MySQL
前言:在MySQL中设计表的时候,MySQL官方推荐不要使用uuid或者不连续不重复的雪花id(long形且唯一),而是推荐连续自增的主键id,官方的推荐是auto_increment,那么为什么不建议采用uuid,使用uuid究竟有什么坏处?
一、MySQL和程序实例
1.1: 要说明这个问题,首先来建立三张表,分别是user_auto_key,user_uuid,user_random_key,分别表示自动增长的主键,uuid作为主键,随机key作为主键,其它完全保持不变。根据控制变量法,只把每个表的主键使用不同的策略生成,而其他的字段完全一样,然后测试一下表的插入速度和查询速度:
注:这里的随机key其实是指用雪花算法算出来的前后不连续不重复无规律的id:一串18位长度的long值
id自动生成表: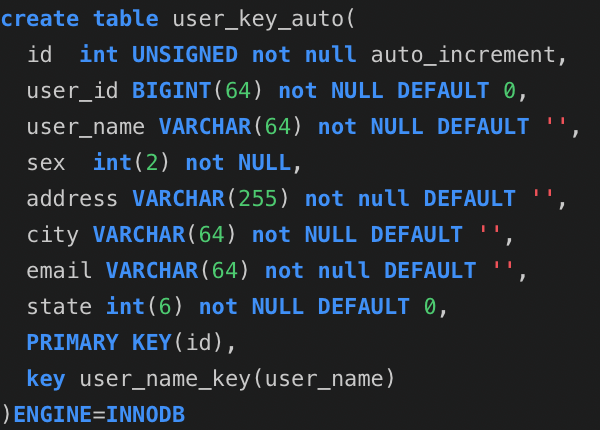
用户uuid表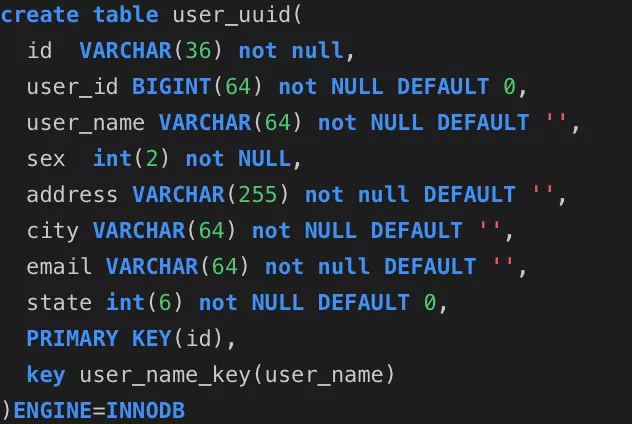
随机主键表: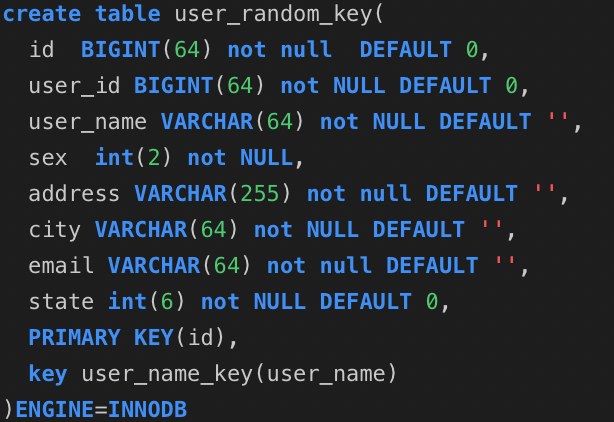
1.2、使用Spring的jdbcTemplate来实现增查测试:
技术框架:springboot+jdbcTemplate+junit+hutool,程序的原理就是连接自己的测试数据库,然后在相同的环境下写入同等数量的数据,来分析一下insert插入的时间来进行综合其效率,为了做到最真实的效果,所有的数据采用随机生成,比如名字、邮箱、地址都是随机生成。
import cn.hutool.core.collection.CollectionUtil;import com.mysqldemo.databaseobject.UserKeyAuto;import com.mysqldemo.databaseobject.UserKeyRandom;import com.mysqldemo.databaseobject.UserKeyUUID;import com.mysqldemo.diffkeytest.AutoKeyTableService;import com.mysqldemo.diffkeytest.RandomKeyTableService;import com.mysqldemo.diffkeytest.UUIDKeyTableService;import com.mysqldemo.util.JdbcTemplateService;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.util.StopWatch;import java.util.List;@SpringBootTest class MysqlDemoApplicationTests {@Autowired