1.dict基本的函数接口
①dict.items():输出字典内容,以{‘key’:value}的形式输出所有的内容
②dict.keys():输出字典的值
③dict.values():输出字典的键值
2.word embedding
3.为什么分类问题的loss函数一般用cross entropy而不是mse等?
4.评估分类器的各种性能指标
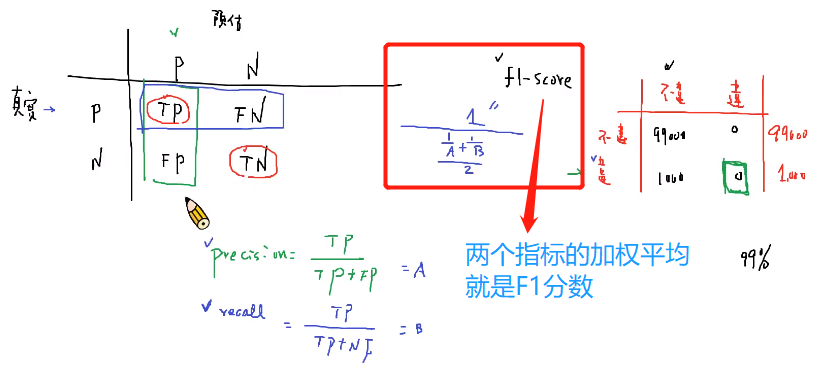
- 某些情况下**不能一味的认为precision越高模型就越好**。比如在样本量很小的时候,要多关注recall(召回率)。
- 注意混淆矩阵的真实值和预估值的摆放位置。
-
5.哈达玛积 Hadamard Product
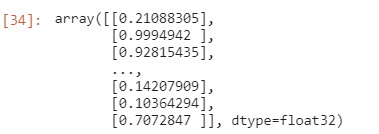
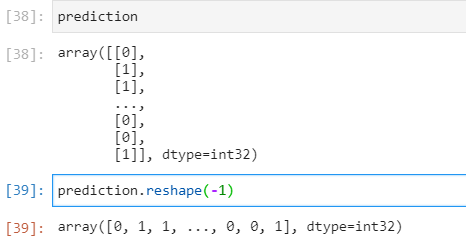
6.分类任务中如何查看最终每个样本的预测概率值以及每个样本的模型预测种类
model.predict(x_test)
此命令可以输出每个样本的预测概率值
prediction=model.predict_classes(x_test)
此命令可以输出每个样本的预测分类结果

若有收获,就点个赞吧
0 人点赞
