- 序列化模块
- configparser 模块
- logging 模块
- collections 模块
- 时间有关的模块
- random 模块
- OS 模块
- sys 模块
- re 模块
- shutil 模块
- shutil.copyfileobj(fsrc, fdst[, length])
- shutil.copyfile(src, dst)
- shutil.copymode(src, dst)
- shutil.copystat(src, dst)
- shutil.copy(src, dst)
- shutil.ignore_patterns(*patterns)
- shutil.copytree(src, dst, symlinks=False, ignore=None)
- shutil.rmtree(path[, ignore_errors[, onerror]])
- shutil.move(src, dst)
- shutil.make_archive(base_name, format,…)
序列化模块
将原本的字典、列表等内容转换成一个字符串的过程就叫做 序列化
序列化的目的
- 以某种存储形式使自定义对象持久化;
- 将对象从一个地方传递到另一个地方。
- 使程序更具维护性。

python 可序列化的数据类型
| Python | JSON |
|---|---|
| dict | object |
| list,tuple | array |
| str | string |
| int,float | number |
| True | true |
| False | false |
| None | null |
json 模块
Json 模块提供了四个功能:dumps、dump、loads、load
import jsondic = {'k1':'v1','k2':'v2','k3':'v3'}str_dic = json.dumps(dic)# 序列化:将一个字典转换成一个字符串print(type(str_dic),str_dic)dic2 = json.loads(str_dic)print(type(dic2),dic2)# 反序列化:将一个字符串格式的字典转换成一个字典list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]str_dic = json.dumps(list_dic)print(type(str_dic),str_dic)list_dic2 = json.loads(str_dic)print(type(list_dic2),list_dic2)
Python
Copy
| Skipkeys | 1, 默认值是 False,如果 dict 的 keys 内的数据不是 python 的基本类型,2, 设置为 False 时,就会报 TypeError 的错误。此时设置成 True,则会跳过这类 key,3, 当它为 True 的时候,所有非 ASCII 码字符显示为 \uXXXX 序列,只需在 dump 时将 ensure_ascii 设置为 False 即可,此时存入 json 的中文即可正常显示。 |
|---|---|
| indent | 是一个非负的整型,如果是 0 就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照 indent 的数值显示前面的空白分行显示,这样打印出来的 json 数据也叫 pretty-printed json |
| ensure_ascii | 当它为 True 的时候,所有非 ASCII 码字符显示为 \uXXXX 序列,只需在 dump 时将 ensure_ascii 设置为 False 即可,此时存入 json 的中文即可正常显示。 |
| separators | 分隔符,实际上是 (item_separator, dict_separator) 的一个元组,默认的就是(‘,’,’:’);这表示 dictionary 内 keys 之间用“,”隔开,而 KEY 和 value 之间用“:”隔开。 |
| sort_keys | 将数据根据 keys 的值进行排序 |
import jsondata = {'name':'陈松','sex':'female','age':88}json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(',',':'),ensure_ascii=False)print(json_dic2)
Python
Copy
pickle 模块
| json | 用于字符串 和 python 数据类型间进行转换 |
|---|---|
| pickle | 用于 python 特有的类型 和 python 的数据类型间进行转换 |
pickle 模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load
不仅可以序列化字典,列表… 可以把 python 中任意的数据类型序列化
import pickledic = {'k1':'v1','k2':'v2','k3':'v3'}str_dic = pickle.dumps(dic)print(str_dic)dic2 = pickle.loads(str_dic)print(dic2)import timestruct_time = time.localtime(1000000000)print(struct_time)f = open('pickle_file','wb')pickle.dump(struct_time,f)f.close()f = open('pickle_file','rb')struct_time2 = pickle.load(f)print(struct_time2.tm_year)
Python
Copy
shelve 模块
shelve 也是 python 提供给我们的序列化工具,比 pickle 用起来更简单一些。
shelve 只提供给我们一个 open 方法,是用 key 来访问的,使用起来和字典类似。
import shelvef = shelve.open('shelve_file')f['key'] = {'int':10,'str':'hello','float':0.123}f.close()f1 = shelve.open('shelve_file')ret = f1['key']f1.close()print(ret)
Python
Copy
这个模块有个限制,它不支持多个应用同一时间往同一个 DB 进行写操作。所以当我们知道我们的应用如果只进行读操作,我们可以让 shelve 通过只读方式打开 DB
import shelvef1 = shelve.open('shelve_file',flag='r')ret = f1['key']f1.close()print(ret)
Python
Copy
由于 shelve 在默认情况下是不会记录待持久化对象的任何修改的,所以我们在 shelve.open() 时候需要修改默认参数,否则对象的修改不会保存。
import shelvef1 = shelve.open('shelve_file')print(f1['key'])f1['key']['k1'] = 'v1'f1.close()f2 = shelve.open('shelve_file',writeback=True)print(f2['key'])f2['key']['k1'] = 'hello'f2.close()
