用户定义的函数
用户定义的函数是一个重要的特性,因为它们显着扩展了查询的表达能力。
注册用户定义的函数
在大多数情况下,必须先注册用户定义的函数,然后才能在查询中使用它。没有必要为Scala Table API注册函数。
TableEnvironment通过调用registerFunction()方法来注册函数。注册用户定义的函数时,会将其插入到函数目录中TableEnvironment,以便 Table API或SQL解析器可以识别并正确转换它。
请找到如何注册,如何调用每个类型的用户定义函数(详细的例子ScalarFunction,TableFunction和AggregateFunction下面的子会话)。
标量函数
如果内置函数中不包含必需的标量函数,则可以为 Table API和SQL定义自定义的,用户定义的标量函数。用户定义的标量函数将零个,一个或多个标量值映射到新的标量值。
为了定义一个标量函数之一具有以扩展的基类ScalarFunction中org.apache.flink.table.functions和实现(一个或多个)的评价方法。标量函数的行为由评估方法确定。评估方法必须公开声明并命名eval。评估方法的参数类型和返回类型也确定标量函数的参数和返回类型。通过实现多个名为的方法,也可以重载评估方法eval。评估方法也可以支持变量参数,例如eval(String... strs)。
以下示例显示如何定义自己的哈希代码函数,在TableEnvironment中注册它,并在查询中调用它。请注意,您可以在注册之前通过构造函数配置标量函数:
public class HashCode extends ScalarFunction {private int factor = 12;public HashCode(int factor) {this.factor = factor;}public int eval(String s) {return s.hashCode() * factor;}}BatchTableEnvironment tableEnv = TableEnvironment.getTableEnvironment(env);// register the functiontableEnv.registerFunction("hashCode", new HashCode(10));// use the function in Java Table APImyTable.select("string, string.hashCode(), hashCode(string)");// use the function in SQL APItableEnv.sqlQuery("SELECT string, HASHCODE(string) FROM MyTable");
// must be defined in static/object context class HashCode(factor: Int) extends ScalarFunction {def eval(s: String): Int = {s.hashCode() * factor}}val tableEnv = TableEnvironment.getTableEnvironment(env)// use the function in Scala Table API val hashCode = new HashCode(10)myTable.select('string, hashCode('string))// register and use the function in SQL tableEnv.registerFunction("hashCode", new HashCode(10))tableEnv.sqlQuery("SELECT string, HASHCODE(string) FROM MyTable")
默认情况下,评估方法的结果类型由Flink的类型提取工具确定。这对于基本类型或简单POJO就足够了,但对于更复杂,自定义或复合类型可能是错误的。在这些情况下TypeInformation,可以通过覆盖手动定义结果类型ScalarFunction#getResultType()。
以下示例显示了一个高级示例,该示例采用内部时间戳表示形式,并将内部时间戳表示形式返回为long值。通过重写,ScalarFunction#getResultType()我们定义返回的long值应该Types.TIMESTAMP由代码生成解释为a 。
public static class TimestampModifier extends ScalarFunction {public long eval(long t) {return t % 1000;}public TypeInformation<?> getResultType(signature: Class<?>[]) {return Types.TIMESTAMP;}}
object TimestampModifier extends ScalarFunction {def eval(t: Long): Long = {t % 1000}override def getResultType(signature: Array[Class[_]]): TypeInformation[_] = {Types.TIMESTAMP}}
表函数
与用户定义的标量函数类似,用户定义的表函数将零个,一个或多个标量值作为输入参数。但是,与标量函数相比,它可以返回任意数量的行作为输出而不是单个值。返回的行可以包含一个或多个列。
为了定义表函数之一具有以扩展的基类TableFunction中org.apache.flink.table.functions和实现(一个或多个)的评价方法。表函数的行为由其评估方法确定。必须声明public和命名评估方法eval。该TableFunction可以通过实施名为多种方法被重载eval。评估方法的参数类型确定表函数的所有有效参数。评估方法也可以支持变量参数,例如eval(String... strs)。返回表的类型由泛型类型确定TableFunction。评估方法使用受保护的方法发出输出行collect(T)。
在该 Table API,表格函数用于.join(Expression)或.leftOuterJoin(Expression)Scala用户和.join(String)或.leftOuterJoin(String)针对Java用户。的join 算子(交叉)关联其中,从外部表与由表值函数(其是在 算子操作者的右侧)所产生的所有行的每行(表上的 算子操作者的左侧)。的leftOuterJoin 算子连接从外部表(在 算子左侧表)与由表值函数(其是在 算子操作者的右侧)所产生的所有行的每一行,并保存的量,表函数返回一个外部行空表。在SQL中使用LATERAL TABLE(<TableFunction>)CROSS JOIN和LEFT JOIN以及ON TRUE连接条件(参见下面的示例)。
