1.使用
1.1下载地址:https://zookeeper.apache.org/releases.html
1.2zk集群部署一般部署2n+1(其中n为容忍的最大宕机数)
cp zoo_sample.cfg zoo.cfg#zk保存数据目录mkdir -p /export/server/zookeeper-3.4.6/zkdatas/vim zoo.cfgdataDir=/export/servers/zookeeper-3.4.9/zkdatas# 保留多少个快照autopurge.snapRetainCount=3# 日志多少小时清理一次autopurge.purgeInterval=1# 集群中服务器地址server.1=node1:2888:3888server.2=node2:2888:3888server.3=node3:2888:3888#选举使用echo 1 > /export/server/zookeeper-3.4.6/zkdatas/myid#各vm执行命令启动zk集群zkServer.sh start#查看zk角色zkServer.sh status#客户端命令连接zkCli.sh -server node2:2181#查看节点ls /#查看内容get /test
2.zookeeper的选举
初始化:每个服务都将自己id和zxid加载到内存中然后广播出去,每个服务都选自己为leader
循环阶段:节点对比自己的id,zxid和收到的对比,首先比较zxid找最大的,如果zxid相同找id最大的,找到后重新将最大的id广播出去,循环往复知道启动的服务达到集群的半数以上,选举完成
3.zookeeper的一致性问题总结
众所周知引入分布式后CAP理论,我们只能保证同时保证两个而不得不舍弃掉其中的一个特性。但是zk恰恰保证了强一致性。
leader接受到写请求后,首先事务封装(也有叫提议)然后转发给所有的follower,同时生成一个zxid(事务id),等待所有的follower发送ack响应,当收到半数以上的ack应答收,leader将事务预写本机内存,发送commit消息 (而follower收到提议后首先将数据写入本地磁盘成功后发送ack,当leader发送commit消息后采后写入内存)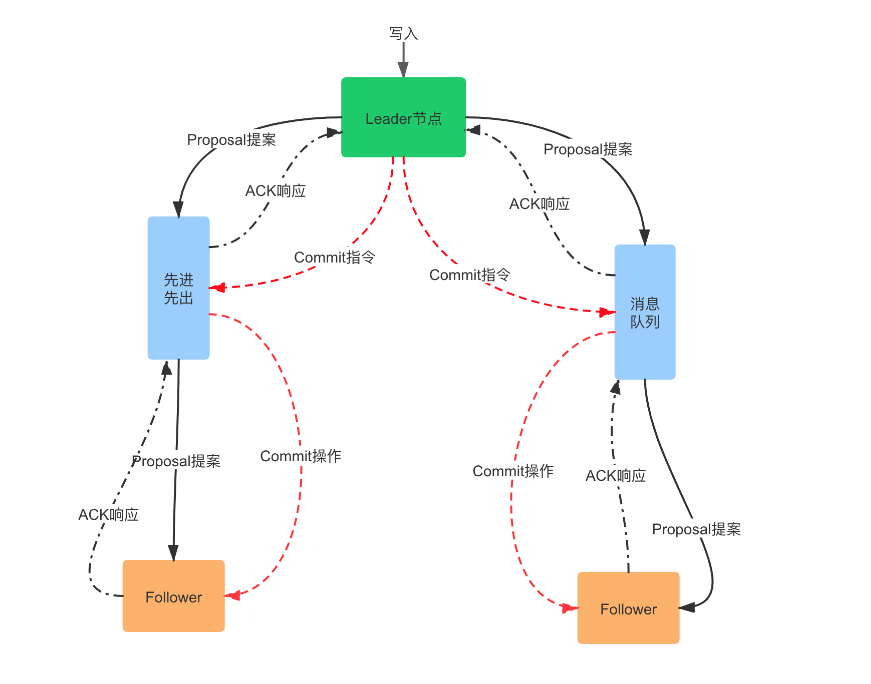

若有收获,就点个赞吧
0 人点赞