Python
Copy
hashlib 模块
Python 的 hashlib 提供了常见的摘要算法,如 MD5,SHA1 等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用 16 进制的字符串表示)。
摘要算法就是通过摘要函数 f() 对任意长度的数据 data 计算出固定长度的摘要 digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算 f(data) 很容易,但通过 digest 反推 data 却非常困难。而且,对原始数据做一个 bit 的修改,都会导致计算出的摘要完全不同。
import hashlibmd5 = hashlib.md5()md5.update('how to use md5 in python hashlib?'.encode('utf-8'))print(md5.hexdigest())
Python
Copy
如果数据量很大,可以分块多次调用 update(),最后计算的结果是一样的
import hashlibmd5 = hashlib.md5()md5.update('how to use md5 '.encode('utf-8'))md5.update('in python hashlib?'.encode('utf-8'))print(md5.hexdigest())
Python
Copy
MD5 是最常见的摘要算法,速度很快,生成结果是固定的 128 bit 字节,通常用一个 32 位的 16 进制字符串表示。另一种常见的摘要算法是 SHA1,调用 SHA1 和调用 MD5 完全类似
import hashlibsha1 = hashlib.sha1()sha1.update('how to use md5 '.encode('utf-8'))sha1.update('in python hashlib?'.encode('utf-8'))print(sha1.hexdigest())
Python
Copy
摘要算法应用
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中
name | password--------+----------michael | 123456bob | abc999alice | alice2008
SQL
Copy
如果使用 md5 来将保护密码那么就是这样
username | password---------+---------------------------------michael | e10adc3949ba59abbe56e057f20f883ebob | 878ef96e86145580c38c87f0410ad153alice | 99b1c2188db85afee403b1536010c2c9
SQL
Copy
有很多 md5 撞库工具,可以轻松的将简单密码给碰撞出来
所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的 MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”
经过 Salt 处理的 MD5 口令,只要 Salt 不被黑客知道,即使用户输入简单口令,也很难通过 MD5 反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如 123456,在数据库中,将存储两条相同的 MD5 值,这说明这两个用户的口令是一样的。
如果假定用户无法修改登录名,就可以通过把登录名作为 Salt 的一部分来计算 MD5,从而实现相同口令的用户也存储不同的 MD5。
显示进度条
import timefor i in range(0,101,2):time.sleep(0.1)char_num = i//2per_str = '\r%s%% : %s\n' % (i, '*' * char_num) \if i == 100 else '\r%s%% : %s' % (i,'*'*char_num)print(per_str,end='', flush=True)
Python
Copy
configparser 模块
该模块适用于配置文件的格式与 windows ini 文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键 = 值)。
常见的文档格式
[DEFAULT]ServerAliveInterval = 45Compression = yesCompressionLevel = 9ForwardX11 = yes[bitbucket.org]User = hg[topsecret.server.com]Port = 50022ForwardX11 = no
使用 python 生成一个这样的文件
import configparserconf = configparser.ConfigParser()conf['DEFAULT'] = {'ServerAliveInterval':'45','Compression':'yes','CompressionLevel':'9','ForwardX11':'yes'}conf['bitbucket.org'] = {'User':'hg'}conf['topsecret.server.com'] = {'Port':'50022','ForwardX11':'no'}with open('config','w') as config:conf.write(config)
Python
Copy
查找
import configparserconf = configparser.ConfigParser()conf['DEFAULT'] = {'ServerAliveInterval':'45','Compression':'yes','CompressionLevel':'9','ForwardX11':'yes'}conf['bitbucket.org'] = {'User':'hg'}conf['topsecret.server.com'] = {'Port':'50022','ForwardX11':'no'}print('bitbucket.org' in conf)print('bitbucket.com' in conf)print(conf['bitbucket.org']['user'])print(conf['DEFAULT']['Compression'])for key in conf['bitbucket.org']:print(key) # DEFAULT的键也会出现print(conf.options('bitbucket.org'))# 同for循环,找到'bitbucket.org'下所有键print(conf.items('bitbucket.org'))# 找到'bitbucket.org'下所有键值对print(conf.get('bitbucket.org','compression'))
Python
Copy
增删改操作
import configparserconf = configparser.ConfigParser()conf.read('config')conf.add_section('yuan') # 添加键conf.remove_section('bitbucket.org') # 删除键conf.remove_option('topsecret.server.com','forwardx11') # 移除条目conf.set('topsecret.server.com','k1','11111') # 在对应键下加上条目conf.set('yuan','k2','22222')conf.write(open('config.new','w')) # 写入文件
