为什么要使用ElasticSearch
实际项目中,我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON/XML通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并在需要扩容时方便地扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。<br /> Lucene是apache软件基金会发布的一个开放源代码的全文检索引擎工具包,提供了完整的创建索引和查询索引,以及部分文本分析的引擎,Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎,Lucene在全文检索领域是一个经典的祖先,现在很多检索引擎都是在其基础上创建的,思想是相通的。<br /> 虽然全文搜索领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
ElasticSearch(简称ES)
ES即为了解决原生Lucene使用的不足,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,其第一个版本于2010年2月出现在GitHub上并迅速成为最受欢迎的项目之一。<br /> 首先,ES的索引库管理支持依然是基于Apache Lucene(TM)的开源搜索引擎。ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。Lucene直接通过java API调用,而ES把这些API调用过程进行了的封装为简单RESTful请求,让我们调用起来更加简单.<br /> 不过,ES的核心不在于Lucene,其特点更多的体现为:分布式的实时文件存储,每个字段都被索引并可被搜索,分布式的实时分析搜索引擎,可以扩展到上百台服务器,处理PB级结构化或非结构化数据,高度集成化的服务,你的应用可以通过简单的 RESTful API、各种语言的客户端甚至命令行与之交互。上手Elasticsearch非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它拥有开瓶即饮的效果(安装即可使用),只需很少的学习既可在生产环境中使用。<br /> Lucene和ES联系,区别:项目中为啥使用ES而不用Lucene.<br /> 联系:ElasticSearch封装了Lucene,让使用变得更简单,在高可用上面做得更好。<br /> 区别:ElasticSearch除了拥有Lucene所有优点以外,还拥有自己优点.<br /> 可用性:支持集群没有单点故障<br /> 扩展性:支持集群扩展<br /> 一般lucene在中小型项目中使用(但是也能使用es),而ES在大型项目中使用.因为ES支持在集群环境使用,并且自身也支持集群.
ES数据管理
什么是ES中的文档
ES是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index,创建索引)每个文档的内容使之可以被搜索。在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
ES使用Javascript对象符号(JavaScript Object Notation),也就是JSON,作为文档序列化格式。JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。
ES存储的一个员工文档的格式示例:
{
“email”: “yyy@xxx.com”,
“name”: “文兵”,
“info”: {
“addr”: “重庆市”,
“age”: 30,
“interests”: [ “樱桃”, “粉嫩” ]
},
“join_date”: “2014-06-01”
}
尽管原始的 employee对象很复杂,但它的结构和对象的含义已经被完整的体现在JSON中了,在ES中将对象转化为JSON并做索引要比在表结构中做相同的事情简单的多。
一个文档不只有数据。它还包含元数据(metadata)—关于文档的信息。三个必须的元数据节点是:
| 节点 | 说明 |
|---|---|
| _index | 索引库,文档存储的地方 |
| _type | 文档类型 |
| _id | 文档的唯一标识 |
_index:索引库,类似于关系型数据库里的“数据库”—它是我们存储和索引关联数据的地方。
_type:类型,类似于关系型数据库中表.在应用中,我们使用对象表示一些“事物”,例如一个用户、一篇博客、一个评论,或者一封邮件。可以是大写或小写,不能包含下划线或逗号。我们将使用 employee 做为类型名。
注意:在新版本里面取消掉了_type 有_type的地方都是一个值_doc
_id: 与 _index 和 _type 组合时,就可以在ELasticsearch中唯一标识一个文档。当创建一个文档,你可以自定义 _id ,也可以让Elasticsearch帮你自动生成。
另外还包括:_uid 文档唯一标识(_type#_id)
_source:文档原始数据
_all:所有字段的连接字符串
文档的增删改
我们以员工对象为例,我们首先要做的是存储员工数据,每个文档代表一个员工。在ES中存储数据的行为就叫做索引(indexing),文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以简单的对比传统数据库和ES的对应关系:<br />关系数据库(MYSQL) -> 数据库DB-> 表TABLE-> 行ROW-> 列Column<br />Elasticsearch -> 索引库Indices -> 类型Types -> 文档Documents -> 字段Fields<br />ES集群可以包含多个索引(indices)(数据库),每一个索引库中可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。<br />**_创建索引文档_**
使用自己的ID创建
PUT {index}/_doc/{id} { "field": "value", ... }使用内置ID创建
POST {index}/_doc { "field": "value", ... }获取指定ID的文档
GET woniu54/_doc/123更新文档
PUT {index}/_doc/{id} { "field": "value", ... }跟创建语法一样,但是会改变版本号
删除文档
DELETE {index}/_doc/{id}注意:尽管文档不存在,但_version依旧增加了。这是内部记录的一部分,它确保在多节点间不同操作可以有正确的顺序
4.3 文档的简单查询(searchAPI)
