- useState vs useReducer
- 关于 finally 的一些特殊场景
- TSLint in 2019
- Screenshot To Code
- 优化 React App 性能的 5 个建议
- 禁用大体积依赖的 import
- 理解 TS 类型注解
- Back/forward cache for Chrome
- ES 新提案:Promise.any(promises)
- 为什么这个函数不能 new
- 函数组件和类组件的根本差异
- Preact X Alpha 0 released
- Chromium Edge 截图透出
- React 函数组件的 TypeScript 写法
- 用 Jest 和 Enzyme 写测试

- useState vs useReducer
- 关于 finally 的一些特殊场景
- TSLint in 2019
- Screenshot To Code
- 优化 React App 性能的 5 个建议
- 禁用大体积依赖的 import
- 理解 TS 类型注解
- Back/forward cache for Chrome
- ES 新提案:Promise.any(promises)
- 为什么这个函数不能 new
- 函数组件和类组件的根本差异
- Preact X Alpha 0 released
- Chromium Edge 截图透出
- React 函数组件的 TypeScript 写法
- 用 Jest 和 Enzyme 写测试
useState vs useReducer
这两个内置的 React Hooks 都可以处理状态,那么我们应该如何对二者进行选择呢?
根据我个人的实践来看,在 H5 项目中,useReducer 可以很好的按照 Redux 的模式完成许多工作,同时又可以不引入 Redux 的依赖。那么大佬们是怎么说的呢?
Matt Hamlin 的文章 useReducer, don’t useState 对这个问题进行了讨论。在本文中,我们先来看下作者在他自己的项目中被问到的一个问题
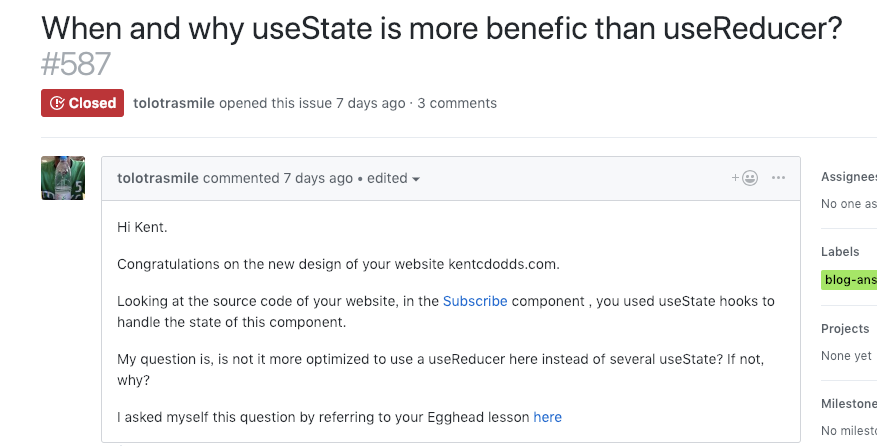
我们来看看所谓的 Subscribe 组件的实现:
const [submitted, setSubmitted] = React.useState(false)const [loading, setLoading] = React.useState(false)const [response, setResponse] = React.useState(null)const [errorMessage, setErrorMessage] = React.useState(null)
是的,因为有了这么些状态,就不免相应的有很多调用状态更新方法的地方:
async function handleSubmit(values) {setSubmitted(false)setLoading(true)try {const responseJson = await fetch(/* stuff */).then(r => r.json())setSubmitted(true)setResponse(responseJson)setErrorMessage(null)} catch (error) {setSubmitted(false)setErrorMessage('Something went wrong!')}setLoading(false)}
可如果我们用 useReducer 重写上面的逻辑,就会变成下面这样:
const [state, dispatch] = React.useReducer(reducer, {submitted: false,loading: false,response: null,errorMessage: null,})
而 reducer 的实现就像下面这样:
const types = {SUBMIT_STARTED: 0,SUBMIT_COMPLETE: 1,SUBMIT_ERROR: 2,};function reducer(state, action) {switch (action.type) {case types.SUBMIT_STARTED: {return { ...state, submitted: false, loading: true };}case types.SUBMIT_COMPLETE: {return {...state,submitted: true,response: action.response,errorMessage: null,loading: false,};}case types.SUBMIT_ERROR: {return {...state,submitted: false,errorMessage: action.errorMessage,loading: false,};}default: {return state;}}}
相应的 handleSubmit 方法就可以调整为:
async function handleSubmit(values) {dispatch({ type: types.SUBMIT_STARTED });try {const responseJson = await fetch(/* stuff */).then(r => r.json());dispatch({ type: types.SUBMIT_COMPLETE, response: responseJson });} catch (error) {dispatch({ type: types.SUBMIT_ERROR, errorMessage: 'Something went wrong!' });}}
Matt Hamlin 在他的文章中列举了如下几点来表明 useReducer 相比 useState 的优越性:
- 更容易管理较大较复杂的状态
- 更容易被其他开发者所理解
- 更容易测试
对于上面这种特定的例子,作者并不觉得第一条和第二条真的成立。只是 4 个状态元素很难说就是个大的复杂的状态,而且前后似乎也看不出有什么更容易理解。作者认为这两种写法是一样的。
至于测试,作者表示绝对同意 reducer 更容易读力测试,如果有很多业务逻辑,这确实是个很好的优势。
在作者看来,有一个原因他会更愿意使用 useState:
当我们并不确定一个组件的具体实现同时我们需要构建这一组件的时候。
当我们构建一个新的组件,我们经常需要在组件的实现代码中添加/删除状态。作者认为,面对这种情况,reducer 的写法调整起来会更加麻烦。一旦你确定了你希望你的组件是什么样的,你就可以决定是否从若干个 useState 的写法转换成一个 useReducer 来写。此外,你也可以考虑使用 useReducer 来实现其中的一部分,并使用 useState 来实现其他部分的逻辑。作者认为,等到确定代码究竟要调整成什么样子时再开始抽象会更好一些。
总的来说,二者自然是兼具优点与缺点的,具体还是得看要怎么用。结合我自己的实践,我发觉文中的意思乍看有些废话,但实际上是有道理的。在我使用 useState 写完之后确定了逻辑,就会开始觉得 useState 的写法有些凌乱,此时在已经确定了各个状态的情况下,再调整成 useReducer 就水到渠成了。
源地址:https://kentcdodds.com/blog/should-i-usestate-or-usereducer
关于 finally 的一些特殊场景
今天我们来看下 finally 在一些特殊场景下的行为。
场景列举
在 catch 中 throw
如果我们在 catch 块中抛出一个异常,且异常没有相应的 catch 来捕获,会发生什么情况呢?
function example() {try {fail()}catch (e) {console.log("Will finally run?")throw e}finally {console.log("FINALLY RUNS!")}console.log("This shouldn't be called eh?")}example()
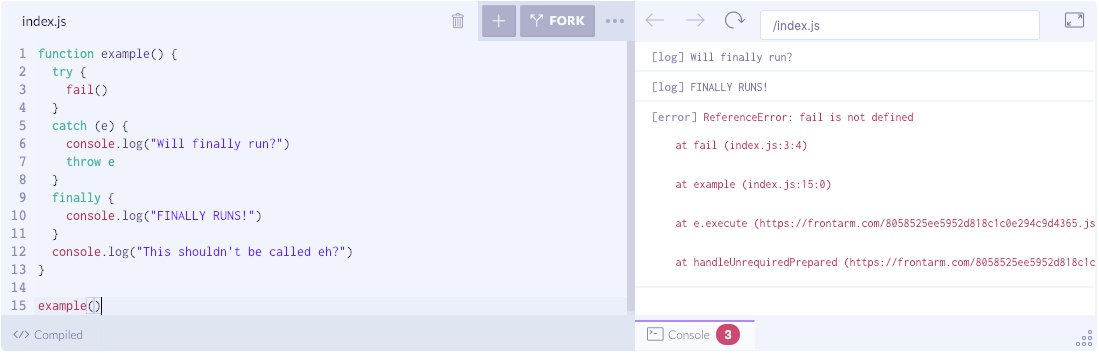
finally 会执行,即使最后一句 console 并没有。finally 是比较特殊的,它使得我们可以执行在抛出异常和离开函数之间的东西,即使异常本身是在 catch 块中抛出的。
没有 catch 的情况
如果没有 catch,finally 又会有怎样的行为呢?当然这一点一般都知道。
function example() {try {console.log("Hakuna matata")}finally {console.log("What a wonderful phrase!")}}example()
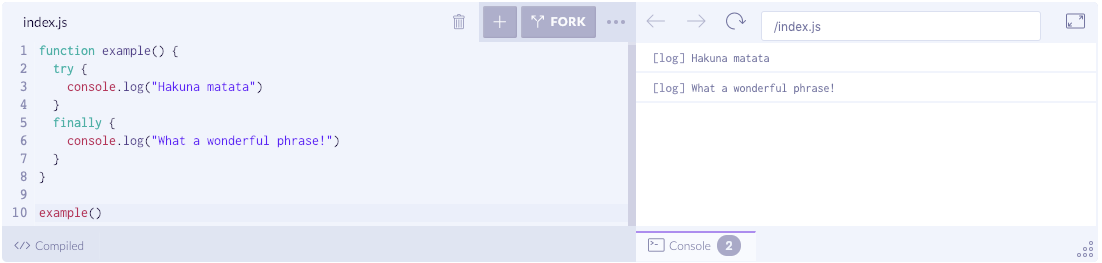
即使 try 中没有错误,finally 仍然会执行,这一点一般都是知道的。当然,如果有错误,那么 finally 也是会执行的。也就是说,finally 会覆盖这两种情况,如下:
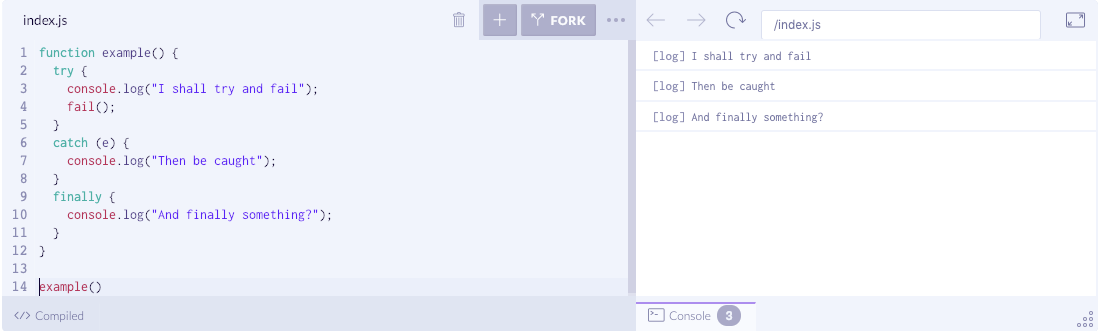
try 中 return 的 finally
如果我们没有出现错误,并且只是 return 了,会怎么执行呢?
