## 前言
Node.js 发展到今天,已经被越来越广泛地应用到 BFF 前后端分离 、 全栈开发 、 客户端工具 等领域。然而,相对于应用层的蓬勃发展,其 Runtime 对于绝大部分前端出身的开发者来说,处于黑盒的状态,这一点并没有得到很好的改善,从而也阻碍了 Node.js 在业务中的应用和推广。
笔者目前就职于阿里巴巴 AliNode 团队,在过去几年里,亲身经历过的很多线上故障,其中让开发者最头痛又最难以排查的是:
内存泄漏
CPU 长期 100%(类死循环)
第一点中,对于缓慢上涨最终 OOM 这种类型的内存泄漏,我们有充足的时间去抓 Heapsnapshot,进而分析堆快照来定位泄漏点。(可参见之前的文章 『Node 案发现场揭秘 —— 快速定位线上内存泄漏』 )
而第二点,对于诸如 while 循环跳出条件失败 、 长正则执行导致进程假死 、以及 由于异常请求导致应用短时间内 OOM 的情况,往往来不及抓取 Heapsnapshot,一直没有特别好的办法进行处理。本文将介绍一种基于 core dump 来分析定位线上应用故障的方法。
## 背景知识
排查疑难杂症,无非是先想办法保存现场,然后再通过工具去分析。
### 如何保存现场?
首先要介绍下 Core Dump,它是操作系统提供的调试辅助操作,包含 内存分配信息 、program counter 以及 堆栈指针 等关键信息,对于开发者诊断和调试程序非常有帮助(有些程序错误是很难重现的)。
生成 Coredump 文件有两种方式:
- 当我们的应用意外崩溃终止时,操作系统将自动记录。
这种方式一般用于 「死后验尸」,用于分析由雪崩触发 OOM。
我们首先要使用 ulimit -c unlimited 打开内核限制,也可以选在 Node 应用启动时加上参数 --abort-on-uncaught-exception 来对出现未捕获的异常时也进行自动 Core dump。
这里需要注意的是,这是一个并没有那么安全的操作:线上一般会 pm2 等具备自动重启功能的守护工具进行进程守护,这意味着如果我们的程序在某些情况下频繁 crash 和重启,那么会生成大量的 Coredump 文件,甚至可能会将服务器磁盘写满。所以开启这个选项后,请务必记得对服务器磁盘进行监控和告警。
