1 字符串定义/截取
1.1 字符串定义(引号)
| 简单定义 |
|
python # 普通赋值 a1 = 'Hello' # 单引号 a2 = "Hello" # 双引号 a3 = '''Hello''' # 单引号*3 a4 = """Hello""" # 双引号*3 print(a1 == a2 == a3 == a4) # 引号套娃机制 print("I'm Peter") print('I like "IT"') # 三引号可换行 print('''a\tb\tc\td 1\t2\t3\t4''') |
python # True # I'm Peter I like "IT" # a b c d 1 2 3 4 |
| 取整函数 |
|
python # 四舍五入 print(round(-3.1)) |
python -3 |
1.2 字符串计算
| 字符串计算 |
|
python str1 = 'abc' str2 = '123' # * 为叠加 print(str1 * 2) # + 为直接合并 print(str1 + str2) # , 为空格衔接 print(str1, str2) |
python # abcabc # abc123 # abc 123 |
1.3 字符串切片(中括号)
| 字符串切片 |
|
python str = '0123456' # str[n] # str[索引:截点:步长] # 指定字符 print(str[3]) # 缺省值 print(str[0:len(str):1]) print(str[-len(str)::1]) # 顺序打印全部 print(str) print(str[:]) # 第一参数 表起点 print(str[4:]) print(str[-3:]) # 第二参数 表终点 print(str[:3]) print(str[:-4]) # 第一二参数 符号相同 print(str[1:4]) print(str[-6:-3]) # 第三参数 正负 表顺逆 print(str[::-1]) # 第三参数 大小 表间隔 print(str[::2]) print(str[::-2]) |
python # # # 3 # 0123456 # 等同于print(str) 0123456 # 等同于print(str) # 0123456 0123456 # 456 456 # 012 012 # 123 # 从 正第1+1 到 正第4 123 # 从 倒第6 到 倒第3+1 # 6543210 # 0246 6420 |
| ```plain 从后面索引: -6 -5 -4 -3 -2 -1 逆序第一参数 从前面索引: 0 1 2 3 4 5 正序第一参数 +—-+—-+—-+—-+—-+—-+ |
a |
b |
c |
d |
e |
f |
+—-+—-+—-+—-+—-+—-+ 从前面截取: : 1 2 3 4 5 : 正序第二参数 从后面截取: : -5 -4 -3 -2 -1 : 逆序第二参数 ``` |
2 特殊字符
2.1 ASCII 字符代码
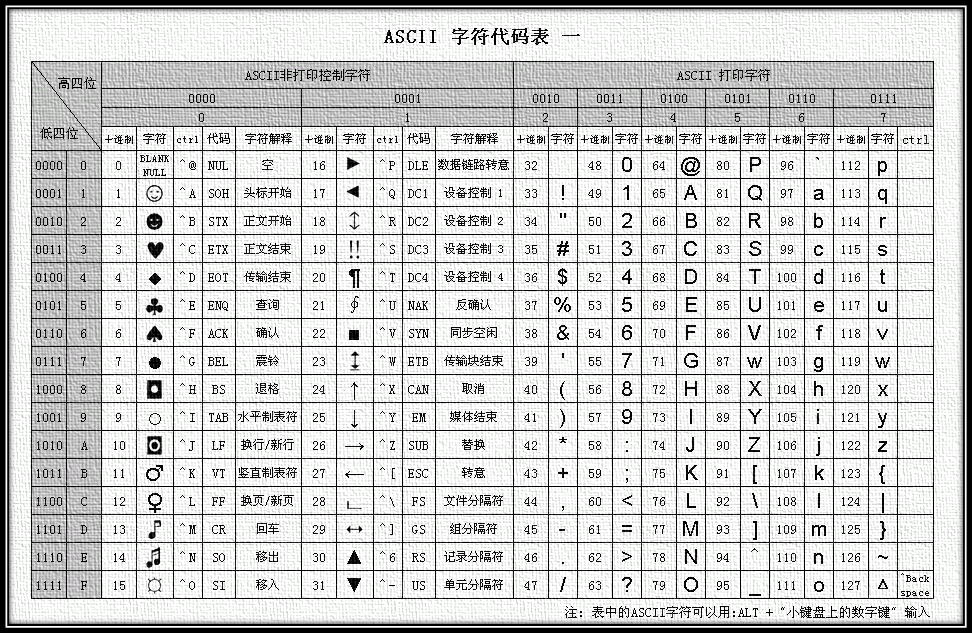 |
|
| 数字转单字母 |
|
python def num_to_letter(t,big=False): if big == False: # 数值转换为ASCII字符 return chr(t + 64) # unichar使用相同 else: # 数值转换为ASCII字符 return chr(t + 96) # unichar使用相同 |
|
python print(num_to_letter(3)) print(num_to_letter(3, True)) |
python C c |
| 单字母转数字 |
|
python def letter_to_num(a): # 字符转换回数值 i = ord(a) if i > 96: return i - 96 else: return i - 64 |
|
python print(letter_to_num('c')) print(letter_to_num('C')) |
python 3 3 |
2.2 万国码(unicode)
python print(u'Hello\u0020World!') |
python Hello World! |
|
Unicode字符列表_百度百科
常用Unicode编码
2.3 转义字符
| 使用频率 |
转义字符 |
说明 |
注释 |
|
\ |
续行符 |
一行没写完,需要另起一行继续写,则在行尾输入\ |
|
\\ |
反斜杠符号 |
\ |
| 高频率 |
\' |
单引号 |
' |
| 高频率 |
\" |
双引号 |
" |
|
\a |
响铃???? |
|
|
\b |
退格 |
相当于Backspace |
|
\e |
转义 |
|
|
\000 |
空 |
|
| 高频率 |
\n |
换行 |
|
|
\v |
纵向制表符 |
|
| 高频率 |
