JobManager 高可用
JobManager High Availability (HA)
JobManager与Flink部署有关,它会负责任务调度以及集群资源管理。
The JobManager coordinates every Flink deployment. It is responsible for both scheduling and resource management.
默认情况下,每一个Flink集群实例只有一个JobManager。这将会导致单点故障:如果这个JobManager挂掉了,程序将没有办法提交到集群,使得运行失败。
By default, there is a single JobManager instance per Flink cluster. This creates a single point of failure (SPOF): if the JobManager crashes, no new programs can be submitted and running programs fail.
通过JobManager高可用机制,你可以消除单点故障问题,使故障中的JobManager恢复。你均可以为独立模式以及Yarn集群模式配置高可用。
With JobManager High Availability, you can recover from JobManager failures and thereby eliminate the SPOF. You can configure high availability for both standalone and YARN clusters.
独立集群的高可用
Standalone Cluster High Availability
对于独立群集,JobManager高可用性的一般概念是,任何时候都有一个单独的前导JobManager和多个备用JobManagers,以便在首要JobManager失败时接管首要JobManager。这样保证了没有单点失败,一旦备用JobManager取得了领导权,程序可以继续运行。主备JobManager之间没有明确的区别。每一个JobManager可以担当主或者备的角色。
The general idea of JobManager high availability for standalone clusters is that there is a single leading JobManager at any time and multiple standby JobManagers to take over leadership in case the leader fails. This guarantees that there is no single point of failure and programs can make progress as soon as a standby JobManager has taken leadership. There is no explicit distinction between standby and master JobManager instances. Each JobManager can take the role of master or standby.
如下例,集群中有三个JobManager实例:
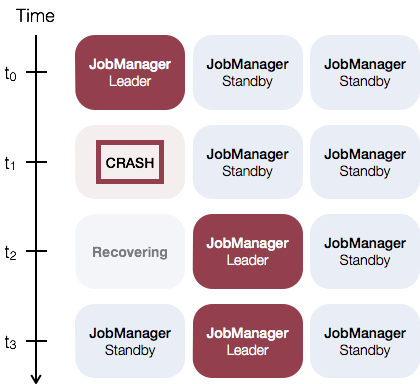
As an example, consider the following setup with three JobManager instances:
设置
Configuration
为了启动JobManager高可用,你必须在zookeeper中设置高可用模式,配置zookeeper,在matser 文件中设置所有的JobManager地址和他们的网页端口。
To enable JobManager High Availability you have to set the high-availability mode to zookeeper, configure a ZooKeeper quorum and set up a masters file with all JobManagers hosts and their web UI ports.
Flink 利用 ZooKeeper 在所有正在运行的JobManager实例之间进行分布式协调。ZooKeeper是Flink的独立服务,通过领导者选举和轻量级一致状态存储提供高度可靠的分布式协调。查阅Zookeeper入门手册获取更多关于Zookeeper的信息。Flink包含一个简单的Zookeeper 安装脚本。
Flink leverages ZooKeeper for distributed coordination between all running JobManager instances. ZooKeeper is a separate service from Flink, which provides highly reliable distributed coordination via leader election and light-weight consistent state storage. Check out ZooKeeper’s Getting Started Guide for more information about ZooKeeper. Flink includes scripts to bootstrap a simple ZooKeeper installation.
主文件
Masters File (masters)
要启动HA群集,请在 conf/masters 中配置主文件:
In order to start an HA-cluster configure the masters file in conf/masters:
主文件: 主文件包含所有JobManager的地址和端口信息。
jobManagerAddress1:webUIPort1[...]jobManagerAddressX:webUIPortX
masters file: The masters file contains all hosts, on which JobManagers are started, and the ports to which the web user interface binds.
jobManagerAddress1:webUIPort1[...]jobManagerAddressX:webUIPortX
默认情况下,JobManager会随机选择一个端口来内部通信。你可以通过关键字 high-availability.jobmanager.port 来修改通信端口。这个关键字接受单一端口(例如 50010),端口号段(50000-50025)或者他们的组合模式(50010,50011,50020-50025,50050-50075)。
By default, the job manager will pick a random port for inter process communication. You can change this via the high-availability.jobmanager.port key. This key accepts single ports (e.g. 50010), ranges (50000-50025), or a combination of both (50010,50011,50020-50025,50050-50075).
