即时理解了前面Selector、Channel、Buffer在Java NIO非阻塞模式下的使用,但是设计一个非阻塞服务器仍然存在着很多的挑战。下面将简要的分析一下非阻塞服务器构建存在的挑战,以及一些可能解决方案。
非阻塞IO流水线是一系列能够处理非阻塞请求的组件构成的链路,它能够以非阻塞的方式来处理读IO和写IO,但不要求非阻塞的读和写都支持。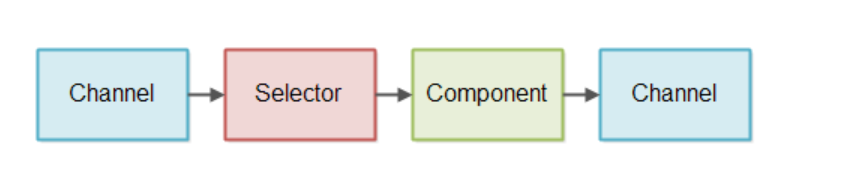
Selector用于检查Channel是否有数据可以读取,如果有,则读取数据进行处理。处理后可能会形成数据数据,再次写入到Channel中。当然,实际中的非阻塞流水线会存在多条链路来响应多个连接请求。每一条流水线也可能同时读取多个Channel中数据,例如同时读取多个SocketChannel中的数据。
阻塞式和非阻塞式一个最大的区别在于,如何通过下图所示的流水线来从Channel中读取数据。IO流水线通常需要从一些流中读取数据,然后再将其划分为一些块或者使用tokenizer进行解析,这个过程可以称为将流数据划分为更大的一些message。那么,实现这个功能的组件可以称为Message Reader。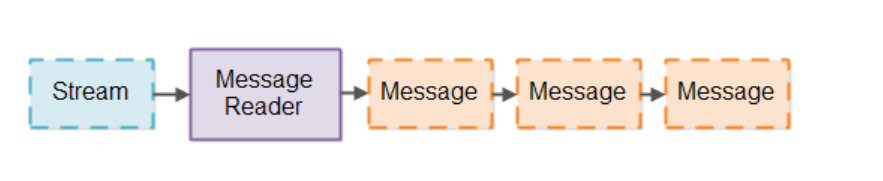
非阻塞式IO流水线通常使用InputStream类的接口来从Channel中逐字节的读取数据,如果没有数据可读,那么InputStream类的接口就会一直被阻塞。此时,Message Reader需要处理多种可能的情况,例如没有数据可读、只有一部分数据,或者需要先读取数据后续才会使用等。
非阻塞式的IO流水线使用起来比较简单,但是它存在着很大的不足之处。对于流水线来说,如果没有数据读或者写,那么它会一直处理阻塞状态,此时管理它的线程也会被阻塞。阻塞的线程是无法再去处理其他的IO请求的,如果多条IO流水线都处于阻塞状态,那么就会有多个线程处于阻塞状态,这会造成资源的极大浪费。 如果服务器处理的并发连接数不多时,这种资源的浪费不会太影响服务器性能。但是如果服务器并发处理的连接请求非常多时,每一个连接都需要一个线程处理,所有的线程都会被阻塞。此时,服务器的资源会被消耗殆尽,性能急剧下降。
为了解决上述的问题,一些服务器采用了线程池的机制。使用线程池中的可用线程来处理连接请求,如果无可用线程,后续的请求就要排队等候处理。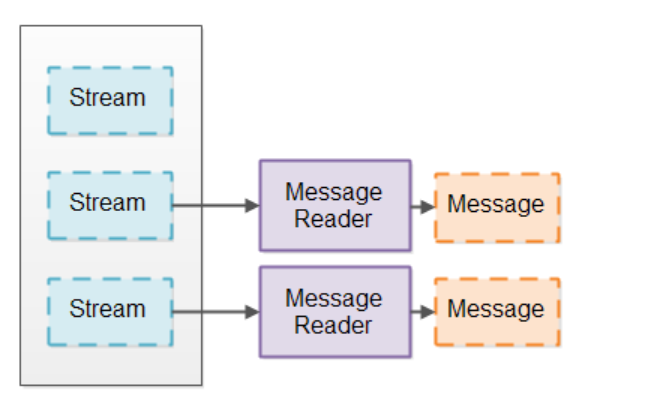
但是,线程池的机制需要处理的连接可以较快的得到响应。如果线程处理的请求都处于阻塞状态,那么线程池很快将没有可用线程来处理到达的请求。大量的请求就会堆积在队列中,而队列的维护需要消耗内存资源,这样线程池的优势就不存在了。一些服务器可能会采用增大线程池容量的方式来缓解这个问题,但是单线程池的容量也是有限的,并不能从根本上上解决这个问题。
