Background
As a front-end veteran, I have to point out that the increasing complexity of front-end projects nowadays makes the dependency installation slower and slower.
At Alibaba and Ant Group, Engineering Productivity is an important metric for engineers, and the speed of installation of front-end dependencies is a big negative impact factor.
We are the team responsible for front-end infrastructure in Ant Group. We mainly focus on building the Node.js community within the company and maintaining many open-source projects like eggjs and cnpm.
We started an initiative in 2021, one of its goals was to optimize the installation speed of dependencies. We managed to speed up the dependency installation by 3 times.
In this article, we’d like to share with you the ideas and results of ‘tnpm rapid mode’.
Thank @sodatea, @nonamesheep, @Sikang Bian(RichSFO), @geekdada so much for the translation of this article, the original article was written by @atian25 and published on Zhihu.

Why is npm soooo slow?
In the modern front-end ecosystem, the number of total modules has been exploding and the dependency graphs are becoming increasingly complex.
- There are a galaxy of modules in the ecosystem. With over 1.8 million npm packages in total, npm has several times as many modules as in other languages by the end of 2021.
- Module relationships are becoming exceedingly complex. Duplicate dependencies and lots of small files are wasting disk space and slowing down disk writes.
The front-end module system prefers small and well-crafted modules. While this brought unprecedented prosperity to the community, it also resulted in complex dependencies which directly led to slower installation. There are trade-offs to be made.
Whether the ecological status quo is correct or not is way beyond the scope of our discussion today, so let’s focus on how to improve installation speed for the time being.
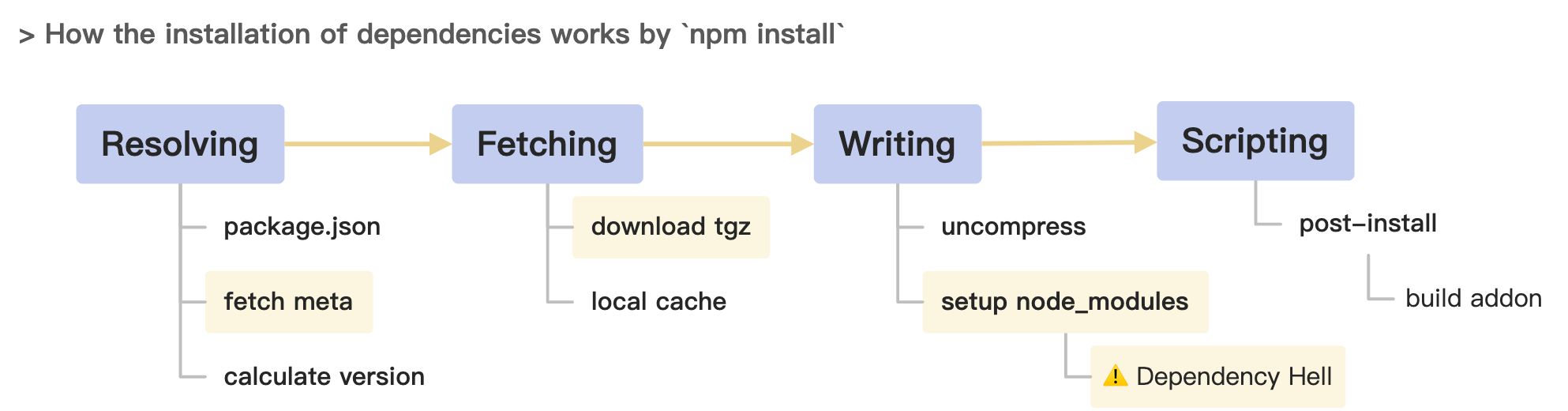
The dependencies installation process for an application is briefly illustrated as above, with the key operations including:
- Query the package information of the child dependencies and then get the download address.
- Download the tgz package locally, unzip it, then install it.
- Create the ‘node_modules’ directory and write the downloaded files under it.
Dependencies Installation
Let’s take vuepress@1.9.2 as an example. It has about 1000 distinct dependencies, taking up 170MB disk spaces with 18542 files.
But if we install the dependencies in a nested way following npm@2’s implementation, we’ll end up installing as many as 3626 dependency packages. There are more than 2000 redundant dependencies. And the actual disk footprint is 523MB with 60257 files.
File I/O operations are very costly, especially for reading/writing large numbers of small files.
npm@3 first came up with an optimization idea to solve the problem of duplicated dependencies + unnecessarily deep hierarchies: the flattening dependency capability, where all child dependencies are slapped flat under node_modules in the root directory.
However, this optimization ended up introducing new problems:
- Phantom dependencies
- NPM doppelgangers. It might still result in several copies of the same package (e.g. there are still 183 duplicate packages in the abovementioned example)
- Non-deterministic dependency structure (though this is solvable via dependencies graph)
- The performance penalty from a complex flattening algorithm
Given so many side effects of the ‘flattening dependencies’, pnpm proposed an alternative solution, by means of symbolic + hard links.
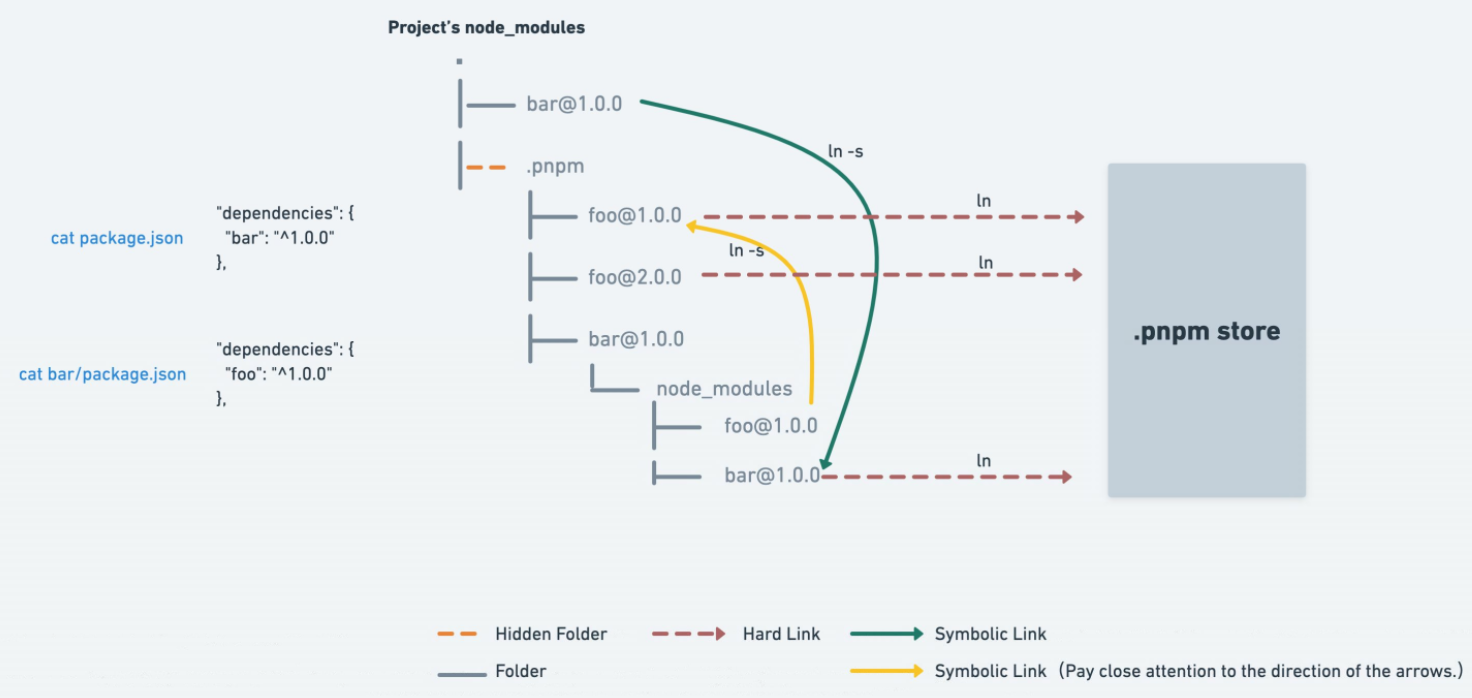
This approach works great because:
- It reduces package duplications while staying compatible with the resolution algorithm of Node.js. The method does not introduce side effects like phantom dependencies, doppelgangers, etc.