\t |
横向制表符 |
相当于Tab |
|
\r |
回车 |
相当于Enter |
|
\f |
换页 |
|
|
\0yy |
八进制数 |
\0固定格式,\012其中1*8+2=10,可看做第10个Unicode字符串,换行新行。 |
|
\xyy |
十六进制数 |
\x固定格式,\x41其中4*16+1=65,可看做第65个Unicode字符串,即A。 |
|
\other |
????? |
| 续行符 |
|
python print('aaa\ bbb') |
python aaabbb |
3 字符串格式化
3.1 ‘%s’ % (‘ ‘) 格式化
| ‘%s’ % (‘ ‘) 格式化 |
|
python print("%s is %s's boyfriend." % \ ('Peter', 'Joey')) |
python Peter is Joey's boyfriend. |
| 使用频率 |
%号 |
说明 |
| 高频率 |
%s |
格式化字符串 |
|
%c |
格式化字符及其ASCII码 |
| 高频率 |
%d |
格式化整数 |
|
%u |
格式化无符号整型 |
|
%o |
格式化无符号八进制数 |
|
%x |
格式化无符号十六进制数 |
|
%X |
格式化无符号十六进制数(大写) |
|
%f |
格式化浮点数字,可指定小数点后的精度 |
|
%e |
用科学计数法格式化浮点数 |
|
%E |
作用同%e,用科学计数法格式化浮点数 |
|
%g |
%f和%e的简写 |
|
%G |
%f 和 %E 的简写 |
|
%p |
用十六进制数格式化变量的地址 |
3.2 f’{表达式}’ 格式化
| f’{表达式}’格式化 |
|
python str1 = 'Peter' str2 = 'Joey' print(f"{str1} is {str2}'s\ boyfriend") |
python Peter is Joey's boyfriend. |
3.3 r’{表达式}’ 格式化
| f’{表达式}’格式化 |
|
python print('abc\t123\nabc\t123') # \后接字母 不转换为转义字符 print(r'abc\t123\nabc\t123') |
python abc 123 abc 123 abc\t123\nabc\t123 |
3.4 .format(‘ ‘) 格式化
# 缺省法a = '{}\'s girlfriend named {}.'.format('Peter', 'Joey')print(a)# 索引法b1 = '{0}\'s girlfriend named {1}.'.format('Peter', 'Joey')print(b1)b2 = '{1} said, \'{1}\'s boyfriend named {0}.\''.format('Peter', 'Joey')print(b2) # 索引法相对于缺省法,可以自定义字符串放置顺序和次数# 关键字c = "{girl_name} said, '{girl_name}'s boyfriend named {boy_name}.'"\.format(boy_name='Peter', girl_name='Joey')print(c) # 通过关键字相对于索引法更具观赏性,其他无异
class Person: def __init__(self,name,age): self.name,self.age = name,age def __str__(self): return 'This guy is {self.name},is {self.age} old'.format(self=self)
4 字符串内建函数
4.1 最值
| 最值 |
|
python str = 'abc123' # 返回最小字符 print(min(str)) # 返回最大字符 print(max(str)) |
python # 1 # c # 在 Python 中字母比数字大 |
4.2 字符串长度
| 字符串长度 |
|
python print(len('abc123')) print(len('\n')) |
python 6 1 # 转义字符算一个字符 |
4.3 字符串表达式
| 字符串表达式 |
|
python str = 'abc\tabc\n123\t123' # 字符串正常赋值,转义字符可转换 print(str) # repr字符串赋值,转义字符不可转换 print(repr(str)) |
python abc abc 123 123 'abc\tabc\n123\t123' |
5 字符串方法
5.1 字符格式化
5.1.1 对齐字符串
| 对齐字符串 |
|
