参考或抄袭自 函数式编程 https://blog.csdn.net/archimelan/article/details/81940858 中间件 https://github.com/marklin2012/moa/blob/master/README.md 函数柯里化 https://juejin.cn/post/6844903882208837645 尾递归 https://juejin.cn/post/6844903808309395464
函数式编程
函数式编程的三大特性
- immutable data 不可变数据:像Clojure一样,默认上变量是不可变的,如果你要改变变量,你需要把变量copy出去修改。这样一来,可以让你的程序少很多Bug。因为,程序中的状态不好维护,在并发的时候更不好维护。(你可以试想一下如果你的程序有个复杂的状态,当以后别人改你代码的时候,是很容易出bug的,在并行中这样的问题就更多了)
- first class functions:这个技术可以让你的函数就像变量一样来使用。也就是说,你的函数可以像变量一样被创建,修改,并当成变量一样传递,返回或是在函数中嵌套函数。这个有点像Javascript的Prototype(参看Javascript的面向对象编程)
- First Class。该类型的值可以作为函数的参数和返回值,也可以赋给变量。
- Second Class。该类型的值可以作为函数的参数,但不能从函数返回,也不能赋给变量。
- Third Class。该类型的值作为函数参数也不行
尾递归优化:我们知道递归的害处,那就是如果递归很深的话,stack受不了,并会导致性能大幅度下降。所以,我们使用尾递归优化技术——每次递归时都会重用stack,这样一来能够提升性能,当然,这需要语言或编译器的支持。Python就不支持。
函数式编程的几个技术
map & reduce :这个技术不用多说了,函数式编程最常见的技术就是对一个集合做Map和Reduce操作。这比起过程式的语言来说,在代码上要更容易阅读。(传统过程式的语言需要使用for/while循环,然后在各种变量中把数据倒过来倒过去的)这个很像C++中的STL中的foreach,find_if,count_if之流的函数的玩法。
- pipeline 流水线:这个技术的意思是,把函数实例成一个一个的action,然后,把一组action放到一个数组或是列表中,然后把数据传给这个action list,数据就像一个pipeline一样顺序地被各个函数所操作,最终得到我们想要的结果。
- recursing 递归 :递归最大的好处就简化代码,他可以把一个复杂的问题用很简单的代码描述出来。注意:递归的精髓是描述问题,而这正是函数式编程的精髓。
- currying 柯里化:把一个函数的多个参数分解成多个函数, 然后把函数多层封装起来,每层函数都返回一个函数去接收下一个参数这样,可以简化函数的多个参数。在C++中,这个很像STL中的bind_1st或是bind2nd。
- higher order function 高阶函数:所谓高阶函数就是函数当参数,把传入的函数做一个封装,然后返回这个封装函数。现象上就是函数传进传出,就像面向对象对象满天飞一样。
函数式的一些好处
- parallelization 并行:所谓并行的意思就是在并行环境下,各个线程之间不需要同步或互斥。
- lazy evaluation 惰性求值:这个需要编译器的支持。表达式不在它被绑定到变量之后就立即求值,而是在该值被取用的时候求值,也就是说,语句如x:=expression; (把一个表达式的结果赋值给一个变量)明显的调用这个表达式被计算并把结果放置到 x 中,但是先不管实际在 x 中的是什么,直到通过后面的表达式中到 x 的引用而有了对它的值的需求的时候,而后面表达式自身的求值也可以被延迟,最终为了生成让外界看到的某个符号而计算这个快速增长的依赖树。
- determinism 确定性:所谓确定性的意思就是像数学那样 f(x) = y ,这个函数无论在什么场景下,都会得到同样的结果,这个我们称之为函数的确定性。而不是像程序中的很多函数那样,同一个参数,却会在不同的场景下计算出不同的结果。所谓不同的场景的意思就是我们的函数会根据一些运行中的状态信息的不同而发生变化。
中间件
Koa 中间件机制:Koa 中间件机制就是函数组合的概念,将一组需要顺序执行的函数复合为一个函数,外层函数的参数实际是内层函数的返回值。洋葱圈模型可以形象表示这种机制,是 Koa 源码中的精髓和难点。
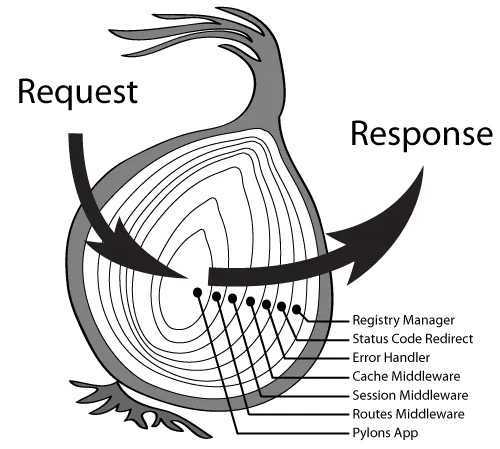
同步函数组合
假设有 3 个同步函数:
// compose_test.jsfunction fn1() {console.log('fn1')console.log('fn1 end')return 'fn2'}function fn2(value) {console.log(value)console.log('fn2 end')return 'fn3'}function fn3(value) {console.log(value)console.log('fn3 end')}// 我们如果想把三个函数组合成一个函数且按照顺序来执行,那通常的做法是这样的fn3(fn2(fn1()))
执行 node compose_test.js 输出结果:
fn1fn1 endfn2fn2 endfn3fn3 end
当然这不能叫做是函数组合,我们期望的应该是需要一个 compose() 方法来帮我们进行函数组合,按如下形式来编写代码:
// compose_test.js// ...const middlewares = [fn1, fn2, fn3]const finalFn = compose(middlewares)finalFn()
让我们来实现一下 compose() 函数,
// compose_test.js// ...const compose = (middlewares) => () => {[first, ...others] = middlewareslet ret = first()others.forEach(fn => {// 将上一个中间件的返回结果作为参数传到下一个中间件ret = fn(ret)})return ret}const middlewares = [fn1, fn2, fn3]const finalFn = compose(middlewares)finalFn()
可以看到我们最终得到了期望的输出结果:
fn1fn1 endfn2fn2 endfn3fn3 end
异步函数组合
了解了同步的函数组合后,我们在中间件中的实际场景其实都是异步的,所以我们接着来研究下异步函数组合是如何进行的,首先我们改造一下刚才的同步函数,使他们变成异步函数,
// compose_test.jsasync function fn1(next) {console.log('fn1')next && await next()console.log('fn1 end')}async function fn2(next) {console.log('fn2')next && await next()console.log('fn2 end')}async function fn3(next) {console.log('fn3')next && await next()console.log('fn3 end')}//...
这次和同步的就不一样了,我们希望输出结果是这样的:
fn1fn2fn3fn3 endfn2 endfn1 end
同时我们希望编写代码的方式也不要改变,
const middlewares = [fn1, fn2, fn3]const finalFn = compose(middlewares)finalFn()
所以我们只需要改造一下 compose() 函数,使他支持异步函数就即可:
function compose(middlewares) {return function () {// 定义一个派发器,这里面就实现了 next 机制function dispatch(i) {// 获取当前中间件let fn = middlewares[i]if (!fn) {return Promise.resolve()}// 返回一个promise对象return Promise.resolve(// 传递fn(function next() {// 通过 i + 1 获取下一个中间件,传递给 next 参数return dispatch(i + 1)}))}// 开始派发第一个中间件return dispatch(0)}}const middlewares = [fn1, fn2, fn3]const finalFn = compose(middlewares)finalFn()
运行结果:
fn1fn2fn3fn3 endfn2 endfn1 end
柯里化
什么是柯里化
所谓”柯里化”,就是把一个多参数的函数,转化为单参数函数。《函数式编程入门教程》阮一峰
柯里化,可以理解为提前接收部分参数,延迟执行,不立即输出结果,而是返回一个接受剩余参数的函数。因为这样的特性,也被称为部分计算函数。柯里化,是一个逐步接收参数的过程。
在数学和计算机科学中的柯里化函数,一次只能传递一个参数;