- The hard linking approach with global caching reduces file duplication and saves disk footprint.
The resulting data speaks for itself: 1109 modules, 18747 files, 5435 directories, 3150 symlinks, 175M disk footprint.
Similarly inspired by pnpm, we’ve refactored and implemented
cnpm/npminstallin cnpm to utilize symlinks. But it didn’t make use of hard links, neither did it hoist transitive dependencies.
However, it is worth noting that there are some potential issues of this approach:
- We’ve observed symbolic linking could cause indexing problems with dead loops in some IDEs (like WebStorm and VSCode) several years ago. This issue, which might not be fully resolved, should’ve been mitigated with IDE optimizations nowadays.
- Compatibility. Relative paths need to be adapted for plug-in loading logic like EggJS and Webpack as they may not follow the Node.js standard resolving strategy, which looks modules up in the directory structure till the root of the disk.
- The dependencies of different applications are hard-linked to the same file, so modifying the file while debugging may inadvertently affect other projects.
- Hard links cannot be used across the file system. And the implementation of symlinks varies among different operating systems. Moreover, there is still some performance loss due to disk IO on non-SSD hard disks.
In addition, yarn also proposed other optimizations such as Plug’n’Play. Since it is too radical to be compatible with the existing Node.js ecosystem, we will not discuss those optimizations further here.
Metadata Requests
Let’s take a look at the dependencies installation process:
- Each dependency needs one metadata query and one tgz download, resulting in a total of 2 HTTP requests;
- If there are different versions of the same package, the metadata is queried only once, and then the tgz for each version is downloaded separately.
Since the number of dependencies is typically very large, the total number of HTTP requests is subsequently magnified, resulting in a significant increase in time consumption. In the above example, npm@2 will make more than 2500 HTTP requests.
A common optimization strategy is to calculate the dependencies graph in advance, so that package managers can download ‘tgz’s directly without querying the package metadata. As a result, much of the network requests can be avoided.
NPM is the first to come up with the idea of shrinkwrap. It was soon superseded by the idea of lockfile from yarn. There’re similar concepts in pnpm but different formats. Although lockfile was meant to lock the dependency versions, people discovered that the lockfile could also be used as a dependencies graph to speed up installations.
However, there are unsolved problems like:
- The first installation will not speed up unless the lockfile was pre-stored in source code management.
- Locking version would lead to some governance problems in large-scale projects in practice.
A Brief Summary
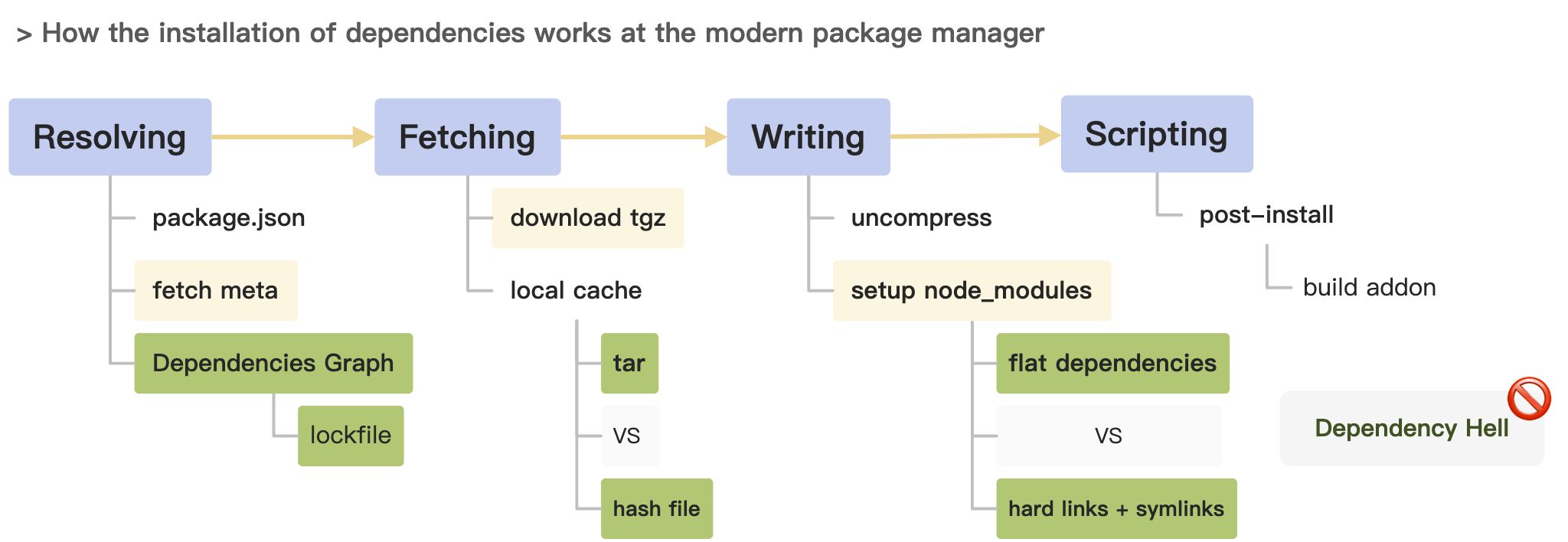
To summarize, to speed up the installation process, we need to think about:
- how to get the dependencies graph faster? (Parsing Strategy)
- how to make tgz downloads faster? (Network I/O)
- how to make to disk faster? How to deal with the duplicated dependencies? (File I/O)
The community was able to reach some common ground where:
- Utilizations of the dependencies graph lead to more efficient concurrent downloads because the requests are better scheduled.
- Simplified node_modules directory leads to less time in File I/O operations because of fewer duplicate dependencies.