function example() {try {console.log("I'm picking up my ball and going home.")return}finally {console.log('Finally?')}}example()
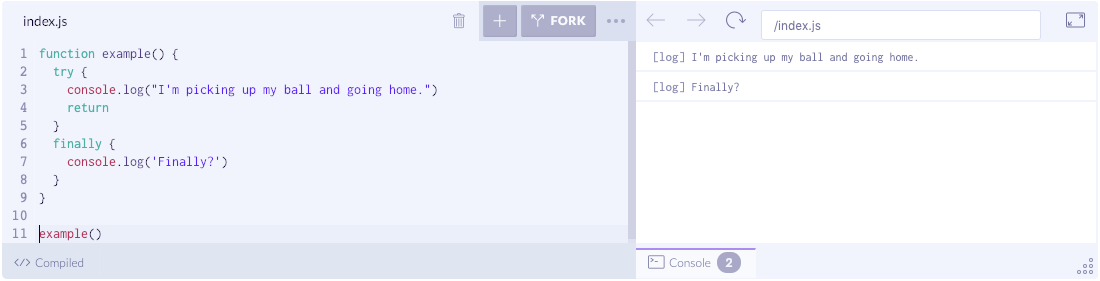
总结
finally 总会执行,即使因为抛出异常或执行 return 而提前结束。
这样就让其非常有用,当我们有无论如何都要执行的东西时,放在 finally 就总是可以执行,例如 cleanup 等等。
源地址:https://frontarm.com/james-k-nelson/will-finally-run-quiz/
TSLint in 2019
Palantir 是 TSLint 的创建及主要维护团队,而 TSLint 是 TypeScript 的标准 linter。由于 TypeScript 社区致力于统一 TypeScript 和 JavaScript 的开发体验,因而作者他们支持 TSLint 和 ESLint 的融合工作。在这篇博文中,他们解释了这样做的原因并阐述了如何去做。
TSLint 与 ESLint 的现状
如今,TSLint 已经是事实上的用 TypeScript 实现的项目和 TypeScript 自身实现的标准 linter。 TSLint 生态系统由核心规则集、社区维护的自定义规则和配置包组成。
与之相对的是,ESLint 是标准的 JavaScript linter。和 TSLint 一样,它由核心规则集和社区维护的自定义规则组成。 ESLint 支持 TSLint 缺少的许多功能,例如条件 lint 配置和自动缩进。与之相对的是,ESLint 规则不能(至少现在不能)从 TypeScript 提供的静态分析和类型推理中受益,因此无法捕获 TSLint 语义规则所涵盖的一类错误和代码嗅探。
TypeScript + ESLint
TypeScript 团队的战略方向(Roadmap)是为了实现「每家每户每个 JavaScript 程序员都可以用上类型」,哈哈哈搞笑。换句话说,他们的方向是使用类型和静态分析等 TypeScript 功能,渐进式的丰富 JavaScript 开发人员的体验,直到 TypeScript 和 JavaScript 开发人员体验融合统一为止。
很明显,linting 是 TypeScript 和 JavaScript 开发人员使用体验的一个核心部分,因此 Palantir 的 TSLint 团队与 Redmond 的 TypeScript 核心团队会面,讨论 TypeScript / JavaScript 的融合之于 linting 的意义。TypeScript 社区旨在满足 JavaScript 开发人员的需求,ESLint 是 JavaScript linting 的首选工具。我们计划弃用 TSLint,集中精力为 ESLint 改进 TypeScript 支持。我们认为这是正确的前进道路,兼具战略性和务实性:
- 降低使用门槛
JavaScript 开发人员迁移到 TypeScript 的障碍之一是从 ESLint 到 TSLint 的并不轻松的迁移。允许开发人员从他们现有的 ESLint 设置开始,逐步添加 TypeScript 特定的静态分析可以减少这一障碍。
- 统一社区
ESLint 和 TSLint 共同的核心目标是:通过强大的核心规则集和大量插件提供出色的代码 linting 体验。现在,在 ESLint 中可以使用 TypeScript 解析,我们认为社区最好能够做到标准化,而不是在竞争中维护不同的代码。
- 性能更好的分析架构
ESLint API 允许更有效地实现某些类检查。虽然可以重构 TSLint 的 API,但是利用 ESLint 的架构并将我们的开发资源集中在其他地方似乎是明智的。
下一步
Palantir 将通过一系列功能和插件为 ESLint 的平滑过渡提供支持,并以此回馈 TSLint 社区。例如:
- 在 TypeScript 中使用 ESLint 规则的支持及文档:issue。
- typescript-eslint 的测试架构:ESLint 内置的检查并不好用,且语法很难阅读。我们想要带来类似TSLint’s testing infrastructure 的东西以确保 TSLint 规则的开发体验。
- 语义化的基于类型的检查规则:移植并添加使用 TypeScript 语言服务的新规则。
一旦我们认为,ESLint 已经参照 TSLint 完成了各个特性,我们就会废弃 TSLint 并帮助用户迁移到 ESLint。我们总结下目前的主要任务是:
- 继续 TSLint 的支持:最重要的维护任务是确保新的变异版本和特性的兼容性。
- TSLint -> ESLint 兼容包:一旦 ESLint 的静态分析检查可以与 TSLint 相提并论,我们就会推出 eslint-config-palantir 包,一个插入式的替代 TSLint 规则的 ESLint 包。
源地址:https://medium.com/palantir/tslint-in-2019-1a144c2317a9
Screenshot To Code
从设计稿变前端代码的故事已经说了很久,而这两天再次更新的 Screenshot To Code 是除了 pix2code 等之外的更让人兴奋的模型。
看看效果
我们来看下整个三步走,首先是将设计稿传入训练好的网络模型(图中其实是在 Jupyter Notebook 里执行 python 脚本):
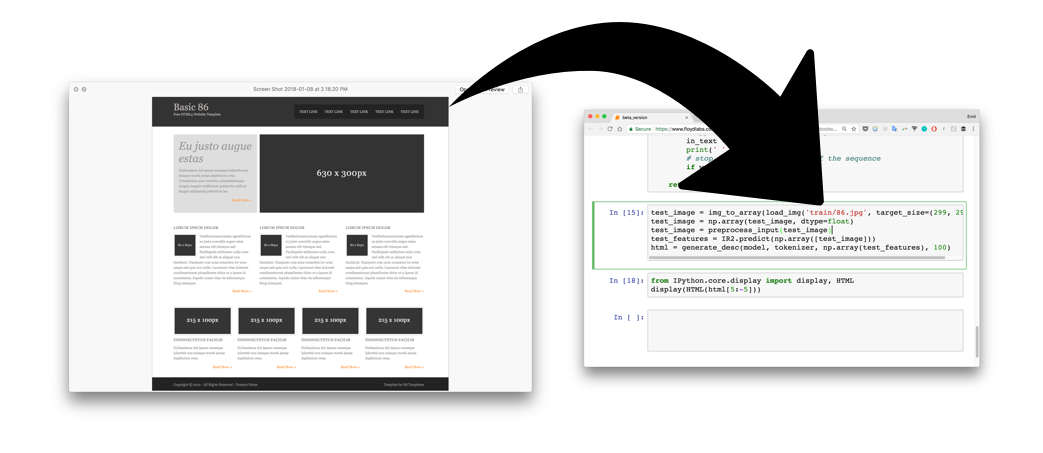
然后模型就会将图片转换成 HTML 标签:
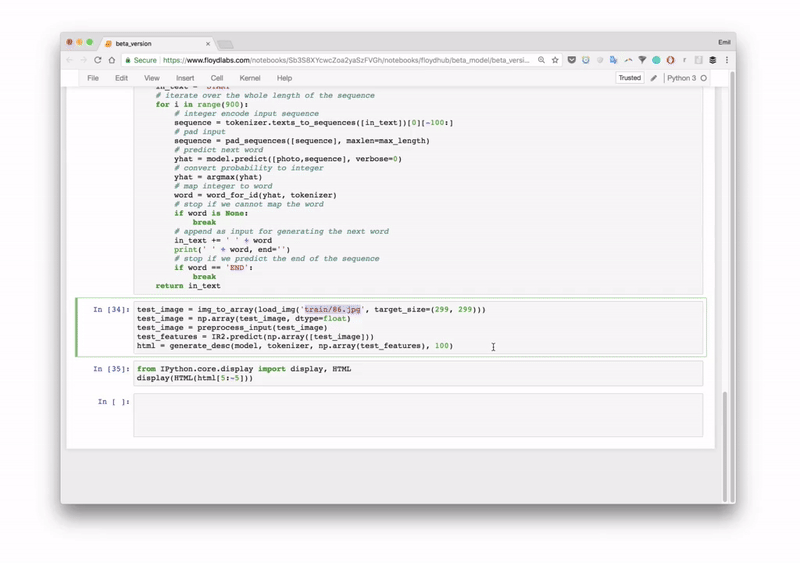
还是很骚的哈。最后渲染出来的静态页面如下,看上去效果很酷啊,不过我们也都知道,展示效果嘛。
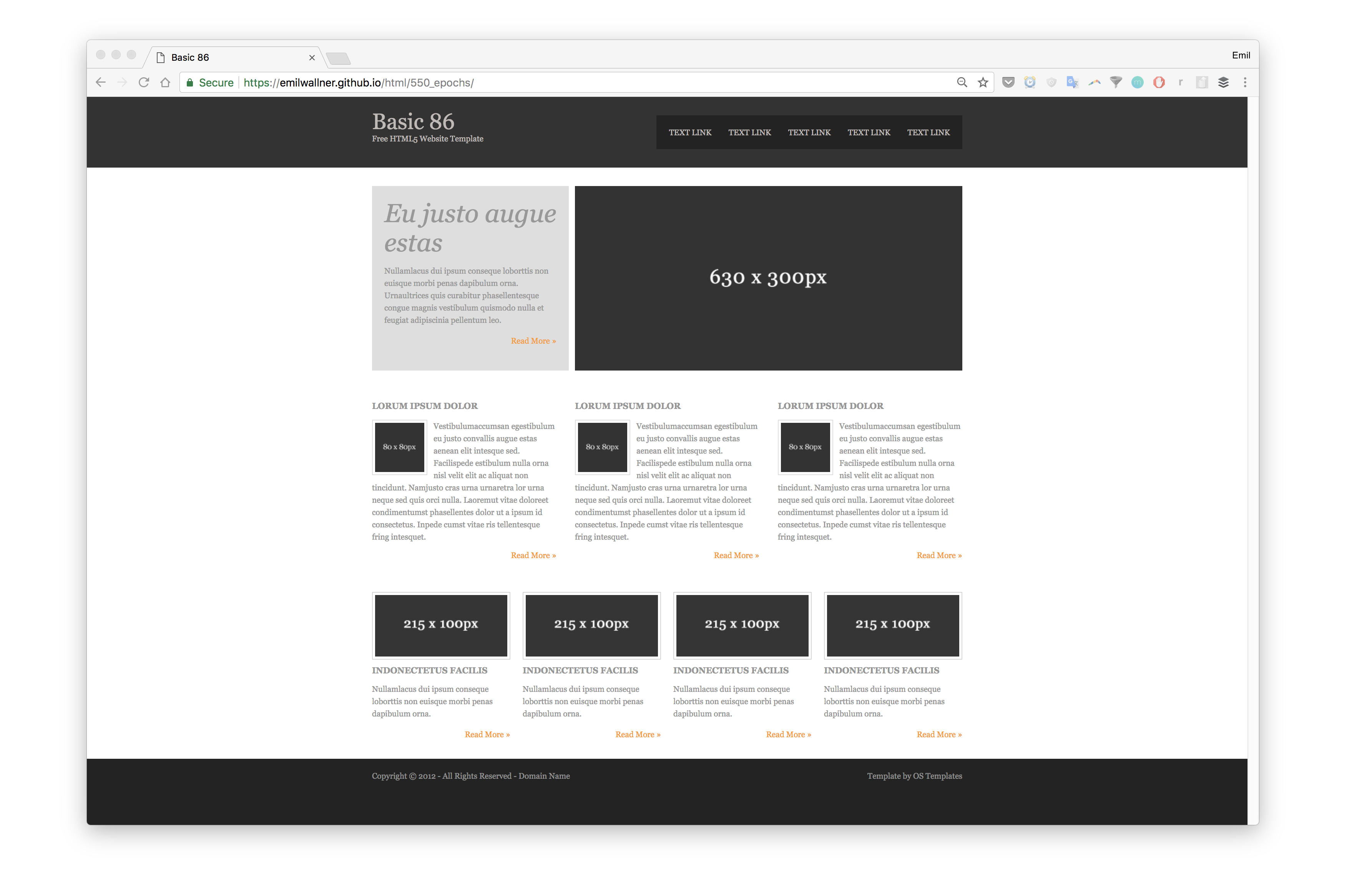
简单分析
框架使用的还是 Keras,然后仓库中提供了 HTML 和 Bootstrap 版本。具体核心逻辑可以参考这篇文章,笔者尚未深入研读,这里就不秀了。
大致的意思是,HTML 标签的输出,是以一个标签和 screenshoot 为输入得到下一个标签,然后再以已有的标签再去推测后续的标签。
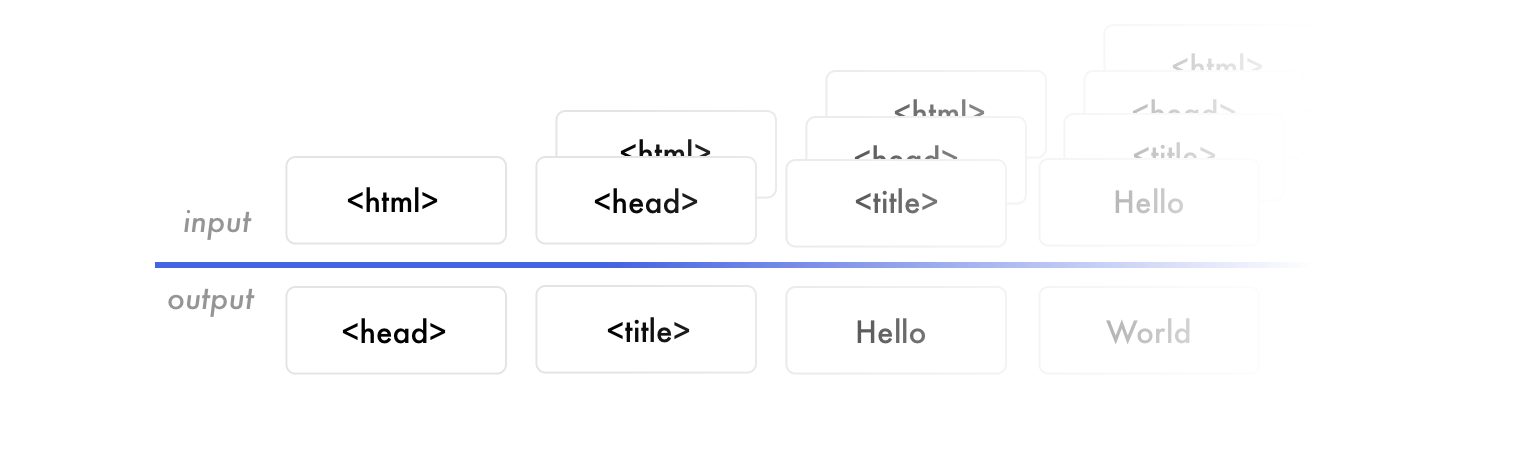
这种思路是借鉴了一个 word 跟着一个 word 的预测,因此网络模型中也大量用到了 LSTM。
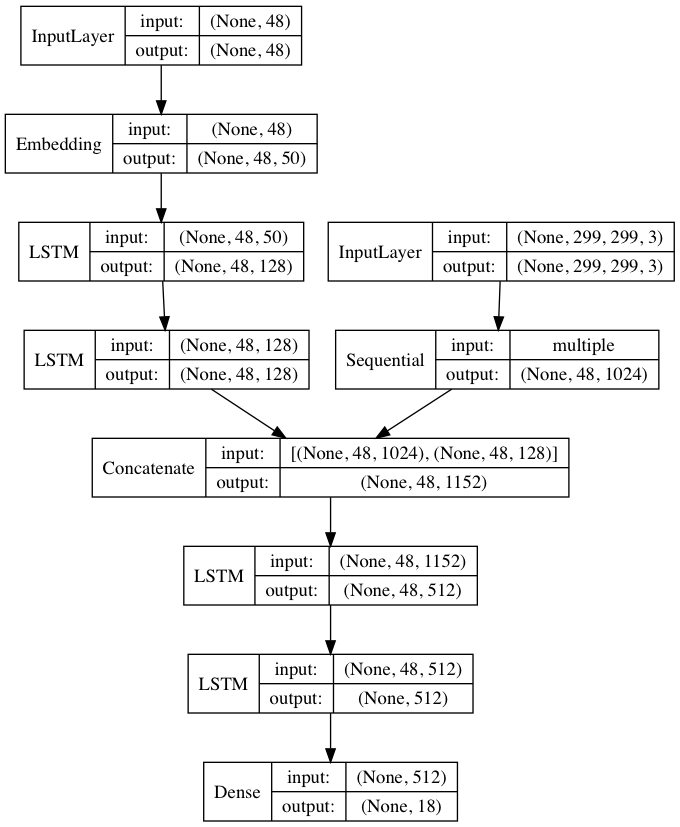
还是可以再了解了解这块东西的,晚点再深入读来看看。
源地址:https://yuque.antfin-inc.com/es2049/wl24q5/pivs9p/edit
优化 React App 性能的 5 个建议

本篇将从 render 角度来探讨 5 个 React App 的优化技巧。需要声明的是,文中将涉及部分 React 16.8.2 的内容,也就是说会有些 Hooks 相关内容。当然,这不是全部,不过理解了 React Hooks 后食用效果更佳。
当我们讨论 React App 的性能问题时,不可避免的就是要探讨我们的组件渲染的有多快。在进入到具体优化建议之前,我们先要理解以下 3 点:
- 当我们在说「渲染」时,我们在说什么?
- 什么时候会有「渲染」?
- 在「渲染」过程中会发生什么?
关于 render 函数
这部分我们将从一种更简单的方式来理解 reconciliation 和 diffing 的概念,当然文档在这里。
哪个是 render 函数?
这个问题其实写过 React 的人都会知道,这里简单说下:
在 class 组件中,指的是 render 方法:
class Foo extends React.Component {render() {return <h1> Foo </h1>;}}
在函数式组件中,我们指的是函数组件本身:
function Foo() {return <h1> Foo </h1>;}
render 什么时候会执行?
render 函数会在两种场景下被调用:
1. 状态更新时
a. 继承自 React.Component 的 class 组件更新状态时
import React from "react";import ReactDOM from "react-dom";class App extends React.Component {render() {return <Foo />;}}class Foo extends React.Component {state = { count: 0 };increment = () => {const { count } = this.state;const newCount = count < 10 ? count + 1 : count;this.setState({ count: newCount });};render() {const { count } = this.state;console.log("Foo render");return (<div><h1> {count} </h1><button onClick={this.increment}>Increment</button></div>);}}const rootElement = document.getElementById("root");ReactDOM.render(<App />, rootElement);
可以看到,代码中的逻辑是我们点击就会更新 count,到 10 以后,就会维持在 10。增加一个 console.log,这样我们就可以知道 render 是否被调用了。
总结:继承了 React.Component 的 class 组件,即使状态没变化,只要调用了setState 就会触发 render。
b. 函数式组件更新状态时
我们用函数实现相同的组件,当然因为要有状态,我们用上了 useState hook:
import React, { useState } from "react";import ReactDOM from "react-dom";class App extends React.Component {render() {return <Foo />;}}function Foo() {const [count, setCount] = useState(0);function increment() {const newCount = count < 10 ? count + 1 : count;setCount(newCount);}console.log("Foo render");return (<div><h1> {count} </h1><button onClick={increment}>Increment</button></div>);}const rootElement = document.getElementById("root");ReactDOM.render(<App />, rootElement);
我们可以注意到,当状态值不再改变之后,render 的调用就停止了。
总结:对函数式组件来说,状态值改变时会触发 render 函数的调用。
2. 父容器重新渲染时
import React from "react";import ReactDOM from "react-dom";class App extends React.Component {state = { name: "App" };render() {return (<div className="App"><Foo /><button onClick={() => this.setState({ name: "App" })}>Change name</button></div>);}}function Foo() {console.log("Foo render");return (<div><h1> Foo </h1></div>);}const rootElement = document.getElementById("root");ReactDOM.render(<App />, rootElement);