// 数学和计算科学中的柯里化://一个接收三个参数的普通函数function sum(a,b,c) {console.log(a+b+c)}//用于将普通函数转化为柯里化版本的工具函数function curry(fn) {//...内部实现省略,返回一个新函数}//获取一个柯里化后的函数let _sum = curry(sum);//返回一个接收第二个参数的函数let A = _sum(1);//返回一个接收第三个参数的函数let B = A(2);//接收到最后一个参数,将之前所有的参数应用到原函数中,并运行B(3) // print : 6
Javascript实际应用中的柯里化函数,可以传递一个或多个参数
//普通函数function fn(a,b,c,d,e) {console.log(a,b,c,d,e)}//生成的柯里化函数let _fn = curry(fn);_fn(1,2,3,4,5); // print: 1,2,3,4,5_fn(1)(2)(3,4,5); // print: 1,2,3,4,5_fn(1,2)(3,4)(5); // print: 1,2,3,4,5_fn(1)(2)(3)(4)(5); // print: 1,2,3,4,5
这是我们常见的应用场景
function checkByRegExp(regExp,string) {return regExp.test(string);}checkByRegExp(/^1\d{10}$/, '18642838455'); // 校验电话号码checkByRegExp(/^(\w)+(\.\w+)*@(\w)+((\.\w+)+)$/, 'test@163.com'); // 校验邮箱
如果没有注释,我们必须通过检查正则的内容, 才能知道我们校验的是电话号码还是邮箱,还是别的什么。
使用柯里化,可以通过函数名称来知道具体用途,最重要的是做到参数复用
//进行柯里化let _check = curry(checkByRegExp);//生成工具函数,验证电话号码let checkCellPhone = _check(/^1\d{10}$/);//生成工具函数,验证邮箱let checkEmail = _check(/^(\w)+(\.\w+)*@(\w)+((\.\w+)+)$/);checkCellPhone('18642838455'); // 校验电话号码checkEmail('test@163.com'); // 校验邮箱
如何实现
实现 add(1)(2, 3)(4)() = 10 的效果。
传入参数时,代码不执行输出结果,而是先储存起来。
当传入空的参数时,代表可以进行真正的运算。
function currying(fn){var allArgs = []; // 闭包,用来储存参数return function next(){var args = [].slice.call(arguments);// 判断是否执行计算if (args.length > 0) {allArgs = allArgs.concat(args); // 收集传入的参数,进行缓存return next;} else {return fn.apply(null, allArgs); // 没有参数了,符合执行条件,执行计算}}}
实现 add(1)(2, 3)(4)(5)``= 15 的效果。
但是要怎样才能知道要什么时候执行函数并返回结果呢?
function currying(fn){var allArgs = [];function next(){var args = [].slice.call(arguments); // 将参数放进闭包中储存起来allArgs = allArgs.concat(args);return next;}next.toString = function(){return fn.apply(null, allArgs); // 字符类型};next.valueOf = function(){return fn.apply(null, allArgs); // 对象类型}return next;}var add = currying(function(){var sum = 0;for(var i = 0; i < arguments.length; i++){sum += arguments[i];}return sum;});const a = add(1)(2, 3)(4)(5)console.log(a) // ƒ 15a === 15 // falseadd(6)console.log(a) // ƒ 21
这个方法有意思的是传的函数可以没有形参,通过valueOf和toString来触发函数调用。
那么什么时候会触发这两个函数呢?