- 手动调用
gcore <pid>的方式来手动生成。
这种方式一般用于 「活体检验」,用于 Node.js 进程假死状态 下的问题定位。
拿到了问题进程的 Coredump 文件,剩下的问题就是如何去分析。
### 如何分析?
一般会借助于 mdb、gdb、lldb 等工具来诊断 crash 的原因,但这些工具都只能帮助我们回溯到 c++ 层面的堆栈信息,如下:
// crash.jsconst article = { title: "Node.js", content: "Hello, Node.js" };setTimeout(() => {console.log(article.b.c);}, 1000);
当我们开启 ulimit 参数并执行 node --abort-on-uncaught-exception crash.js 后,可以看到当前目录会生成一份 core.<pid> 格式的文件(mac 下通常会在 /cores/ 目录下),接着我们尝试使用 lldb 进行尝试分析:
$ lldb node -c core.<pid>
命令行提示 Core file xxx was loaded. 时,表示已经加载成功,接着我们执行 bt ,来回溯下 crash 时刻的栈信息,可以看到如下图所示:
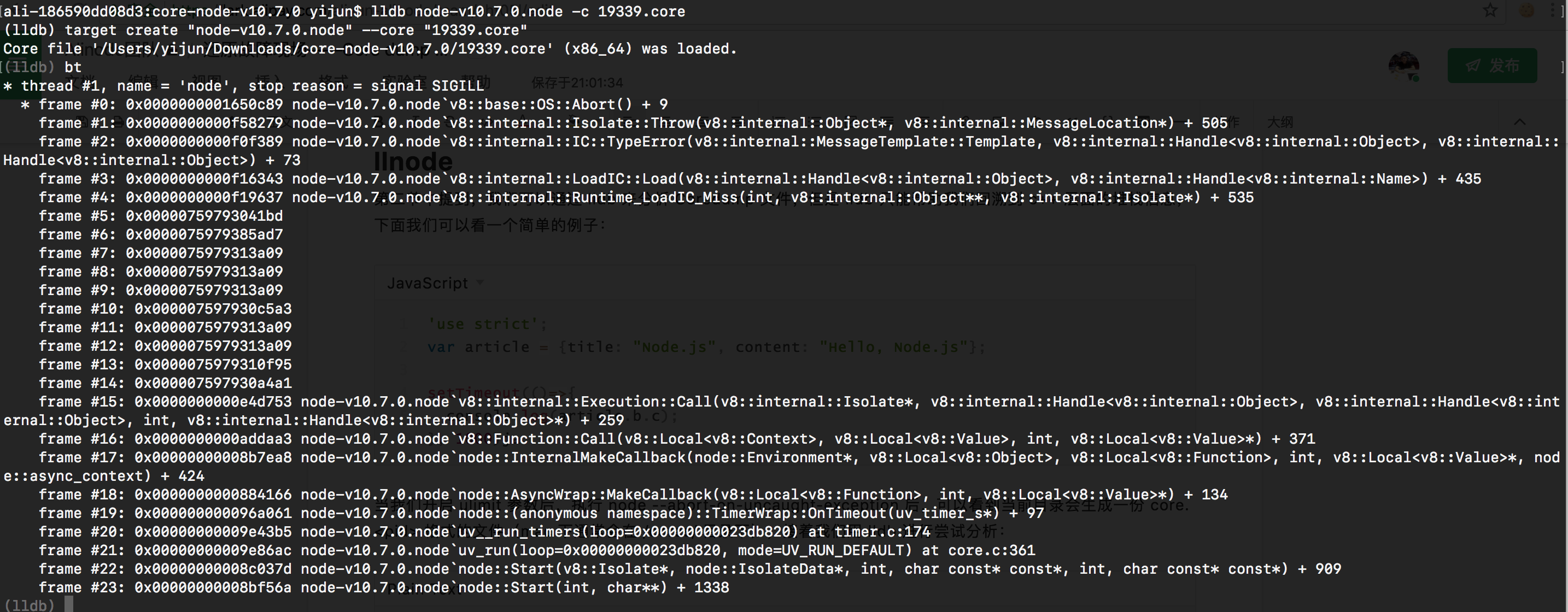
熟悉 Node.js 源代码的同学会发现 node::Start -> uv_run -> uv__run_timers 确实是从启动到进入 libuv 的地方,并且这里应该是执行了一个 js 层的 timer 导致的奔溃,这些分析和我们的问题代码确实是符合的,然而考虑到线上真实代码的复杂度,显然单纯靠 c++ 的栈信息,我们并不能看到是哪里的 js 代码触发了进程奔溃。
幸好我们有 llnode,它实际上是 lldb 的一个插件,它借助于 lldb 暴露出来的 api,经过转换后能够还原 js 栈和 v8 对象,sourcemap 的既视感有没有?