只要点击了 App 组件内的 Change name 按钮,就会重新 render。而且可以注意到,不管 Foo 具体实现是什么,Foo 都会被重新渲染。
总结:无论组件是继承自 React.Component 的 class 组件还是函数式组件,只要父容器重新 render 了,组件的 render 都会被再次调用。
render 函数执行时发生了什么?
只要 render 函数被调用,就会有两个步骤按顺序执行。这两个步骤非常重要,理解了它们才好知道如何去优化 React App。
Diffing
在此步骤中,React 将新调用的 render 函数返回的树与旧版本的树进行比较,这一步是 React 决定如何更新 DOM 的必要步骤。虽然 React 使用高度优化的算法执行此步骤,但仍然需要付出一定性能开销。
Reconciliation
基于 diffing 的结果,React 更新 DOM 树。这一步同样要因为卸载和挂载 DOM nodes 带来了许多的性能开销。
Tip
Tip #1:慎重分配 state 以避免不必要的 render 调用
我们以下面的例子为例,其中 App 会渲染两个组件:
CounterLabel,接收 count 值和一个增加父组件 App 中的状态 count 的值的方法。List,接收 item 的列表。
import React, { useState } from "react";import ReactDOM from "react-dom";const ITEMS = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12];function App() {const [count, setCount] = useState(0);const [items, setItems] = useState(ITEMS);return (<div className="App"><CounterLabel count={count} increment={() => setCount(count + 1)} /><List items={items} /></div>);}function CounterLabel({ count, increment }) {return (<><h1>{count} </h1><button onClick={increment}> Increment </button></>);}function List({ items }) {console.log("List render");return (<ul>{items.map((item, index) => (<li key={index}>{item} </li>))}</ul>);}const rootElement = document.getElementById("root");ReactDOM.render(<App />, rootElement);
只要父组件 App 中的状态被更新,CounterLabel 和 List 就都会更新。
当然,CounterLabel 重新渲染是正常的,因为 count 发生了变化,自然要重新渲染。但是对于 List 而言,就完全是不必要的更新了,因为它的渲染是独立于 count 值的。尽管 React 并不会在 reconciliation 阶段真的更新 DOM,毕竟完全没变化,但是仍然会执行 diffing 阶段来对前后的树进行对比,这仍然存在性能开销。
还记得 render 执行的 diffing 和 reconciliation 阶段吗?前面讲过的东西在这里碰到了。
因此,为了避免不必要的 diffing 开销,我们应当考虑将特定的状态值放到更低的层级或组件中(与 React 中所说的「提升」概念正好相反)。在这个例子中,我们就是要将 count 值放到 CounterLabel 组件中管理来解决这个问题。
Tip #2:合并状态更新
因为每次状态更新都会触发新的 render 调用,那么更少的状态更新也就可以更少的调用 render 了。
我们知道,React class 组件有 componentDidUpdate(prevProps, prevState) 的钩子,可以用来检测 props 或 state 有没有发生变化。尽管有时有必要在 props 发生变化时再触发 state 更新,但我们总可以避免在一次 state 变化后再进行一次 state 更新这种操作:
import React from "react";import ReactDOM from "react-dom";function getRange(limit) {let range = [];for (let i = 0; i < limit; i++) {range.push(i);}return range;}class App extends React.Component {state = {numbers: getRange(7),limit: 7};handleLimitChange = e => {const limit = e.target.value;const limitChanged = limit !== this.state.limit;if (limitChanged) {this.setState({ limit });}};componentDidUpdate(prevProps, prevState) {const limitChanged = prevState.limit !== this.state.limit;if (limitChanged) {this.setState({ numbers: getRange(this.state.limit) });}}render() {return (<div><inputonChange={this.handleLimitChange}placeholder="limit"value={this.state.limit}/>{this.state.numbers.map((number, idx) => (<p key={idx}>{number} </p>))}</div>);}}const rootElement = document.getElementById("root");ReactDOM.render(<App />, rootElement);
这里渲染了一个范围的数字序列,范围为 0 到 limit。只要用户改变了 limit 值,我们就会在 componentDidUpdate 中进行检测,并设定新的数字列表。
毫无疑问,上面的代码是可以满足需求的,但是,我们仍然可以进行优化。
上面的代码中,每次 limit 发生改变,我们都会触发两次状态更新:第一次是为了修改 limit,第二次是为了修改展示的数字列表。这样一来,每次 limit 的变化会带来两次 render 开销:
// 初始状态{ limit: 7, numbers: [0, 1, 2, 3, 4, 5, 6]// 更新 limit -> 4render 1: { limit: 4, numbers: [0, 1, 2, 3, 4, 5, 6] } //render 2: { limit: 4, numbers: [0, 2, 3]
我们的代码逻辑带来了下面的问题:
- 我们触发了比实际需要更多的状态更新;
- 我们出现了「不连续」的渲染结果,数字列表与 limit 不匹配。
为了改进,我们应避免在不同的状态更新中改变数字列表。事实上,我们可以在一次状态更新中搞定:
import React from "react";import ReactDOM from "react-dom";function getRange(limit) {let range = [];for (let i = 0; i < limit; i++) {range.push(i);}return range;}class App extends React.Component {state = {numbers: [1, 2, 3, 4, 5, 6],limit: 7};handleLimitChange = e => {const limit = e.target.value;const limitChanged = limit !== this.state.limit;if (limitChanged) {this.setState({ limit, numbers: getRange(limit) });}};render() {return (<div><inputonChange={this.handleLimitChange}placeholder="limit"value={this.state.limit}/>{this.state.numbers.map((number, idx) => (<p key={idx}>{number} </p>))}</div>);}}const rootElement = document.getElementById("root");ReactDOM.render(<App />, rootElement);
Tip #3:使用 PureComponent 和 React.memo 以避免不必要的 render 调用
我们在之前的例子中看到将特定状态值放到更低的层级来避免不必要渲染的方法,不过这并不总是有用。
我们来看下下面的例子:
import React, { useState } from "react";import ReactDOM from "react-dom";function App() {const [isFooVisible, setFooVisibility] = useState(false);return (<div className="App">{isFooVisible ? (<Foo hideFoo={() => setFooVisibility(false)} />) : (<button onClick={() => setFooVisibility(true)}>Show Foo </button>)}<Bar name="Bar" /></div>);}function Foo({ hideFoo }) {return (<><h1>Foo</h1><button onClick={hideFoo}>Hide Foo</button></>);}function Bar({ name }) {return <h1>{name}</h1>;}const rootElement = document.getElementById("root");ReactDOM.render(<App />, rootElement);
可以看到,只要父组件 App 的状态值 isFooVisible 发生变化,Foo 和 Bar 就都会被重新渲染。
这里因为需要决定 Foo 是否要被渲染出来,我们需要将 isFooVisible 放在 App中维护,因此也就不能将状态拆除放到更低的层级。不过,在 isFooVisible 发生变化时重新渲染 Bar 仍然是不必要的,因为 Bar 并不依赖 isFooVisible。我们只希望 Bar 在传入属性 name 变化时重新渲染。
那我们该怎么搞呢?两种方法。
其一,对 Bar 做记忆化(memoize):
const Bar = React.memo(function Bar({name}) {return <h1>{name}</h1>;});
这就能保证 Bar 只在 name 发生变化时才重新渲染。
此外,另一个方法就是让 Bar 继承 React.PureComponent 而非 React.Component:
class Bar extends React.PureComponent {render() {return <h1>{name}</h1>;}}
是不是很熟悉?我们经常提到使用 React.PureComponent 能带来一定的性能提升,避免不必要的 render。
总结:避免组件不必要的渲染的方法有:React.memo 包起来的函数式组件,继承自 React.PureComponent 的 class 组件。
为什么不让每个组件都继承 PureComponent 或者用 memo 包呢?
