Redis
Redis 的 List 实现消息队列有很多局限性,比如:
- 没有良好的 ACK 机制;
- 没有 ConsumerGroup 消费组概念;
- 消息堆积。
- List 是线性结构,想要查询指定数据需要遍历整个列表;
Stream 是 Redis 5.0 引入的一种专门为消息队列设计的数据类型,Stream 是一个包含 0 个或者多个元素的有序队列,这些元素根据 ID 的大小进行有序排列。
它实现了大部分消息队列的功能:
- 消息 ID 系列化生成;
- 消息遍历;
- 消息的阻塞和非阻塞读;
- Consumer Groups 消费组;
- ACK 确认机制。
- 支持多播。
提供了很多消息队列操作命令,并且借鉴 Kafka 的 Consumer Groups 的概念,提供了消费组功能。
同时提供了消息的持久化和主从复制机制,客户端可以访问任何时刻的数据,并且能记住每一个客户端的访问位置,从而保证消息不丢失。
先来看下如何使用,官网文档详见:https://redis.io/topics/streams-intro
XADD:插入消息
「云岚宗众弟子听命,击杀萧炎!」
当云山最后一字落下,那弥漫的紧绷气氛,顿时宣告破碎,悬浮半空的众多云岚宗长老背后双翼一振,便是咻咻的划过天际,追杀萧炎。
云山使用以下指令向队列中插入「追杀萧炎」命令,让长老带领子弟去执行。
XADD 云岚宗 * task kill name 萧炎"1645936602161-0"
Stream 中的每个元素由键值对的形式组成,不同元素可以包含不同数量的键值对。
该命令的语法如下:
XADD streamName id field value [field value ...]
消息队列名称后面的 「*」 ,表示让 Redis 为插入的消息自动生成唯一 ID,当然也可以自己定义。
消息 ID 由两部分组成:
- 当前毫秒内的时间戳;
顺序编号。从 0 为起始值,用于区分同一时间内产生的多个命令。 :::tips 通过将元素 ID 与时间进行关联,并强制要求新元素的 ID 必须大于旧元素的 ID, Redis 从逻辑上将流变成了一种只执行追加操作(append only)的数据结构。
这种特性对于使用流实现消息队列和事件系统的用户来说是非常重要的:
用户可以确信,新的消息和事件只会出现在已有消息和事件之后,就像现实世界里新事件总是发生在已有事件之后一样,一切都是有序进行的。 :::XREAD:读取消息
云凌老狗使用如下指令接收云山的命令:
XREAD COUNT 1 BLOCK 0 STREAMS 云岚宗 0-01) 1) "\xe4\xba\x91\xe5\xb2\x9a\xe5\xae\x97"2) 1) 1) "1645936602161-0"2) 1) "task"2) "kill"3) "name"4) "萧炎" # 萧炎
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
该指令可以同时对多个流进行读取,每个心法对应含义如下:
COUNT:表示每个流中最多读取的元素个数;
- BLOCK:阻塞读取,当消息队列没有消息的时候,则阻塞等待, 0 表示无限等待,单位是毫秒。
- ID:消息 ID,在读取消息的时候可以指定 ID,并从这个 ID 的下一条消息开始读取,0-0 则表示从第一个元素开始读取。
如果想使用 XREAD 进行顺序消费,每次读取后要记住返回的消息 ID,下次调用 XREAD 就将上一次返回的消息 ID 作为参数传递到下一次调用就可以继续消费后续的消息了。
如果历史的消息不接受处理,只想接收使用 XREAD 阻塞等待的那一刻开始通过 XADD 发布的消息要咋整?
运行$符号表示读取最新的阻塞消息,读取不到则一直死等。
等待过程中,其他长老向队列追加消息,则会立即读取到。
XREAD COUNT 1 BLOCK 0 STREAMS 云岚宗 $
这么容易就实现消息队列了么?说好的 ACK 机制呢?
这里只是开胃菜,通过 XREAD 读取的数据其实并没有被删除,当重新执行 XREAD COUNT 2 BLOCK 0 STREAMS 云岚宗 0-0 指令的时候又会重新读取到。
所以还需要 ACK 机制,
接下来,来一个真正的消息队列。
ConsumerGroup
Redis Stream 的 ConsumerGroup(消费者组)允许用户将一个流从逻辑上划分为多个不同的流,并让 ConsumerGroup 的消费者去处理。
它是一个强大的支持多播的可持久化的消息队列。Redis Stream 借鉴了 Kafka 的设计。
Stream 的高可用是建立主从复制基础上的,它和其它数据结构的复制机制没有区别,也就是说在 Sentinel 和 Cluster 集群环境下 Stream 是可以支持高可用的。
- Redis Stream 的结构如上图所示。有一个消息链表,每个消息都有一个唯一的 ID 和对应的内容;
- 消息持久化;
- 每个消费组的状态是独立的,不不影响,同一份的 Stream 消息会被所有的消费组消费;
- 一个消费组可以由多个消费者组成,消费者之间是竞争关系,任意一个消费者读取了消息都会使 last_deliverd_id 往前移动;
- 每个消费者有一个 pending_ids 变量,用于记录当前消费者读取了但是还没 ack 的消息。它用来保证消息至少被客户端消费了一次。
消费组实现的消息队列主要涉及以下三个指令:
- XGROUP用于创建、销毁和管理消费者组。
- XREADGROUP通过消费组从流中读取数据。
-
创建消费组
Stream 通过
XGROUP CREATE指令创建消费组 (Consumer Group),需要传递起始消息 ID 参数用来初始化 last_delivered_id 变量。
使用 XADD 往 bossStream 队列插入一些消息:XADD bossStream * name zhangsan age 26XADD bossStream * name lisi age 2XADD bossStream * name bigold age 40
如下指令,为消息队列名为 bossStream 创建「青龙门」和「六扇门」两个消费组。
# 语法如下# XGROUP CREATE stream group start_idXGROUP CREATE bossStream 青龙门 0-0 MKSTREAMXGROUP CREATE bossStream 六扇门 0-0 MKSTREAM
stream:指定队列的名字;
- group:指定消费组名字;
- start_id:指定消费组在 Stream 中的起始 ID,它决定了消费者组从哪个 ID 之后开始读取消息,0-0 从第一条开始读取, $ 表示从最后一条向后开始读取,只接收新消息。
MKSTREAM:默认情况下,XGROUP CREATE命令在目标流不存在时返回错误。可以使用可选MKSTREAM子命令作为 之后的最后一个参数来自动创建流。
读取消息
让「青龙门」消费组的 consumer1 从bossStream 阻塞读取一条消息:
XREADGROUP GROUP 青龙门 consumer1 COUNT 1 BLOCK 0 STREAMS bossStream >1) 1) "bossStream"2) 1) 1) "1645957821396-0"2) 1) "name"2) "zhangsan"3) "age"4) "26"
语法如下:
XREADGROUP GROUP groupName consumerName [COUNT n] [BLOCK ms] STREAMS streamName [stream ...] id [id ...]
