SparkMllib 简介及功能介绍
- SparkMllib架构
- 1-Utils工具层和Spark基础架构层
- 2-JVM
- 3-RDD结合基于NetLib-Java之上Breeze抽象出了VectorInterface
- 4-抽象出了Matrices Interface
- 5-具体算法的应用,分类,回归,聚类,降维
6-需要具体的任务需要一定校验标准
- 如:分类问题AUC。ROC。Acurucy。Precision。F1-Score
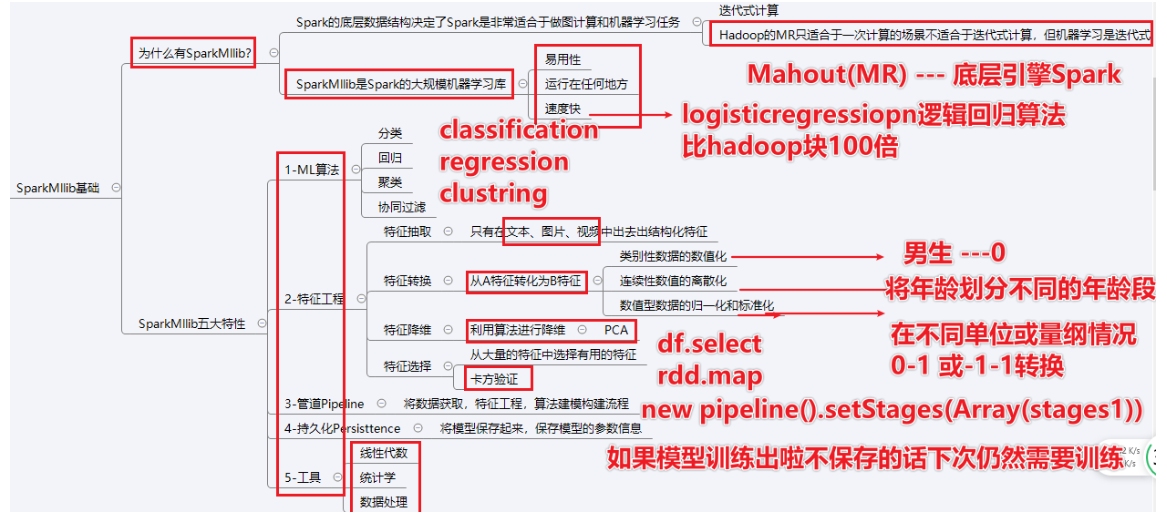
MLLIB是Spark的机器学习库。提供了利用Spark构建大规模和易用性的机器学习平台,组件:
(1) ML 算法:包括了分类、回归、聚类、降维、协同过滤
(2) Featurization 特征化:特征抽取、特征转换、特征降维、特征选择
(3) Pipelines 管道:tools for constructing, evaluating, and tuning ML Pipelines
(4) Persistence 持久化:模型的保存、读取、管道操作
(5) Utilities:提供了线性代数、统计学以及数据处理工具分类:
数据集角度:根据是否有标签类 分为监督学习(更具值是否是连续的分为分类和回归)和非监督学习(聚类分析)
任务角度出发:当前任务的类型:分类+回归+聚类特征工程
StringIndexer:
StringIndexer 将标签的字符串列编码为标签索引列。索引[0, numLabels)按标签频率排序,因此最常用的标签获得索引 0。如果输入列是数字,我们将其转换为字符串并索引字符
串值。当下游管道组件(例如 Estimator 或 Transformer 使用此字符串索引标签)时,必须将
组件的输入列设置为此字符串索引列名称。在许多情况下,您可以使用设置输入列
setInputCol.IndexToString
对称的 StringIndexer,IndexToString 将一列标签索引映射回包含原始标签作为字符串的 列。一个常见的用例是从标签生成索引 StringIndexer,使用这些索引训练模型,并从预测索 引列中检索原始标签 IndexToString