以下示例显示如何定义表值函数,在TableEnvironment中注册它,并在查询中调用它。请注意,您可以在注册之前通过构造函数配置表函数:
// The generic type "Tuple2<String, Integer>" determines the schema of the returned table as (String, Integer).public class Split extends TableFunction<Tuple2<String, Integer>> {private String separator = " ";public Split(String separator) {this.separator = separator;}public void eval(String str) {for (String s : str.split(separator)) {// use collect(...) to emit a rowcollect(new Tuple2<String, Integer>(s, s.length()));}}}BatchTableEnvironment tableEnv = TableEnvironment.getTableEnvironment(env);Table myTable = ... // table schema: [a: String]// Register the function.tableEnv.registerFunction("split", new Split("#"));// Use the table function in the Java Table API. "as" specifies the field names of the table.myTable.join("split(a) as (word, length)").select("a, word, length");myTable.leftOuterJoin("split(a) as (word, length)").select("a, word, length");// Use the table function in SQL with LATERAL and TABLE keywords.// CROSS JOIN a table function (equivalent to "join" in Table API).tableEnv.sqlQuery("SELECT a, word, length FROM MyTable, LATERAL TABLE(split(a)) as T(word, length)");// LEFT JOIN a table function (equivalent to "leftOuterJoin" in Table API).tableEnv.sqlQuery("SELECT a, word, length FROM MyTable LEFT JOIN LATERAL TABLE(split(a)) as T(word, length) ON TRUE");
// The generic type "(String, Int)" determines the schema of the returned table as (String, Integer). class Split(separator: String) extends TableFunction[(String, Int)] {def eval(str: String): Unit = {// use collect(...) to emit a row.str.split(separator).foreach(x -> collect((x, x.length))}}val tableEnv = TableEnvironment.getTableEnvironment(env)val myTable = ... // table schema: [a: String]// Use the table function in the Scala Table API (Note: No registration required in Scala Table API). val split = new Split("#")// "as" specifies the field names of the generated table. myTable.join(split('a) as ('word, 'length)).select('a, 'word, 'length)myTable.leftOuterJoin(split('a) as ('word, 'length)).select('a, 'word, 'length)// Register the table function to use it in SQL queries. tableEnv.registerFunction("split", new Split("#"))// Use the table function in SQL with LATERAL and TABLE keywords.// CROSS JOIN a table function (equivalent to "join" in Table API) tableEnv.sqlQuery("SELECT a, word, length FROM MyTable, LATERAL TABLE(split(a)) as T(word, length)")// LEFT JOIN a table function (equivalent to "leftOuterJoin" in Table API) tableEnv.sqlQuery("SELECT a, word, length FROM MyTable LEFT JOIN TABLE(split(a)) as T(word, length) ON TRUE")
IMPORTANT: Do not implement TableFunction as a Scala object. Scala object is a singleton and will cause concurrency issues.