[] 内的表示可选参数,该命令与 XREAD 大同小异,区别在于新增
GROUP groupName consumerName选项。
该选项的两个参数分别用于指定被读取的消费者组以及负责处理消息的消费者。
其中::命令的最后参数 >,表示从尚未被消费的消息开始读取;
- BLOCK:阻塞读取;
敲黑板了
如果消息队列中的消息被消费组的一个消费者消费了,这条消息就不会再被这个消费组的其他消费者读取到。
比如 consumer2 执行读取操作:
XREADGROUP GROUP 青龙门 consumer2 COUNT 1 BLOCK 0 STREAMS bossStream >1) 1) "bossStream"2) 1) 1) "1645957838700-0"2) 1) "name"2) "lisi"3) "age"4) "2"
consumer2 不能再读取到 zhangsan 了,而是读取下一条 lisi 因为这条消息已经被 consumer1 读取了。
使用消费者的另一个目的可以让组内的多个消费者分担读取消息,也就是每个消费者读取部分消息,从而实现均衡负载。
比如一个消费组有三个消费者 C1、C2、C3 和一个包含消息 1、2、3、4、5、6、7 的流: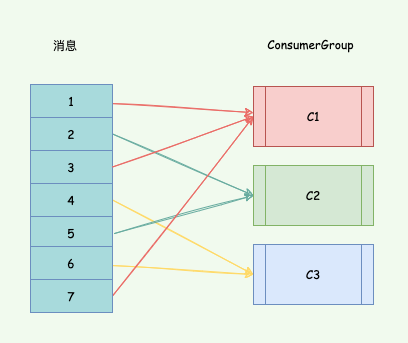
XPENDING 查看已读未确认消息
为了保证消费者在消费的时候发生故障或者宕机重启后依然可以读取消息,Stream 内部有一个队列(pending List)保存每个消费者读取但是还没有执行 ACK 的消息。
如果消费者使用了 XREADGROUP GROUP groupName consumerName 读取消息,但是没有给 Stream 发送 XACK 命令,消息依然保留。
比如查看 bossStream 中的 消费组「青龙门」中各个消费者已读取未确认的消息信息:
XPENDING bossStream 青龙门1) (integer) 22) "1645957821396-0"3) "1645957838700-0"4) 1) 1) "consumer1"2) "1"2) 1) "consumer2"2) "1"
- 1)未确认消息条数;
- 2) ~ 3)青龙门中所有消费者读取的消息最小和最大 ID;
查看 consumer1读取了哪些数据,使用以下命令:
XPENDING bossStream 青龙门 - + 10 consumer11) 1) "1645957821396-0"2) "consumer1"3) (integer) 37583844) (integer) 1
ACK 确认
所以当接收到消息并且消费成功以后,需要手动 ACK 通知 Streams,这条消息就会被删除了。命令如下:
XACK bossStream 青龙门 1645957821396-0 1645957838700-0(integer) 2
语法如下:
XACK key group-key ID [ID ...]
消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行 ack 确认消息已经被消费完成,整个流程的执行如下图所示:
使用 Redisson 实战
使用 maven 添加依赖
<dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.16.7</version></dependency>
添加 Redis 配置,这里 Redis 没有配置密码,大家根据实际情况配置即可。
spring:application:name: redissionredis:host: 127.0.0.1port: 6379ssl: false
@Slf4j@Servicepublic class QueueService {@Autowiredprivate RedissonClient redissonClient;/*** 发送消息到队列** @param message*/public void sendMessage(String message) {RStream<String, String> stream = redissonClient.getStream("sensor#4921");stream.add("speed", "19");stream.add("velocity", "39%");stream.add("temperature", "10C");}/*** 消费者消费消息** @param message*/public void consumerMessage(String message) {RStream<String, String> stream = redissonClient.getStream("sensor#4921");stream.createGroup("sensors_data", StreamMessageId.ALL);Map<StreamMessageId, Map<String, String>> messages = stream.readGroup("sensors_data", "consumer_1");for (Map.Entry<StreamMessageId, Map<String, String>> entry : messages.entrySet()) {Map<String, String> msg = entry.getValue();System.out.println(msg);stream.ack("sensors_data", entry.getKey());}}}

若有收获,就点个赞吧
0 人点赞