private JdbcTemplateService jdbcTemplateService;@Autowired private AutoKeyTableService autoKeyTableService;@Autowired private UUIDKeyTableService uuidKeyTableService;@Autowired private RandomKeyTableService randomKeyTableService;@Testvoid testDBTime() {StopWatch stopwatch = new StopWatch("执行sql时间消耗"); /** * auto_increment key任务 */final String insertSql = "INSERT INTO user_key_auto(user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?)";List<UserKeyAuto> insertData = autoKeyTableService.getInsertData();stopwatch.start("自动生成key表任务开始"); long start1 = System.currentTimeMillis();if (CollectionUtil.isNotEmpty(insertData)) {boolean insertResult = jdbcTemplateService.insert(insertSql, insertData, false);System.out.println(insertResult);}long end1 = System.currentTimeMillis();System.out.println("auto key消耗的时间:" + (end1 - start1));stopwatch.stop(); /** * uudID的key */final String insertSql2 = "INSERT INTO user_uuid(id,user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?,?)";List<UserKeyUUID> insertData2 = uuidKeyTableService.getInsertData();stopwatch.start("UUID的key表任务开始"); long begin = System.currentTimeMillis();if (CollectionUtil.isNotEmpty(insertData)) {boolean insertResult = jdbcTemplateService.insert(insertSql2, insertData2, true);System.out.println(insertResult);}long over = System.currentTimeMillis();System.out.println("UUID key消耗的时间:" + (over - begin));stopwatch.stop(); /** * 随机的long值key */final String insertSql3 = "INSERT INTO user_random_key(id,user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?,?)";List<UserKeyRandom> insertData3 = randomKeyTableService.getInsertData();stopwatch.start("随机的long值key表任务开始");Long start = System.currentTimeMillis();if (CollectionUtil.isNotEmpty(insertData)) {boolean insertResult = jdbcTemplateService.insert(insertSql3, insertData3, true);System.out.println(insertResult);}Long end = System.currentTimeMillis();System.out.println("随机key任务消耗时间:" + (end - start));stopwatch.stop();String result = stopwatch.prettyPrint();System.out.println(result);}}
1.3、程序写入结果
user_key_auto写入结果: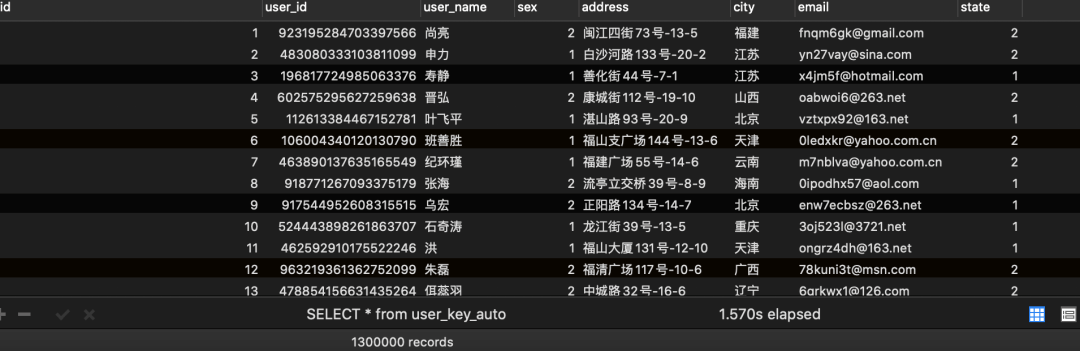
user_random_key写入结果: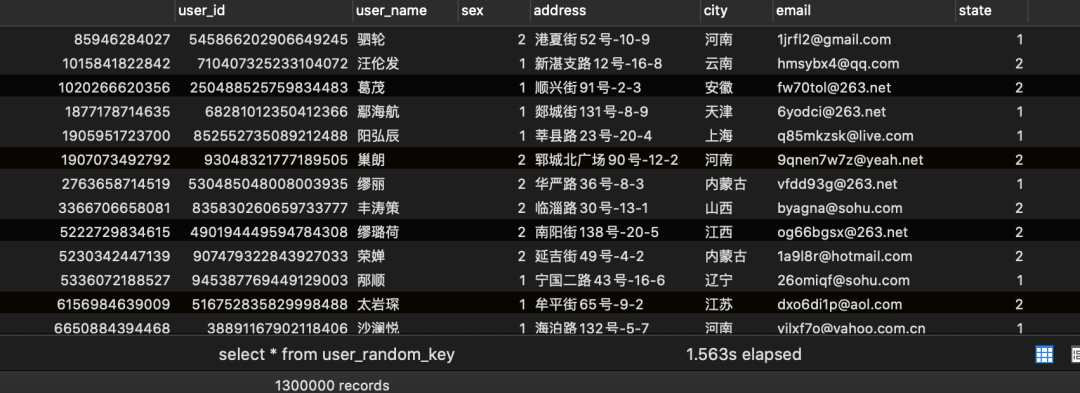
user_uuid表写入结果: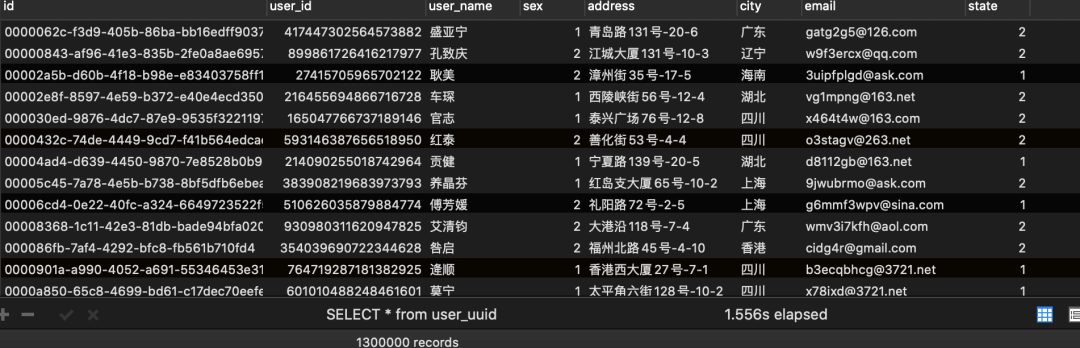
1.4、效率测试结果
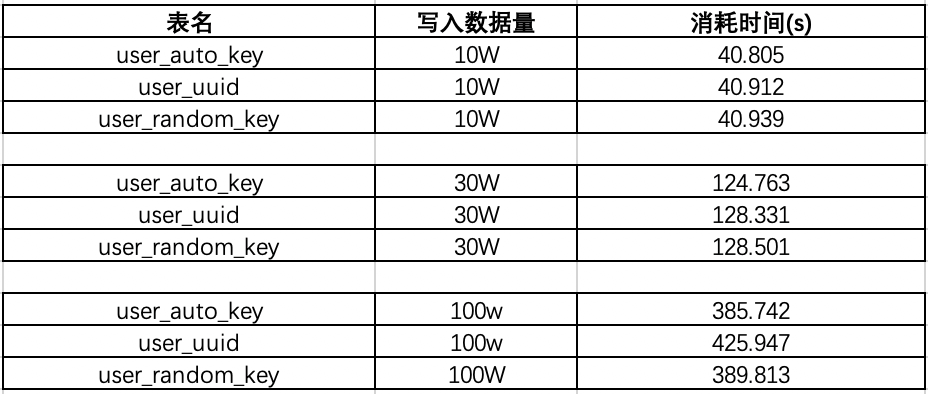
在已有数据量为130W的时候:再来测试一下插入10w数据,看看会有什么结果:
可以看出在数据量100W左右的时候,uuid的插入效率垫底,并且在后序增加了130W的数据,uudi的时间又直线下降。时间占用量总体可以打出的效率排名为:auto_key>random_key>uuid,uuid的效率最低,在数据量较大的情况下,效率直线下滑。那么为什么会出现这样的现象呢?带着疑问,来探讨一下这个问题:
二、使用uuid和自增id的索引结构对比
2.1、使用自增id的内部结构
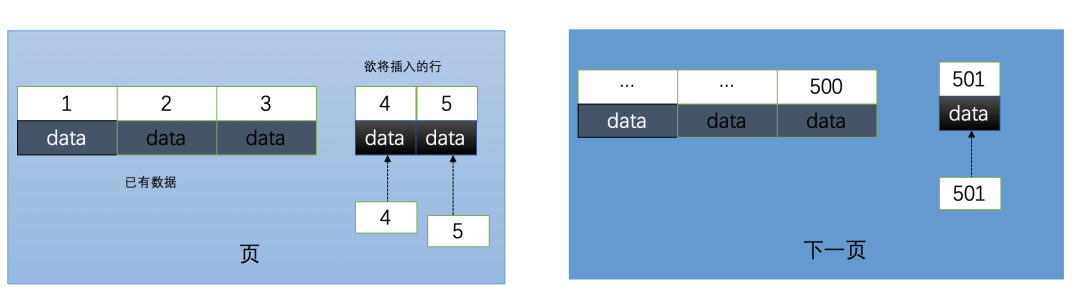
自增的主键的值是顺序的,所以Innodb把每一条记录都存储在一条记录的后面。当达到页面的最大填充因子时候(innodb默认的最大填充因子是页大小的15/16,会留出1/16的空间留作以后的修改):
①下一条记录就会写入新的页中,一旦数据按照这种顺序的方式加载,主键页就会近乎于顺序的记录填满,提升了页面的最大填充率,不会有页的浪费
②新插入的行一定会在原有的最大数据行下一行,MySQL定位和寻址很快,不会为计算新行的位置而做出额外的消耗
③减少了页分裂和碎片的产生
2.2、使用uuid的索引内部结构
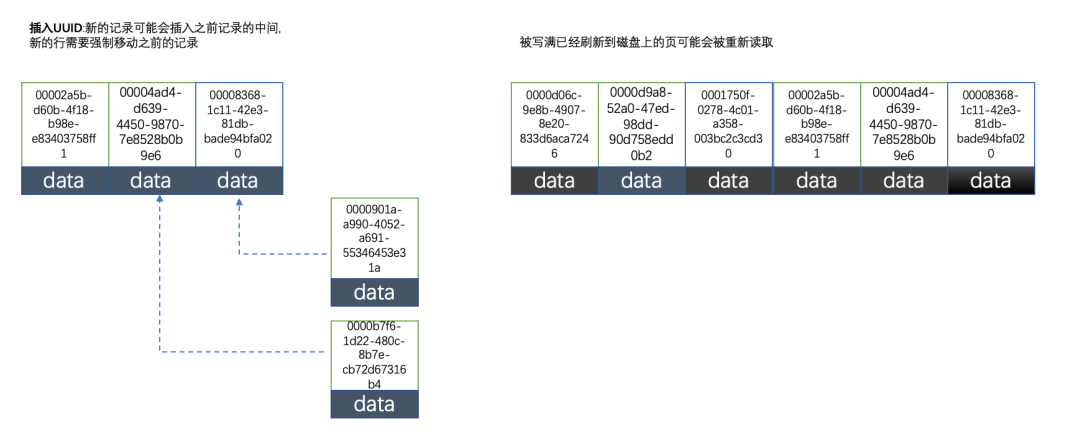
因为uuid相对顺序的自增id来说是毫无规律可言的,新行的值不一定要比之前的主键的值要大,所以innodb无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间。这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱,将会导致以下的问题:
①: 写入的目标页很可能已经刷新到磁盘上并且从缓存上移除,或者还没有被加载到缓存中,innodb在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机IO
②:因为写入是乱序的,innodb不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,一次插入最少需要修改三个页以上
③:由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片
在把随机值(uuid和雪花id)载入到聚簇索引(innodb默认的索引类型)以后,有时候会需要做一次OPTIMEIZE TABLE来重建表并优化页的填充,这将又需要一定的时间消耗。
结论:使用innodb应该尽可能的按主键的自增顺序插入,并且尽可能使用单调的增加的聚簇键的值来插入新行
2.3、使用自增id的缺点
那么使用自增的id就完全没有坏处了吗?并不是,自增id也会存在以下几点问题:
①:别人一旦爬取数据库,就可以根据数据库的自增id获取到业务增长信息,很容易分析出你的经营情况
②:对于高并发的负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争
③:Auto_Increment锁机制会造成自增锁的抢夺,有一定的性能损失
附:Auto_increment的锁争抢问题,如果要改善需要调优innodb_autoinc_lock_mode的配置

若有收获,就点个赞吧
0 人点赞