python a = '417' # a = 417 也可执行 # ------------ 右对齐 ------------ # print('{:>8}'.format(a)) print('{:0>8}'.format(a)) print('{:a>8}'.format(a)) # ------------ 左对齐 ------------ # print('{:<8}'.format(a)) print('{:0<8}'.format(a)) print('{:a<8}'.format(a)) # ------------- 居中 ------------- # print('{:^8}'.format(a)) print('{:0^8}'.format(a)) print('{:a^8}'.format(a)) |
python # 417 00000417 aaaaa417 # 417 41700000 417aaaaa # 417 00417000 aa417aaa # 奇数补齐,优先给右侧 |
5.1.2 进制/精度/分隔符(不可用?)
a = '417' # a = 417 也可执行# -------------- 进制 -------------- #print('{:b}'.format(a)) # 返回:110100001 二进制print('{:o}'.format(a)) # 返回:641 八进制print('{:d}'.format(a)) # 返回:417 十进制print('{:x}'.format(a)) # 返回:1a1 十六进制# -------------- 精度 -------------- #print('{:.6f}'.format(a)) # 返回:417.000000# ------------- 分隔符 ------------- #b = 1234567890print('{:,}'.format(b)) # 返回:1,234,567,890
5.2 空格/占位
5.2.1 去除空格
| 去空格 |
|
| ```python str = ‘ Peter ‘ print(‘ |
‘ + str.lstrip() + ‘ |
‘) print(‘ |
‘ + str.rstrip() + ‘ |
‘) print(‘ |
‘ + str.strip() + ‘ |
‘) ``` |
```python |
Peter |
# 左侧 删除 空格 |
Peter |
# 右侧 删除 空格 |
Peter |
# 两侧 删除 空格 ``` |
5.2.2 空格/0占位
| 空格/0占位 |
|
| ```python str = ‘12345’ print(‘ |
‘ + str.zfill(8) + ‘ |
‘) print(‘ |
‘ + str.rjust(8) + ‘ |
‘) print(‘ |
‘ + str.ljust(8) + ‘ |
‘) print(‘ |
‘ + str.center(8) + ‘ |
‘) ``` |
```python |
00012345 |
# 左侧 补齐 0 |
12345 |
# 左侧 补齐 空格 |
12345 |
# 右侧 补齐 空格 |
12345 |
# 两侧 补齐 空格 # 两侧补齐时,优先补齐右侧 ``` |
5.3 字符串替换
5.3.1 特定字符转换
| 指定字符串转换 |
|
python str = 'abc abc abc' # 指定字符串替换 print(str.replace('a', 'A')) # 替换数量限定 print(str.replace('a', 'A', 1)) # 全部替换 print(str.replace('a', 'A', 10)) |
python # 把所有 'a' 换成 'A' Abc Abc Abc # 1 为更改次数 Abc abc abc # 指定数量大于实际数量时,全部替换 Abc Abc Abc |
5.3.2 TAB转换为空格
| TAB 转 空格 |
|
python str = '123\t123\t123' print(str) # 按默认长度转换 print(str.expandtabs()) # 转换为指定长度 print(str.expandtabs(3)) |
python 123 123 123 # 123 123 123 # 123 123 123 |
5.3.3 大小写转换
| 大小写转换 |
|
python str = 'heLLo worLD!' # 仅首单词的首字母大写 print(str.capitalize()) # 所有单词仅首字母大写 print(str.title()) # 全小写显示 print(str.lower()) # 全大写显示 print(str.upper()) # 大小写反转 print(str.swapcase()) |
python # Hello world! # Hello World! # hello world! # HELLO WORLD! # HEllO WORld! |
5.3.4 映射表
| 方法 |
|
|
说明 |
maketrans |
tranlist = str.maketrans(str1, str2) |
|
制作一个映射表。str1和str2的字符串数量要求一致 |
translate |