而非阻塞式的IO只需要使用单个线程就能管理很多的Channel,Selector实现了IO的多路复用,用于检查注册的多个SelectableChannel。调用Selector的select方法或者selectNow方法监听,当其中一个或多个Channel有数据可读时,对应的Channel就会被返回。
当从SelectableChannel中读取数据时,程序是无法知道数据块的大小,可能很大也可能很小。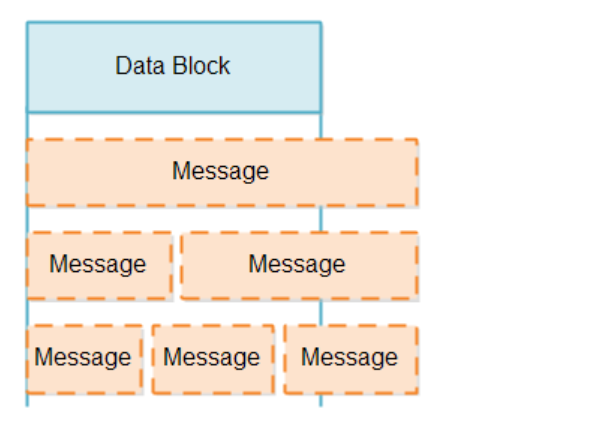
因此,对于处理部分的message来说,存在着如下的两个挑战:
- 检查Channel中的数据块是否是一个完整的message
- 如果不是一个完整的message应该如何进行处理
Message Reader就需要负责检查数据块是否包含完整的message,如果块中包含一个或多个完整的message,那么就可以将其送到下游的流水线进行处理。这个过程会周而复始的进行,因此处理的速度需要尽可能的快。如果消息不是一个完成的message,那么Message Reader就需要先将其存储起来,等到剩余的message全部达到后再进行处理。因此,检查和存储的工作都需要Message Reader来完成,为了避免多个Channel之间数据的混乱,需要为每一个Channel分配一个Message Reader。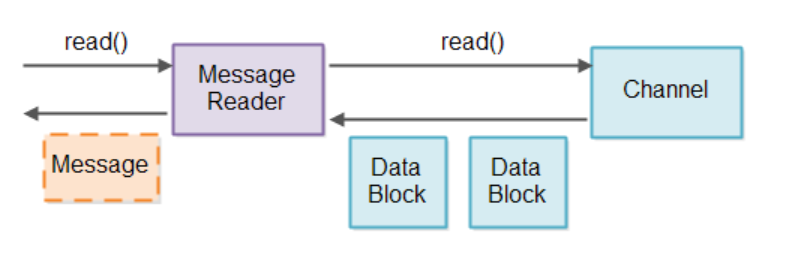
一旦Selector监测到Channel有数据可以读取,Message Reader就会关联到这个Channel,如果读取到的数据是一个或多个完整的message,就将其交给下游的流水线进行处理。Message Reader也是基于特定协议的,因此,他需要知道所处理的message的格式。
如果Message Reader读取的数据不是完整的message,就需要进行存储知道完整的message到达。对于部分message的存储需要考虑如下的两个问题:
- 尽可能少的执行message的复制操作
- 完整的message可以用一种连续的字节序列存储,便于后续的解析使用
如果每个Message Reader都使用独有Buffer来存储读取到的部分message,那么又会有一个问题:Buffer的容量应该设置多大?一种解决办法是使用可调整大小的Buffer,当Buffer容量不够使用时,可以自动的进行扩容。这种办法有不同的实现方案,如下所示。
Resize by Copy
**
初始时Buffer的大小设置为4KB,如果Buffer的空间不足以容纳接收到的message,那么将会分配一个更大的Buffer(例如8KB),然后将message复制到新的Buffer中。这种方案的好处在于,所有的message都以连续的序列存放,便于后续的解析使用。但是,如果复制的数据量很大,那么复制的开销将很大。
通过分析后续message的大小可以减少复制的次数,如果后续大部分的message大小都小于4KB,那么Buffer分配4KB就足够了。如果后续的message大小超过了4KB,但是都小于128KB,那么Buffer如果要扩容,大小就应该选择为128KB。如果message大小超过了128KB,那么Buffer空间的大小就只能根据message的大小随时进行调整了。