Python
Copy
logging 模块
函数式简单配置
import logginglogging.debug('debug message')logging.info('info message')logging.warning('warning message')logging.error('error message')logging.critical('critical message')
Python
Copy
默认情况下 Python 的 logging 模块将日志打印到了标准输出中,且只显示了大于等于 WARNING 级别的日志,这说明默认的日志级别设置为 WARNING(日志级别等级 CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger 名称:用户输出消息。
import logginglogging.basicConfig(level=logging.DEBUG,format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',datefmt='%a, %d %b %Y %H:%M:%S',filename='test.log',filemode='w')logging.debug('debug message')logging.info('info message')logging.warning('warning message')logging.error('error message')logging.critical('critical message')
Python
Copy
参数解释
- logging.basicConfig() 函数中可通过具体参数来更改 logging 模块默认行为,可用参数有:
- filename:用指定的文件名创建 FiledHandler,这样日志会被存储在指定的文件中。
- filemode:文件打开方式,在指定了 filename 时使用这个参数,默认值为“a”还可指定为“w”。
- format:指定 handler 使用的日志显示格式。
- datefmt:指定日期时间格式。
- level:设置 rootlogger(后边会讲解具体概念)的日志级别
- stream:用指定的 stream 创建 StreamHandler。可以指定输出到 sys.stderr,sys.stdout 或者文件 (f=open- (‘test.log’,’w’)),默认为 sys.stderr。若同时列出了 filename 和 stream 两个参数,则 stream 参数会被忽略。
- format 参数中可能用到的格式化串:
- %(name)s Logger 的名字
- %(levelno)s 数字形式的日志级别
- %(levelname)s 文本形式的日志级别
- %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
- %(filename)s 调用日志输出函数的模块的文件名
- %(module)s 调用日志输出函数的模块名
- %(funcName)s 调用日志输出函数的函数名
- %(lineno)d 调用日志输出函数的语句所在的代码行
- %(created)f 当前时间,用 UNIX 标准的表示时间的浮 点数表示
- %(relativeCreated)d 输出日志信息时的,自 Logger 创建以 来的毫秒数
- %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
- %(thread)d 线程 ID。可能没有
- %(threadName)s 线程名。可能没有
- %(process)d 进程 ID。可能没有
- %(message)s 用户输出的消息
logger 对象配置
import logginglogger = logging.getLogger()# 创建一个handler,用于写入日志文件fh = logging.FileHandler('test.log',encoding='utf-8')# 再创建一个handler,用于输出到控制台ch = logging.StreamHandler()formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')fh.setLevel(logging.DEBUG)fh.setFormatter(formatter)ch.setFormatter(formatter)logger.addHandler(fh) #logger对象可以添加多个fh和ch对象logger.addHandler(ch)logger.debug('logger debug message')logger.info('logger info message')logger.warning('logger warning message')logger.error('logger error message')logger.critical('logger critical message')
Python
Copy
logging 库提供了多个组件:Logger、Handler、Filter、Formatter。Logger 对象提供应用程序可直接使用的接口,Handler 发送日志到适当的目的地,Filter 提供了过滤日志信息的方法,Formatter 指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug) 设置级别, 当然,也可以通过 fh.setLevel(logging.Debug) 单对文件流设置某个级别。
logger 的配置文件
"""logging配置"""import osimport logging.config# 定义三种日志输出格式 开始standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s'# 定义日志输出格式 结束logfile_dir = os.path.dirname(os.path.abspath(__file__)) # log文件的目录logfile_name = 'all2.log' # log文件名# 如果不存在定义的日志目录就创建一个if not os.path.isdir(logfile_dir):os.mkdir(logfile_dir)# log文件的全路径logfile_path = os.path.join(logfile_dir, logfile_name)# log配置字典LOGGING_DIC = {'version': 1,'disable_existing_loggers': False,'formatters': {'standard': {'format': standard_format},'simple': {'format': simple_format},},'filters': {},'handlers': {#打印到终端的日志'console': {'level': 'DEBUG','class': 'logging.StreamHandler', # 打印到屏幕'formatter': 