配置文件(flink-conf.yaml)
Config File (flink-conf.yaml)
为了启动高可用,在配置文件 conf/flink-conf.yaml 中添加以下配置项:
In order to start an HA-cluster add the following configuration keys to conf/flink-conf.yaml:
高可用模式 (必需): 高可用模式必须在
conf/flink-conf.yaml中设置zookeeper才能启用高可用模式。或者,此选项可以设置为Flink应该用于创建高可用服务实例的工厂类FQN。high-availability: zookeeper
high-availability mode (required): The high-availability mode has to be set in
conf/flink-conf.yamlto zookeeper in order to enable high availability mode. Alternatively this option can be set to FQN of factory class Flink should use to create HighAvailabilityServices instance.high-availability: zookeeper
zookeeper 仲裁 (必需): zookeeper仲裁是zookeeper服务的一个复制组,它提供了分布式协调服务。
high-availability.zookeeper.quorum: address1:2181[,...],addressX:2181
每一个addressX:port表示Flink可以在给定的地址和端口访问的zookeeper服务。
ZooKeeper quorum (required): A ZooKeeper quorum is a replicated group of ZooKeeper servers, which provide the distributed coordination service.
high-availability.zookeeper.quorum: address1:2181[,...],addressX:2181
Each addressX:port refers to a ZooKeeper server, which is reachable by Flink at the given address and port.
Zookeeper 根节点 (推荐): 在Zookeeper根节点上放置所有的集群节点。
high-availability.zookeeper.path.root: /flink
ZooKeeper root (recommended): The root ZooKeeper node, under which all cluster nodes are placed.
high-availability.zookeeper.path.root: /flink
Zookeeper 集群Id (推荐): 在该节点下保存集群的所有必需协调数据。
high-availability.cluster-id: /default_ns # important: customize per cluster
ZooKeeper cluster-id (recommended): The cluster-id ZooKeeper node, under which all required coordination data for a cluster is placed.
high-availability.cluster-id: /default_ns # important: customize per cluster
重要: 在运行yarn集群时 你不能手动的设置yarn会话或者其他集群管理。在这种情况下,集群id会根据应用id自动生存,手动设置集群id会覆盖Yarn的配置。反过来,使用-z CLI选项指定cluster-id会覆盖手动配置。如果在裸机上运行多个Flink 高可用群集,则必须为每个群集手动配置单独的群集ID。
Important: You should not set this value manually when running a YARN cluster, a per-job YARN session, or on another cluster manager. In those cases a cluster-id is automatically being generated based on the application id. Manually setting a cluster-id overrides this behaviour in YARN. Specifying a cluster-id with the -z CLI option, in turn, overrides manual configuration. If you are running multiple Flink HA clusters on bare metal, you have to manually configure separate cluster-ids for each cluster.
存储路径 (必需): JobManager元数据存储在文件系统的storageDir中,只有指向此状态的指针存储在Zookeeper中。
high-availability.storageDir: hdfs:///flink/recovery
Storage directory (required): JobManager metadata is persisted in the file system storageDir and only a pointer to this state is stored in ZooKeeper.
high-availability.storageDir: hdfs:///flink/recovery
存储路径保存了恢复失败的JobManager需要的所有元数据。
The
storageDirstores all metadata needed to recover a JobManager failure.
配置好主服务器和zookeeper仲裁机制后,你可以像往常一样使用提供的集群启动脚本。它们将启动一个高可用集群。记住当你执行脚本的时候,zookeeper仲裁机制将会运行,确保为你正在启动的每个HA集群配置单独的zookeeper根路径。
After configuring the masters and the ZooKeeper quorum, you can use the provided cluster startup scripts as usual. They will start an HA-cluster. Keep in mind that the ZooKeeper quorum has to be running when you call the scripts and make sure to configure a separate ZooKeeper root path for each HA cluster you are starting.
示例:有两个JobManager的standalone模式集群
Example: Standalone Cluster with 2 JobManagers
在
conf/flink-conf.yaml配置高可用模式和zookeeper仲裁机制:high-availability: zookeeperhigh-availability.zookeeper.quorum: localhost:2181high-availability.zookeeper.path.root: /flinkhigh-availability.cluster-id: /cluster_one # important: customize per clusterhigh-availability.storageDir: hdfs:///flink/recovery
Configure high availability mode and ZooKeeper quorum in
conf/flink-conf.yaml:high-availability: zookeeperhigh-availability.zookeeper.quorum: localhost:2181high-availability.zookeeper.path.root: /flinkhigh-availability.cluster-id: /cluster_one # important: customize per clusterhigh-availability.storageDir: hdfs:///flink/recovery
在
conf/masters配置主服务:localhost:8081localhost:8082
Configure masters in
conf/masters:localhost:8081localhost:8082
在
conf/zoo.cfg中中配置zookeeper服务 (目前它只可能再每一台机器上运行一个zookeeper服务):server.0=localhost:2888:3888
Configure ZooKeeper server in
conf/zoo.cfg(currently it’s only possible to run a single ZooKeeper server per machine):server.0=localhost:2888:3888
启动zookeeper仲裁机制:
$ bin/start-zookeeper-quorum.shStarting zookeeper daemon on host localhost.
Start ZooKeeper quorum:
$ bin/start-zookeeper-quorum.shStarting zookeeper daemon on host localhost.
