1.类图
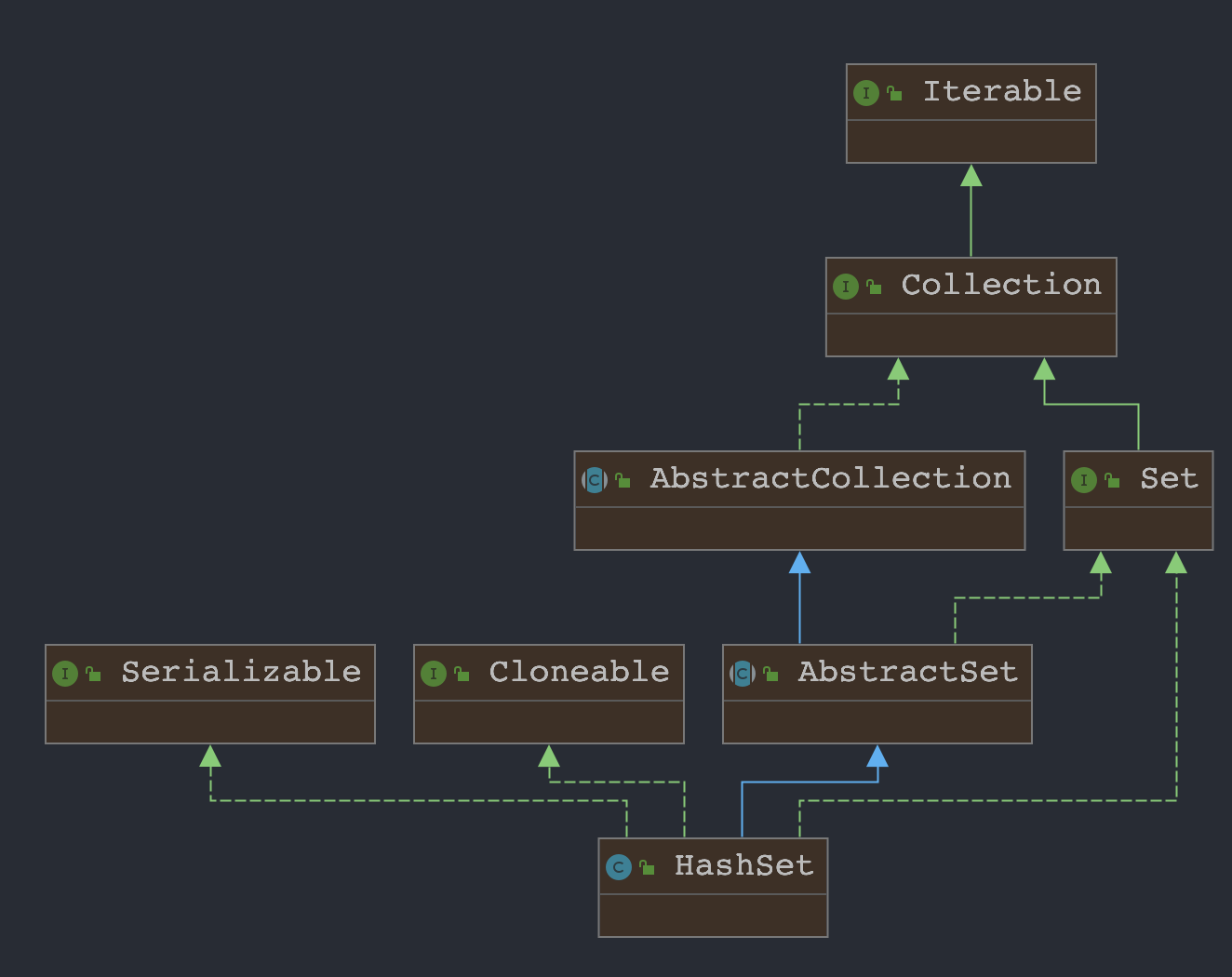
public class HashSet<E>extends AbstractSet<E>implements Set<E>, Cloneable, java.io.Serializable {}
继承于AbstractSet抽象类,实现了Set、Cloneable、Serializable接口。
2.成员变量
// 底层是一个hashmap<E, Object>的集合private transient HashMap<E,Object> map;// Dummy value to associate with an Object in the backing Map// 因为 HashMap 是存放键值对的,而 HashSet 只会存放其中的key,即当做 HashMap 的key,// 而value 就是这个 Object 对象了,HashMap 中所有元素的 value 都是它private static final Object PRESENT = new Object();
为什么使用PRESENT而不使用null,参见4中的add方法
3. 构造方法
public HashSet() {map = new HashMap<>();}public HashSet(Collection<? extends E> c) {map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));addAll(c);}public HashSet(int initialCapacity, float loadFactor) {map = new HashMap<>(initialCapacity, loadFactor);}public HashSet(int initialCapacity) {map = new HashMap<>(initialCapacity);}// 非public的,意味着它只能被同一个包或者子类调用,这是LinkedHashSet专属的方法。HashSet(int initialCapacity, float loadFactor, boolean dummy) {map = new LinkedHashMap<>(initialCapacity, loadFactor);}
hashSet的构造方法是为了辅助构建map集合。传入的参数都跟map有关:初始容量和加载因子
4.方法
放入的元素一定要重写hashCode和equals方法。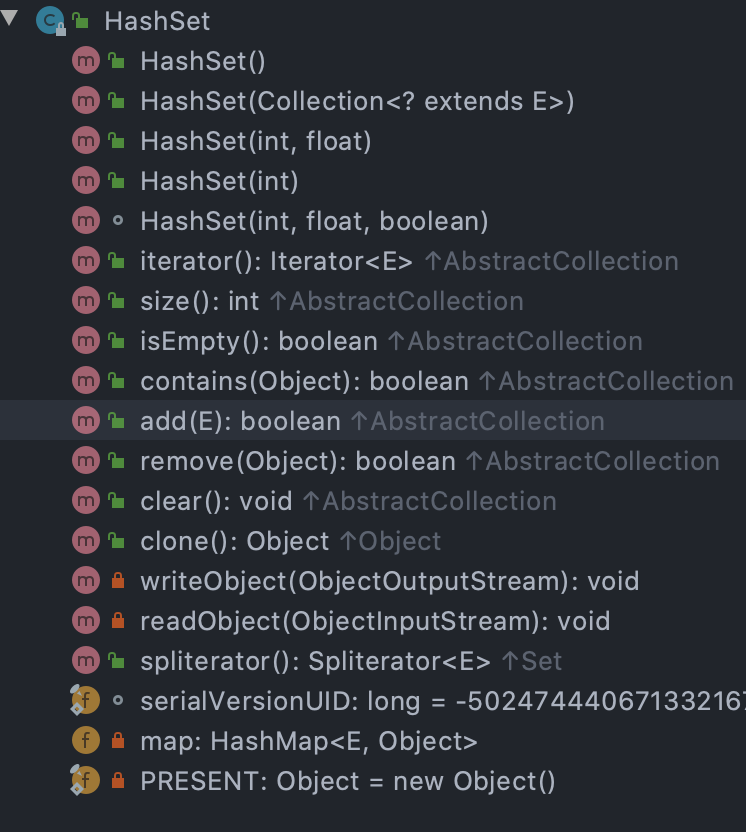
HashSet底层的方法都是通过map进行的,所以底层的方法都是调用hashMap的方法。而这些方法全部继承于付了AbstractCollection