str.translate(tranlist) |
|
将str中所有str1涉及的字符替换成str2中的字符 |
| 映射表 |
|
python str1 = 'qwertyuioplkjhgfdsazxcvbnm' str2 = 'QWERTYUIOPLKJHGFDSAZXCVBNM' str = "i'm a supper man" # 制作映射表 tranlist = str.maketrans(str1, str2) # 按照映射表替换指定字符串 print(str.translate(tranlist)) |
python # # I'M A SUPPER MAN |
5.4 字符串分割/合并
5.4.1 字符串分割
| 方法 |
|
返回类型 |
分割次数 |
是否保留分割字符 |
split |
string.split('str1') |
列表 |
彻底 |
否 |
|
string.split('str1', n) |
|
|
|
partition |
str.partition('str1') |
元组 |
1次 |
是 |
rpartition |
str.rpartition('str1') |
|
|
|
splitlines |
str.splitlines() |
列表 |
\n、\r、\n\r的次数 |
否 |
|
str.splitlines(True) |
|
|
\n保留 |
| 字符串分割 |
|
| ```python str = ‘abc123 |
abc123 |
abc123’ # 返回列表,彻底分割,不保留分割字符 tmp = str.split(‘ |
‘) print(type(tmp)) for i in tmp: print(i) # 返回列表,按次数分割,不保留分割字符 tmp = str.split(‘ |
‘, 1) print(type(tmp)) for i in tmp: print(i) # 返回元组,左分一次,保留分割字符 tmp = str.partition(‘ |
‘) print(type(tmp)) for i in tmp: print(i) # 返回元组,右分一次,保留分割字符 tmp = str.rpartition(‘ |
‘) print(type(tmp)) for i in tmp: print(i) str = ‘1st\n2ed\r3rd\r\n4th’ # 返回列表,按\r\n彻底分割,不保留分割字符 tmp = str.splitlines() print(type(tmp)) for i in tmp: print(i) # 返回列表,按\r\n彻底分割,\n保留分割字符 tmp = str.splitlines(True) print(type(tmp)) for i in tmp: print(i) ``` |
```python # abc123 abc123 abc123 # abc123 abc123 |
abc123 # abc123 |
abc123 |
abc123 # abc123 |
abc123 |
abc123 # 1st 2ed 3rd 4th # 1st 2ed 3rd 4th ``` |
5.4.2 字符串合并
| 字符串合并 |
|
| ```python # 合并列表 list1 = [‘a’, ‘b’, ‘c’] str = ‘ |
‘ print(str.join(list1)) # 合并元组 tup1 = (‘a’, ‘b’, ‘c’) str = ‘ |
‘ print(str.join(tup1)) # 合并字典key,乱序 dic1 = {‘a’, ‘b’, ‘c’} str = ‘ |
‘ print(str.join(dic1)) # 合并字典key,顺序 dic1 = {‘a’:1, ‘b’:2, ‘c’:3} str = ‘ |
‘ print(str.join(dic1)) # 合并集合 set1 = ([‘a’, ‘b’, ‘c’]) str = ‘ |
‘ print(str.join(set1)) ``` |
```python # a |
b |
c # a |
b |
c # 不含item的dic合并后得到的字符串乱序 b |
c |
a # a |
b |
c # a |
b |
c ``` |
5.5 字符串成分
5.5.1 字符串位置/数量
| 字符串位置 |
|
python str = '1234567890\n1234567890' # 从左侧寻找字符串 print(str.find('1')) print(str.find('a')) # 从右侧寻找字符串 print(str.rfind('1')) print(str.rfind('a')) # 从左侧寻找字符串 print(str.index('1')) print(str.index('a')) # 从右侧寻找字符串 print(str.rindex('1')) print(str.rindex('a')) |