这样Buffer空间的变化层次设置为4KB - 128KB,可以有效的减少复制的次数。如果所有的message都不超过4KB,那么不需要复制,如果某个message大于4KB小于128KB,只需要进行1次复制。如果message大于128KB,那么只需要进行2次复制。
一旦message被完全处理,Buffer分配的内存应该被再次释放。这样,从相同连接接收到的下一条消息将再次以最小的Buffer大小开始。这对于确保连接之间可以更有效地共享内存是必要的,不是所有连接都同时需要大Buffer空间。
Resize by Append
**
这种方案的思想是:预先分配多个数组或者数组的切片,如果当前的数组不足以存放message,就将其存放到另一个数组或者切片中。这种方式不会产生复制操作,实现较为简单。但由于message不是以连续序列的形式保存,后续的解析工作执行起来较为困难
TLV Encoded Messages
一些协议消息格式使用TLV格式(类型,长度,值)进行编码。这意味着,当消息到达时,消息的总长度被存储在消息的开头。这样你就可以立即知道为整个消息分配多少内存。TLV编码使得内存管理变得更容易,服务器立即知道要为消息分配多少内存,没有内存被浪费。TLV编码的一个缺点是,在消息的所有数据到达之前,为消息分配所有内存。一些发送较大消息的缓慢连接可以分配所有可用的内存,从而使服务器无响应。
解决此问题的方法是使用包含多个TLV字段的消息格式。因此,内存分配给每个字段,而不是整个消息,内存只在字段到达时才分配。尽管如此,一个大的领域可能会对你的内存管理产生同样的影响。另一个解决方法是超时例如没有收到的消息10-15秒。这可以使服务器从许多大消息的同时到达的同时恢复,但它仍然会使服务器一段时间无响应。此外,有意的DoS(拒绝服务)攻击仍然可以导致服务器的内存完全分配。
TLV编码存在不同的变化。究竟使用了多少字节,所以指定字段的类型和长度取决于每个单独的TLV编码。也有TLV编码,首先是字段的长度,然后是类型,然后是值(LTV编码)。虽然字段的顺序是不同的,但它仍然是一个TLV变化。TLV编码使内存管理更容易的事实是HTTP 1.1是如此糟糕的协议的原因之一。这是他们试图在HTTP 2.0中解决数据以LTV编码帧传输的问题之一。
Writing Partial Message
在一个非阻塞的IO Channel中写数据也是一个挑战。当以非阻塞模式在Channel上调用写入(ByteBuffer)时,无法保证正在写入ByteBuffer中有多少个字节。写(ByteBuffer)方法返回写了多少字节,所以可以跟踪写入的字节数。这就是挑战:跟踪部分编写的消息,以便最终发送消息的所有字节。
为了管理将部分消息写入Message Writer,将创建一个Message Writer。就像使用Message Reader一样,我们需要每个Channel写消息的Message Writer。在每个Message Writer内部,记录了它正在写入的消息的字节数。