- Global caching can reduce the number of download requests.
Still existing problems:
- Lockfile will increase maintenance costs. Neither locking nor unlocking version is a silver bullet.
- Flat dependencies and symbolic links (symlinks in short) have their own compatibility issues.
- There is no consensus on the best implementation of global caching. The “uncompressed copy” approach would generate a lot of file IO, and the hard linking approach would cause potential conflict issues. So there are trade-offs to be made.
What are tnpm and cnpm?
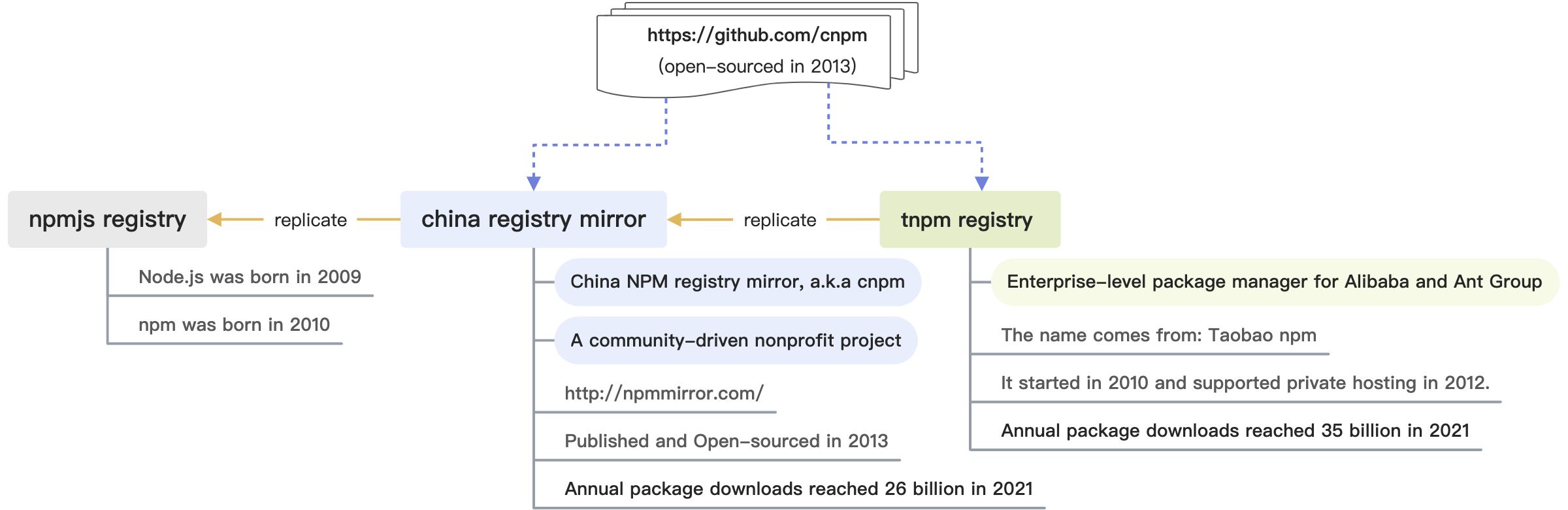
As shown in the above diagram, briefly speaking:
- cnpm is our open-source implementation of npm, which supports mirror synchronization with the official npm registry and private package capabilities.
- npmmirror is a community-deployed project based on cnpm, which provides mirroring services for Chinese front-end developers.
- tnpm is our enterprise service for Alibaba and Ant Group, which is also based on cnpm, with additional enterprise-level customization.
cnpm/tnpm is not only a local command-line interface, but also a remote registry service that allows deeper optimization compare to other package managers.
Optimization Results
Test Scenario
If you can’t measure it, you can’t improve it. - Peter Drucker
| Operating System | Mac mini (M1, 2020) Processor 8 CPUs, Memory 16 GB Linux 5.11.0-rc4+ |
|---|---|
| Test Environment | Node.js v17.1.0 Registry https://registry.npmmirror.com Network ~50MB/s |
| Test Case | vuepress@1.9.5 (1128 transitive dependencies, 60257 files, 523MB disk footprint) Base on https://pnpm.io/benchmarks |
| Candidates | npm@8.2.0 pnpm@6.25.0 yarn@3.1.1 tnpm@8.3.5-alpha.0 |
PS: We are probably the first company in the industry to re-install Mac mini m1 with Linux OS to form a front-end build cluster. This reinstallation itself doubled our overall build speed on top of all the other optimizations.
Test Results
We will not interpret the result for now. You’ll get more in-depth feeling and understanding after we systematically discuss the optimization ideas for tnpm rapid mode.
The Supporting Data
Recall the data we gave earlier at the beginning of our analysis about the reasons behind the overall slowdown. The complete datasets are shown below.
| Package Manager | Disk Footprint | Disk IO | Network IO |
|---|---|---|---|
| npm@2 | 523MB, 61947 files | - | - |
| npm@8.2.0 | 179MB, 19883 files | 102694 syscalls, 28.5s | Speed: max: 5672 KB/s, avg: 1478 KB/s Requests: meta: 997, tgz: 1292 |
| pnpm@6.25.0 | 175MB, 18745 files | 67182 syscalls, 7s | Speed: max: 3882 KB/s, avg: 1152 KB/s Requests: meta: 1128, tgz: 1128 |
| yarn@3.1.1 | 167MB, 18542 files | 271033 syscalls, 34.5s | Speed: max: 5887 KB/s, avg: 1431 KB/s Requests: meta: 1128, tgz: 1128 |
| tnpm@8.3.5 | 125MB, 18542 files | 68957 syscalls,3.3s | Speed: max: 5981 KB/s, avg: 5981 KB/s Requests: meta: 1, tgz: 1128 |
We collect the relevant data, without lock or cache, by strace and charles. We also counted the corresponding file counts and sizes.
Here is the brief interpretation:
- Number of files: the number of ‘flat dependencies’ and ‘symbolic and hard links’ are basically the same. They both reduce the disk footprint significantly.
- Disk IO: an important indicator, the number of file writes is directly related to the installation speed.
- Network speed: reflects whether the installation process can run as full bandwidth as possible, the greater the better.
- Number of requests: includes the number of tgz downloads and the number of query package information. The number can be approximated as the number of overall modules.
From the data, we can see that tnpm is more optimized for both Disk IO and Network IO.
How were the optimizations achieved?
Network I/O
We only have one goal in optimizing the network I/O: how do we maximize the network utilization?