如果这条建议可以让我们避免不必要的重新渲染,那我们为什么不把每个 class 组件变成 PureComponent、把每个函数式组件用 React.memo 包起来?为什么有了更好的方法还要有 React.Component 呢?为什么函数式组件不默认记忆化呢?
毫无疑问,这些方法并不总是万灵药呀。
嵌套对象的问题
我们先来考虑下 PureComponent 和 React.memo 的组件到底做了什么?
每次更新的时候(包括状态更新或上层组件重新渲染),它们就会在新 props、state 和旧 props、state 之间对 key 和 value 进行浅比较。浅比较是个严格相等的检查,如果检测到差异,render 就会执行:
// 基本类型的比较shallowCompare({ name: 'bar'}, { name: 'bar'}); // output: trueshallowCompare({ name: 'bar'}, { name: 'bar1'}); // output: false
尽管对于基本类型(如字符串、数字、布尔)的比较工作的很好,如对象这类复杂的值可能就会带来意想不到的行为:
shallowCompare({ name: {first: 'John', last: 'Schilling'}},{ name: {first: 'John', last: 'Schilling'}}); // output: false
上述两个 name 对象的引用是不同的。
我们重新看下之前的例子,然后修改我们传入 Bar 的 props:
import React, { useState } from "react";import ReactDOM from "react-dom";const Bar = React.memo(function Bar({ name: { first, last } }) {console.log("Bar render");return (<h1>{first} {last}</h1>);});function Foo({ hideFoo }) {return (<><h1>Foo</h1><button onClick={hideFoo}>Hide Foo</button></>);}function App() {const [isFooVisible, setFooVisibility] = useState(false);return (<div className="App">{isFooVisible ? (<Foo hideFoo={() => setFooVisibility(false)} />) : (<button onClick={() => setFooVisibility(true)}>Show Foo</button>)}<Bar name={{ first: "John", last: "Schilling" }} /></div>);}const rootElement = document.getElementById("root");ReactDOM.render(<App />, rootElement);
尽管 Bar 做了记忆化且 props 值并没有发生变动,每次父组件重新渲染时它仍然会重新渲染。这是因为每次比较的两个对象尽管拥有相同的值,却因为浅比较的引用不同触发重新渲染。
函数 props 的问题
我们也可以把函数作为属性向组件传递,当然,在 JavaScript 中函数也是传递的引用,因此浅比较也是基于其传递的引用。
因此,如果我们传递的是箭头函数(匿名函数),组件仍然会在父组件重新渲染时重新渲染。
Tip #4:更好的 props 写法
前面的问题的一种解决方法是改写我们的 props。
我们不传递对象作为 props,而是将对象拆分成基本类型:
<Bar firstName="John" lastName="Schilling" />
而对于传递箭头函数的场景,我们可以代以只唯一声明过一次的函数,从而总可以拿到相同的引用,如下所示:
class App extends React.Component{constructor(props) {this.doSomethingMethod = this.doSomethingMethod.bind(this);}doSomethingMethod () { // do something}render() {return <Bar onSomething={this.doSomethingMethod} />}}
Tip #5:控制更新
还是那句话,任何方法总有其适用范围。
第三条建议虽然处理了不必要的更新问题,但我们也不总能使用它。
而第四条,在某些情况下我们并不能拆分对象,如果我们传递了某种嵌套确实复杂的数据结构,那我们也很难将其拆分开来。
不仅如此,我们并不总能传递只声明了一次的函数。比如在我们的例子中,如果 App 是个函数式组件,恐怕就不能做到这一点了(在 class 组件中,我们可以用 bind 或者类内箭头函数来保证 this 的指向及唯一声明,而在函数式组件中则可能会导致一些问题)。
幸运的是,无论是 class 组件还是函数式组件,我们都有办法控制浅比较的逻辑。
在 class 组件中,我们可以使用生命周期钩子 shouldComponentUpdate(prevProps, prevState) 来返回一个布尔值,当返回值为 true 时才会触发 render。
而如果我们使用 React.memo,我们可以传递一个比较函数作为第二个参数。
注意!React.memo 的第二参数(比较函数)和
shouldComponentUpdate的逻辑是相反的,只有当返回值为 false 的时候才会触发 render。参考文档。
const Bar = React.memo(function Bar({ name: { first, last } }) {console.log("update");return (<h1>{first} {last}</h1>);},(prevProps, newProps) =>prevProps.name.first === newProps.name.first &&prevProps.name.last === newProps.name.last);
尽管这条建议是可行的,但我们仍要注意比较函数的性能开销。如果 props 对象过深,反而会消耗不少的性能。
总结
上述场景仍不够全面,但多少能带来一些启发性思考。当然我们还有许多其他的问题需要考虑,但遵守上述的准则仍能带来相当不错的性能提升。
禁用大体积依赖的 import
Addy Osmani 大佬推荐了一个 ESLint 的方法来达成这一效果。
有时候我们可能在团队的项目中禁用大体积依赖包的引入,而这一点我们可以借助 ESLint 来指定项目中不引用特定的依赖来做到,也即 no-restricted-modules 规则。
如下的例子展示的是禁用 moment.js 的引入(这类体积大的直接引用的话肯定就爆了,不过我们也常常会考虑按需加载)。这条规则也支持自定义提示信息,所以错误提示可以建议大家使用小一些的包来代替,如 date-fns、Luxon 等。
{"rules": {"no-restricted-imports": ["error", {"paths": [{"name": "moment","message": "Use date-fns or Luxon instead!"}]}]}}
这样一来,当团队中有人尝试着如下写法,就会报错:
import moment from 'moment';
另一个例子是禁用 lodash:
{"rules": {"no-restricted-imports": ["error", {"name": "lodash","message": "Use lodash-es instead!",}],}}
当然,我们也可以不适用错误提示,一个数组搞定:
{"rules": {"no-restricted-imports": ["error", "underscore", "bluebird"]}}
当然,还有一些高级用法,no-restricted-modules 还支持类似 .gitignore 风格的模式。例如,如果有人尝试着引入匹配了 legacy/* 模式的包,我们就会报错,如 import helpers from 'legacy/helpers'; 这种:
{"rules": {"no-restricted-imports": ["error", {"patterns": ["legacy/*"]}],}}
源地址:https://addyosmani.com/blog/disallow-imports/
理解 TS 类型注解
这篇文章来自 Dr. Axel Rauschmayer 的博客,对 TypeScript 的静态类型注解进行了梳理。今天来学习下。
1. 我们会学到什么
在读完本篇文章后,我们应该能够理解下面这段代码的含义:
interface Array<T> {concat(...items: Array<T[] | T>): T[];reduce<U>(callback: (state: U, element: T, index: number, array: T[]) => U,firstState?: U): U;···}
上面这一坨看上去让人晕眩。一旦理解,就可以通过上面的表达很快明白整个代码行为。
2. 尝试运行文中的例子
TypeScript 有个 在线测试网站。为了得到最全面的检查,我们应该把 Options 所有项都打开。这就等同于 TypeScript 编译器打开 —strict 模式。
3. 指定类型检测的严格度(comprehensiveness)
一般来说,使用 TypeScript 还是要打开最严格的设置的,即 —strict,不然的话,程序本身可能会更好写一些,但是肯定会失去静态类型检查的诸多好处。目前,这一设置会打开如下子设置项:
- —noImplicitAny: 如果 TypeScript 不能推断出类型,你就必须手动指定。这通常用于函数方法的参数:有了这一设定,我们就必须注解参数类型。
- —noImplicitThis: 如果 this 的类型不明确,就会报问题。
- —alwaysStrict: 尽可能使用 JavaScript 的严格模式。
- —strictNullChecks: null 什么类型也不是 (除了它本身的类型:null) ,而且必须显示指明。
- —strictFunctionTypes: 对于函数类型进行更严格的检查。
- —strictPropertyInitialization: 如果一个属性不能够为 undefined,那么它必须在构造函数中被初始化。
4. 类型(Types)
本文定义类型就是「一些值的集合」。JavaScript (不是 TypeScript!) 有 7 种类型:
- Undefined: 只有 undefined 的集合。
- Null: 只有 null 的集合。
- Boolean: 有 false 和 true 的集合。
- Number: 所有数字的集合。
- String: 所有字符串的集合。
- Symbol: 所有符号的集合。
- Object: 所有对象的集合(包含函数和数组)。
所有这些类型都是动态的,我们可以在运行时使用它们。
TypeScript 为 JavaScript 带来了额外的一层:静态类型。静态类型只存在于编译或对源代码进行类型检查的时候。每个存储位置(变量或属性)都有一个静态类型,类型检查会确保其对值类型的预测正确。当然,还有很多可以静态检查的方式。如果函数调用的参数类型为数字,那么传入字符串就会报错。
5. 类型注解(Type annotations)
变量名后的冒号后跟着的就是类型注解:这个类型签名标识变量可以拥有什么样的值。
A colon after a variable name starts a type annotation: the type signature after the colon describes what values the variable can have. 例如下面的代码标识 x 只能为数字类型:
let x: number;
如果我们用 undefined 对 x 进行初始化(毕竟一个变量在未赋值的状态下默认就是 undefined),那么 TypeScript 会让我们无法对其进行赋值。
6. 类型推理(Type inference)
尽管在 TypeScript 中每一个存储位置里都带有静态类型,我们并不总是需要显示指定。TypeScript 是可以推测类型的。例如:
let x = 123;
上面的代码就可以直接推测出数字类型。
7. 描述类型(Describing types)
What comes after the colon of a type annotation is a so-called type expression. These range from simple to complex and are created as follows.
在冒号后跟着的类型注解就是所谓的类型表达式,基本的类型如下:
- JavaScript 动态类型相应的静态类型:
- undefined, null
- boolean, number, string
- symbol
- object.
- 注意: 值 undefined vs 类型 undefined (取决于使用的位置)
- TypeScript 特定类型:
- Array (准确的说并不是 JS 的类型)
- any (任意类型)
- Etc.