如果有更多的消息到达消息写入器,而不是直接写入通道,则消息需要在Message Writer内部排队。Message Writer然后将消息尽可能快地写入Channel。
下面是一个图表,展示了如何设计部分消息: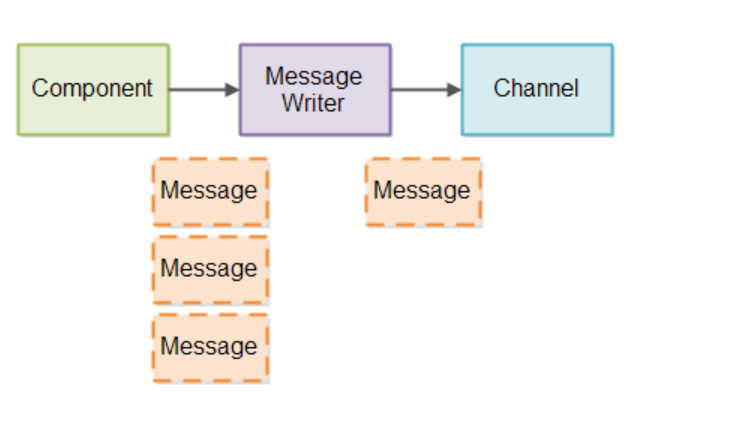
为了使Message Writer能够发送仅部分被发送的消息,Message Writer需要不时地被调用,所以它可以发送更多的数据。
如果很多的连接,就会有很多Message Writer实例。检查例如一百万个Message Writer实例来查看它们是否可以写入任何数据的速度很慢。
要检查Channel是否准备好写入,可以使用选择器注册通道。但是,我们不想使用Selector注册所有Channel实例。试想一下,如果有1000000连接,大部分是空闲的,所有1000000连接都被注册到了Selector。然后当调用select方法时,这些Channel实例中的大部分都将准备好写入。然后必须检查所有这些连接的Message Writer,看看是否有任何数据要写入。
为了避免检查消息的所有Message Writer实例,以及所有Channel实例,它们没有任何消息发送给它们,我们使用这个两步法:
当消息写入Message Writer时,消息写入器向Selector(如果它尚未注册)注册其关联的Channel
当你的服务器有时间的时候,它会检查Selector来查看哪些已注册的Channel实例准备好写入。 对于每个写入就绪Channel,其相关的Message Writer被要求将数据写入Channel。 如果Message Writer将其所有消息写入其通Channel,则该Channel将再次从Selector中注销
这个小小的两步方法确保只有Channel消息被写入到它们的实例才会真正注册到Selector中。
Putting it All Together
非阻塞服务器需要不时检查传入数据,查看是否收到任何新的完整message。 服务器可能需要多次检查,直到收到一个或多个完整的message。
同样,非阻塞服务器需要不时检查是否有数据要写入。 如果是,服务器需要检查是否有相应的连接准备好写入数据。
总而言之,一个非阻塞服务器最终需要定期执行三个“Channel”:
- 读取Channel,用于检查来自打开的连接的新输入数据
- 处理任何收到的完整消息的流程Channel
- 写入Channel检查是否可以将任何传出消息写入任何打开的连接
这三条Channel是循环重复执行的,可能会稍微优化执行。 例如,如果没有排队的消息,则可以跳过写入Channel。 或者如果没有收到新的完整的消息,也许可以跳过流程Channel。以下是一个说明整个服务器循环的图表: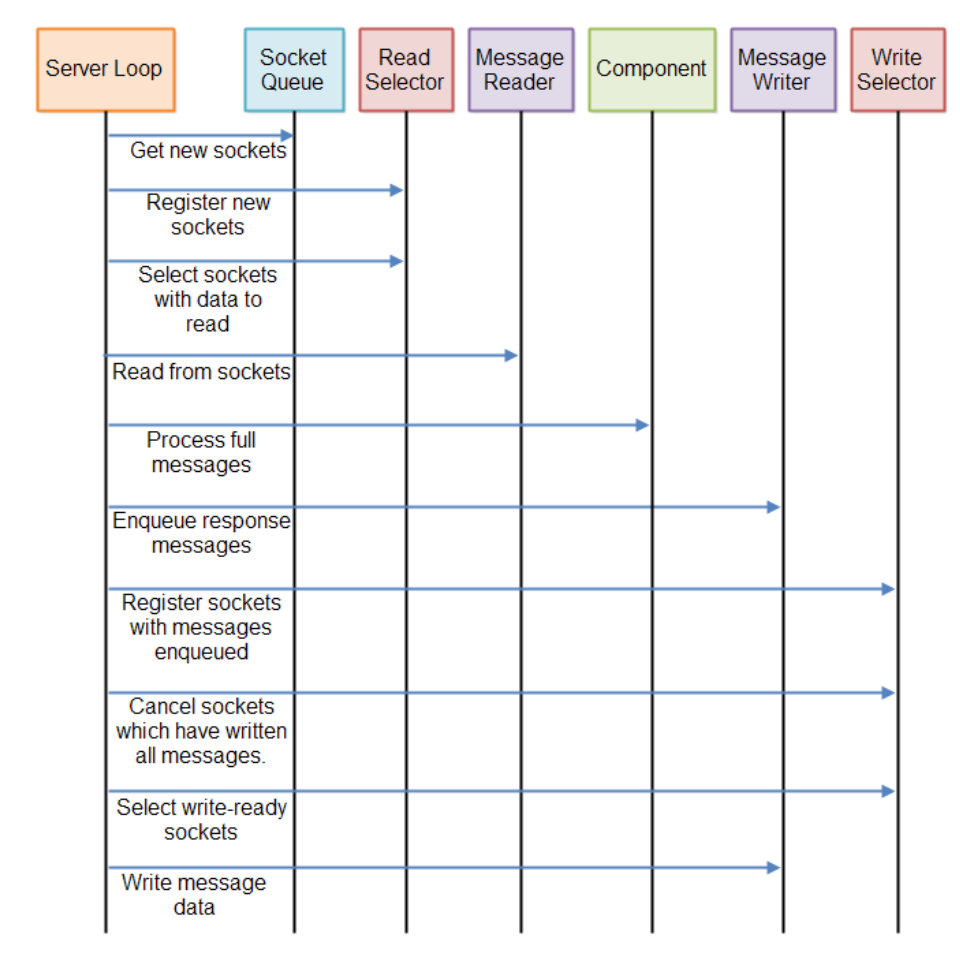

若有收获,就点个赞吧
0 人点赞