请注意,POJO类型没有确定性字段顺序。因此,您无法重命名由表函数返回的POJO字段AS。
默认情况下,a的结果类型TableFunction由Flink的自动类型提取工具确定。这适用于基本类型和简单POJO,但对于更复杂,自定义或复合类型可能是错误的。在这种情况下,结果的类型可以通过覆盖TableFunction#getResultType()返回它来手动指定TypeInformation。
以下示例显示了一个TableFunction返回Row需要显式类型信息的类型的示例。我们定义返回的表类型应该RowTypeInfo(String, Integer)通过重写TableFunction#getResultType()。
public class CustomTypeSplit extends TableFunction<Row> {public void eval(String str) {for (String s : str.split(" ")) {Row row = new Row(2);row.setField(0, s);row.setField(1, s.length);collect(row);}}@Overridepublic TypeInformation<Row> getResultType() {return Types.ROW(Types.STRING(), Types.INT());}}
class CustomTypeSplit extends TableFunction[Row] {def eval(str: String): Unit = {str.split(" ").foreach({ s =>val row = new Row(2)row.setField(0, s)row.setField(1, s.length)collect(row)})}override def getResultType: TypeInformation[Row] = {Types.ROW(Types.STRING, Types.INT)}}
聚合函数
用户定义的聚合函数(UDAGG)将一个表(一个或多个具有一个或多个属性的行)聚合到标量值。
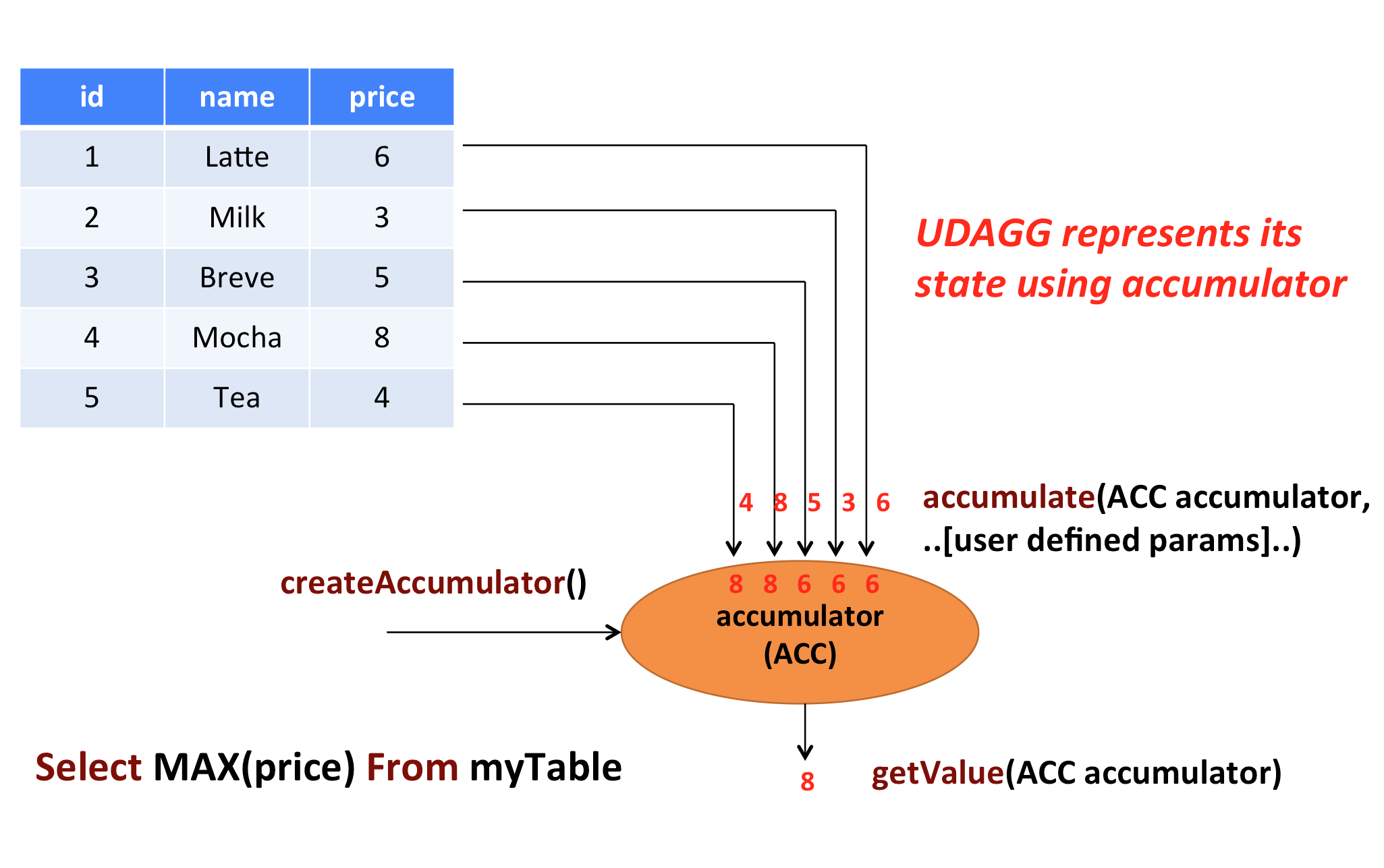
上图显示了聚合的示例。假设您有一个包含饮料数据的表格。该表由三列的id,name和price5行。想象一下,您需要找到表中所有饮料的最高价格,即执行max()聚合。您需要检查5行中的每一行,结果将是单个数值。
用户定义的聚合函数通过扩展AggregateFunction类来实现。一个AggregateFunction作品如下。首先,它需要一个accumulator,它是保存聚合的中间结果的数据结构。通过调用createAccumulator()方法创建一个空累加器AggregateFunction。随后,accumulate()为每个输入行调用函数的方法以更新累加器。处理完所有行后,将getValue()调用该函数的方法来计算并返回最终结果。
每种方法都必须使用以下方法AggregateFunction:
createAccumulator()accumulate()getValue()
Flink的类型提取工具无法识别复杂的数据类型,例如,如果它们不是基本类型或简单的POJO。类似于ScalarFunction和TableFunction,AggregateFunction提供了指定TypeInformation结果类型(通过 AggregateFunction#getResultType())和累加器类型(通过AggregateFunction#getAccumulatorType())的方法。
除了上述方法之外,还有一些可以选择性实施的简约方法。虽然其中一些方法允许系统更有效地执行查询,但其他方法对于某些用例是强制性的。例如,merge()如果聚合函数应该应用于会话组窗口的上下文中,则该方法是必需的(当观察到“连接”它们的行时,需要连接两个会话窗口的累加器)。
AggregateFunction根据用例,Required以下方法:
retract()有界OVER窗口上的聚合需要。merge()是许多批量聚合和会话窗口聚合所必需的。resetAccumulator()是许多批量聚合所必需的。
所有方法AggregateFunction必须声明为public,而不是static完全按照上面提到的名称命名。该方法createAccumulator,getValue,getResultType,和getAccumulatorType在定义的AggregateFunction抽象类,而另一些则收缩的方法。为了定义聚合函数,必须扩展基类org.apache.flink.table.functions.AggregateFunction并实现一个(或多个)accumulate方法。该方法accumulate可以使用不同的参数类型重载,并支持可变参数。
AggregateFunction下面给出了所有方法的详细文档。
/*** Base class for aggregation functions.** @param <T> the type of the aggregation result* @param <ACC> the type of the aggregation accumulator. The accumulator is used to keep the* aggregated values which are needed to compute an aggregation result.* AggregateFunction represents its state using accumulator, thereby the state of the* AggregateFunction must be put into the accumulator.*/public abstract class AggregateFunction<T, ACC> extends UserDefinedFunction {/*** Creates and init the Accumulator for this [[AggregateFunction]].** @return the accumulator with the initial value*/public ACC createAccumulator(); // MANDATORY/** Processes the input values and update the provided accumulator instance. The method* accumulate can be overloaded with different custom types and arguments. An AggregateFunction* requires at least one accumulate() method.