注意,作为值的 undefined 和作为类型的 undefined 都写作 undefined,而具体是什么取决于我们使用的位置。同样,对于 null 也是相同的情况。
我们可以通过类型运算符来组合基本类型,从而得到负责的类型表达式,本质上来说就是取并集和交集。
接下来几块就要讲解下 TypeScript 提供的一些类型运算符。
8. 数组类型
- 列表:拥有相同类型元素,数组长度可变;
- 元组:数组长度固定,元素并不必须拥有相同类型。
8.1 list
有两种方式来表示一个拥有数组类型元素的列表:
let arr: number[] = [];let arr: Array<number> = [];
一般来说,如果有赋值的话,TypeScript 是可以推断出变量的类型的。不过在上述场景中,我们必须得指定,因为从空数组中是无法进行推断的。
晚些我们会断尖括号进行阐述。
8.2 tuple
如果我们要在数组中存储二维点,那么我们就要以元组的方式使用数组。
let point: [number, number] = [8, 3];
在这种情况下,我们其实可以不写类型注解。
另一个例子是 Object.entries(obj) 的返回结果:obj 的每个属性都会返回一个 [key, value]:
> Object.entries({ a: 1, b: 2 })[ ['a', 1], ['b', 2] ]
那么 Object.entries() 返回值的类型其实就是:
Array<[string, any]>
9. 函数类型
函数类型的例子如下:
(num: nubmer) => string
含义不过多描述,如果我们想实际声明一个类型注解,可以如下(这里 String 表示一个函数):
const func: (num: number) => string = String;
当然这里 TypeScript 是知道 String 类型的,因此可以推测出 func 的类型。
下面的代码可能更实际一些:
function stringify123(callback: (num: nubmer) => string) {return callback(123);}
我们用一个函数类型来描述 stringify123 的参数 callback 的类型。因为这样进行了注解,下面的写法就会报错:
f(Number)
但是这个就可以:
f(String);
9.1 函数声明的返回类型
一个好的实践是函数的所有参数都加上注解,当然也可以指定返回类型(TypeScript 还是相当擅长推断的):
function stringify123(callback: (num: number) => string): string {const num = 123;return callback(num);}
特定返回类型 void
void 是一种特殊的返回类型:它可以告诉 TypeScript 函数总是返回 undefined(无论显示或隐式):
function f1(): void { return undefined } // OKfunction f2(): void { } // OKfunction f3(): void { return 'abc' } // error
9.2 可选参数
标识符后的问号意味着参数是可选的:
function stringify123(callback?: (num: number) => string) {const num = 123;if (callback) {return callback(num); // (A)}return String(num);}
如果在 —strict 模式下运行 TypeScript,如果提前做了检查,它将只允许你在 A 行执行。
参数默认值
TypeScript 支持 ES6 默认值写法:
function createPoint(x=0, y=0) {return [x, y];}
默认值会使得参数变得可选。我们通常会忽略类型注解,因为 TypeScript 可以推测出类型。例如,它可以推测出 x 和 y 都拥有数字类型。
如果我们想要添加类型注解,可以这么写:
function createPoint(x:number = 0, y:number = 0) {return [x, y];}
9.3 rest 展开类型
还可以在 TypeScript 参数定义的时候使用 ES6 展开运算符。对应参数的类型必须是数组:
function joinNumbers(...nums: number[]): string {return nums.join('-');}joinNumbers(1, 2, 3); // '1-2-3'
10. 联合类型
在 JavaScript 中,变量有时可能有几种类型。为了描述这类变量,我们使用联合类型。例如,在下面代码中,x 可以为 null 或者数字类型:
let x = null;x = 123;
这种情况下,x 的类型就可以描述如下:
let x:null|number = null;x = 123;
类型表达式 s|t 就是用集合论中的联合符号来表达这一运算的含义的。
现在我们来重写下上面的 stringify123():这次我们不希望参数 callback 是可选的,而是明确定义的。如果调用者不想传入函数,也要显式传入一个 null。实现如下:
function stringify123(callback: null | ((num: number) => string)) {const num = 123;if (callback) { // (A)return callback(123); // (B)}return String(num);}
仍然要注意的是,我们需要检查 callback 是否实际上是函数(如 A 行所示),然后我们才可以调用 callback(如 B 行)。如果不进行检查,TypeScript 会报错。
10.1 Optional vs. undefined|T
类型 T 的可选参数和类型 undefined|T 相当相似。
主要的区别在于,我们可以忽略可选参数:
function f1(x?: number) { }f1(); // OKf1(undefined); // OKf1(123); // OK
但不可以忽略类型为 undefined|T 的参数:
function f2(x: undefined | number) { }f2(); // errorf2(undefined); // OKf2(123); // OK
10.2 值 null 和 undefined 通常并不是类型
在许多编程语言中,null 是一种类型。例如,如果 Java 中的参数类型是 String,你仍可以传入 null 而 Java 并不会报错。
与之相对的,TypeScript 中,undefined 和 null 是分开处理的。如果想做到上述效果,就需要指定 undefined|string 或 null|string,这两者是不同的。
11. 类型对象(接口)
和数组相似,对象扮演着两种角色(有时候会有所混合或者更加动态):
- 记录:在开发阶段可以存储定量的已知属性,每种属性都可以有不同类型。
- 字典:在开发阶段存放的未知键值的属性,每个属性键(字符串或符号)及值都有相同的类型。
我们会忽略字典的用法,事实上,Maps 类型是个更合适的选择。
11.1 通过接口指定作为记录的对象的类型
接口可以描述作为记录使用的对象:
interface Point {x: number;y: number;}
TypeScript 类型系统的一个优势是,它可以按结构工作,而不是按名义:
function pointToString(p: Point) {return `(${p.x},${p.y})`;}pointToString({x: 5, y: 7}); // '(5, 7)'
与之相对的是,Java 的名义类型系统需要类来 implement 接口。
11.2 可选属性
如果属性可以被忽略,同样用问号即可:
interface Person {name: string;company?: string;}
11.3 方法
接口可以包含函数方法:
interface Point {x: number;y: number;distance(other: Point): number;}
12. 类型变量 & 通用类型
(其实下面这段我都看不懂什么意思,如果我理解的没错,尖括号其实就是模板的概念。)
有了静态类型,我们就有了两种层级:
- 值处于对象层级
- 类型处于元层级
一般的变量可以通过 const、let 等定义,类型变量则通过上文提到的尖括号(<>)。例如,下面的代码包含了类型变量 T:
interface Stack<T> {push(x: T): void;pop(): T;}
我们可以看到,类型参数 T 在 Stack 定义体中出现了两次。因此,这个接口就可以这么理解:
- Stack 是一种栈类型,其元素都是类型 T,我们需要在使用 Stack 的时候指定 T;
- push 方法接受一个类型 T 的值;
- pop 方法会返回类型 T 的值。
如果我们使用 Stack,我们必须赋「类型」给 T,接下来的代码展示了一个傻乎乎的栈:
const dummyStack: Stack<number> = {push(x: number) {},pop() { return 123 },};
12.1 例子:Maps
如下是 Map 类型的使用方法:
const myMap: Map<boolean, string> = new Map([[false, 'no'],[true, 'yes'],]);
12.2 函数的类型变量
函数也可以使用类型变量:
function id<T>(x: T): T {return x;}
这样的话,函数就可以这么用了:
id<number>(123);
因为可以做类型推断,所以代码也可以忽略类型参数:
id(123);
12.3 传递类型参数
函数可以传递参数给接口、类等等:
function fillArray<T>(len: number, elem: T) {return new Array<T>(len).fill(elem);}
类型 T 出现了 3 次:
- fillArray
:引入类型变量 - elem: T:使用从参数得到的类型变量
- Array
:传递 T 到数组构造函数
13. 总结
现在我们回过头去看最初的那段代码:
interface Array<T> {concat(...items: Array<T[] | T>): T[];reduce<U>(callback: (state: U, element: T, index: number, array: T[]) => U,firstState?: U): U;···}
代码定义了一个数组的接口,元素类型为 T:
- concat 方法有一个或多个参数(通过展开运算符定义),每个参数都拥有类型 T[]|T,也就是说每个元素都可能是 T 的数组或一个 T 类型的值。
- reduce 方法引入了类型变量 U。U 表示后续的 U 类型都有一样的类型:
Back/forward cache for Chrome
Chrome 团队正在研发一种新的回退、前进缓存技术,当用户导到其他页面时,将页面缓存在内存中(维护 JavaScript 和 DOM 的状态)。这项技术还是相当牛的,可以明显加快浏览器回退、前进导航的速度。
当导航离开一个页面的时候,回退/前进缓存(后文缩写为 bfcahce)会缓存整个(包括 JavaScript 的堆),这样当用户导航回来的时候,就可以恢复整个页面的状态,这就有点像暂停了一个页面然后离开,过了一会又回来了我们继续「播放」这个页面一样舒爽。
下面的视频是在笔记本上跑的 bfcache 早期原型效果,可以看到右侧运用了 bfcache 的效果非常炫(建议直接拖到中间看):
如果是上传到外网然后不可见的话,也可以考虑点这个油管链接。
下面的则是在安卓机 Chrome 上的效果:
如果是上传到外网然后不可见的话,也可以考虑点这个油管链接。
这项技术估计可以为移动端 Chrome 的导航提升 19% 的性能。
一些细节可参考这里:
- 调整 Chrome 的导航栈来创建新的帧,而不是复用原有的部分;
- 修改 Blink 的代码来保证在页面进入 bfcache 的时候,所有页面相关的任务都会被冻结;
- 根据资源和隐私限制,这缓存可缓存的页面。
源地址:https://developers.google.com/web/updates/2019/02/back-forward-cache
ES 新提案:Promise.any(promises)
Promise.any 的提案目前处于 stage-0,例子如下:
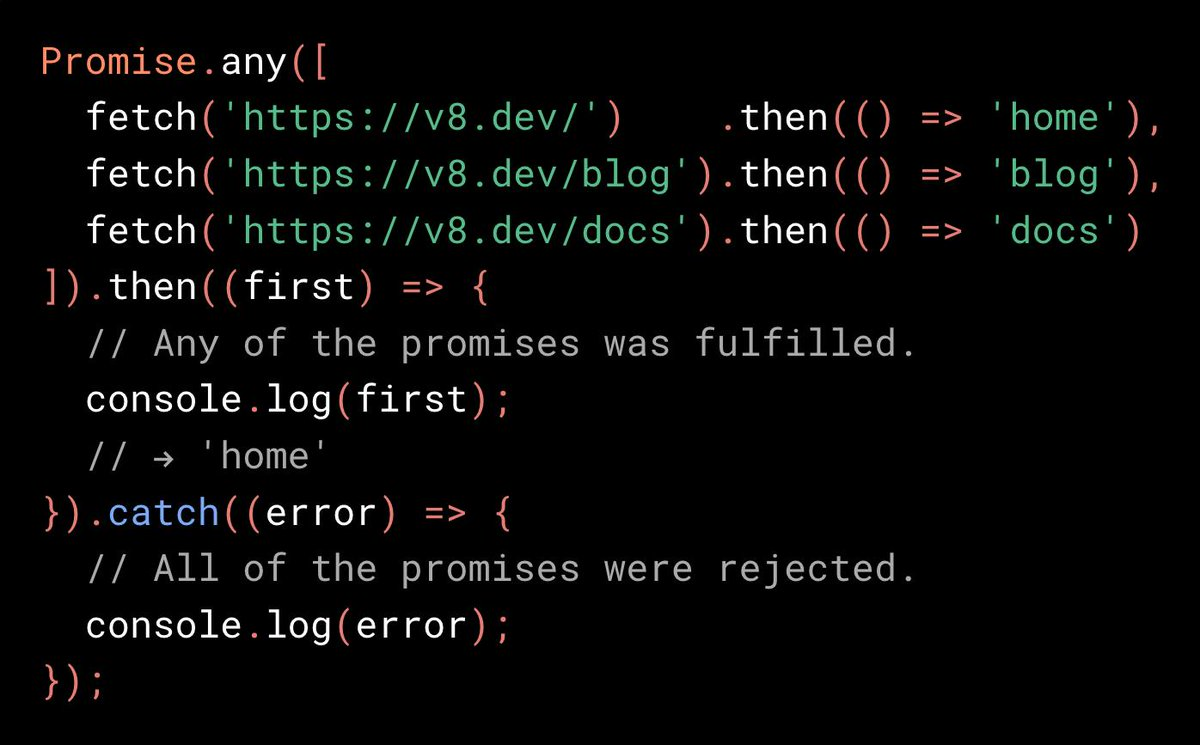
Promise.any 会在任一 promise 完成之后返回相应的值,这是在 Promise.allSettled、Promise.all 和 Promise.race 之后的又一 Promise 相关的能力。
那么这几个东西有什么区别呢?

问题来了,settled 和 fulfilled 之间有什么区别呢?在推特的评论中有这么一句解释:
Settled means fulfilled or rejected, not pending. Fulfilled means it resolved, not rejected.