GET /_search GET /woniu47/_search GET /woniu47,woniu48/_search GET /woniu*/_searchURLsearch:
通过ID获取GET /woniu47/_doc/1只返回文档内容,不要元数据:
GET /woniu47/_source/1查询字符串搜索:
返回文档的部分字段:GET /woniu47/_doc/1?_source=name,age查询年龄为25岁的学员
GET /woniu47/_search?q=age:25查询年龄在25到28 (两边都包括)或则姓名为wangwu的学员
GET /woniu47/_search?q=age:[25 TO 28] OR name:wangwu中括号可以换成大括号,中括号有=大括号没有
分页:
查询20岁以上的学员,显示3条GET /woniu47/_search?q=age:>=20&size=3查询20岁以上的学员,每页显示3条,显示第2页
GET /woniu47/_search?q=age:>=20&size=3&from=3查询参数说明:
| Name | Description |
|---|---|
| q | 标识查询字符串 |
| df | 在查询中,没有定义字段前缀的情况下默认字段的前缀 |
| analyzer | 在分析查询字符串时,分析器的名字 |
| default_operator | 被用到的默认操作,有AND和OR两种,默认是OR |
| explain | 对于每一个命中,对怎样得到命中得分的计算给出一个解释 |
| _source | 将其设置为false,查询就会放弃检索_source字段。也可以通过设置检索部分文档 |
| fields | 命中的文档返回的字段 |
| sort | 排序执行,可以fieldName、fieldName:asc |
| track_scores | 当排序的时候,将其设置为true,可以返回相关度得分 |
| from | 分页查询起始点,默认0 |
| size | 查询数量,默认10 |
| search_type | 搜索操作执行的类型 |
| …… | …… |
索引与分词
什么是倒排索引
倒排索引是先将文档进行分词处理,标记每个词都出现在哪些文档里面,这样就可以快速查询某个词所出现的文档位置。与之对应的是“正排索引”,例如我们看一本书的目录,从前往后查找目录,就是正排索引。<br /> 我们先来看3组文档,我们将文档编号分别列为1、2、3。<br />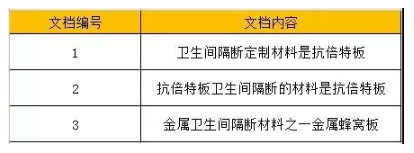<br /> 这3个文档里,核心词是“卫生间隔断”,如果你在搜索引擎上,直接搜索卫生间隔断,抛开文章内容,单看标题,哪个排第一?没错,就是文档1会出现在第一位,为什么?<br /> 因为倒排索引里,会通过单词词典,统计一个单词在文档里出现的位置。我们将上述文档里出现的词,都赋予一个ID。<br /> 这是一个最简单的倒排索引示意图:<br />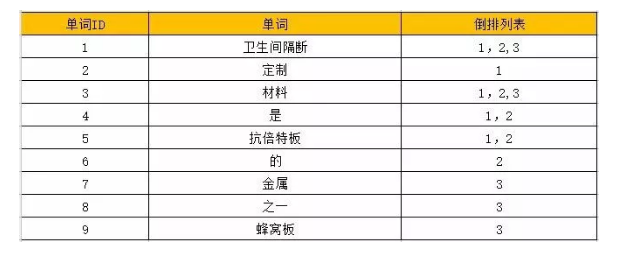
什么是分词
分词是指将文本转换成一系列单词的过程,也可以叫文本分析,在es里面称为Analysis,如下图所示:
分词器是ES中专门处理分词的组件,英文为Analyzer,它的组成如下:
- Character Filters
针对原始文本进行处理,比如去除html特殊标记 - Tokenizer
将原始文本按照一定规则切分为单词 - Token Filters
针对tokenizer处理的单词进行再加工,比如转小写、删除或新增等处理
Analyze API
ES提供了一个测试分词的api接口,方便验证分词效果,endpoint是_analyze
直接指定analyzer进行测试
POST _analyze { "analyzer": "standard", "text": "hello world" }直接指定索引中的字段进行测试
POST woniu47/_analyze { "field": "name", "text": "hello java" }ES自带分词器如下:
| Name | Description |
|---|---|
| standard | 默认分词器,按词切分,支持多语言,小写处理 |
| simple | 按照非字母切分,小写处理 |
| whitespace | 按照空格切分 |
| stop | 相比simple 多了stop word处理(语气2组词等修饰性的词语,比如the、an、的、这等等) |
| keyword | 不分词,直接将输入作为一个单词输出 |
| pattern | 通过正则表达式自定义分割符,默认是\W+, 即非字词的符号作为分隔符 |
中文分词器
中文分词器是将一个汉字序列切分成一个一个单独的词。在英语中,单词之间是以空格作为自然分界符,汉语中词没有一个形式上的分界符。上下文不同,分词结果迥异,比如交叉歧义问题,比如下面两种分词都合理:
- 乒乓球拍/卖/完了
- 乒乓球/拍卖/完了
常用分词系统
- IK
- 实现中英文单词的切分,支持ik_smart、ik_maxword等模式,
- 可自定义词库,支持热更新分词词典
- https://github.com/medcl/elasticsearch-analysis-ik
- 实现中英文单词的切分,支持ik_smart、ik_maxword等模式,
- jieba
- python中最流行的分词系统,支持分词和词性标注
- 支持繁体分词、自定义词典、并行分词等
- https://github.com/sing1ee/elasticsearch-jieba-plugin
IK的使用
- 安装
- git clone https://github.com/medcl/elasticsearch-analysis-ik
- cd elasticsearch-analysis-ik
- mvn clean
- mvn compile
- mvn package
- 拷贝和解压release下的文件: #{project_path}/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-*.zip 到你的 elasticsearch 插件目录, 如: plugins/ik 重启elasticsearch
测试
POST _analyze { "analyzer": "ik_smart", "text": "中华人民共和国国歌" }POST _analyze { "analyzer": "ik_max_word", "text": "中华人民共和国国歌" }ik_smart与ik_max_word的区别
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询
注意: 在config文件夹下面有很多扩展词的配置

若有收获,就点个赞吧
0 人点赞