** @param accumulator the accumulator which contains the current aggregated results* @param [user defined inputs] the input value (usually obtained from a new arrived data).*/public void accumulate(ACC accumulator, [user defined inputs]); // MANDATORY/*** Retracts the input values from the accumulator instance. The current design assumes the* inputs are the values that have been previously accumulated. The method retract can be* overloaded with different custom types and arguments. This function must be implemented for* datastream bounded over aggregate.** @param accumulator the accumulator which contains the current aggregated results* @param [user defined inputs] the input value (usually obtained from a new arrived data).*/public void retract(ACC accumulator, [user defined inputs]); // OPTIONAL/*** Merges a group of accumulator instances into one accumulator instance. This function must be* implemented for datastream session window grouping aggregate and dataset grouping aggregate.** @param accumulator the accumulator which will keep the merged aggregate results. It should* be noted that the accumulator may contain the previous aggregated* results. Therefore user should not replace or clean this instance in the* custom merge method.* @param its an [[java.lang.Iterable]] pointed to a group of accumulators that will be* merged.*/public void merge(ACC accumulator, java.lang.Iterable<ACC> its); // OPTIONAL/*** Called every time when an aggregation result should be materialized.* The returned value could be either an early and incomplete result* (periodically emitted as data arrive) or the final result of the* aggregation.** @param accumulator the accumulator which contains the current* aggregated results* @return the aggregation result*/public T getValue(ACC accumulator); // MANDATORY/*** Resets the accumulator for this [[AggregateFunction]]. This function must be implemented for* dataset grouping aggregate.** @param accumulator the accumulator which needs to be reset*/public void resetAccumulator(ACC accumulator); // OPTIONAL/*** Returns true if this AggregateFunction can only be applied in an OVER window.** @return true if the AggregateFunction requires an OVER window, false otherwise.*/public Boolean requiresOver = false; // PRE-DEFINED/*** Returns the TypeInformation of the AggregateFunction's result.** @return The TypeInformation of the AggregateFunction's result or null if the result type* should be automatically inferred.*/public TypeInformation<T> getResultType = null; // PRE-DEFINED/*** Returns the TypeInformation of the AggregateFunction's accumulator.** @return The TypeInformation of the AggregateFunction's accumulator or null if the* accumulator type should be automatically inferred.*/public TypeInformation<T> getAccumulatorType = null; // PRE-DEFINED}