使用操作符的时候,如果其中一边为对象,则会先调用toSting方法,也就是隐式转换,然后再进行操作。
操作符包括算术运算符、一元运算符、逻辑运算符(布尔运算符)、关系运算符(比较运算符)、赋值运算符。
但是这个方法缺陷很大,通过这个柯理化函数返回的是一个函数,只是触发了valueOf或toString方法中的原始函数。
JavaScript 中所有变量都可以当作对象使用,除了两个例外 null 和 undefined。
JavaScript调用
valueOf方法将对象转换为原始值。你很少需要自己调用valueOf方法;当遇到要预期的原始值的对象时,JavaScript会自动调用它。 默认情况下,valueOf方法由Object后面的每个对象继承。 每个内置的核心对象都会覆盖此方法以返回适当的值。如果对象没有原始值,则valueOf将返回对象本身。 JavaScript的许多内置对象都重写了该函数,以实现更适合自身的功能需要。因此,不同类型对象的valueOf()方法的返回值和返回值类型均可能不同。字符串上下文中的对象通过 toString()方法转换,这与使用valueOf转换为原始字符串的String对象不同。所有对象都能转换成一个“[object 类型]”这种格式的字符串。但是很多对象不能转换为数字,布尔或函数。
function curry (fn, currArgs) {return function() {let args = [].slice.call(arguments);// 首次调用时,若未提供最后一个参数currArgs,则不用进行args的拼接if (currArgs !== undefined) {args = args.concat(currArgs);}// 递归调用if (args.length < fn.length) {return curry(fn, args);}// 递归出口return fn.apply(null, args);}}function sum(a, b, c) {return (a + b + c);}const fn = curry(sum);fn(1, 2, 3); // 6fn(1, 2)(3); // 6fn(1)(2, 3); // 6fn(1)(2)(3); // 6typeof fn(1, 2, 3) // "number"
这个是更为正统的一种写法,但是传入的参数fn就必须声明参数,这样fn.length才能获取到参数个数。
但是如果参数不够,是不会执行的。
尾递归
先来说说尾调用
当函数a的最后一个动作是调用函数b时,那么对函数b的调用形式就是尾调用
比如下面的代码里对fn1的调用就是尾调用
const fn1 = (a) => {let b = a + 1;return b;}const fn2 = (x) => {let y = x + 1;return 1 + fn1(y); // 普通调用}const fn3 = (x) => {let y = x + 1;return fn1(y); // 尾调用}const result = fn2(1);
// 普通递归// 经典的阶乘函数function factorial(n) {if (n <= 1) return 1;return factorial(n - 1) * n}console.log(factorial(5)) // 120console.log(factorial(6594)) // 6594爆栈// 尾递归function factorial(n, sum) {if (n <= 1) return sum;return factorial(n - 1, sum * n)}console.log(factorial(5, 1)) // 120console.log(factorial(12040, 1)) // 12000左右依然爆栈了,但是比之前的爆栈上限提升了不少
为什么会堆栈溢出呢?从上面的概念我们理解到,每次函数调用,都会为其开辟一小块内存,并把函数推入堆栈,执行完毕后才会释放。
而我们的阶乘函数,在最后一句return factorial(n - 1) n 包含了一个对自身的调用 n,这就使得该函数必须要等待新的函数调用执行完毕后再乘以n之后才算执行完毕返回,同样的新的函数调用在最后的时候又要等待内部的新的函数嗲调用执行完毕后进行计算再返回。
如此一来,就好比如,a内有个b,b有个c,c内有个d……而a要等b执行完才释放,b要等c,c要等d……这样在堆栈内便存放了n多个函数的“调用记录”,而每一个“调用记录”是开辟了一块内存的,所以,便超出了浏览器的限制,溢出了。
尾调用的核心就是:在函数执行的最后一步返回一个函数调用。注意哦,是最后一步,而不必须是最后一行代码。
我们虽然通过了尾调用优化了我们的递归函数(这里是尾递归,尾调用自身即尾递归),但是上面的操作,在达到某个值的时候依然会爆栈。这是为什么呢?究其原因:
- 尾调用只在严格模式下生效,正常模式下是没有效果的
- es6明确表示,只要实现了尾调用,就不会栈溢出。然后js解释器在实现的时候并未遵守这一规范。v8曾经实现过,后来又删除了调用优化,因为进行函数尾递归优化之后,会破坏函数的调用栈记录。w3c也在致力于寻找新的语法来指明函数的尾调用。

若有收获,就点个赞吧
0 人点赞