python # 0 # 找到左侧第一个则返回位置 -1 # 没找到返回 -1 # 11 # 找到右侧第一个则返回位置 -1 # 没找到返回 -1 # 0 # 找到左侧第一个则返回位置 报错:ValueError # 11 # 找到右侧第一个则返回位置 报错:ValueError |
| 字符串数量 |
|
python str = '1234567890\n1234567890' # 返回字符串数量 print(str.count('1')) print(str.count('a')) |
python # 2 0 |
| 区间内查找或计数 |
|
python str = '1234567890\n1234567890' # 区间内查找 print(str.find('1', 5)) print(str.rfind('1', 0, 5)) # 区间内计数 print(str.count('1', 5)) print(str.rfind('1', 0, 5)) |
python # find(查找的字符, 起点, 终点) 11 0 # count(统计的字符, 起点, 终点) 1 0 |
5.5.2 判断字符串成分
| 是否含有字段 |
|
python str = "Hello, Peter" # 判断字符串是否以某一字符串开头 print(str.startswith('Hell')) print(str.startswith('hell')) # 判断字符串是否以某一字符串结尾 print(str.endswith('ter')) print(str.endswith('Ter')) |
python # Ture False # Ture False |
| 是否满足要求 |
|
python # 非空,只有 数字 或 字母 print('abc123'.isalnum()) print('abc 123'.isalnum()) # 非空,只有 字母 print('Yes'.isalpha()) print('Y e s'.isalpha()) # 非空,只有 数字 print('321'.isdigit()) print('321'.isnumeric()) print('321'.isdecimal()) print(u'321'.isdecimal()) # 非空,只有 空格 print(' '.isspace()) # 至少一个字母,字母小写,可有其他字符 print('abc123!'.islower()) # 至少一个字母,字母大写,可有其他字符 print('ABC123!'.isupper()) # 非空,每个单词仅首字母大写,可有... print("I'm Peter.".istitle()) print("I Am Peter.".istitle()) |
python # True False # True False # True True True True # True # True # True # False True |
5.6 编码/解码
| 方法 |
|
|
说明 |
encode |
str.encode(<font style="color:rgb(34, 34, 34);">encoding="utf-8"</font>, errors = "strict") |
|
将unicode编码转换成其他编码的字符串 |
decode |
str.encode(<font style="color:rgb(34, 34, 34);">encoding="utf-8"</font>, errors = "strict") |
|
将其他编码的字符串转换成unicode编码 |
| 参数 |
|
|
说明 |
encoding |
<font style="color:rgb(34, 34, 34);">"utf-8"</font> |
国际通用 |
编码方式
默认值为<font style="color:rgb(34, 34, 34);">"utf-8"</font> |
|
'gbk' |
'gb2312'相似,中文编码 |
|
errors |
"strict" |
遇到非法字符就抛出异常 |
遇到非法字符的处理方式
默认值为"strict" |
|
"ignore" |
忽略非法字符 |
|
|
"replace" |
用?替换非法字符 |
|
|
"xmlcharrefreplace" |
使用 xml 的字符引用 |
python str = '你叫啊' # 编码 str1 = str.encode('utf-8', 'strict') print(str1) str2 = str.encode('gbk', 'strict') print(str2) # 解码 print(str1.decode()) print(str1.decode('utf-8')) print(str2.decode('gbk')) |
python # b'\xe4\xbd\xa0\xe5\x8f\xab\xe5\x95\x8a' b'\xc4\xe3\xbd\xd0\xb0\xa1' # 你叫啊 你叫啊 你叫啊 |
|