也就是说,settled 意味着确定的结果,与 pending 相对,可能是 fullfilled 或者是 rejected;而 fulfilled 与 rejected 相对,意味着 resolved。
所以在上面表中,就可以明白 Promise.race 和 Promise.any 的区别了:
Promise.race will reject if any of the promises reject.
即,如果任一一个 promise 被 reject 了,那么 Promise.race 就会 reject,而 Promise.all 并不会,这就是 settled 和 fulfilled 的区别。
最后复习下 MDN 上关于 Promise 的图:
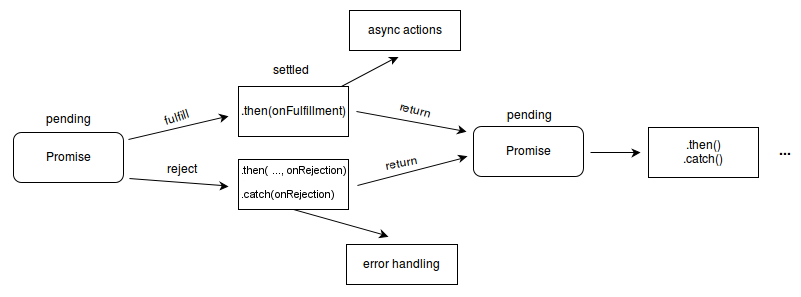
源地址:https://github.com/tc39/proposal-promise-any
为什么这个函数不能 new
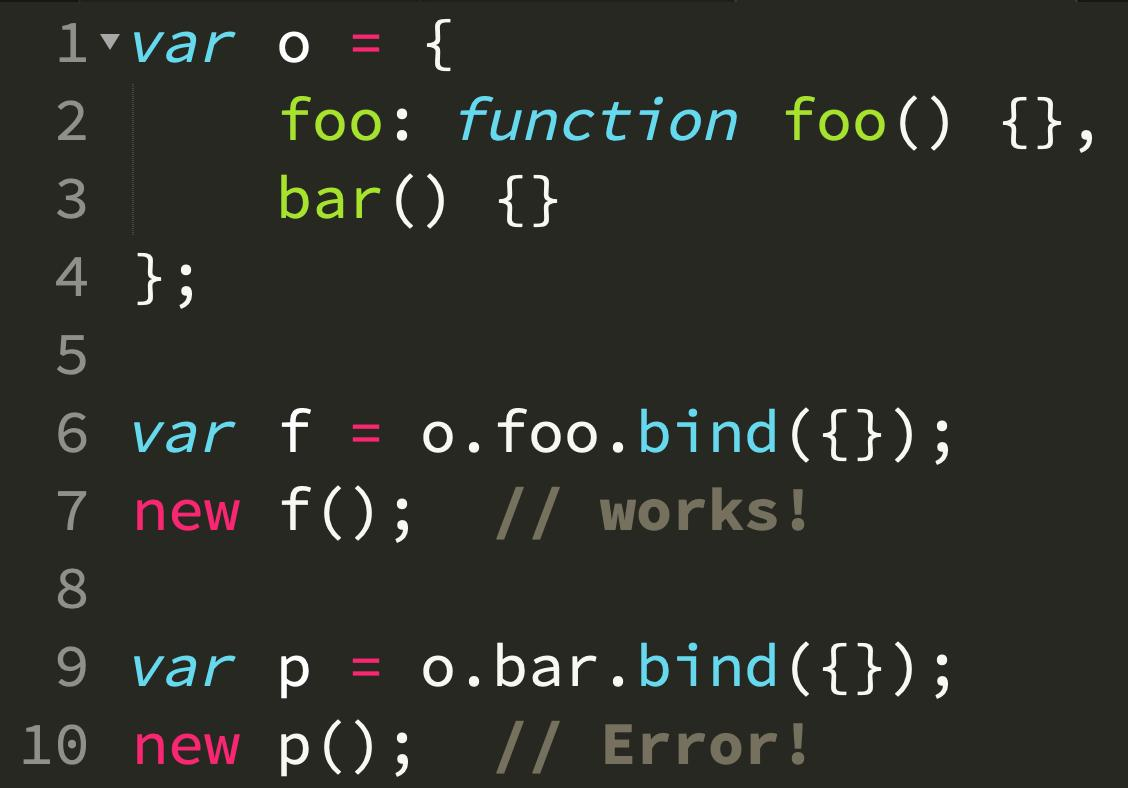
本篇讨论的就是上面图中的问题:为什么 foo 可以用 new 初始化,而 bar 不行呢?
method syntax
这事可以从 ES2015 的一个缩写语法说起。ES2015 增加了一种在对象初始化时在其中定义方法的缩写语法:
var obj = {foo() {return 'bar';}}console.log(obj.foo());// expected output: "bar"
当然,可定义的方法类型很多,除了普通的函数方法,也可以挂上 generator、async 方法、计算属性等:
var obj = {property( parameters… ) {},*generator( parameters… ) {},async property( parameters… ) {},async* generator( parameters… ) {},// with computed keys:[property]( parameters… ) {},*[generator]( parameters… ) {},async [property]( parameters… ) {},// compare getter/setter syntax:get property() {},set property(value) {}};
那么回想下最开始的例子,如果我们有如下定义:
var obj = {foo: function() {/* code */},bar: function() {/* code */}};
我们就可以缩写成这种方式:
var obj = {foo() {/* code */},bar() {/* code */}};
也就是说,bar 其实就是 foo 的缩写,怎么还整出区别了呢?
研究一下
MDN 文档上有这么一段:
var obj = {method() {}};new obj.method; // TypeError: obj.method is not a constructorvar obj = {* g() {}};new obj.g; // TypeError: obj.g is not a constructor (changed in ES2016)
具体为什么,不妨在浏览器中试验一下,可以得到如下结果:

从这张图中其实可以看到,不同定义方式对 foo() 和 bar() 的结果产生了影响:foo() 本身是 callable 的,在它的原型 prototype 上有 constructor;bar() 并不是 callable 的,它并没有原型 prototype 而只有 proto。
感觉还是有些理不清呀,这里祭出一张珍藏多年的图,我们对照着看:
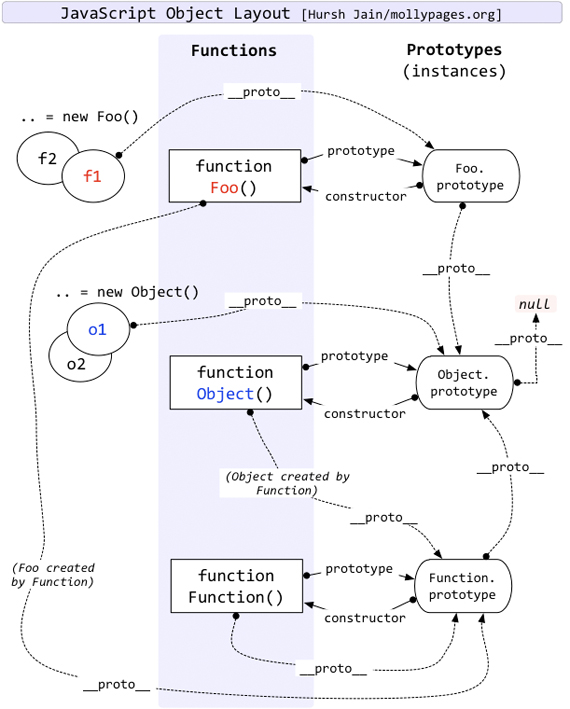
先说 foo(),作为一个函数,它的 prototype 就是 foo.prototype,而 foo.prototype 上也确实有 constructor,而 foo.prototype.constructor 正是 foo 本身,使用 new 来调用没有问题。此外,foo.prototype 上有 proto,它正是 Object.prototype,而它的 constructor 就是 Object 函数。
再说 bar(),它没有 prototype,而这正是行为差异的所在。它只有 proto,指向 Function.prototype,而 Function.prototype 的 constructor 正是 ƒ Function()。
哈哈是不是捋清楚了一点。
整理
ES2015 对函数的两种类型进行了区分:
- callable functions:不使用 new 的函数,如 foo();
- constructable functions:使用 new 的函数,如 bar();
函数定义的方式决定了一个函数是 callable 的还是 constructable 的。标准中已经说明了通过方法语法定义的函数不是 constructable 的。
具体划分如下:
- Constructable functions(要 new 的函数):
- Classes
- Callable functions(不 new 的函数):
- Arrow functions
- Object/class methods (via method syntax)
- Generator functions
- Async functions
- 用不用 new 都行:
- Function declarations/expressions
函数组件和类组件的根本差异
我们肯定看过很多形式上的差异,比如同样的效果按函数方式和类的方式去实现会有什么样的区别:
看上去,二者也只是在实现时存在些写法的差异,再不然我们可能会有一些「很权威」的结论,比如类组件能有更多的特性(如状态)。但是因为有了 hooks,这些差异都不再是真正的差异了。
Dan 总结了差异的真正所在:
Function components capture the rendered values.
不过我们不着急,先往下看。
以一个例子开始
那么真正的差异究竟是什么呢?我们看一个下面的例子:
具体源码是这样的:
// index.jsimport React from "react";import ReactDOM from "react-dom";import ProfilePageFunction from './ProfilePageFunction';import ProfilePageClass from './ProfilePageClass';class App extends React.Component {state = {user: 'Dan',};render() {return (<><label><b>Choose profile to view: </b><selectvalue={this.state.user}onChange={e => this.setState({ user: e.target.value })}><option value="Dan">Dan</option><option value="Sophie">Sophie</option><option value="Sunil">Sunil</option></select></label><h1>Welcome to {this.state.user}’s profile!</h1><p><ProfilePageFunction user={this.state.user} /><b> (function)</b></p><p><ProfilePageClass user={this.state.user} /><b> (class)</b></p><p>Can you spot the difference in the behavior?</p></>)}}const rootElement = document.getElementById("root");ReactDOM.render(<App />, rootElement);
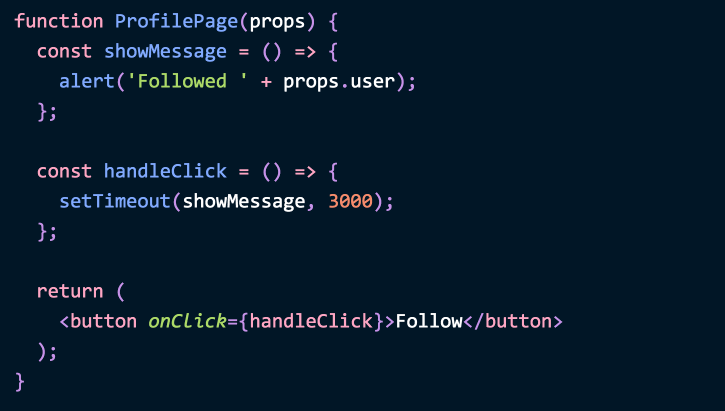
// ProfilePageClass.jsimport React from 'react';class ProfilePage extends React.Component {showMessage = () => {alert('Followed ' + this.props.user);};handleClick = () => {setTimeout(this.showMessage, 3000);};render() {return <button onClick={this.handleClick}>Follow</button>;}}export default ProfilePage;
// ProfilePageFunction.jsimport React from 'react';function ProfilePage(props) {const showMessage = () => {alert('Followed ' + props.user);};const handleClick = () => {setTimeout(showMessage, 3000);};return (<button onClick={handleClick}>Follow</button>);}export default ProfilePage;
handleClick 就是模拟了一个异步请求的操作,代码中其实就是用函数和类分别实现了这样的功能。
然后操作如下:
- 点击其中一个 Follow;
- 在 3 秒钟过去前修改选中的 profile;
- 读取 alert 文案;
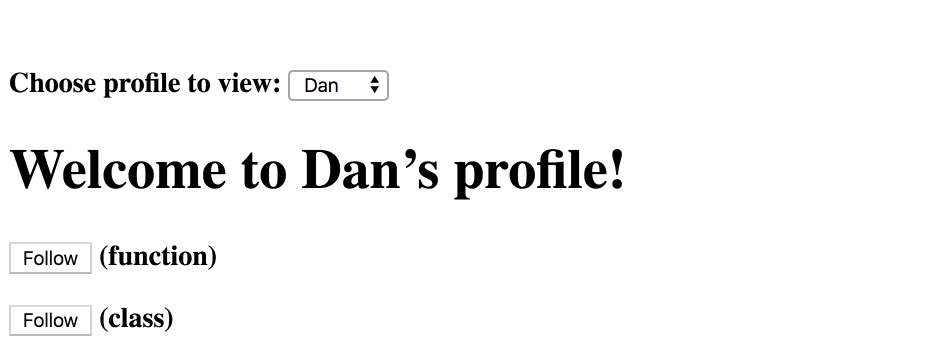
然后我们就会发现二者的区别:
- 使用 ProfilePage 函数实现的方法,在 Dan 那里点击完 Follow 然后切换到 Sophie 仍会弹出 ‘Followed Dan’.