/*** Base class for aggregation functions.** @tparam T the type of the aggregation result* @tparam ACC the type of the aggregation accumulator. The accumulator is used to keep the* aggregated values which are needed to compute an aggregation result.* AggregateFunction represents its state using accumulator, thereby the state of the* AggregateFunction must be put into the accumulator.*/abstract class AggregateFunction[T, ACC] extends UserDefinedFunction {/*** Creates and init the Accumulator for this [[AggregateFunction]].** @return the accumulator with the initial value*/def createAccumulator(): ACC // MANDATORY/*** Processes the input values and update the provided accumulator instance. The method* accumulate can be overloaded with different custom types and arguments. An AggregateFunction* requires at least one accumulate() method.** @param accumulator the accumulator which contains the current aggregated results* @param [user defined inputs] the input value (usually obtained from a new arrived data).*/def accumulate(accumulator: ACC, [user defined inputs]): Unit // MANDATORY/*** Retracts the input values from the accumulator instance. The current design assumes the* inputs are the values that have been previously accumulated. The method retract can be* overloaded with different custom types and arguments. This function must be implemented for* datastream bounded over aggregate.** @param accumulator the accumulator which contains the current aggregated results* @param [user defined inputs] the input value (usually obtained from a new arrived data).*/def retract(accumulator: ACC, [user defined inputs]): Unit // OPTIONAL/*** Merges a group of accumulator instances into one accumulator instance. This function must be* implemented for datastream session window grouping aggregate and dataset grouping aggregate.** @param accumulator the accumulator which will keep the merged aggregate results. It should* be noted that the accumulator may contain the previous aggregated* results. Therefore user should not replace or clean this instance in the* custom merge method.* @param its an [[java.lang.Iterable]] pointed to a group of accumulators that will be* merged.*/def merge(accumulator: ACC, its: java.lang.Iterable[ACC]): Unit // OPTIONAL/*** Called every time when an aggregation result should be materialized.* The returned value could be either an early and incomplete result* (periodically emitted as data arrive) or the final result of the* aggregation.** @param accumulator the accumulator which contains the current* aggregated results* @return the aggregation result*/def getValue(accumulator: ACC): T // MANDATORYh/*** Resets the accumulator for this [[AggregateFunction]]. This function must be implemented for* dataset grouping aggregate.** @param accumulator the accumulator which needs to be reset*/def resetAccumulator(accumulator: ACC): Unit // OPTIONAL/*** Returns true if this AggregateFunction can only be applied in an OVER window.** @return true if the AggregateFunction requires an OVER window, false otherwise.*/def requiresOver: Boolean = false // PRE-DEFINED/*** Returns the TypeInformation of the AggregateFunction's result.