- 1.Scalars(标量)=====>0D tensors
- 2.trick:在线help命令
- 3.Vectors(向量)=====>1D tensors
- ">
- 4.如何快速得出变量是几维的张量?
- 5.Matrices(矩阵)=====>2D tensors
- 6.三维或者更高维的张量怎么理解?
- 7.三维张量的例子
- 8.借助np.random.randint()构造4维张量
- 9.张量的三个属性及对应命令【张量的第一维的数值就是个数】
- 10.可视化mnist数据以及plt.cm内置色彩映射函数的用法
- 11.切片操作:从目标张量中取出需要的数据
- 12.按照条件进行索引
- 13.深度学习与统计学习最大的区别
- 14.现实数据的张量维度举例
1.Scalars(标量)=====>0D tensors
2.trick:在线help命令
3.Vectors(向量)=====>1D tensors
x = np.array([12,3,6,14])x
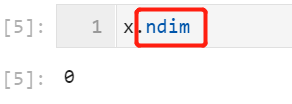
4.如何快速得出变量是几维的张量?
法一:看np.array()的小括号中有几个完整的中括号
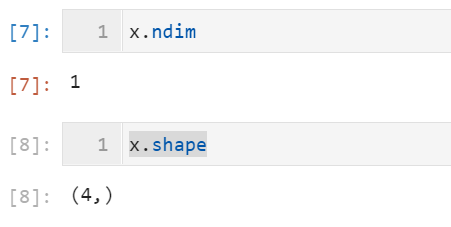
法二:调用.shape命令【注:(4,)表示一维的!】
5.Matrices(矩阵)=====>2D tensors
x = np.array([[5,78,2,34,0],
[6,79,3,35,1],
[7,80,4,36,2]])
6.三维或者更高维的张量怎么理解?
可以看成是k个低一维的张量进行拼接(高维张量的第一个数字就是k的值)
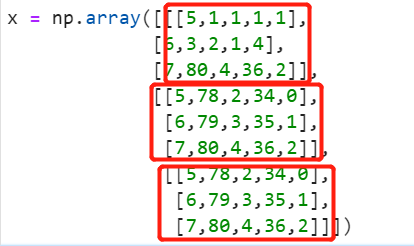
7.三维张量的例子
x = np.array([[[5,1,1,1,1],
[6,3,2,1,4],
[7,80,4,36,2]],
[[5,78,2,34,0],
[6,79,3,35,1],
[7,80,4,36,2]],
[[5,78,2,34,0],
[6,79,3,35,1],
[7,80,4,36,2]]])

8.借助np.random.randint()构造4维张量
x = np.random.randint(30,size=(3,2,2,4))
- 第一个30表示:要产生0~29之间的随机数【30取不到】
- 第二个参数size(3,2,24)表示:要产生这样形状的4维张量
- 表示要构造3个(2,2,4)的三维张量,每一个(2,2,4)都由2个(2,4)的张量组成