'simple'},#打印到文件的日志,收集info及以上的日志'default': {'level': 'DEBUG','class': 'logging.handlers.RotatingFileHandler', # 保存到文件'formatter': 'standard','filename': logfile_path, # 日志文件'maxBytes': 1024*1024*5, # 日志大小 5M'backupCount': 5,'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了},},'loggers': {#logging.getLogger(__name__)拿到的logger配置'': {'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕'level': 'DEBUG','propagate': True, # 向上(更高level的logger)传递},},}def load_my_logging_cfg():logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置logger = logging.getLogger(__name__) # 生成一个log实例logger.info('It works!') # 记录该文件的运行状态if __name__ == '__main__':load_my_logging_cfg()
Python
Copy
注意:#1、有了上述方式我们的好处是:所有与logging模块有关的配置都写到字典中就可以了,更加清晰,方便管理#2、我们需要解决的问题是:1、从字典加载配置:logging.config.dictConfig(settings.LOGGING_DIC)2、拿到logger对象来产生日志logger对象都是配置到字典的loggers 键对应的子字典中的按照我们对logging模块的理解,要想获取某个东西都是通过名字,也就是key来获取的于是我们要获取不同的logger对象就是logger=logging.getLogger('loggers子字典的key名')但问题是:如果我们想要不同logger名的logger对象都共用一段配置,那么肯定不能在loggers子字典中定义n个key'loggers': {'l1': {'handlers': ['default', 'console'], #'level': 'DEBUG','propagate': True, # 向上(更高level的logger)传递},'l2: {'handlers': ['default', 'console' ],'level': 'DEBUG','propagate': False, # 向上(更高level的logger)传递},'l3': {'handlers': ['default', 'console'], #'level': 'DEBUG','propagate': True, # 向上(更高level的logger)传递},}#我们的解决方式是,定义一个空的key'loggers': {'': {'handlers': ['default', 'console'],'level': 'DEBUG','propagate': True,},}这样我们再取logger对象时logging.getLogger(__name__),不同的文件__name__不同,这保证了打印日志时标识信息不同,但是拿着该名字去loggers里找key名时却发现找不到,于是默认使用key=''的配置
collections 模块
在内置数据类型(dict、list、set、tuple)的基础上,collections 模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple 和 OrderedDict 等。
- namedtuple: 生成可以使用名字来访问元素内容的 tuple
- deque: 双端队列,可以快速的从另外一侧追加和推出对象
- Counter: 计数器,主要用来计数
- OrderedDict: 有序字典
- defaultdict: 带有默认值的字典
namedtuple
from collections import namedtuplepoint = namedtuple('point',['x','y'])p = point(1,2)print(p.x)
Python
Copy
一个点的二维坐标就可以表示成, 但是,看到 (1, 2),很难看出这个 tuple 是用来表示一个坐标的。
这时,namedtuple 就派上了用场
deque
使用 list 存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为 list 是线性存储,数据量大的时候,插入和删除效率很低。
deque 是为了高效实现插入和删除操作的双向列表,适合用于队列和栈
from collections import dequeq = deque(['a','b','c'])q.append('x')q.appendleft('y')print(q)
Python
Copy
deque 除了实现 list 的 append() 和 pop() 外,还支持 appendleft() 和 popleft(),这样就可以非常高效地往头部添加或删除元素。
OrderedDict
from collections import OrderedDictd = dict([('a',1),('b',2),('c',3)])print(d)od = OrderedDict([('a',1),('b',2),('c',3)])print(od)
Python
Copy
注意,OrderedDict 的 Key 会按照插入的顺序排列,不是 Key 本身排序
defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90…],将所有大于 66 的值保存至字典的第一个 key 中,将小于 66 的值保存至第二个 key 的值中。
即: {‘k1’: 大于 66 , ‘k2’: 小于 66}
li = [11,22,33,44,55,77,88,99,90]result = {}for row in li:if row < 66:if 'key1' not in result:result['key1']=[]result['key1'].append(row)else:if 'key2' not in result:result['key2']=[]result['key2'].append(row)print(result)
Python
Copy
from collections import defaultdictli = [11,22,33,44,55,77,88,99,90]result=defaultdict(list)for row in li:if row > 66:result['key1'].append(row)else:result['key2'].append(row)print(result)
Python
Copy
counter
Counter 类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为 key,其计数作为 value。
from collections import Counterc = Counter('qazxswqazxswqazxswsxaqwsxaqws')print(c)