** @return The TypeInformation of the AggregateFunction's result or null if the result type* should be automatically inferred.*/def getResultType: TypeInformation[T] = null // PRE-DEFINED/*** Returns the TypeInformation of the AggregateFunction's accumulator.** @return The TypeInformation of the AggregateFunction's accumulator or null if the* accumulator type should be automatically inferred.*/def getAccumulatorType: TypeInformation[ACC] = null // PRE-DEFINED }
以下示例说明如何 算子操作
- 定义一个
AggregateFunction计算给定列的加权平均值, - 在
TableEnvironment和中注册函数 - 在查询中使用该函数。
为了计算加权平均值,累加器需要存储已累积的所有数据的加权和和计数。在我们的示例中,我们将一个类定义为WeightedAvgAccum累加器。Flink的检查点机制自动备份累加器,并在无法确保一次性语义的情况下进行恢复。
accumulate()我们的方法WeightedAvg AggregateFunction有三个输入。第一个是WeightedAvgAccum累加器,另外两个是用户定义的输入:输入值ivalue和输入的权重iweight。虽然retract(),merge()和resetAccumulator()方法不是强制性的最聚集的类型,我们提供以下举例它们。请注意,我们使用Java基本类型和定义getResultType(),并getAccumulatorType()在Scala例如方法,因为Flink类型提取不Scala类型的工作非常好。
/*** Accumulator for WeightedAvg.*/public static class WeightedAvgAccum {public long sum = 0;public int count = 0;}/*** Weighted Average user-defined aggregate function.*/public static class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccum> {@Overridepublic WeightedAvgAccum createAccumulator() {return new WeightedAvgAccum();}@Overridepublic Long getValue(WeightedAvgAccum acc) {if (acc.count == 0) {return null;} else {return acc.sum / acc.count;}}public void accumulate(WeightedAvgAccum acc, long iValue, int iWeight) {acc.sum += iValue * iWeight;acc.count += iWeight;}public void retract(WeightedAvgAccum acc, long iValue, int iWeight) {acc.sum -= iValue * iWeight;acc.count -= iWeight;}public void merge(WeightedAvgAccum acc, Iterable<WeightedAvgAccum> it) {Iterator<WeightedAvgAccum> iter = it.iterator();while (iter.hasNext()) {WeightedAvgAccum a = iter.next();acc.count += a.count;acc.sum += a.sum;}}public void resetAccumulator(WeightedAvgAccum acc) {acc.count = 0;acc.sum = 0L;}}// register functionStreamTableEnvironment tEnv = ...tEnv.registerFunction("wAvg", new WeightedAvg());// use functiontEnv.sqlQuery("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user");
import java.lang.{Long => JLong, Integer => JInteger}import org.apache.flink.api.java.tuple.{Tuple1 => JTuple1}import org.apache.flink.api.java.typeutils.TupleTypeInfoimport org.apache.flink.table.api.Typesimport org.apache.flink.table.functions.AggregateFunction/*** Accumulator for WeightedAvg.*/class WeightedAvgAccum extends JTuple1[JLong, JInteger] {sum = 0Lcount = 0}/*** Weighted Average user-defined aggregate function.*/class WeightedAvg extends AggregateFunction[JLong, CountAccumulator] {override def createAccumulator(): WeightedAvgAccum = {new WeightedAvgAccum}override def getValue(acc: WeightedAvgAccum): JLong = {if (acc.count == 0) {null} else {acc.sum / acc.count}}def accumulate(acc: WeightedAvgAccum, iValue: JLong, iWeight: JInteger): Unit = {acc.sum += iValue * iWeightacc.count += iWeight}def retract(acc: WeightedAvgAccum, iValue: JLong, iWeight: JInteger): Unit = {acc.sum -= iValue * iWeightacc.count -= iWeight}def merge(acc: WeightedAvgAccum, it: java.lang.Iterable[WeightedAvgAccum]): Unit = {val iter = it.iterator()while (iter.hasNext) {val a = iter.next()acc.count += a.countacc.sum += a.sum}}def resetAccumulator(acc: WeightedAvgAccum): Unit = {acc.count = 0acc.sum = 0L}override def getAccumulatorType: TypeInformation[WeightedAvgAccum] = {new TupleTypeInfo(classOf[WeightedAvgAccum], Types.LONG, Types.INT)}override def getResultType: TypeInformation[JLong] = Types.LONG}// register function val tEnv: StreamTableEnvironment = ???tEnv.registerFunction("wAvg", new WeightedAvg())// use function tEnv.sqlQuery("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user")
实施UDF的最佳实践
Table API和SQL代码生成在内部尝试尽可能地使用原始值。用户定义的函数可以通过对象创建,转换和(un)装箱引入很多开销。因此,强烈建议将参数和结果类型声明为基本类型而不是它们的盒装类。Types.DATE并且Types.TIME也可以表示为int。Types.TIMESTAMP可以表示为long。
我们建议用户定义的函数应该由Java而不是Scala编写,因为Scala类型对Flink的类型提取器构成了挑战。
将UDF与运行时集成
有时,用户定义的函数可能需要获取全局运行时信息,或者在实际工作之前进行一些设置/清理工作。用户定义的函数提供open()和close()方法可以被覆盖,并提供与RichFunctionDataSet或DataStream API中的方法类似的函数。
open()在评估方法之前调用该方法一次。在close()该评价方法最后一次通话之后方法。
该open()方法提供FunctionContext包含关于执行用户定义的函数的上下文的信息,例如度量标准组,分布式缓存文件或全局作业参数。
通过调用以下相应的方法可以获得以下信息FunctionContext:
| 方法 | 描述 |
|---|---|
getMetricGroup() |
此并行子任务的度量标准组。 |
getCachedFile(name) |
分布式缓存文件的本地临时文件副本。 |
getJobParameter(name, defaultValue) |
与给定键关联的全局作业参数值。 |
以下示例代码段显示了如何FunctionContext在标量函数中使用以访问全局作业参数:
public class HashCode extends ScalarFunction {private int factor = 0;@Overridepublic void open(FunctionContext context) throws Exception {// access "hashcode_factor" parameter// "12" would be the default value if parameter does not existfactor = Integer.valueOf(context.getJobParameter("hashcode_factor", "12"));}public int eval(String s) {return s.hashCode() * factor;}}ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();BatchTableEnvironment tableEnv = TableEnvironment.getTableEnvironment(env);// set job parameterConfiguration conf = new Configuration();conf.setString("hashcode_factor", "31");env.getConfig().setGlobalJobParameters(conf);// register the functiontableEnv.registerFunction("hashCode", new HashCode());// use the function in Java Table APImyTable.select("string, string.hashCode(), hashCode(string)");// use the function in SQLtableEnv.sqlQuery("SELECT string, HASHCODE(string) FROM MyTable");
object hashCode extends ScalarFunction {var hashcode_factor = 12override def open(context: FunctionContext): Unit = {// access "hashcode_factor" parameter// "12" would be the default value if parameter does not existhashcode_factor = context.getJobParameter("hashcode_factor", "12").toInt}def eval(s: String): Int = {s.hashCode() * hashcode_factor}}val tableEnv = TableEnvironment.getTableEnvironment(env)// use the function in Scala Table API myTable.select('string, hashCode('string))// register and use the function in SQL tableEnv.registerFunction("hashCode", hashCode)tableEnv.sqlQuery("SELECT string, HASHCODE(string) FROM MyTable")

若有收获,就点个赞吧
0 人点赞