启动高可用集群:
$ bin/start-cluster.shStarting HA cluster with 2 masters and 1 peers in ZooKeeper quorum.Starting jobmanager daemon on host localhost.Starting jobmanager daemon on host localhost.Starting taskmanager daemon on host localhost.
Start an HA-cluster:
$ bin/start-cluster.shStarting HA cluster with 2 masters and 1 peers in ZooKeeper quorum.Starting jobmanager daemon on host localhost.Starting jobmanager daemon on host localhost.Starting taskmanager daemon on host localhost.
停止zookeeper仲裁和集群:
$ bin/stop-cluster.shStopping taskmanager daemon (pid: 7647) on localhost.Stopping jobmanager daemon (pid: 7495) on host localhost.Stopping jobmanager daemon (pid: 7349) on host localhost.$ bin/stop-zookeeper-quorum.shStopping zookeeper daemon (pid: 7101) on host localhost.
Stop ZooKeeper quorum and cluster:
$ bin/stop-cluster.shStopping taskmanager daemon (pid: 7647) on localhost.Stopping jobmanager daemon (pid: 7495) on host localhost.Stopping jobmanager daemon (pid: 7349) on host localhost.$ bin/stop-zookeeper-quorum.shStopping zookeeper daemon (pid: 7101) on host localhost.
高可用YARN集群
当运行一个高可用YARN集群,我们不必运行多个JobManager实例,只需要一个,由yarn在失败时重新启动。确切的行为取决于你使用的yarn版本。
YARN Cluster High Availability
When running a highly available YARN cluster, we don’t run multiple JobManager (ApplicationMaster) instances, but only one, which is restarted by YARN on failures. The exact behaviour depends on on the specific YARN version you are using.
配置
Configuration
最大主应用尝试次数(yarn-site.xml)
Maximum Application Master Attempts (yarn-site.xml)
你必须在yarn-site.xml为你的主应用上的yarn设置最大尝试次数。
<property><name>yarn.resourcemanager.am.max-attempts</name><value>4</value><description>The maximum number of application master execution attempts.</description></property>
You have to configure the maximum number of attempts for the application masters for your YARN setup in yarn-site.xml:
<property><name>yarn.resourcemanager.am.max-attempts</name><value>4</value><description>The maximum number of application master execution attempts.</description></property>
对当前版本的yarn的默认值是2(表示单个JobManager的失败的可容忍的)。
The default for current YARN versions is 2 (meaning a single JobManager failure is tolerated).
应用尝试(flink-conf.yaml)
Application Attempts (flink-conf.yaml)
为了配置集群高可用(见上,你必须在conf/flink-conf.yaml设置最大尝试次数。
yarn.application-attempts: 10
In addition to the HA configuration (see above), you have to configure the maximum attempts in conf/flink-conf.yaml:
yarn.application-attempts: 10
这意味着应用在失败后可以重启可以被重启9次(9次重启+1次初始化)。当YARN操作需要时:抢占,节点硬件故障或重启,或nodemanager重新同步,YARN可以执行重启。这些重启将不会记录在 yarn.application-attemps 中,查阅 Jian Fang’s blog post。值得注意的是, yarn.application.am.max-attempts 是应用程序重启的上限。因此Flink中设置的应用程序尝试次数不能超过启动YARN的集群设置次数。
This means that the application can be restarted 9 times for failed attempts before YARN fails the application (9 retries + 1 initial attempt). Additional restarts can be performed by YARN if required by YARN operations: Preemption, node hardware failures or reboots, or NodeManager resyncs. These restarts are not counted against yarn.application-attempts, see Jian Fang’s blog post. It’s important to note that yarn.resourcemanager.am.max-attempts is an upper bound for the application restarts. Therefore, the number of application attempts set within Flink cannot exceed the YARN cluster setting with which YARN was started.
容器关闭行为
Container Shutdown Behaviour
- YARN 2.3.0 < version < 2.4.0. 当主应用失败,所有的容器都被重启。
- YARN 2.4.0 < version < 2.6.0. TaskManager容器在主应用程序故障期间保持活跃,这具有以下优点:启动时间更快并且用户不必等待再次获得容器资源。
YARN 2.6.0 <= version. 将尝试失败有效间隔设置为Flink的Akka超时值。尝试失败有效间隔表示只有在系统一个间隔期间达到最大应用程序尝试次数才会终止应用程序。这避免了长久的工作会耗尽它的应用程序尝试次数。
YARN 2.3.0 < version < 2.4.0. All containers are restarted if the application master fails.
- YARN 2.4.0 < version < 2.6.0. TaskManager containers are kept alive across application master failures. This has the advantage that the startup time is faster and that the user does not have to wait for obtaining the container resources again.