$ # 安装 llnode$ npm install llnode -g$$ # 分析$ llnode node -c core.<pid>
然后执行 v8 bt 进行回溯,结果如下图所示:

Cool~ js 的栈信息也能看到了,借助于这样更加完整的信息,我们就可以很快的定位到问题函数了。
看到这里,似乎我们今天的话题就可以结束了,毕竟借助 llnode + Coredump,我们已经完美解决了之前提到的疑难杂症。
但在实际使用中,纯客户端的 llnode 还有一些问题:
安装配置麻烦
llnode 依赖 lldb 版本,部分 Coredump 文件在 lldb-3.x/4.x 下无法获取到正确的栈信息。
llnode 插件本身是 addon,本地安装编译需要高版本 gcc(支持 c++11) 和 python 环境的支持。
还原 utf8 编码的中文存在问题,导致一些中文字符串会乱码,且被异常截断导致字符串大小出错影响故障排查。
分析方式不够自动化和智能
默认线程未必是 JS 线程,这种情况下需要手动挨个去查找 JS 线程。
命令行下 js 栈和 c++ 栈加上一些 unknown stub 挤在一块很是考验眼力。
## Coredump 分析服务
Coredump 分析服务是 Node.js 性能平台(Alinode) 提供的一项 免费服务,我们基于开源的 llnode 进行了二次开发和深度定制,解决了上述问题,可以降低开发者的使用门槛,并更智能的去辅助分析定位线上故障。
下面将使用两个真实的故障案例,来给大家展现下。
### 使用准备
首先简单介绍下如何将 Coredump 文件以及可执行 node 文件上传分析。访问控制台主页,打开任意一个应用界面的 文件 选项。(如果你没有创建过应用,可以先按照 创建应用 流程创建一个新应用。)
文件列表默认展示的是原来的 Heapsnapshot、CPU Profile 和 GC Trace 等性能分析文件,现在新增了 Coredump 分析文件列表,只需要将鼠标移动到左边 Tab 栏目的 文件 按钮上,可以看到新增内容:
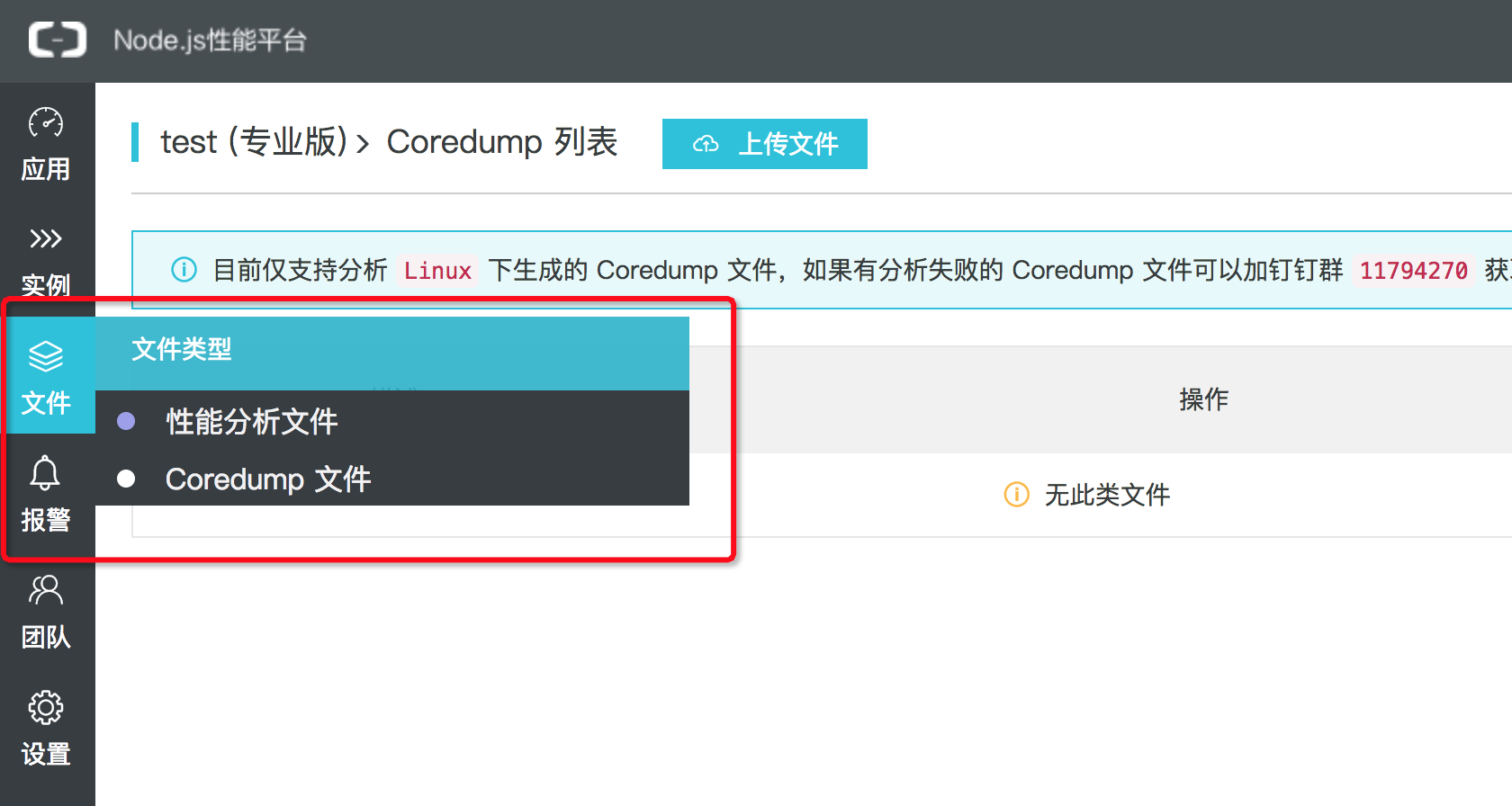