Python
Copy
时间有关的模块
常用方法
- time.sleep(secs)
- (线程) 推迟指定的时间运行。单位为秒。
- time.time()
- 获取当前时间戳
表示时间的三种方式
在 Python 中,通常有这三种方式来表示时间:时间戳、元组 (struct_time)、格式化的时间字符串:
- 时间戳 (timestamp) :通常来说,时间戳表示的是从 1970 年 1 月 1 日 00:00:00 开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是 float 类型。
格式化的时间字符串 (Format String): ‘1999-12-06’ | %y | 两位数的年份表示(00-99) | | —- | :—- | | %Y | 四位数的年份表示(000-9999) | | %m | 月份(01-12) | | %d | 月内中的一天(0-31) | | %H | 24 小时制小时数(0-23) | | %I | 12 小时制小时数(01-12) | | %M | 分钟数(00=59) | | %S | 秒(00-59) | | %a | 本地简化星期名称 | | %A | 本地完整星期名称 | | %b | 本地简化的月份名称 | | %B | 本地完整的月份名称 | | %c | 本地相应的日期表示和时间表示 | | %j | 年内的一天(001-366) | | %p | 本地 A.M. 或 P.M. 的等价符 | | %U | 一年中的星期数(00-53)星期天为星期的开始 | | %w | 星期(0-6),星期天为星期的开始 | | %W | 一年中的星期数(00-53)星期一为星期的开始 | | %x | 本地相应的日期表示 | | %X | 本地相应的时间表示 | | %Z | 当前时区的名称 | | %% | % 号本身 |
元组 (struct_time) :struct_time 元组共有 9 个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等) | 索引(Index) | 属性(Attribute) | 值(Values) | | :—- | :—- | :—- | | 0 | tm_year(年) | 比如 2011 | | 1 | tm_mon(月) | 1 月 12 日 | | 2 | tm_mday(日) | 1 月 31 日 | | 3 | tm_hour(时) | 0 - 23 | | 4 | tm_min(分) | 0 - 59 | | 5 | tm_sec(秒) | 0 - 60 | | 6 | tm_wday(weekday) | 0 - 6(0 表示周一) | | 7 | tm_yday(一年中的第几天) | 1 - 366 | | 8 | tm_isdst(是否是夏令时) | 默认为 0 |
import timeprint(time.time())print(time.strftime('%Y-%m-%d %X'))print(time.strftime('%Y-%m-%d %H-%M-%S'))print(time.localtime())
Python
Copy
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
几种格式之间的转换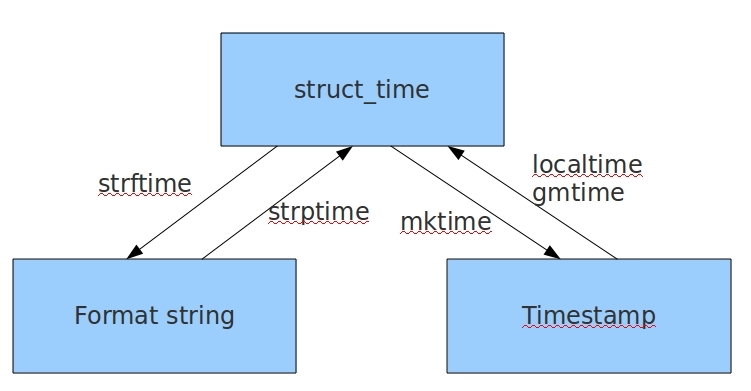
import time# 格式化时间 ----> 结构化时间ft = time.strftime('%Y/%m/%d %H:%M:%S')st = time.strptime(ft,'%Y/%m/%d %H:%M:%S')print(st)# 结构化时间 ---> 时间戳t = time.mktime(st)print(t)# 时间戳 ----> 结构化时间t = time.time()st = time.localtime(t)print(st)# 结构化时间 ---> 格式化时间ft = time.strftime('%Y/%m/%d %H:%M:%S',st)print(ft)
Python
Copy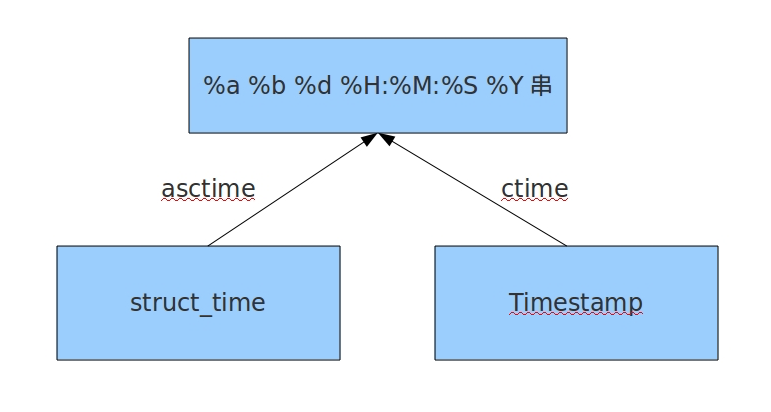
import time#结构化时间 --> %a %b %d %H:%M:%S %Y串#time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串print(time.asctime(time.localtime(1550312090.4021888)))#时间戳 --> %a %d %d %H:%M:%S %Y串#time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串print(time.ctime(1550312090.4021888))
Python
Copy
计算时间差
import timestart_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S'))end_time=time.mktime(time.strptime('2019-09-12 11:00:50','%Y-%m-%d %H:%M:%S'))dif_time=end_time-start_timestruct_time=time.gmtime(dif_time)print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1,struct_time.tm_mday-1,struct_time.tm_hour,struct_time.tm_min,struct_time.tm_sec))
Python
Copy
datatime 模块
# datatime模块import datetimenow_time = datetime.datetime.now() # 现在的时间# 只能调整的字段:weeks days hours minutes secondsprint(datetime.datetime.now() + datetime.timedelta(weeks=3)) # 三周后print(datetime.datetime.now() + datetime.timedelta(weeks=-3)) # 三周前print(datetime.datetime.now() + datetime.timedelta(days=-3)) # 三天前print(datetime.datetime.now() + datetime.timedelta(days=3)) # 三天后print(datetime.datetime.now() + datetime.timedelta(hours=5)) # 5小时后print(datetime.datetime.now() + datetime.timedelta(hours=-5)) # 5小时前print(datetime.datetime.now() + datetime.timedelta(minutes=-15)) # 15分钟前print(datetime.datetime.now() + datetime.timedelta(minutes=15)) # 15分钟后print(datetime.datetime.now() + datetime.timedelta(seconds=-70)) # 70秒前print(datetime.datetime.now() + datetime.timedelta(seconds=70)) # 70秒后current_time = datetime.datetime.now()# 可直接调整到指定的 年 月 日 时 分 秒 等print(current_time.replace(year=1977)) # 直接调整到1977年print(current_time.replace(month=1)) # 直接调整到1月份print(current_time.replace(year=1989,month=4,day=25)) # 1989-04-25 18:49:05.898601# 将时间戳转化成时间print(datetime.date.fromtimestamp(1232132131)) # 2009-01-17
Python