9.张量的三个属性及对应命令【张量的第一维的数值就是个数】
- 维度【.ndim】
- 形状【.shape】
组成元素的类型【.dtype】
train_images.ndim train_images.shape print(train_images.dtype)#uint8--->8个bit表示的整数10.可视化mnist数据以及plt.cm内置色彩映射函数的用法
digit = train_images[4] plt.imshow(digit,cmap = plt.cm.binary)#黑白 plt.show()train_images[4]取出的就是第5张图片,每一个图片就是一个(28,28)的二维张量
- **plt.cm.__用于进行色彩渲染,binary是黑白的**_
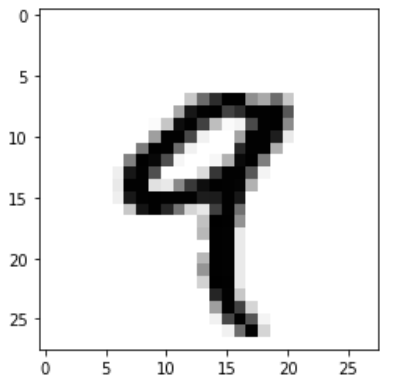
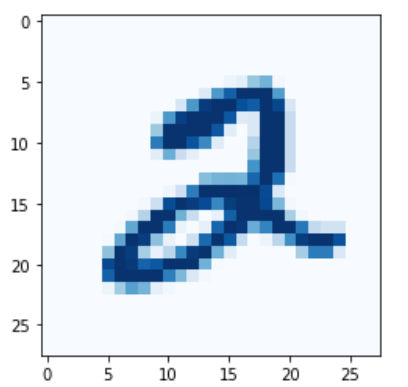
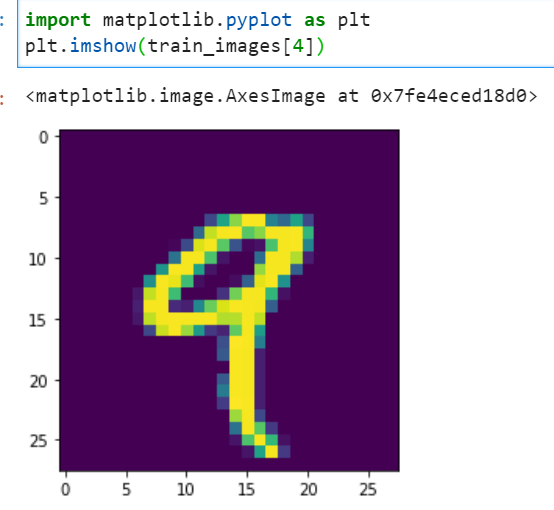
matplotlib.cm.色彩:对【数据集】使用【色彩】进行渲染展示
11.切片操作:从目标张量中取出需要的数据
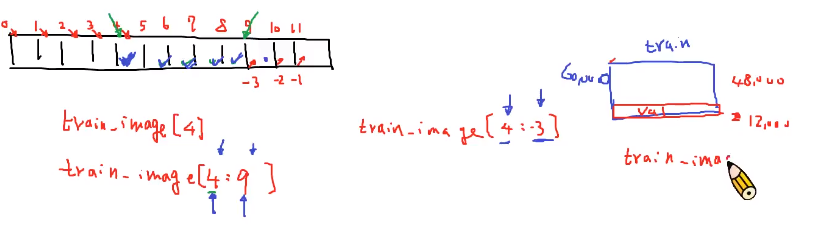
注:索引标注在格子划分的正上方,对应的数据在其右下方。
train_image[4:9]:总共5个数据【索引分别维4、5、6、7、8的python也是从0开始的】
理解方式一:起点的4右下方,终点的9左下方。**【并且9左下方的数据也是要的】
_理解方式二:起点的4表示第一个要的数据的索引,终点的9表示第一个不要的数据的索引。
trick负数索引的使用:负数索引所代表的数据在其右上方_
trainimage[4:9]=train_image4:-3**
Note:如果想要使得train_image数据的后20%作为验证集,也就是最后的12000张图片。
可以使用train_image[:,-12000],:就表示从头开始选取数据,从0开始,并且最后的12000张数据是不需要的。_12.按照条件进行索引
①mnist数据集挑选第11张图片到第100张图片
方式一:#在一堆张量中截取需要的数据 #编号10到编号99 #第11张图片取到第100张图片 my_slice = train_images[10:100] my_slice.shape方式二:
my_slice = train_images[10:100,:,:] my_slice.shape方式三:
my_slice = train_images[10:100,0:28,0:28] my_slice.shape结果都是:(90,28,28)
②挑选数据集每一张图片的右下角1/4部分my_slice = train_images[:,14:,14:]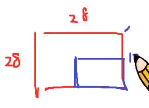 从第15列开始,即从索引14到最后
从第15列开始,即从索引14到最后
③挑选数据集每一张图片的正中间1/4部分
方式一:my_slice = train_images[:,7:21,7:21]方式二:【借助负数索引】
my_slice = train_images[:,7:-7,7:-7]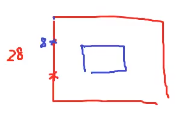 上7列,中14列,下7列
上7列,中14列,下7列
note:从第8列开始取14列即第21列,对应的索引是20.所以切片为【7:21】.
考虑负数索引更简单:最后7列都不要,所以对应的索引是【7:-7】13.深度学习与统计学习最大的区别
深度学习可以对数据进行分批导入分批处理,但是一般的统计学习是一次性处理全部的数据。所以,一般来说深度学习不会让模型卡掉,顶多是训练时间长一点。
实际处理中可能的分批操作:batch = train_images[:128] batch = train_images[128:256] batch = train_images[128*n,128*(n+1)]14.现实数据的张量维度举例
实例1:**若干个数据,每个数据由若干个特征组成======(Vector向量2D tensor)
比如10000个人,每个人都有3个特征,则用(10000,3)表示。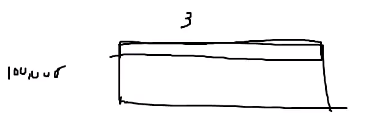 **
**在文本分析领域,现在由500篇文章,想要去看这500篇文章出现2000个目标单词的情况,数据就用(500,2000)这一2d tensors表示。
- 2d tensors时,第一个维度的取值就是样本个数,第二个取值是特征的数目。
实例2:时间序列式的数据或者其他的序列式数据(samples,timestep,feature)
- 股价分析:每天记录390分钟的数据,每一分钟一次股市的数据变动,每次记录股市的最大值、最小值以及收盘值共三个特征。每年记录250天。**(250,390,3)**
实例3:图片====(4d tensors)(samples,height,width,channel)**【顺序不一定,和使用的框架有关系】**
- 每一张彩色图片都是:(28,28,3).3个通道分别是RGB,相当于3个(28,28)的图片进行叠加。如果是黑白的,那么就是(28,28,1).
实例4:video**=====(5d tensors)(samples,frame,height,width,channel)**
- frame:视频的帧数,也就是一个视频由多少张图片组成的。
- 比如有一个60s的视频,每1s取4帧,总共有4个这样的视频,视频的分辨率是144*256.则这样的张量为:(4,240,144,256,3)
**

若有收获,就点个赞吧
0 人点赞
