Mapping(文档映射)
ES的文档映射(mapping)机制用于进行字段类型确认(字段是什么类型,什么分词器),将每个字段匹配为一种确定的数据类型。类似于数据库的表结构定义,主要作用如下:
- 定义Index下的字段名(Field Name)
- 定义字段的类型,比如数值型、字符串型、布尔型等
- 定义倒排索引相关配置,比如是否索引、记录position等
查看某个Index的Mapping
GET woniu47/_mapping
自定义Mapping
创建一个Index的映射
PUT woniu48
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"desc": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
Mapping中的字段类型一旦设定后,禁止直接修改,因为Lucene实现的倒排索引生成后不允许修改
通过dynamic参数来控制字段的新增
- true(默认)允许自动新增字段
- false 不允许自动新增字段,但是文档可以正常写入,但无法对字段进行查询等操作
strict 文档不能写入,报错
PUT woniu48 { "mappings": { "dynamic": "false", "properties": { "name": { "type": "keyword" }, "age": { "type": "integer" }, "desc": { "type": "text", "analyzer": "ik_smart" } } } }copy_to
将该字段的值复制到目标字段,实现类似_all的作用
不会出现在_source中,只用来搜索
PUT woniu48 { "mappings": { "dynamic": "false", "properties": { "name": { "type": "keyword", "copy_to": "full_name" }, "age": { "type": "integer" }, "desc": { "type": "text", "analyzer": "ik_smart", "copy_to": "full_name" }, "full_name": { "type": "text" } } } }index
控制当前字段是否索引,默认为true,即记录索引,false不记录,即不可搜索
PUT woniu48 { "mappings": { "dynamic": "false", "properties": { "name": { "type": "keyword", "index": false }, "age": { "type": "integer" }, "desc": { "type": "text", "analyzer": "ik_smart", "copy_to": "full_name" } } } }null_value
当字段遇到null值时的处理策略,默认为null,即空值,此时ES会忽略该值,不会创建索引。可以通过设定该值得一个空值的替换值来对空值进行索引,可以用替换值进行对空值的搜索
PUT woniu48 { "mappings": { "properties": { "name": { "type": "keyword" }, "age": { "type": "integer" }, "desc": { "type": "text", "analyzer": "ik_smart" }, "sex": { "type": "keyword", "null_value": "null" } } } }使用null替换了空值,下面添加一个空值
PUT woniu48/_doc/1 { "name": "zs", "age": 23, "desc": "中国人很好", "sex": null }可以使用替换的null值来进行空值搜索
GET woniu48/_search { "query": { "match": { "sex": "null" } } }ignore_above
该属性是keyword类型的一个属性,用来规定字段值长度,超出这个长度的字段将不会被索引,但是会存储。
PUT woniu48 { "mappings": { "properties": { "name": { "type": "text", "fields": { "pinyin": { "type": "keyword", "ignore_above": 5 } } }, "age": { "type": "integer" } } } }多字段特性 multi-fields
允许对同一个字段采用不同的配置,比如分词,常见的例子如一个字段我需要通过索引分词查询也需要能够通过精装匹配查询
PUT woniu48 { "mappings": { "properties": { "name": { "type": "text", "fields": { "pinyin": { "type": "keyword" } } }, "age": { "type": "integer" } } } }数据类型
- 核心数据类型
- 字符串型: text、keyword
- 数值型: long、integer、short、byte、double、float、half_float、scaled_float
- 日期类型: date默认格式:
- “yyyy-MM-dd”
- “yyyyMMdd”
- “yyyyMMddHHmmss”
- “yyyy-MM-ddTHHss”
- “yyyy-MM-ddTHHss.SSS”
- “yyyy-MM-ddTHHss.SSSZ”
使用其他格式需要再mapping里面指定: “format”:”yyyy-MM-dd HHss||yyyy-MM-dd||epoch_millis”
- “yyyy-MM-dd”
- 布尔类型: boolean
- 二进制类型: binary
- 范围类型: integer_range、float_range、long_range、double_range、date_range
- 字符串型: text、keyword
- 复杂数据类型
- 数组类型: array
要求里面的数据类型要一直,会以数组里面数据类型直接座位该属性的数据类型
如果是对象,会以里面的对象类类型作为数据类型 - 对象类型: object
就是罗列出所有的字段单独设置数据类型 - 嵌套类型: nested object
- 数组类型: array
- 地理位置数据类型
- geo_point
- geo_shape
- 专用类型
| JSON类型 | ES类型 |
|---|---|
| null | 忽略 |
| boolean | boolean |
| 浮点类型 | float |
| 整数 | long |
| object | object |