// 增// map的put方法底层在新增节点时如果已经存在该键值,将返回null,(键为e,值统一为同一个Object即PRESENT)// 所以如果是null,该方法返回false,即不能有重复值// 在这里使用PRESENT而不使用null,是因为如果值为null,put的时候如果发现相同的key,则会返回旧值// 而此时旧值就是null,会返回true,即插入了重复值,矛盾。public boolean add(E e) {return map.put(e, PRESENT)==null;}// 删// map的remove方法如果删除成功返回该键对应的值(即PRESENT),如果删除成功,该方法返回true,// 如果不存在,remove方法返回null,该方法返回false。public boolean remove(Object o) {return map.remove(o)==PRESENT;}// 查public boolean contains(Object o) {// 返回的是键的查询return map.containsKey(o);}public int size() {return map.size();}public boolean isEmpty() {return map.isEmpty();}public void clear() {map.clear();}// 迭代器是map的键迭代器public Iterator<E> iterator() {return map.keySet().iterator();}
5. LinkedHashSet
public class LinkedHashSet<E>extends HashSet<E>implements Set<E>, Cloneable, java.io.Serializable { }
底层使用LInkedHashMap存储数据,使数据由于链表指针的存在具有有序性,所有的方法均来自父类HashSet,直接调用父类方法即可。
public LinkedHashSet() {super(16, .75f, true);}public LinkedHashSet(int initialCapacity) {super(initialCapacity, .75f, true);}public LinkedHashSet(int initialCapacity, float loadFactor) {super(initialCapacity, loadFactor, true);}public LinkedHashSet(Collection<? extends E> c) {super(Math.max(2*c.size(), 11), .75f, true);addAll(c);}

若有收获,就点个赞吧
0 人点赞