OneHotEncoder
单热编码将一列标签索引映射到一列二进制向量,最多只有一个单值。此编码允许期望 连续特征(例如 Logistic 回归)的算法使用分类特征。
VectorIndexer
VectorIndexer 可以自动将决定哪些 features 是类别的,并且可以将原始值转换成类别指 标。而在决策树和提升树算法中,能够确定类别特征指标,VectorIndexer 可以提升这些算法的 性能。
MinMaxScaler
MaxAbsScaler
VectorAssembler
VectorAssembler 是一个变换器,它将给定的列表组合到一个向量列中。将原始特征和 由不同特征变换器生成的特征组合成单个特征向量非常有用,以便训练 ML 模型,如逻辑回 归和决策树。VectorAssembler 接受以下输入列类型:所有数字类型,布尔类型和矢量类型。 在每一行中,输入列的值将按指定的顺序连接到一个向量中。
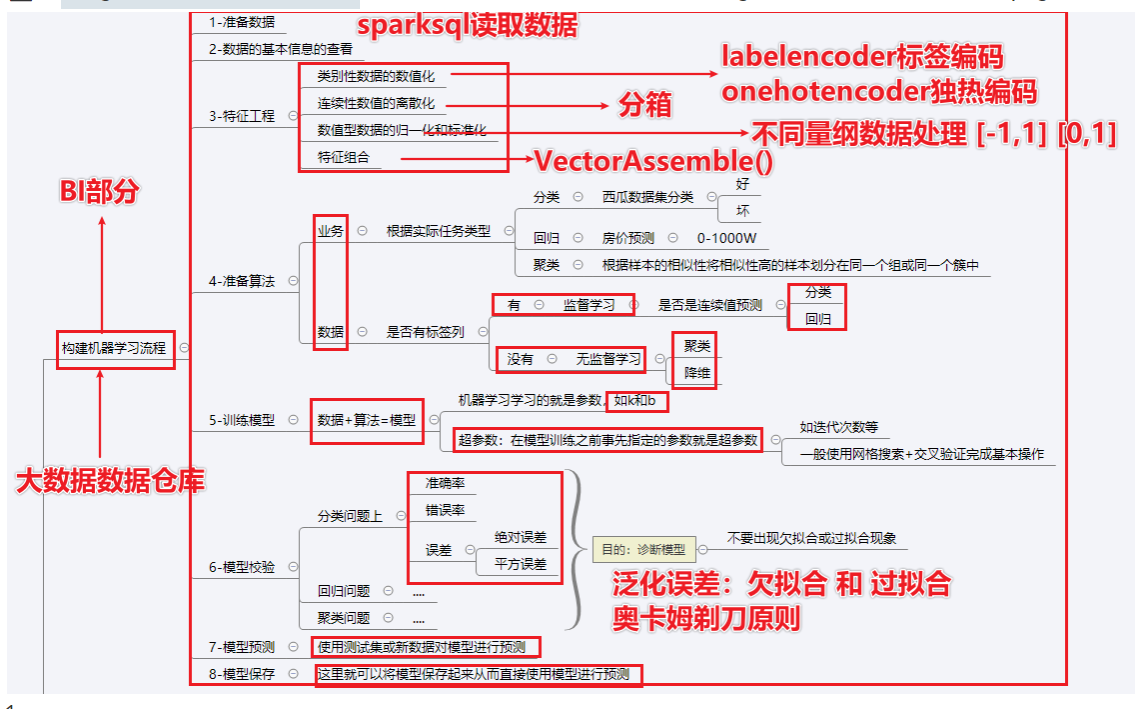
构建机器学习的流程
1.利用hie或者spark sql完成数据的特征数据的抽取
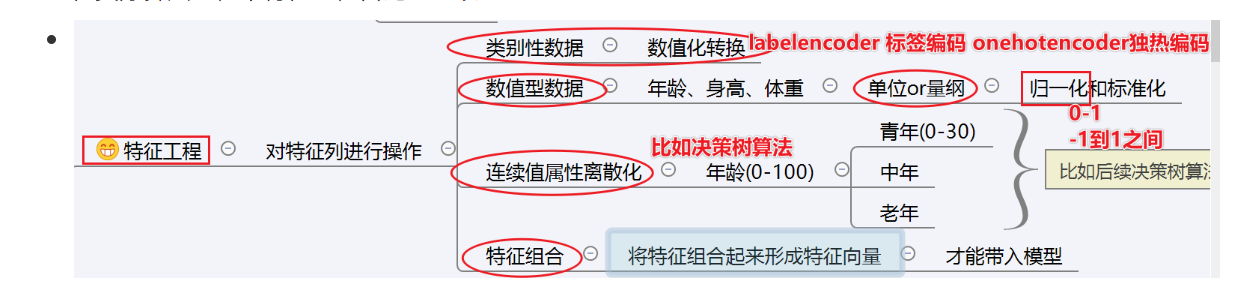
2.准备数据:数据清洗(缺省值,异常值),数据转换(日期转换,地区转换),特征工程对于特征列进行操作(类别型数据做数据的转换;值型数据比如年龄身高体重等数据大小做归一化和标准化;连续值属性离散:比如年龄;特征组合:将特征组合起来形成特征向量)
3.准备算法 监督学习(分类,回归),无监督学习(聚类)
4.训练模型(借助算法结合数据训练模型)
5.模型校验,模型的评价,模型泛化能力,体现在模型对于新数据或者测试集的准确率,比如:欠拟合(模型在训练和测试效果都很差,出现的原因一般否是模型过于简单。解决办法就是增加多项式,减少正则罚项),过拟合(表现为在训练集上效果较好,测试集效果较差,出现原因是模型过于复杂,数据不纯,数据量少可以通过增加正则罚项,增加清洗数据,重新采样)。总之模型的选择尽量遵循奥卡姆剃刀原则:在具备相同或相似的泛化误差的情况下,优先选择较为简单的模型
6.模型的保存
7.模型在新数据预测交叉验证

若有收获,就点个赞吧
0 人点赞
