spark sql 执行流程
spark sql使用方式分为两种,一种是直接写sql语句这个需要元数据库支持,另外一种时通过Dataset/DataFrame编写spark应用程序。spark sql执行过程分为: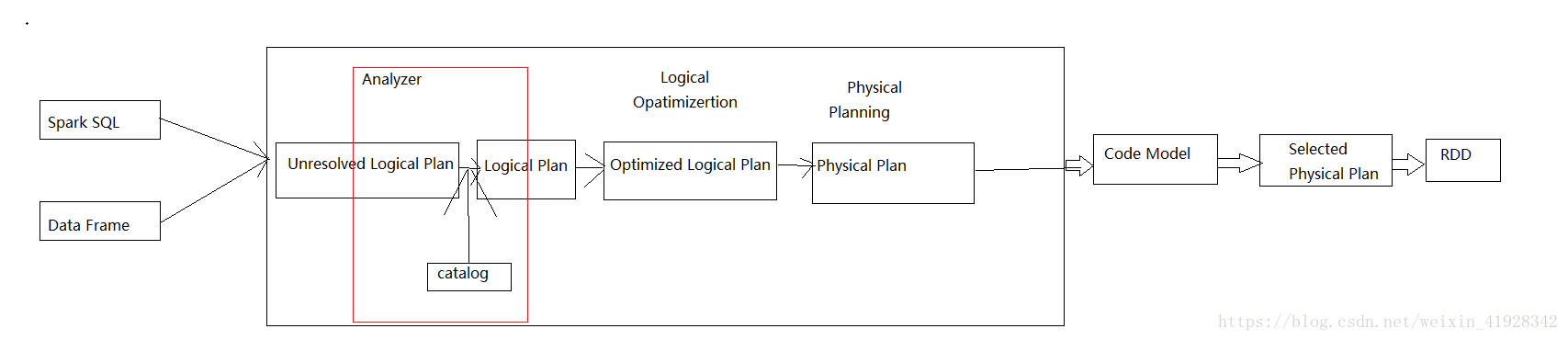
- sql语句首先被解析成Logical Plan
- Analyzer 阶段会使用事先定义好的 Rule对与Logical Plan进行转换
- 逻辑优化阶段Optimizer,这个阶段的优化器主要是基于规则的(Rule-based Optimizer,简称 RBO)比如:谓词下推,列裁剪,常量转换
- 生成可执行的物理计划阶段Physical Plan。核心思想是计算每个物理计划的代价,然后得到最优的物理计划(CBO)。
- 代码生成阶段底层还是基于sparkRDD去进行处理的
spark sql join 实现方式
Broadcast Hash Join
使用条件要求被广播的表需要小于 spark.sql.autoBroadcastJoinThreshold 所配置的值,默认是10M,也就是说要是一张小表join 一张大表。hash join的原理是首先spark 一般会将小表标识为buildtable,大表作为Probe table。根据hash将buildtable中的数据放到内存中如果放不下则dump到磁盘中。扫描probe table的每一行数据,每取到一行数据先更具关联条件去buildtable中找到对应的管理key,如果找到则join成功。
Shuffle Hash Join
Shuffle Hash Join的条件有以下几个:
- 分区的平均大小不超过spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M
- 基表不能被广播,比如left outer join时,只能广播右表
- 一侧的表要明显小于另外一侧,小的一侧将被广播(明显小于的定义为3倍小,此处为经验值)
过程:
适合一张小表(比上一个大一点)和一张大表进行Join。因为broadcast hash join 广播的表是小标所以可以避免shuffle提供性能。但是如果表大一点的话,我们如果同样的将表广播出去,因为被广播的表会首先被collect到driver端然后被冗余的发送到各个executor上所有表较大时采用broadcast join 会对driver端executor端造成较大的压力。首先将两张表按照join key 重新分区既shuffle,目的时让具有相同的key的记录分到对应的分区中。然后对对应的数据进行join,拿大表的数据来小标来匹配。Sort Merge Join
适合两张大表进行Join。可以看出如果两张都是大表上面的hash join方式时不适合的。首先将两张表的key 按照hask 分区(shuffle),保证相同的key值到相同的分区中,shuffle天然支持sort。排序后再把对应分区中的数据进行连接。可以看出无论数据有多大都不会直接将一侧的数据全部加载到内存中,而是即用既丢。因为两个序列的数据是排序的遇到相同的key则输出,如果不同左边小区左边,右边小取右边大大提高了join的效率
参考资料:
Spark SQL之Join优化
SparkSQL中的三种Join及其具体实现
Spark SQL join的三种实现方式
记录一次spark sql的优化过程

若有收获,就点个赞吧
0 人点赞