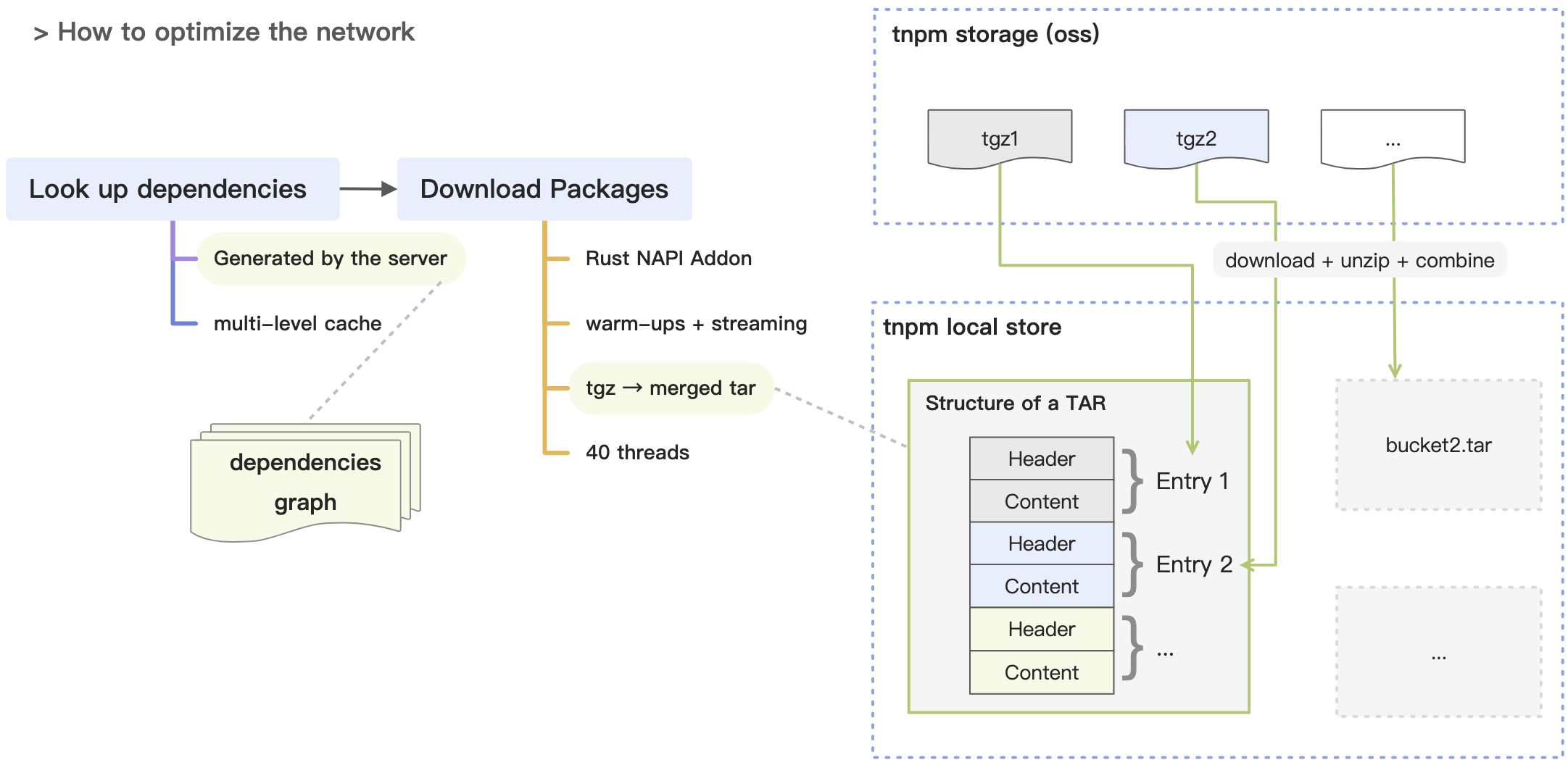
The first optimization comes from ‘dependencies graph’:
- The common practice is using dependencies graph to avoid requesting every package’s metadata on the client-side, thus significantly reducing the number of HTTP requests;
- What’s special in our approach is that: we generate the dependencies graph on the server-side, with a multi-level caching strategy;
- It’s based on
@npmcli/arborist, so it’s npm-compatible.
Our experience and philosophy in our enterprise-scale projects are that we do not advocate locking versions locally but only reuse the dependencies graph from the previous phase in the iteration workflows, such as from development environments to test environments (or emergency iterations). (Locking version vs not locking version is a common topic for debates. There is no common consensus. Finding the respective balance based on the enterprise team’s situation is generally recommended. We will not discuss it here.)
The second optimization is HTTP request warm-ups:
- tgz download process will first visit the registry, and then be redirected 302 to the OSS(Alibaba Cloud Object Storage Service) download address.
- We can improve concurrency by warming up in advance and thus reduce the overall HTTP time consumption.
- It is worth mentioning that we encountered an issue of intermittent DNS 5 second delay.
There’s no such 302 redirection in the official npm registry. We separated the download traffic from the registry by redirecting them to CDN-cached OSS addresses, which improved the stability of the registry service.
The third optimization is to combine the files:
- We found during testing that we could not utilize full bandwidth. Through analysis, we found that: with a huge number of dependency packages, frequent writing small files often leads to file IO bottlenecks.
- Simply extracting tgz files to tar files made it easy to properly merge files when writing to disk, given that tar is an archive file format.
- Repeated testing showed that combining 1000 tgz files into 40 tarball files is ideal.
The fourth optimization is to use Rust to reimplement the download and decompressing process:
- Forty concurrent threads were used to download, decompress and merge the original packages into 40 tarball files, all in a streaming manner.(The value comes from repeated testing)
- Rust was used to implement this feature as an experiment. It showed some potential in decompressing files but not enough to let us believe it’s a silver bullet for solving every performance issue. We used neon to bridge the gap between Rust and Node.js, and planned to rewrite it to napi modules by napi-rs.
FUSE Technology
We believe the original _nested directory _approach is better than the _flattening _node_modules one. But we don’t want the compatibility issues caused by symlinks. How can we hit two birds with one stone?
First, let’s introduce a “black technology”: FUSE (FileSystem in Userspace).
Sounds abstract? Let’s think of an analogy that front-end developers are familiar with: using ServiceWorker to refine and customize HTTP Cache-Control Logic.
Similarly. We can think of FUSE as the file system counterpart of ServiceWorker, from the perspective of front-end developers. We can take over a directory’s file system operation logic via FUSE.
