概述
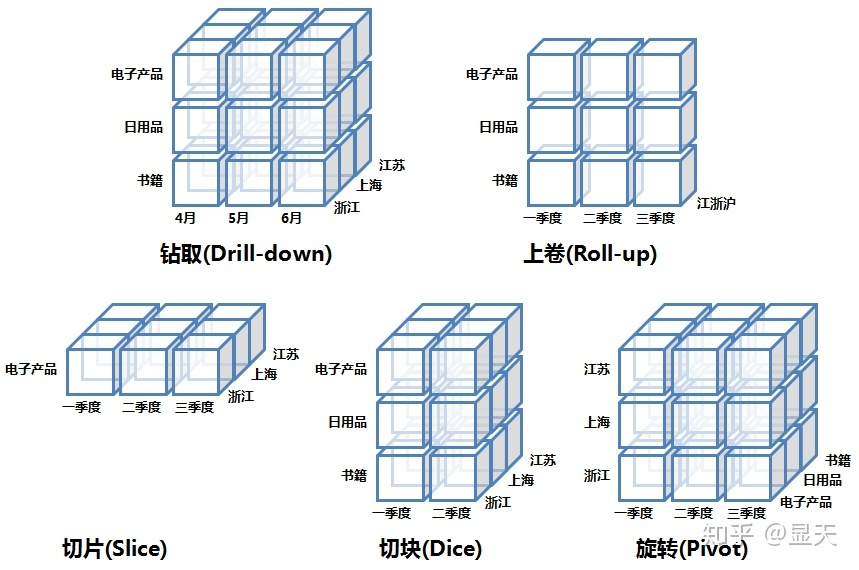
联机事务处理OLTP(On-line Transaction Processing)下面介绍数据立方体中最常见的五大操作:切片,切块,旋转,上卷,下钻。
- MPP即大规模并行处理(Massively Parallel Processor
- 搜索引擎架构的系统(Elasticsearch等)相对比MPP系统,在入库时将数据转换为倒排索引,采用Scatter-Gather计算模型,牺牲了灵活性换取很好的性能,在搜索类查询上能做到亚秒级响应。但是对于扫描聚合为主的查询,随着处理数据量的增加,响应时间也会退化到分钟级
- 预计算系统(Druid/Kylin等)则在入库时对数据进行预聚合,进一步牺牲灵活性换取性能,以实现对超大数据集的秒级响应。
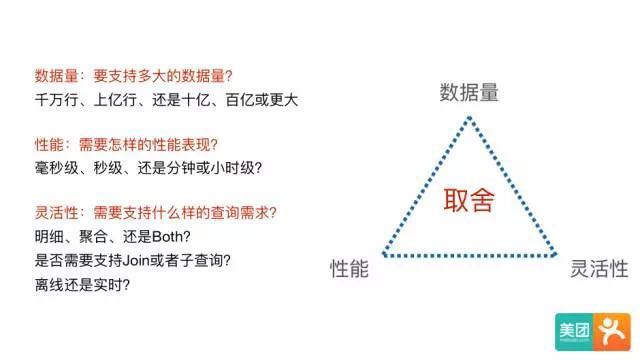
在调研了市面上主流的开源OLAP引擎后发现,目前还没有一个系统能够满足各种场景的查询需求。其本质原因是,没有一个系统能同时在数据量、性能、和灵活性三个方面做到完美,每个系统在设计时都需要在这三者间做出取舍。
框架对比
| Hive | SparkSql/FLinkSql | Kylin | Impala | Kudu | Druid | Presto | Doris | Clickhouse | |
|---|---|---|---|---|---|---|---|---|---|
| 原理划分 | 纯计算 | 纯计算 | 计算+存储 | 计算 | 存储 | 计算+存储 | 计算 | 计算+存储 | 计算+存储 |
| 依赖Hadoop生态 | 是 | 是 | 是 | 是 | 是 | 否 | 是 | 否 | 否 |
| 查询性能 | 小时,分钟级 | 小时,分钟级 | 秒 | 秒 | 秒/毫秒 | 秒 | 秒/毫秒 | 秒/耗秒 | |
| 特点 | sql解析成MR | Spark底层解析sql运行spark job | 预计算 | 内存计算 一般结合Kudu使用 |
OLAP+OLTP | 预计算 实时处理的时序性数据库 |
内存计算 | MPP 引入向量化 |
向量化 |
| 优势 | 稳定 数据量取决于hdfs |
生态对接丰富 复用spark底层优化 |
压秒级查询性能 | 高效利用cpu和内存性能>Presto>Spark | 实时写入 支持update/delete |
实时,批量摄入 支持kafka |
生态丰富支持Redis,mysql,kafka,iceberg | join能力 分析性能 |
单表性能最好 |
| 缺点 | 时间最长 | 多使用代码 | 只能针对预计算指标 浪费磁盘 指标列不能太多 |
内存要求高 稳定性不如hive |
全局事务需要自己实现 | 只能针对预计算指标 不支持sql 不支持join 不支持jdbc方式】 运维复杂 |
同Impala | 生态还在发展中 | 不能join 并发低 |

若有收获,就点个赞吧
0 人点赞