Copy
random 模块
import randomprint(random.random()) # 大于0且小于1之间的小数print(random.uniform(1,3)) # 大于1小于3的小数print(random.randint(1,5)) # 大于等于1且小于等于5之间的整数print(random.randrange(1,10,2)) # 大于等于1且小于10之间的奇数ret = random.choice([1,'23',[4,5]]) # 1或者23或者[4,5]print(ret)a,b = random.sample([1,'23',[4,5]],2) # 列表元素任意2个组合print(a,b)item = [1,3,5,7,9]random.shuffle(item) # 打乱次序print(item)
Python
Copy
生成随机验证码
import randomdef v_code():code = ''for i in range(5):num=random.randint(0,9)alf=chr(random.randint(65,90))add=random.choice([num,alf])code="".join([code,str(add)])return codeprint(v_code())
Python
Copy
OS 模块
os 模块是与操作系统交互的一个接口
当前执行这个 python 文件的工作目录相关的工作路径
| os.getcwd() | 获取当前工作目录,即当前 python 脚本工作的目录路径 |
|---|---|
| os.chdir(“dirname”) | 改变当前脚本工作目录;相当于 shell 下 cd |
| os.curdir | 返回当前目录: (‘.’) |
| os.pardir | 获取当前目录的父目录字符串名:(‘..’) |
文件夹相关
| os.makedirs(‘dirname1/dirname2’) | 可生成多层递归目录 |
|---|---|
| os.removedirs(‘dirname1’) | 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 |
| os.mkdir(‘dirname’) | 生成单级目录;相当于 shell 中 mkdir dirname |
| os.rmdir(‘dirname’) | 删除单级空目录,若目录不为空则无法删除,报错;相当于 shell 中 rmdir dirname |
| os.listdir(‘dirname’) | 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 |
文件相关
| os.remove() | 删除一个文件 |
|---|---|
| os.rename(“oldname”,”newname”) | 重命名文件 / 目录 |
| os.stat(‘path/filename’) | 获取文件 / 目录信息 |
操作系统差异相关
| os.sep | 输出操作系统特定的路径分隔符,win 下为 “\\“,Linux 下为 “/“ |
|---|---|
| os.linesep | 输出当前平台使用的行终止符,win 下为 “\t\n”,Linux 下为 “\n” |
| os.pathsep | 输出用于分割文件路径的字符串 win 下为;,Linux 下为: |
| os.name | 输出字符串指示当前使用平台。win->’nt’; Linux->’posix’ |
执行系统命令相关
| os.system(“bash command”) | 运行 shell 命令,直接显示 |
|---|---|
| os.popen(“bash command).read() | 运行 shell 命令,获取执行结果 |
| os.environ | 获取系统环境变量 |
path 系列,和路径相关
| os.path.abspath(path) | 返回 path 规范化的绝对路径 |
|---|---|
| os.path.split(path) | 将 path 分割成目录和文件名二元组返回 |
| os.path.dirname(path) | 返回 path 的目录。其实就是 os.path.split(path) 的第一个元素 |
| os.path.basename(path) | 返回 path 最后的文件名。如何 path 以/或 \ 结尾,那么就会返回空值,即 os.path.split(path) 的第二个元素。 |
| os.path.exists(path) | 如果 path 存在,返回 True;如果 path 不存在,返回 False |
| os.path.isabs(path) | 如果 path 是绝对路径,返回 True |
| os.path.isfile(path) | 如果 path 是一个存在的文件,返回 True。否则返回 False |
| os.path.isdir(path) | 如果 path 是一个存在的目录,则返回 True。否则返回 False |
| os.path.join(path1[, path2[, …]]) | 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 |
| os.path.getatime(path) | 返回 path 所指向的文件或者目录的最后访问时间 |
| os.path.getmtime(path) | 返回 path 所指向的文件或者目录的最后修改时间 |
| os.path.getsize(path) | 返回 path 的大小 |
import osprint(os.stat('.\config')) # 当前目录下的config文件的信息# 运行结果# os.stat_result(st_mode=33206, st_ino=2814749767208887, st_dev=1788857329, st_nlink=1, st_uid=0, st_gid=0, st_size=185, st_atime=1550285376, st_mtime=1550285376, st_ctime=1550285376)
Python
Copy
| st_mode | inode 保护模式 |
|---|---|
| st_ino | inode 节点号 |
| st_dev | inode 驻留的设备 |
| st_nlink | inode 的链接数 |
| st_uid | 所有者的用户 ID |
| st_gid | 所有者的组 ID |
| st_size | 普通文件以字节为单位的大小;包含等待某些特殊文件的数据 |