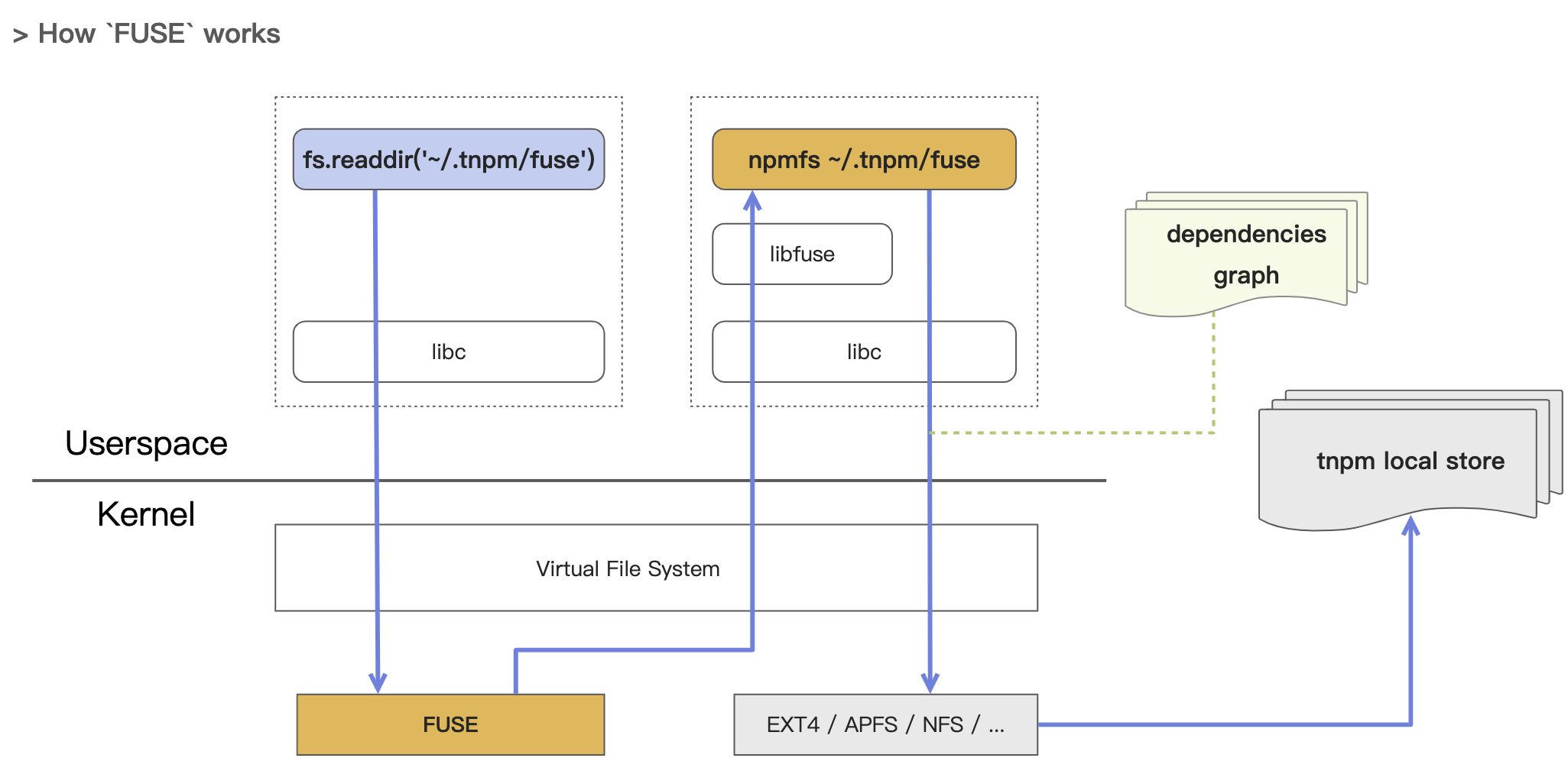
As shown above:
- We implemented the
npmfsas a FUSE daemon on top of nydus, it would mount one directory for one project. - When the OS needs to read the files in that directory, our daemon process would take care of that.
- The daemon process would look up the dependencies graph to retrieve the corresponding file contents from the global cache.
In this way, we were able to achieve that:
- All system calls for files and directories would treat this directory as a real directory.
- Files are independent of each other. Modifications made in one file would not result in changes in other projects (unlike the hard-links approach).
nydus doesn’t support macOS at the moment, so we implemented an adapter of nydus to macfuse. We’ll open source it when it’s ready.
Trivia: Nydus is a Zerg structure in StarCraft, which is used to move units quickly around the map.
OverlayFS
We may need to temporarily modify the code inside node_modules during our day-to-day development for debugging. Editing files within a module can inadvertently lead to changes in another module because of how symbolic and hard linking solutions work.
FUSE supports custom write operations, but the implementation is more verbose. So we directly use a union mount filesystem OverlayFS.
- OverlayFS can aggregate multiple different mount points into a single directory.
- A common scenario is to overlay a read-write layer on top of a read-only layer to enable the read-write layer.
- This is how Docker images are implemented, where the layers in the image can be reused in different containers without affecting each other.
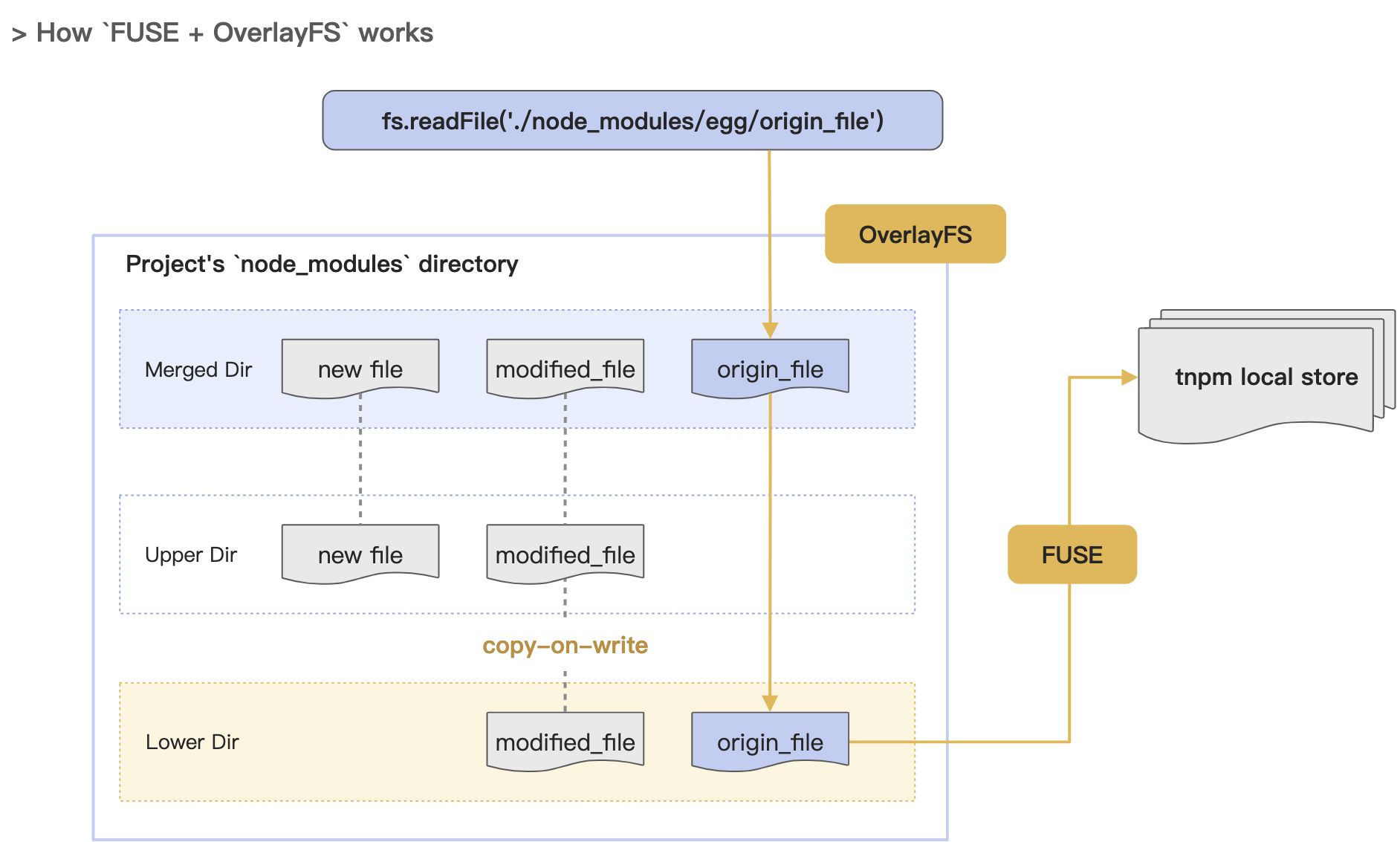
So, we further implement:
- Using the FUSE directory as the Lower Dir of OverlayFS, we construct a read-write filesystem and mount it as the node_modules directory of the application.