| array | 由第一个非null值得类型决定 |
| string | 匹配为日期格式则设为date类型(默认开启); 匹配为数字的话设为float或long类型(默认关闭)设为text类型,并附带keyword子字段 |
DSL查询
由ES提供丰富且灵活的查询语言叫做DSL查询(Query DSL)。将查询语句通过http request body发送到ES,主要包含如下参数:
- query符合Query DSL语法的查询语句
- from、size
- timeout
- sort
- 。。。
例如:
GET woniu48/_search
{
"query": {
"term": {
"name": "lisi"
}
}
}
基于JSON定义的查询语言,主要包含如下两种类型
- 字段类查询
如term、match、range等,只针对某一个字段进行查询 复合查询
如bool查询等,包含一个或多个字段类查询或则复合查询语句
字段类查询
字段类查询主要包括以下两类:
全文匹配
- 针对text类型的字段进行全文检索,会对查询语句先进行分词处理,如match、match_phrase等query类型
- 单词匹配
- 不会对查询语句做分词处理,直接匹配字段的倒排索引,如term、terms、range等query类型
全文匹配(Match Query)
GET woniu48/_search
{
"query": {
"match": {
"username": "alfred way"
}
}
}
Match Query流程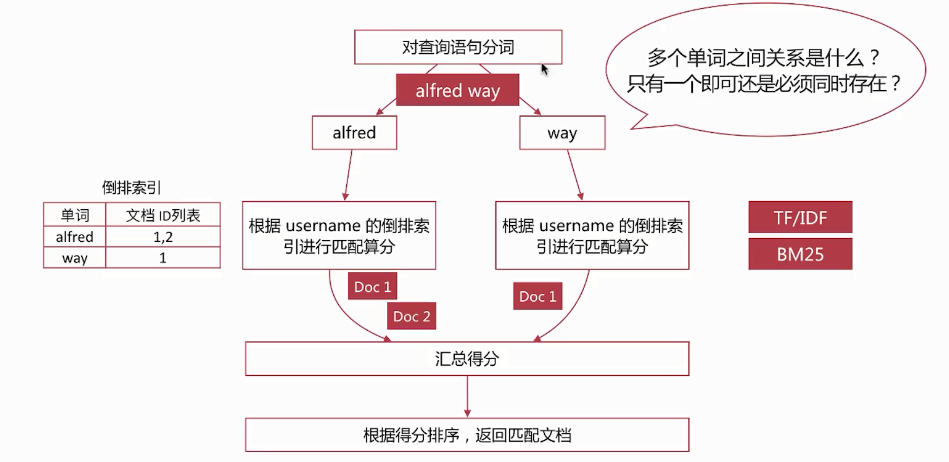
通过operator参数可以控制单词间的匹配关系,可选项为or或则and
GET woniu48/_search
{
"query": {
"match": {
"desc": {
"query": "非常漂亮",
"operator": "and"
}
}
}
}
上面查询如果分词器分词为“非常”、“漂亮”两个词,查询匹配结果就必须同时包含这两个词的文档
单词匹配(Term Query)
GET woniu48/_search
{
"query": {
"term": {
"name": "lisi"
}
}
}
一次传入多个单词进行查询
GET woniu48/_search
{
"query": {
"terms": {
"name": [
"lisi",
"wangmazi"
]
}
}
}
Range Query(范围查询)
GET woniu48/_search
{
"query": {
"range": {
"age": {
"gte": 20,
"lte": 23
}
}
}
}
复合查询
复合查询是指包含字段类查询或复合查询的类型,主要包括以下几类:
- constant_score query
- bool query *
- dis_max query
- function_score query
- boosting query
Bool Query
布尔查询由一个或多个布尔子句组成,主要包含如下4个:
| Name | Description |
|---|---|
| filter | 只过滤符合条件的文档,不计算相关性得分 |
| must | 文档必须复合must中的所有条件,会影响相关性得分 |
| must_not | 文档必须不符合must_not中的所有条件 |
| should | 文档可以符合should中的条件,会影响相关性得分 |
FilterFilter查询只过滤符合条件的文档,不会进行相关性算分
- ES针对Filter会有智能缓存,因此其执行效率很高
- 做简单匹配查询且不考虑算分时,推荐使用filter替代query等
GET woniu48/_search { "query": { "bool": { "filter": [ { "term": { "name": "admin" } }, { "range": { "age": { "gte": 25 } } } ] } } }
must
GET woniu48/_search { "query": { "bool": { "must": [ { "match": { "desc": "漂亮的人" } }, { "range": { "age": { "gte": 22 } } } ] } } }must_not
查询描述里面经过分词有“漂亮”一词以及不带“非常”一词的结果GET woniu48/_search { "query": { "bool": { "must": [ { "match": { "desc": "漂亮的人" } } ], "must_not": [ { "match": { "desc": "非常好" } } ] } } }should
只包含should时,文档必须至少满足一个条件(minimun_should_match可以控制满足条件的个数或则百分比)
例如:下面至少满足一个条件GET woniu48/_search { "query": { "bool": { "should": [ { "match": { "desc": "漂亮的人" } }, { "range": { "age": { "lte": 20 } } } ] } } }例如:下面需要满足两个条件
GET woniu48/_search { "query": { "bool": { "should": [ { "match": { "desc": "漂亮的人" } }, { "range": { "age": { "lte": 20 } } } ], "minimum_should_match": 2 } } }同时包含should和must时,文档不必满足should中的条件,但是如果满足条件,会增加相关性得分
该查询只会以must匹配来搜索GET woniu48/_search { "query": { "bool": { "should": [ { "range": { "age": { "lte": 19 } } } ], "must": [ { "match": { "desc": "漂亮的人" } } ] } } }
综合实例
查询年龄大于20并且包含“漂亮的人”描述或则年龄小于18的学员,分页显示第2页,每页显示2条,且按照年龄由低到高排序GET woniu48/_search { "query": { "bool": { "should": [ { "bool": { "must": [ { "match": { "desc": "漂亮的人" } }, { "range": { "age": { "gte": 20 } } } ] } }, { "range": { "age": { "lte": 18 } } } ] } }, "from": 2, "size": 2, "sort": [ { "age": { "order": "desc" } } ] }

若有收获,就点个赞吧
0 人点赞