选择 Coredump 文件 即可进入 Coredump 文件列表,点击上图中的 上传文件 选项,即可在弹出框中按照提示将对应的 Coredump 文件和 node 可执行文件上传至服务器了。
这里需要注意的是,请将 Coredump 文件以 .core 结尾重命名,Node 可执行文件以 .node 结尾重命名,推荐的命名方式为 <os info>-<alinode/node>-<version>.node,方便以后回顾,比如 centos7-alinode-v4.2.2.node 这种。最后 Coredump 文件和 node 可执行文件之间必须是 一一对应 的关系。这里一一对应指的是:这份 Coredump 文件必须是由这个 Node 可执行文件启动的进程生成的,如果这两者没有一一对应,分析结果往往是无效信息。
### CPU 长期 100%(类死循环)
样例使用 Egg.js 搭建,首先来看这样的一段 Egg Controller 代码:
'use strict';const Controller = require('egg').Controller;class RegexpController extends Controller {async long() {const { ctx } = this;let str = '<br/> ' +' 早餐后自由活动,于指定时间集合自行办理退房手续。';str += '<br/> <br/>' +' <br/> ' +' <br/>';str += ' <br/>' +' ' +' ' +' <br/>';str += ' <br/> <br/>';str += ' ' +' ' +' 根据船班时间,自行前往暹粒机场,返回中国。<br/>';str += '如需送机服务,需增加280/每单。<br/>';const r = str.replace(/(^(\s*?<br[\s\/]*?>\*?)+|(\s*?<br[\s\/]*?>\s*?)+?$)/igm, '');ctx.body = r;}}module.exports = RegexpController;