- Using its COW (copy-on-write) feature, we can reuse the underlying files to save space and support independent file modifications, isolate different applications to avoid interference, and reuse one copy of the global cache independently.
File I/O
Next, let’s talk about the global cache. There are two main options in the industry:
- npm: Unpack tgz into tar as a global cache, and unpack it into node_modules when installing dependencies again.
- pnpm: Unpack tgz into files, and cache them globally as hash, so that different versions of the same package can share the same file, and hard link it directly when installing again.
What they both have in common is that at some point, the tgz files would be decompressed to standalone files and written to the disk.
When we analyze syscalls by strace, we find that the huge amount of small files generated by decompression can cause a huge amount of I/O operations.
One day, it occurs to us that, maybe we can just skip decompressing? 🤔 🤔 🤔
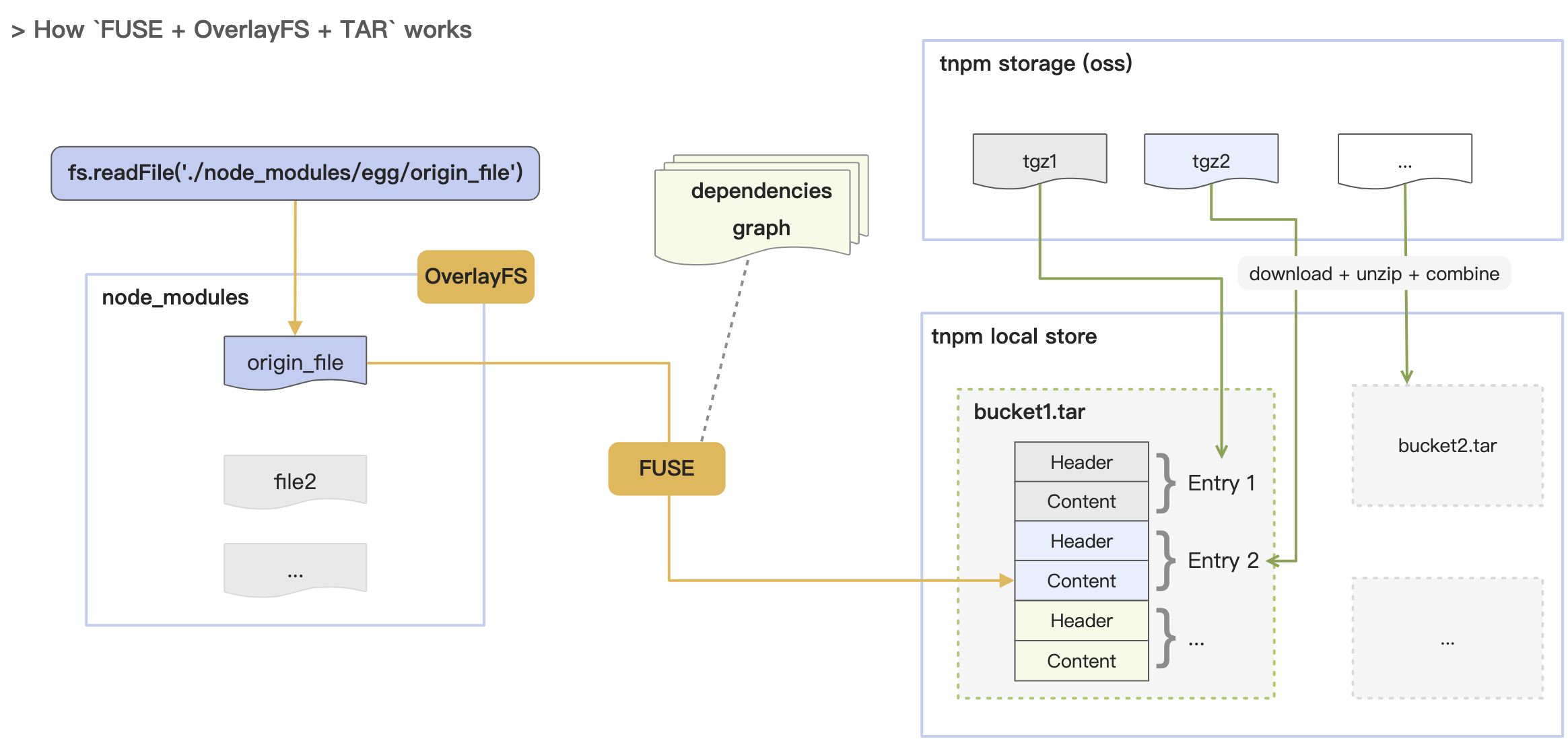
So, we went one step further:
- The node_modules are directly mapped to tar archives via FUSE + dependencies graph, eliminating the need for File I/O operations happened in decompression.
- At the same time, the highly controllable nature of FUSE allows us to easily support both nested directories and flat structures, switching between them on demand.
- Even better: How can we further improve the performance of cloud storage access in the future so that we don’t even have to download tgz?
Some other attempts: we tried to use stargz + lz4 instead of tar + gzip, but the benefits were not significant:
- stargz has more indexing capabilities than tar. But in fact a separate dependencies graph would serve a similar purpose, and there is no need to package them together.
- lz4 has a huge performance gain over gzip, but we have found that the ROI is not high in our current practice.
Extra Costs
No solution can be perfect, and there are some extra costs to our solution.
The first one is the cost of FUSE:
- We need to be aware of the cross-system compatibility issues. Although there are support libraries for every operating system, it takes time to test their compatibility.
- We need to support privileged containers for scenarios used within the enterprise.
- Community scenarios like CI/CD rely on whether GitHub Actions and Travis support FUSE.
The second one is the maintenance burden of the registry server:
- The capability to generate dependencies graph analysis can only be turned on in the private enterprise registry due to server-side resource constraints.
- Public mirror services will fall back to the CLI side to generate a dependencies graph.
PS: Community’s solution, including ours, cannot solve the problem of multiple “require cache” for the same dependency. Maybe it can be solved by ESM Loader but it is beyond our discussion today.