- YARN 2.6.0 <= version: Sets the attempt failure validity interval to the Flinks’ Akka timeout value. The attempt failure validity interval says that an application is only killed after the system has seen the maximum number of application attempts during one interval. This avoids that a long lasting job will deplete it’s application attempts.
注意: Hadoop YARN 2.4.0存在一个重大问题(在2.5.0版本中修复)阻止容器从应用程序的Master Mangaer或Job Manager容器中重启。详情查阅FLINK-4142 。我们推荐使用最新版本Hadoop 2.5.0为高可用设置YARN。
Note: Hadoop YARN 2.4.0 has a major bug (fixed in 2.5.0) preventing container restarts from a restarted Application Master/Job Manager container. See FLINK-4142 for details. We recommend using at least Hadoop 2.5.0 for high availability setups on YARN.
举例: 高可用的YARN缓存
Example: Highly Available YARN Session
在
conf/flink-conf.yaml中设置高可用模式和zookeeper选举:high-availability: zookeepercihigh-availability.zookeeper.quorum: localhost:2181high-availability.storageDir: hdfs:///flink/recoveryhigh-availability.zookeeper.path.root: /flinkyarn.application-attempts: 10
Configure HA mode and ZooKeeper quorum in
conf/flink-conf.yaml:high-availability: zookeepercihigh-availability.zookeeper.quorum: localhost:2181high-availability.storageDir: hdfs:///flink/recoveryhigh-availability.zookeeper.path.root: /flinkyarn.application-attempts: 10
在
conf/zoo.cfg中设置Zookeeper服务 (目前每台机器只能运行一个Zookeeper服务)server.0=localhost:2888:3888
Configure ZooKeeper server in
conf/zoo.cfg(currently it’s only possible to run a single ZooKeeper server per machine):server.0=localhost:2888:3888
启动Zookeeper 选举:
$ bin/start-zookeeper-quorum.shStarting zookeeper daemon on host localhost.
Start ZooKeeper quorum:
$ bin/start-zookeeper-quorum.shStarting zookeeper daemon on host localhost.
启动一个高可用集群:
$ bin/yarn-session.sh -n 2
Start an HA-cluster:
$ bin/yarn-session.sh -n 2
配置Zookeeper安全性
Configuring for Zookeeper Security
如果Zookeeper是在Kerberos运行的安全模式,你可以根据需要覆盖 flink-conf.yaml中的以下配置:
zookeeper.sasl.service-name: zookeeper # default is "zookeeper". If the ZooKeeper quorum is configured# with a different service name then it can be supplied here.zookeeper.sasl.login-context-name: Client # default is "Client". The value needs to match one of the values# configured in "security.kerberos.login.contexts".
在Flink上配置Kerberos安全模式的更多信息,请查阅here. 你也可以查阅here 更多关于在Flink内部设置基于kerberos安全性的细节。
If ZooKeeper is running in secure mode with Kerberos, you can override the following configurations in flink-conf.yaml as necessary:
zookeeper.sasl.service-name: zookeeper # default is "zookeeper". If the ZooKeeper quorum is configured# with a different service name then it can be supplied here.zookeeper.sasl.login-context-name: Client # default is "Client". The value needs to match one of the values# configured in "security.kerberos.login.contexts".
For more information on Flink configuration for Kerberos security, please see here. You can also find here further details on how Flink internally setups Kerberos-based security.
Bootstrap Zookeeper
Bootstrap ZooKeeper
如果你没有运行的Zookeeper安装,你可以使用Flink附带的帮助程序脚本。
conf/zoo.cfg 中有一个Zookeeper配置模板。你可以使用 server.X 条目配置主机以运行Zookeeper,其中X是每个服务器的唯一ID:
server.X=addressX:peerPort:leaderPort[...]server.Y=addressY:peerPort:leaderPort
If you don’t have a running ZooKeeper installation, you can use the helper scripts, which ship with Flink.
There is a ZooKeeper configuration template in conf/zoo.cfg. You can configure the hosts to run ZooKeeper on with the server.X entries, where X is a unique ID of each server:
server.X=addressX:peerPort:leaderPort[...]server.Y=addressY:peerPort:leaderPort
bin/start-zookeeper-quorum.sh 脚本将会在每一个配置的域名下启动一个Zookeeper服务。启动的进程通过Flink包装器启动Zookeeper服务器,该包装器从 conf/zoo.cfg 读取配置,并确保为方便设置一些必需的配置项。在生产配置中,建议你安装自己的Zookeeper集群。
The script bin/start-zookeeper-quorum.sh will start a ZooKeeper server on each of the configured hosts. The started processes start ZooKeeper servers via a Flink wrapper, which reads the configuration from conf/zoo.cfg and makes sure to set some required configuration values for convenience. In production setups, it is recommended to manage your own ZooKeeper installation.

若有收获,就点个赞吧
0 人点赞
