date(); const nextId = this.state.toDoCounter + 1; const newList = [{ id: nextId, createdAt: date }, …this.state.list]; this.setState({ list: newList, toDoCounter: nextId }); }
render() { return (
{this.state.list.map((todo, index) => (
| ID | created at |
|---|
class ToDoList extends React.Component { constructor() { super(); const date = new Date(); const todoCounter = 1; this.state = { todoCounter: todoCounter, list: [ { id: todoCounter, createdAt: date } ] }; }
sortByEarliest() { const sortedList = this.state.list.sort((a, b) => { return a.createdAt - b.createdAt; }); this.setState({ list: […sortedList] }); }
sortByLatest() { const sortedList = this.state.list.sort((a, b) => { return b.createdAt - a.createdAt; }); this.setState({ list: […sortedList] }); }
addToEnd() { const date = new Date(); const nextId = this.state.todoCounter + 1; const newList = […this.state.list, { id: nextId, createdAt: date }]; this.setState({ list: newList, todoCounter: nextId }); }
addToStart() { const date = new Date(); const nextId = this.state.todoCounter + 1; const newList = [{ id: nextId, createdAt: date }, …this.state.list]; this.setState({ list: newList, todoCounter: nextId }); }
render() { return (
| ID | created at |
|---|
sortByEarliest() { const sortedList = this.state.list.sort((a, b) => { return a.createdAt - b.createdAt; }); this.setState({ list: […sortedList] }); }
sortByLatest() { const sortedList = this.state.list.sort((a, b) => { return b.createdAt - a.createdAt; }); this.setState({ list: […sortedList] }); }
addToEnd() { const date = new Date(); const nextId = this.state.todoCounter + 1; const newList = […this.state.list, { id: nextId, createdAt: date }]; this.setState({ list: newList, todoCounter: nextId }); }
addToStart() { const date = new Date(); const nextId = this.state.todoCounter + 1; const newList = [{ id: nextId, createdAt: date }, …this.state.list]; this.setState({ list: newList, todoCounter: nextId }); }
render() { return (
| ID | created at |
|---|
export default function App() { return (
Demo1: index作为key
Demo2: id作为key
Demo3: Random作为key
参考
https://react.iamkasong.com/diff/one.html
https://github.com/7kms/react-illustration-series/blob/master/docs/algorithm/diff.md
https://github.com/neroneroffy/react-source-code-debug/blob/master/docs/render%E9%98%B6%E6%AE%B5/beginWork%E9%98%B6%E6%AE%B5/Diff%E7%AE%97%E6%B3%95.md
key:https://qdmana.com/2021/06/20210621212702480R.html

若有收获,就点个赞吧
0 人点赞