Summary
Key Ideas
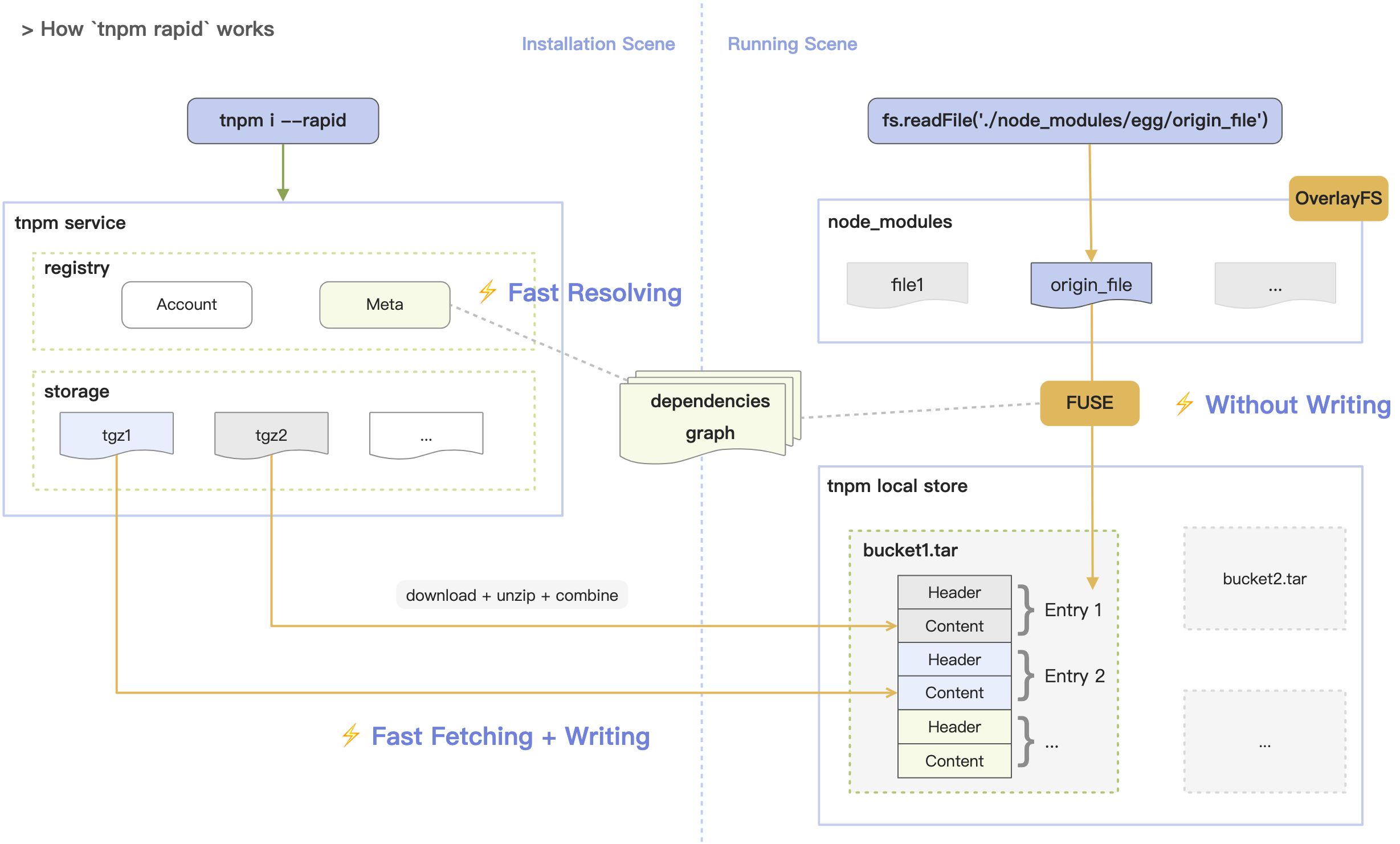
In conclusion, the core advantages of our solution are:
- Network I/O
- Skipping the metadata requests by using server-generated dependencies graph. This saves
Number of packages * Metadata request duration. - The performance gain from using Rust language, and increased concurrency due to download process optimization.
- Skipping the metadata requests by using server-generated dependencies graph. This saves
- File I/O
- Reducing disk writes by storing the combined tar files. This saves
(Number of packages - 40) * Disk operation duration. - Reducing disk writes by not unpacking files but using FUSE mounting instead in the projects. This saves
(Number of files + Number of directories + Number of symlinks and hard links) * Disk operation duration.
- Reducing disk writes by storing the combined tar files. This saves
- Compatibility
- Standard Node.js directory structure. No symlinks, no issues caused by flattening node_modules.
The difference between black magic and black technology is that the former is a pile of “this-is-fine“ dirty hacks to achieve the goal, while the latter is a cross-disciplinary juggernaut to solve challenges once and for all. FUSE is our Dual-vector Foil.(The Three-Body Problem)
Data Interpretation
From the above analysis, one might already fully understand the optimization idea of tnpm rapid mode. Now let’s go back and interpret the data of the previous test results.
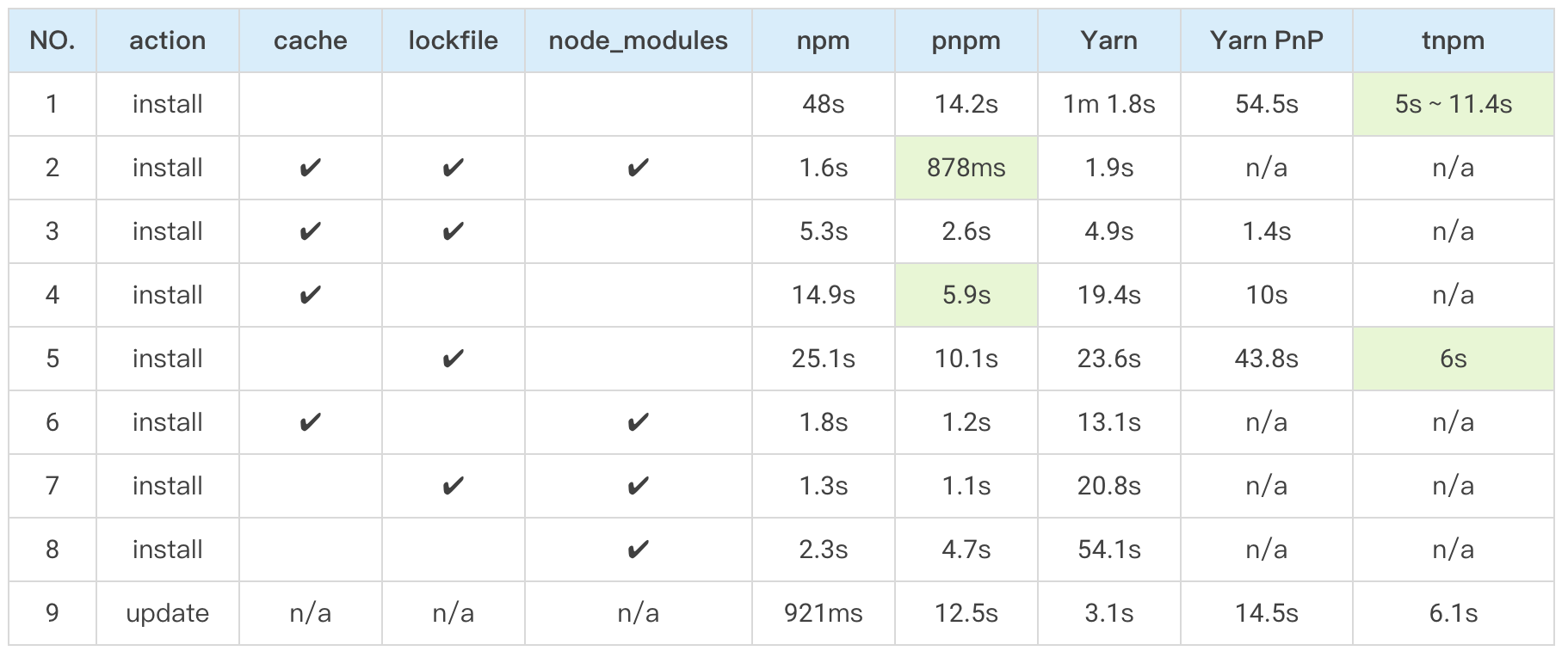
Note: ‘tnpm rapid mode’ is still under small-scale testing, and improvement is expected in future iterations. So the test data is for reference only. Also, yarn in the table is slower than npm@8. We don’t know why for now, but we’ve tested it many times with pnpm benchmark, and the same results kept showing up.