| st_atime | 上次访问的时间 |
| st_mtime | 最后一次修改的时间 |
| st_ctime | 由操作系统报告的 “ctime”。在某些系统上(如 Unix)是最新的元数据更改的时间,在其它系统上(如 Windows)是创建时间(详细信息参见平台的文档) |
sys 模块
sys 模块是与 python 解释器交互的一个接口
| sys.argv | 命令行参数 List,第一个元素是程序本身路径 |
|---|---|
| sys.exit(n) | 退出程序,正常退出时 exit(0), 错误退出 sys.exit(1) |
| sys.version | 获取 Python 解释程序的版本信息 |
| sys.path | 返回模块的搜索路径,初始化时使用 PYTHONPATH 环境变量的值 |
| sys.platform | 返回操作系统平台名称 |
re 模块
正则表达式
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在 Python 中)它内嵌在 Python 中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
| 元字符 | 匹配内容 | |
|---|---|---|
| \w | 匹配字母(包含中文)或数字或下划线 | |
| \W | 匹配非字母(包含中文)或数字或下划线 | |
| \s | 匹配任意的空白符 | |
| \S | 匹配任意非空白符 | |
| \d | 匹配数字 | |
| \D | 匹配非数字 | |
| \A | 从字符串开头匹配 | |
| \z | 匹配字符串的结束,如果是换行,只匹配到换行前的结果 | |
| \n | 匹配一个换行符 | |
| \t | 匹配一个制表符 | |
| ^ | 匹配字符串的开始 | |
| $ | 匹配字符串的结尾 | |
| . | 匹配任意字符,除了换行符,当 re.DOTALL 标记被指定时,则可以匹配包括换行符的任意字符。 | |
| […] | 匹配字符组中的字符 | |
| [^…] | 匹配除了字符组中的字符的所有字符 | |
| * | 匹配 0 个或者多个左边的字符。 | |
| + | 匹配一个或者多个左边的字符。 | |
| ? | 匹配 0 个或者 1 个左边的字符,非贪婪方式。 | |
| {n} | 精准匹配 n 个前面的表达式。 | |
| {n,m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 | |
| a | b | 匹配 a 或者 b。 |
| () | 匹配括号内的表达式,也表示一个组 |
单字符匹配
import reprint(re.findall('\w','上大人123asdfg%^&*(_ \t \n)'))print(re.findall('\W','上大人123asdfg%^&*(_ \t \n)'))print(re.findall('\s','上大人123asdfg%^&*(_ \t \n)'))print(re.findall('\S','上大人123asdfg%^&*(_ \t \n)'))print(re.findall('\d','上大人123asdfg%^&*(_ \t \n)'))print(re.findall('\D','上大人123asdfg%^&*(_ \t \n)'))print(re.findall('\A上大','上大人123asdfg%^&*(_ \t \n)'))print(re.findall('^上大','上大人123asdfg%^&*(_ \t \n)'))print(re.findall('666\z','上大人123asdfg%^&*(_ \t \n)666'))print(re.findall('666\Z','上大人123asdfg%^&*(_ \t \n)666'))print(re.findall('666$','上大人123asdfg%^&*(_ \t \n)666'))print(re.findall('\n','上大人123asdfg%^&*(_ \t \n)'))print(re.findall('\t','上大人123asdfg%^&*(_ \t \n)'))
Python
Copy
重复匹配
import reprint(re.findall('a.b', 'ab aab a*b a2b a牛b a\nb'))print(re.findall('a.b', 'ab aab a*b a2b a牛b a\nb',re.DOTALL))print(re.findall('a?b', 'ab aab abb aaaab a牛b aba**b'))print(re.findall('a*b', 'ab aab aaab abbb'))print(re.findall('ab*', 'ab aab aaab abbbbb'))print(re.findall('a+b', 'ab aab aaab abbb'))print(re.findall('a{2,4}b', 'ab aab aaab aaaaabb'))print(re.findall('a.*b', 'ab aab a*()b'))print(re.findall('a.*?b', 'ab a1b a*()b, aaaaaab'))# .*? 此时的?不是对左边的字符进行0次或者1次的匹配,# 而只是针对.*这种贪婪匹配的模式进行一种限定:告知他要遵从非贪婪匹配 推荐使用!# []: 括号中可以放任意一个字符,一个中括号代表一个字符# - 在[]中表示范围,如果想要匹配上- 那么这个-符号不能放在中间.# ^ 在[]中表示取反的意思.print(re.findall('a.b', 'a1b a3b aeb a*b arb a_b'))print(re.findall('a[abc]b', 'aab abb acb adb afb a_b'))print(re.findall('a[0-9]b', 'a1b a3b aeb a*b arb a_b'))print(re.findall('a[a-z]b', 'a1b a3b aeb a*b arb a_b'))print(re.findall('a[a-zA-Z]b', 'aAb aWb aeb a*b arb a_b'))print(re.findall('a[0-9][0-9]b', 'a11b a12b a34b a*b arb a_b'))print(re.findall('a[*-+]b','a-b a*b a+b a/b a6b'))print(re.findall('a[-*+]b','a-b a*b a+b a/b a6b'))print(re.findall('a[^a-z]b', 'acb adb a3b a*b'))# 分组:() 制定一个规则,将满足规则的结果匹配出来print(re.findall('(.*?)_sb', 'cs_sb zhao_sb 日天_sb'))print(re.findall('href="(.*?)"','<a href="http://www.baidu.com">点击</a>'))print(re.findall('compan(y|ies)','Too many companies have gone bankrupt, and the next one is my company'))print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, and the next one is my company'))# 分组() 中加入?: 表示将整体匹配出来而不只是()里面的内容