- 使用 ProfilePage 类实现的方法,则会弹出 ‘Followed Sophie’:
很显然,前者才是正确的,或者说,在函数式实现中,this.props.user 才是我们想要的。
分析
我们再来看看 class 实现的的代码到底是怎样的:
class ProfilePage extends React.Component {showMessage = () => {alert('Followed ' + this.props.user);};
This class method reads from this.props.user. Props are immutable in React so they can never change. However, this is, and has always been, mutable.
类方法读取了 this.props.user。在 React 中,Props 是 immutable 的,因此它们并不会发生改变。但是,this 永远是 mutable 的。
事实上,这就是 class 中的 this 的全部目的。React 会不断地改变 this,从而在 render 和生命周期方法中总能得到新版本的组件。
所以,如果我们的组件在请求过程中发生了重新渲染,this.props 也会改变。也就是说,showMessage 读取到了「太新」 的 props。
这也是对交互界面的本质的一个有趣的观察视角。如果说 UI 本质上是当前应用状态的函数,那 event handler 就是渲染结果的一部分。我们的 handler是「从属于」特定的 render,对应着特定的 props 和 state。
但是呢,读取 this.props 的 setTimeout 中的回调方法破坏了这一联系。showMessage 并没有和特定的 render 联系在一起,并且没有拿到争取的 props。
那么究竟应该怎么做呢? 无论什么方法什么前端库,其实都会导致上面所说的问题。如果没有 hooks,而我们又想拿到正确的值,解决问题的关键在于闭包。
尽管很多时候我们会避免闭包行为,但是在 React 中,props 和 state 是 immutable 的,而这就避免了闭包可能带来的不好的影响。如果我们针对特定 render 闭包 props 和 state,我们就总能将它们的关系一一对应起来。
class ProfilePage extends React.Component {render() {// Capture the props!const props = this.props;// Note: we are *inside render*.// These aren't class methods.const showMessage = () => {alert('Followed ' + props.user);};const handleClick = () => {setTimeout(showMessage, 3000);};return <button onClick={handleClick}>Follow</button>;}}
这样,我们就总能将 props 与 render 对应起来,不再出现上面展示的那种 bug。
但是还不够,上面的写法未免太扯了。我们不妨包上一层:
function ProfilePage({ user }) {const showMessage = () => {alert('Followed ' + user);};const handleClick = () => {setTimeout(showMessage, 3000);};return (<button onClick={handleClick}>Follow</button>);}
这一次,我们就能得到正确的结果了。
因此,Dan 针对这一差异做了总结:
Function components capture the rendered values.
而毫无疑问的,Hooks 解决了这一问题。事实上在文档中,反复提及了所谓的「副作用是 render 结果的一部分」这样的理念。
源地址:https://overreacted.io/how-are-function-components-different-from-classes/
Preact X Alpha 0 released
Preact X 是下一个 major release,旨在提供一些迫切需要的特性如 Fragments、componentDidCatch、createContext、hooks,以及其他一些和三方库之间兼容性问题的改进。
Fragments✅
与 React 中的 React.Fragments 类似,Preact 终于也支持了这种写法。当然,在 React 中,我们还可以使用 <><\/> 来进一步简化代码。
此外,Preact 还可以将组件以数组的方式返回:
function Columns() {return [<td>Hello</td><td>World</td>];}
componentDidCatch✅
componentDidCatch 是 React 16 中的新的生命周期方法,在之前的一期中更新过。当一个 class 内定义了这个生命周期方法,这个组件就变成了一个 error boundary。
现在在 Preact X 中终于也提供了,我们可以用它来捕获 render 或其他生命中其方法中的错误。有了它,就可以展示更友好的错误信息,或者向外部服务发送 log 信息。
class Foo extends Component {state = { error: false };componentDidCatch(err) {logErrorToBackend(err);this.setState({ error: true });}render() {// If an error happens somewhere down the tree// we display a nice error message.if (this.state.error) {return <div class="error">Something went wrong...</div>;}return <Bar />;}}
Hooks
紧跟着 React 16.8 的脚步,Preact 也开始支持 Hooks 了。React 的 Hooks 文档真的很不错,无论如何都推荐认真读一读,对 UI 的理解可能会有些不同。
Preact 引入 hooks 是按需引入的,当我们使用打包工具打包时,没用到的 hooks 就不会打包到 App 中:
import { h, render } from 'preact';import { useState } from 'preact/hooks';function Counter() {const [count, setCount] = useState(0);// ^ default state valuereturn (<div class="counter">Current count: {count}<button onClick={() => setCount(count + 1}}> +1 </button><button onClick={() => setCount(count - 1}}> -1 </button></div>);}render(<Counter />, document.body);
createContext✅
现在 React 16.4 中的特性也支持了,通过它可以做一些 pub/sub 模式的工作。不过老实说,我不是很喜欢这种方式。但总的来说,Preact X 确实支持了很多 React 已有的实用特性。
import { createContext } from "preact";const Theme = createContext("red");function Button() {return <Theme.Consumer>{value => <button style={{ color: value }}>click</button>}</Theme.Consumer>;}function App() {return <Theme.Provider value="blue"><Button /></Theme.Provider>;}
可以看出,基本是完全一样的写法。
setState 异步
在 Preact 之前的版本中,setState 是同步执行的。这让我想到了小程序中的 setData 也是同步的,终于 Preact 也走向了异步更新的道路,只是不知道内部是不是 batchUpdate 的思路。
总的来说,Preact 似乎仍然是以更轻量的 React 来定位自己,在某些对包体积非常敏感的场景,随着 Preact 的发展,其地位应该会越来越高吧。
源地址:https://github.com/developit/preact/releases/tag/10.0.0-alpha.0
Chromium Edge 截图透出
去年年底,微软表示其计划在 Chromium 上重建 Edge 浏览器。该软件巨头一直在测试新版浏览器的日常开发版本,现在透出的一些截图展示了微软的进展。虽然微软当前版本的 Edge 拥有自己独特的 UI,但基于 Chromium 的 Edge 版本看起来很像 Chrome。
Neowin 发布了许多 Chromium Edge 主要界面、功能的截图和一些可用的设置。这个新浏览器显然处于早期阶段,微软似乎正在测试扩展支持、同步和一种包括当天和大多数访问过的网站的图像的新标签视图。现在的版本支持现有的 Edge 扩展,Microsoft 也应该会支持 Chrome 自己的 web 扩展。
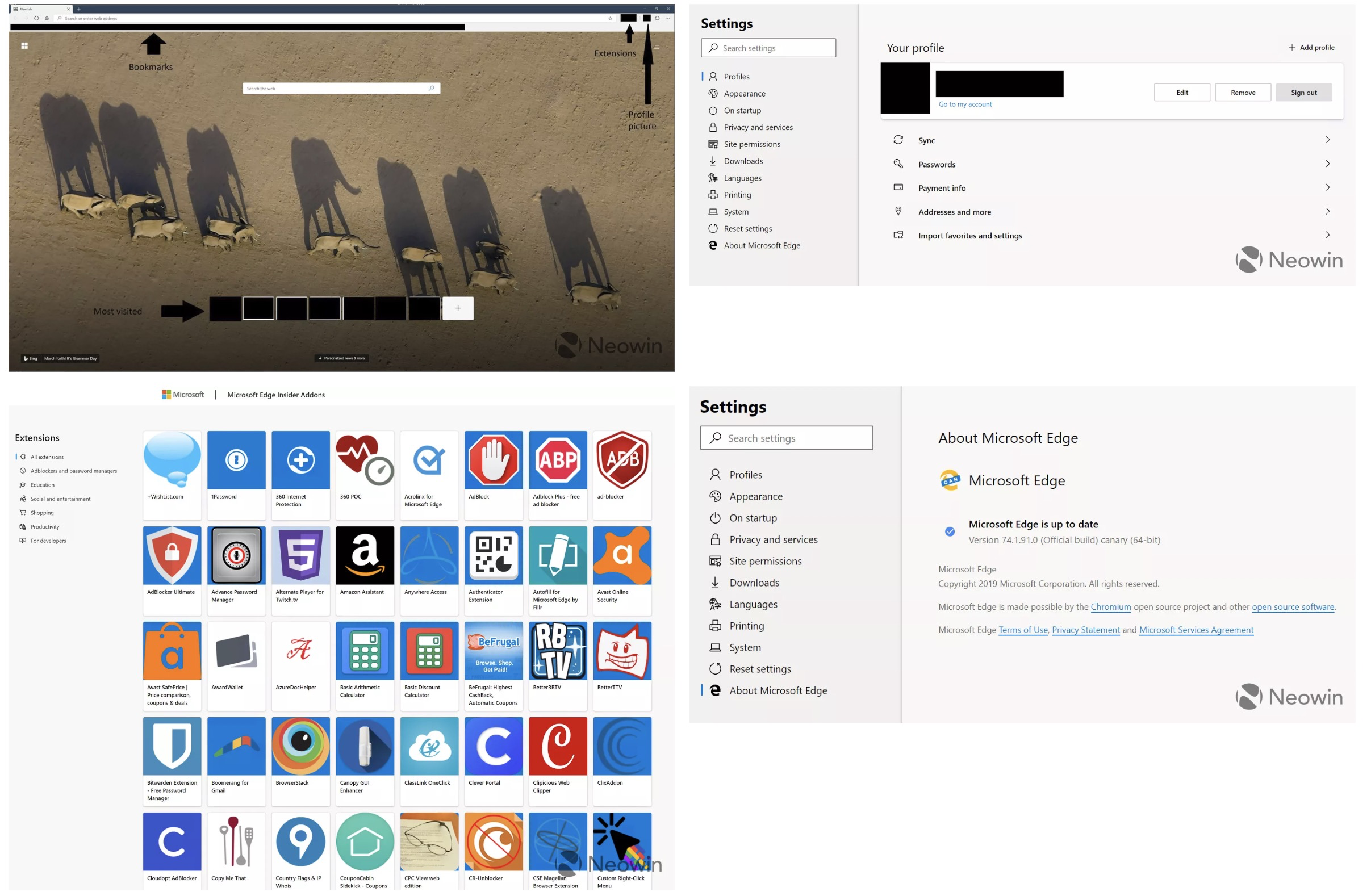
浏览器界面本身包含与 Chrome 相同的刷新、主页和导航按钮。地址栏上甚至还有收藏夹和个人资料图片。这是因为微软的工作建立在 Chromium 的核心之上,但由于这些是非常早期的版本,我们可能还没有看到任何界面变化。
目前还不清楚微软计划何时公开测试其 Chromium 版本的 Edge。 Microsoft 员工可以使用日常构建版本,并且很快就会对浏览器进行更广泛的测试。如果有兴趣在可用之后对其进行测试,可以注册来参与到 Microsoft 的 Edge Insider 计划,在微软准备公测后收到通知。
源地址:https://www.theverge.com/2019/3/5/18251263/microsoft-edge-chromium-screenshots-leak-browser
React 函数组件的 TypeScript 写法
今天来看下引入 TS 之后,Hooks 方面的代码怎么写。嗯,Hooks 的东西写太多了。
Functional Component with TypeScript
因为过去函数式组件是没有状态的,被称为 Stateless Function Components,因此过去我们在定义函数式组件的时候使用的是 React.SFC。现在因为有了 Hooks 的引入,函数式组件同样有了状态,可以使用到生命周期的能力,因此调整成 React.FC。
import * as React from 'react'interface IProps {// ... props interface}// NEW syntax for typing function componentsconst MyNewComponent: React.FC<IProps> = (props) => {...};// OLD syntax for typing function componentsconst MyOldComponent: React.SFC<IProps> = (props) => {...};
传入属性的定义在 FunctionComponent:
interface FunctionComponent<P = {}> {(props: P & { children?: ReactNode }, context?: any): ReactElement | null;propTypes?: WeakValidationMap<P>;contextTypes?: ValidationMap<any>;defaultProps?: Partial<P>;displayName?: string;}
注意:React 团队正在考虑移除函数组件的 defaultProps。事实上这一点在自己开发的过程中也有体会,因为函数的默认参数已经能够满足需求,引入 defaultProps 纯属增加复杂度。
useState with TypeScript
毕竟函数组件有了 Hooks,所以本文可能要讲述下这块的写法和变化。使用 useState 并没有什么特别需要修改的地方,我们看下下面的例子:
import * as React from 'react';const MyComponent: React.FC = () => {const [count, setCount] = React.useState(0);return (<div onClick={() => setCount(count + 1)}>{count}</div>);};
对于简单的函数来说,useState 可以从初始值推断出类型并且基于函数使用的值来返回结果。对于复杂的状态,我们可以通过泛型 useState
import * as React from 'react';interface IUser {username: string;email: string;password: string;}const ComplexState = ({ initialUserData }) => {const [user, setUser] = React.userState<IUser | null>(initialUserDate);if (!user) {// do something else when our user is null}return (<form><input value={user.username} onChange={e => setUser({...user, username: e.target.value})} /><input value={user.email} onChange={e => setUser({...user, email: e.target.value})} /><input value={user.password} onChange={e => setUser({...user, password: e.target.value})} /></form>);}view raw
可以看出,主要是利用接口来定义了复杂状态的类型,同时使用的联合类型保证了它可以为 null。
官方定义的类型如下:
function useState<S>(initialState: S | (() => S)): [S, Dispatch<SetStateAction<S>>];type Dispatch<A> = (value: A) => void;type SetStateAction<S> = S | ((prevState: S) => S);
useEffect with TypeScript
在使用 useEffect 的时候,并不会有什么需要注意的类型定义,毕竟 useEffect 本身就是传入一个回调函数和触发副作用的 trigger。我们可以直接看一下官方定义:
function useEffect(effect: EffectCallback, deps?: DependencyList): void;// The first argument, `effect`type EffectCallback = () => (void | (() => void | undefined));// The second argument, `deps?`type DependencyList = ReadonlyArray<any>;
可以看出,第一个参数是一个函数类型,函数可以返回空或者指定一个回调,也就是一个 cleanup 函数;第二个参数是可选的依赖列表,其类型是只读的、元素为任意类型的列表。
useReducer with TypeScript
useReducer 也是常用的一个 hooks,它的使用则相对复杂一些(其实也不复杂):
import * as React from 'react';enum ActionType {Increment = 'increment',Decrement = 'decrement',}interface IState {count: number;}interface IAction {type: ActionType;payload: {count: number;};}const initialState: IState = {count: 0};const reducer: React.Reducer<IState, IAction> = (state, action) => {switch (action.type) {case ActionType.Increment:return {count: state.count + action.payload.count};case ActionType.Decrement:return {count: state.count - action.payload.count};default:throw new Error();}}const ComplexState = () => {const [state, dispatch] = React.useReducer<React.Reducer<IState, IAction>, IState>(reducer, initialState);return (<div><div>Count: {state.count}</div><button onClick={() => dispatch({type: ActionType.Increment, payload: { count: 1 } })}>+</button><button onClick={() => dispatch({type: ActionType.Decrement, payload: { count: 1 }})}>-</button></div>);
可以看到,action 本身被定义成枚举类型,这其实与我们将类型分别定义成常量并 export 没什么区别;同时,初始状态被定义成 IState 类型,而 action 则被定义成 IAction 类型,而 reducer 内部的实现,与普通 redux 写法并无不同。
其他 hooks 因为不常使用,就不再赘叙。
用 Jest 和 Enzyme 写测试
Jest 是一个单元测试框架,由脸书团队制作;Enzyme 则是用于测试组件的框架,可以写断言来证明 UI 能够正确的工作(寻找组件并交互,如有问题则给出错误标识)。这两者是独立的工具,但二者相互补充。
因为笔者尚未对测试方面有什么了解,因此本文很简单,就是用 cra 跑个项目来对这两个工具有个体感。
cra 已经包括了 Jest,我们只需要再额外安装 enzyme 和 enzyme-adapter-react-16:
yarn add enzyme enzyme-adapter-react-16 --dev
创建一个设置文件,并将其放置到 src 目录下:
// setupTests.jsimport { configure } from 'enzyme';import Adapter from 'enzyme-adapter-react-16';configure({ adapter: new Adapter() });
这样就引入了 Enzyme 并配置了运行测试用的适配器。
测试快照
「快照测试」是为了跟踪应用 UI 的变化。快照非常有用,因为可以捕获一个组件在某一时刻的代码,从而让我们在组件的不同状态下对组件进行比较。
第一次运行时,组件代码的快照就会生成并保存在 src 目录下的 snapshots。后面只要运行测试,当前的 UI 就会与已经存在的版本进行比较。下面是一个例子:
it("renders correctly", () => {const wrapper = shallow(<App />);exprect(wrapper).toMatchSnapshot();});
然后执行 yarn run test 即可。
每次生成的新的快照都会保存在 tests 目录下。
如果我们修改了 UI 层的内容,例如将 h2 标签的内容进行了修改,就会得到如下内容:
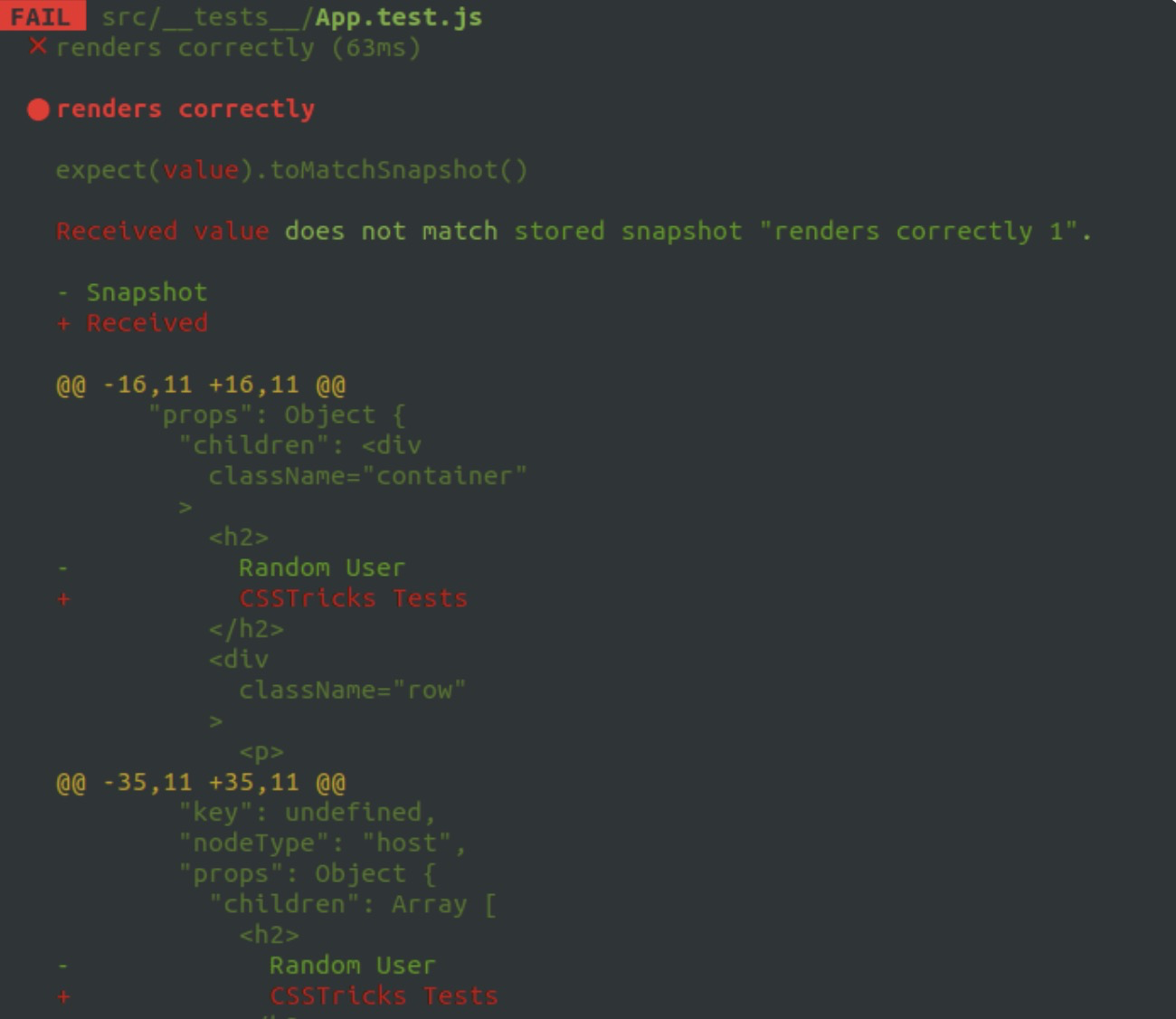
但或许我们是故意这么修改的,那么为了通过我们的测试,我们可以讲标签内容改为之前的内容,也可以更新我们的快找文件。Jest 提供了关于更新快照的知道信息,这样我们就不比人更去更新快照了:
Inspect your code changes or press `u` to update them.
有个细节是 shallow 方法,这是 Enzyme 包内高速测试只在一个单一组件上进行,即使子组件也不进行测试。将代码进行拆分有助于调试,尤其对于简单的没有交互的组件。
与之相反的是 render 方法,它将包含子组件的信息。
总结:快照类的测试可以较好地比较 UI,对于变化不频繁的共用组件、页面还是很好用的。
测试组件的生命周期
虽然按目前的习惯已经是基本不用 class 了,所以也不存在使用生命周期的场景了,但还是来看看。
生命周期本身也是 React 过去提供的钩子,我们常常在组件的挂在阶段进行一些 data fetching 的工作。我们可以利用 Jest 来测试生命周期方法是否被调用,从而让我们可以模拟 React 应用的生命周期方法。
it('calls componentDidMount', () => {jest.spyOn(App.prototype, 'componentDidMount')const wrapper = shallow(<App />)expect(App.prototype.componentDidMount.mock.calls.length).toBe(1)})
上面的方法就是监控 componentDidMount() 并断言该方法被调用了一次。
暂时没看明白这个有什么特别的用处。
测试组件的属性
这个还是很重要的,尤其是项目中有大量按照贫血模型实现而出现的受控组件。使用 Enzyme 的 API 可以让我们来模拟传入的属性。
假设我们讲过App 组件中的用户信息传入 Profile 组件,那么我们 mock 一下传入的属性:
const user = {name: 'hydraz320',email: 'gezhen_auto@163.com',username: 'hydraz',image: null}
我们使用 describe 来包裹需要测试的组件,如下例子:
describe ('<Profile />', () => {it ('contains h4', () => {const wrapper = mount(<Profile user={user} />)const value = wrapper.find('h4').text()expect(value).toEqual('John Doe')})it ('accepts user props', () => {const wrapper = mount(<Profile user={user} />);expect(wrapper.props().user).toEqual(user)})})
这里包含了两部分测试。首先我们向挂载的 Profile 组件传入属性,然后我们检查是否能在其中找到 Profile 组件中本该包含的 h4 元素。然后,我们检查了传入的属性是不是与我们创建的 mock 属性相等。注意,即使我们在 Profile 组件内部通过结构的方式处理属性,也不会影响测试结果。
模拟 API 调用
测试 API 的一个注意点在于我们并不是真的想去请求 API。有些 API 的调用次数有限,甚至可能要花钱,因此我们需要避免真的去做请求来测试。我们可以使用 Jest 来 mock axios 请求。
首先我们会创建一个新的 mock 目录,这里放置我们想要执行的 mock request:
module.exports = {get: jest.fn(() => {return Promise.resolve({data: [{id: 1,name: 'Jane Doe',email: 'janedoe@gmail.com',username: 'jdoe'}]})})}
我们想要测试是否发出了 GET 请求,因此我们通过如下语句:
import axios from 'axios';// ...jest.mock('axios')
Jest 有个方法是 spyOn(),它有个 accessType 参数可用于检测我们是否「get」到了 API 调用的返回结果。
it('fetches a list of users', () => {const getSpy = jest.spyOn(axios, 'get')const wrapper = shallow(<App />)expect(getSpy).toBeCalled()})
整体来看,仅就目前而言,前端方面的测试并不是一个已经解决的问题,还有很多的探索值得去做。
源地址:https://css-tricks.com/writing-tests-for-react-applications-using-jest-and-enzyme/

若有收获,就点个赞吧
0 人点赞