在 Node.js 应用中,正则匹配是一个相当常见的操作,并且正则表达式匹配的字符串往往来自于用户和其它内部接口。这意味着匹配字符串本身不是那么可控的,因此如果一个异常的输入触发了正则表达式灾难性的回溯,会导致执行时间要耗费几年甚至几十年,显然不管是那种情况,单主工作线程的模型会导致我们的 Node.js 应用处于假死状态,即进程依旧存活,但是却不再处理新的请求。
上述这段代码中,模拟了这样的一种回溯状态,当我们访问到这个 Controller 时,会发现 Node.js 服务器会立即卡住,此时使用 gcore 生成一份当前进程的 Coredump 文件,按照上一小节中的方式,我们将生成的 Coredump 文件和对应的 node 可执行文件重命名后上传,耐心等待上传成功后,可以看到如下界面:
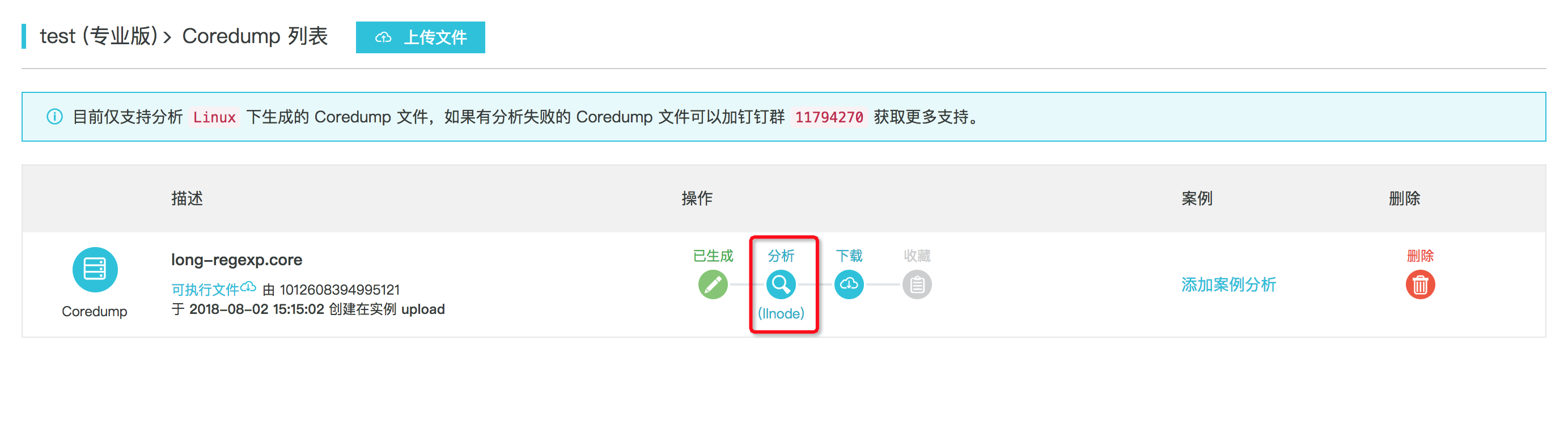
点击 分析 按钮,即可开始分析,等待分析完成后如下图所示:
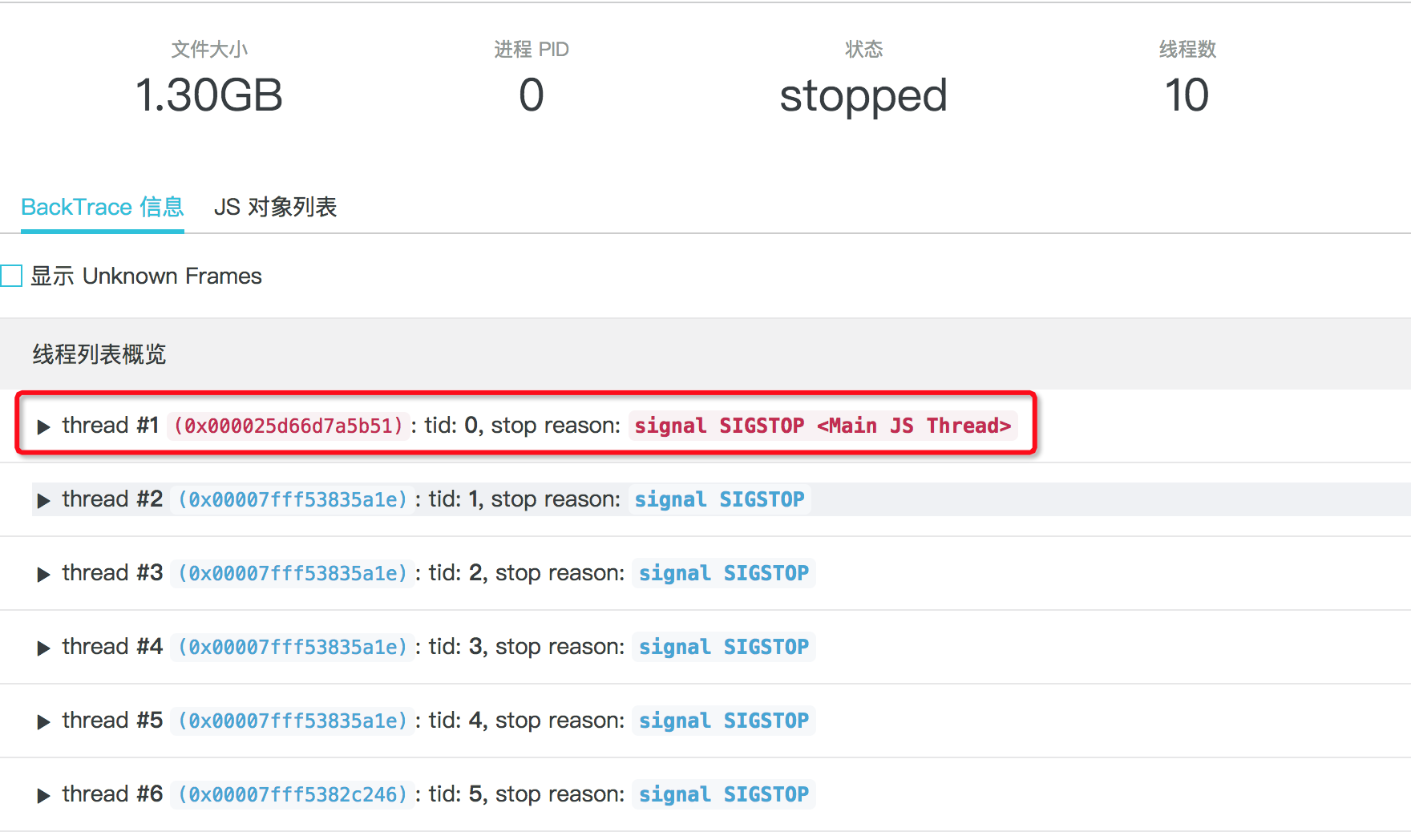
在 llnode 中,实际上默认的 thread 1 并不一定是主线程,这里我们将包含 JS 栈信息的线程过滤出来,并且标红置顶方便使用,点开这里的 Main JS Thread 后,可以看到当前的 frame 详情:

此时很容易就能看到,进程当前在执行一个 replace 操作,并且正则表达式的具体内容和执行这个 replace 正则操作的函数位置也很清楚。甚至这里省略展示的正则匹配字符串,我们想要看到全貌的话也非常简单:鼠标移动到 “
…” 字符串上并点击一下,就可展开更多内容:

可以看到,这里的字符串内容和我们代码中模拟的触发长回溯的字符串一模一样。另外这种 CPU 长期 100% 的问题,我们也提供了另外相对轻量的方式来解决,详情参见 Node.js 性能平台支持死循环和正则攻击定位。
### 堆内存短时间内雪崩
短时间内堆内存雪崩也是一类相对难以排查的问题,因为内存告警一般有时间差,一些情况下等我们收到堆内存告警时,进程其实已经 OOM 并重启了,根本来不及抓堆快照,可以看下面的一个例子:
'use strict';const Controller = require('egg').Controller;const fs = require('fs');const path = require('path');const util = require('util');const readFile = util.promisify(fs.readFile);class DatabaseError extends Error {constructor(message, stack, sql) {super();this.name = 'SequelizeDatabaseError';this.message = message;this.stack = stack;this.sql = sql;}}class MemoryController extends Controller {async oom() {const { ctx } = this;let bigErrorMessage = await readFile(path.join(__dirname, 'resource/error.txt'));bigErrorMessage = bigErrorMessage.toString();const error = new DatabaseError(bigErrorMessage, bigErrorMessage, bigErrorMessage);ctx.logger.error(error);ctx.body = { ok: false };}}module.exports = MemoryController;
这个例子也是来源于一个真实的线上故障,当我们使用 egg-logger 输出日志的时候,很多时候会像例子中一样,不去对属性加以限制直接输出,而在 egg-loger 中,当我们传入的第一个参数是 Error 的实例时,会去调用 Node.js 核心库 util 中的 inspect 方法进行格式化。问题就在这里,如果 error 对象上面有一些属性包含了很大的字符串,做 inspect 的时候就会溢出触发 OOM,这里正是在 resource/error.txt 中填充了一个大字符串模拟了这种情况。
如果此时我们按照第二节中的说明已经打开了 ulimit 参数限制,那么堆内存迅速雪崩时,系统会自动生成一份 Coredump 文件,同样我们把这份 Coredump 文件和对应的 node 可执行文件上传到性能平台,并点击 分析 按钮,等待分析完成后点开 标红 的 JS 主线程,可以看到如下信息:

圈起来的 JS 调用栈和我们之前提到的过程完全一致,更多的,我们可以看下产生问题的字符串大小,将鼠标悬浮到字符串上可以看到字符串大小:
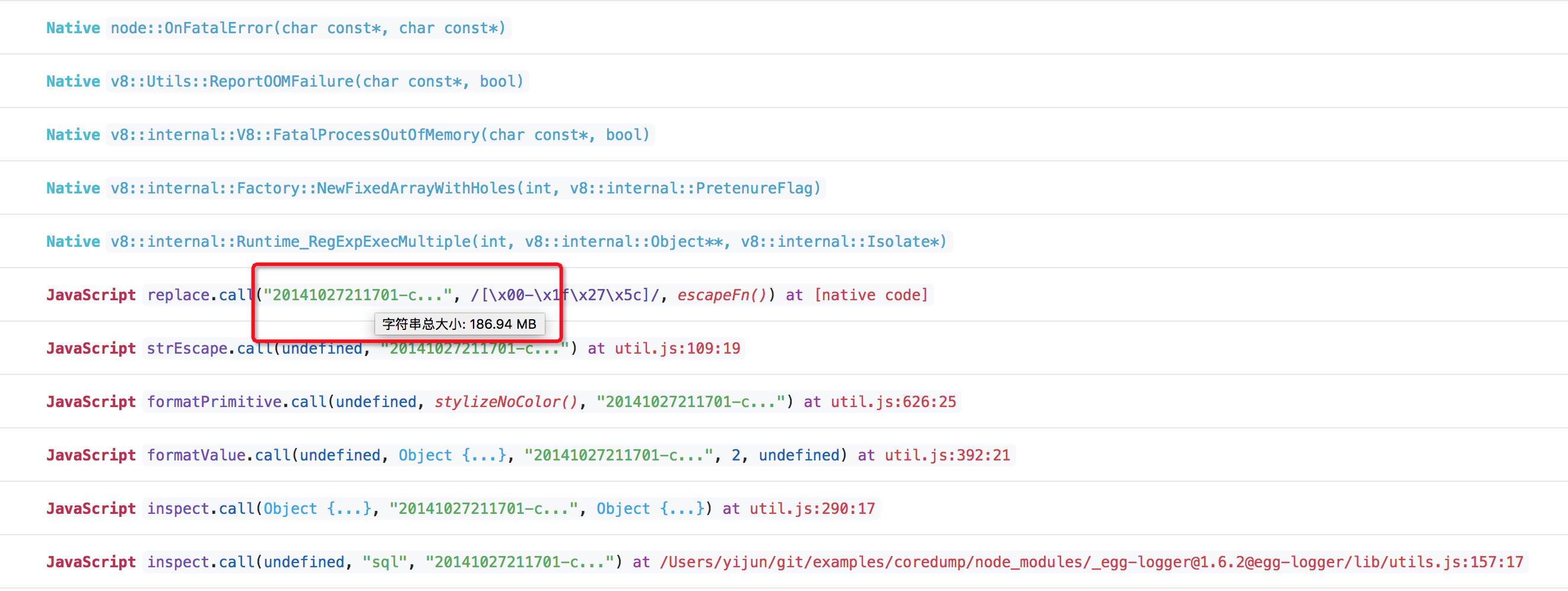
这里正是这个 186M 的大字符串 inspect 时导致了 OOM。而在那个真实的线上故障中,实际上是拼接的 sql 语句非常大,大小约为 120M,因此首先导致数据库操作失败,接着数据库操作失败后输出的 DatabaseError 对象实例上则原封不动地将问题 sql 语句设置到属性上,从而导致了 ctx.logger.error(error) 时堆内存的雪崩。
## 一些感想
笔者从 14 年开始投入到 Node.js 相关方面的开发,写过业务,做过基础架构,到现在致力于更底层的保障。虽然不算是国内最早一批接触到 Node.js 的开发者,但这一路走来,也是看到了这样一门年轻的技术伴随着不断质疑的发展历程。不够稳定、玩具、只能拿来写写脚本工具、不能做大型项目是常见的社区里的一些声音。
在我看来,对于开发者自身而言:
首先,我们需要去避免拿着锤子找钉子这种自我局限的想法,毕竟任何技术都有其适用和不适用的场景。
其次,Node.js 的社区繁荣和生态蓬勃发展已经证明了她作为一门服务端技术的魅力所在,而且在底层的性能稳定性和故障排查这一层面上,现在已经有了很多的办法去完成我们以前很难做到的一些事情,所以我们对于这门技术本身应该有更多的信心。
在这历程中,朴灵老师组建了 Alinode 团队,专注为阿里数以千计的 Node 应用保驾护航,专治 Node 的各种疑难杂症。
目前我们只是从 0 到 10,未来还有很多很多空白等着我们去填补,如果你有志于此,快来私信勾搭加入我们吧!
## 参考资料

若有收获,就点个赞吧
0 人点赞