Python
Copy
常用方法举例
import re# findall 全部找到返回一个列表print(re.findall('a','aghjmnbghagjmnbafgv'))# search 只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回Noneprint(re.search('sb|chensong', 'chensong sb sb demon 日天'))print(re.search('chensong', 'chensong sb sb barry 日天').group())# match:None,同search,不过在字符串开始处进行匹配,完全可以用search+^代替matchprint(re.match('sb|chensong', 'chensong sb sb demon 日天'))print(re.match('chensong', 'chensong sb sb barry 日天').group())# split 分割 可按照任意分割符进行分割print(re.split('[::,;;,]','1;3,c,a:3'))# sub 替换print(re.sub('帅哥','sb','陈松是一个帅哥'))# complie 根据包含的正则表达式的字符串创建模式对象。可以实现更有效率的匹配。obj = re.compile('\d{2}')print(obj.search('abc123eeee').group())print(obj.findall('1231232aasd'))ret = re.finditer('\d','asd123affess32432') # finditer返回一个存放匹配结果的迭代器print(ret)print(next(ret).group())print(next(ret).group())print([i.group() for i in ret])
Python
Copy
命名分组举例
命名分组匹配
import reret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")print(ret.group('tag_name'))print(ret.group())ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>")# 如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致# 获取的匹配结果可以直接用group(序号)拿到对应的值print(ret.group(1))print(ret.group())
Python
Copy
shutil 模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
import shutilshutil.copyfileobj(open('config','r'),open('config.new','w'))
Python
Copy
shutil.copyfile(src, dst)
拷贝文件
import shutilshutil.copyfile('config','config1') # 目标文件无需存在
Python
Copy
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
import shutilshutil.copymode('config','config1') # 目标文件必须存在
Python
Copy
shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
import shutilshutil.copystat('config','config1') # 目标文件必须存在
Python
Copy
shutil.copy(src, dst)
拷贝文件和权限
import shutilshutil.copy('config','config1') # 目标文件必须存在
Python
Copy
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
import shutilshutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))# 目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除# 硬链接shutil.copytree('f1', 'f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))# 软链接
Python
Copy
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
import shutilshutil.rmtree('folder1')
Python
Copy
shutil.move(src, dst)
递归的去移动文件,它类似 mv 命令,其实就是重命名。
import shutilshutil.move('folder1', 'folder3')
Python
Copy
shutil.make_archive(base_name, format,…)
- 创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
- 如 data_bak => 保存至当前路径
- 如:/tmp/data_bak => 保存至 /tmp/
- format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是 logging.Logger 对象
Python# 将 /data 下的文件打包放置当前程序目录import shutilret = shutil.make_archive("data_bak", 'gztar', root_dir='/data')# 将 /data下的文件打包放置 /tmp/目录import shutilret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
Copy
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的
Pythonimport zipfile# 压缩z = zipfile.ZipFile('laxi.zip', 'w')z.write('a.log')z.write('data.data')z.close()# 解压z = zipfile.ZipFile('laxi.zip', 'r')z.extractall(path='.')z.close()
Copyimport tarfilet = tarfile.open('/tmp/egon.tar','w')t.add('/test1/a.py',arcname='a.bak')t.add('/test1/b.py',arcname='b.bak')t.close()t = tarfile.open('/tmp/egon.tar','r')t.extractall('/egon')t.close()
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,

若有收获,就点个赞吧
0 人点赞