| NO. | action | cache | lockfile | node_modules | npm | pnpm | Yarn | Yarn PnP | tnpm |
|---|---|---|---|---|---|---|---|---|---|
| 1 | install | 48s | 14.2s | 1m 1.8s | 54.5s | 5s ~ 11.4s | |||
| 2 | install | ✔ | ✔ | ✔ | 1.6s | 878ms | 1.9s | n/a | n/a |
| 3 | install | ✔ | ✔ | 5.3s | 2.6s | 4.9s | 1.4s | n/a | |
| 4 | install | ✔ | 14.9s | 5.9s | 19.4s | 10s | n/a | ||
| 5 | install | ✔ | 25.1s | 10.1s | 23.6s | 43.8s | 6s | ||
| 6 | install | ✔ | ✔ | 1.8s | 1.2s | 13.1s | n/a | n/a | |
| 7 | install | ✔ | ✔ | 1.3s | 1.1s | 20.8s | n/a | n/a | |
| 8 | install | ✔ | 2.3s | 4.7s | 54.1s | n/a | n/a | ||
| 9 | update | n/a | n/a | n/a | 921ms | 12.5s | 3.1s | 14.5s | 6.1s |
Here are the brief interpretations:
(1) The time taken to generate the dependencies graph.
- The difference between test 1 and test 5 is the time taken by the corresponding package manager.
- pnpm analyzes the graph by client-side HTTP request, which is about 4 seconds or so (querying package information and downloading are parallel).
- tnpm analyzes the graph by server-side calculation, which currently takes 5 seconds. (when hitting remote cache, this should cost less than 1 second).
- The speed is the same now, but since tnpm has less network latency than pnpm, we still need to optimize this in the future.
In the enterprise scenario, the dependency modules are relatively convergent, so most of the time, the first test of tnpm should take 5 seconds in case of hitting the cache(the dependencies graph generation of tnpm has a caching mechanism).
(2) File I/O overhead
- Test 5 is closer to CI/CD scenarios which have dependencies graph + no global cache.
- The primary time consumption observed was from tgz download time + File IO time. As the tgz download time was alike, the time gap was mainly from file IO.
- What we concluded from the data is that tnpm is 4 seconds faster than pnpm. FUSE helped save the decompress + file write time, as well as the TAR merge time.
(3) Local development
- Both dependencies graph and global cache are made available for local development.
- This corresponds to Test 2 (dependency is not new, second development), Test 3 (second development, reinstallation of dependencies) and Test 4 (first development of new application).
- In principle, time used = dependencies graph update + writing to node_modules file + few package downloads and updates.
- Since tnpm is still under development, we couldn’t test it this time, but from the above formula analysis, tnpm has IO advantage over pnpm.
To summarize: the speed advantage of tnpm over pnpm is 5 seconds for dependencies graph + 4 seconds for FUSE free decompression.
Future planning
Front-end package management has been developing for nearly a decade. Npm was once the trailblazer who kept innovating and advancing this area. However, the advancement was somewhat stagnated after npm won against all the other alternatives like bower. Soon after, Yarn became the challenger and rejuvenated the overall competition, pushing further innovation on npm. Pnpm raised from the new challenge and led the innovation again.
We believe that for front-end dependency optimization and governance, there is still a long way to go. We hope to continue strengthening cooperation with our domestic and international colleagues to keep pushing the advancement of package managers together.
cnpm isn’t trying to be the replacement to the existing package managers. We have always been an enterprise-ready solution for building an on-premise private registry. We don’t recommend developers to use cnpm cli without that specific need. pnpm and yarn are good enough.
npmfs is a package manager agnostic tool by design. We hope it benefits not only cnpm/tnpm but also all the package managers that the community loves.
If the community recognizes the solution we propose, we would love to contribute to other well-accepted package managers. Please stay tuned for npmfs to be open source!
Therefore, our subsequent plan is to give our experience gathered from enterprise-level private deployment and governance back to the community as much as we can.
- After the tnpm rapid model is refined, we will open-source the corresponding capabilities, as well as the npmfs suite. Unfortunately, there’s currently no way for the community to experience it.
- Currently cnpm/npmcore is under refactoring to better support private deployments. (We sincerely welcome contributions from the open source community to further expedite this effort.)
In the meantime, it would be highly beneficial for the community if we could work together to standardize the front-end package management:
- We need a standard like ECMAScript to regulate the behavior of each package manager.
- We need a conformance test suite like “Test262”.
- We should accelerate the transition from CommonJS to ES modules.
- We should find a way to fully resolve the chaotic situation resulting from the deltas among different dependency scenarios of frontend and Node.js.
About me
I’m TZ(atian25), currently work for Ant Group. I am in charge of building and optimizing our front-end Node.js infrastructure. I love open-source and am the main maintainer of eggjs, cnpm.
Node.js is an indispensable infrastructure in the field of front-end. Maybe the future changes of front-end would make all existing engineering problems irrelevant. Nonetheless, no matter what will happen, I just hope that I can seriously record what I see and think in this field. I’d like to exchange ideas with colleagues who are experiencing the evolution of the current “front-end industrialization” and are equally troubled by it.
In the enterprise application scenario, optimization of front-end build execution speed is a system engineering challenge. Dependency resolution and installation is only one of the many challenges we are facing. The opportunities are abundant. We are continuously looking for talented engineers to join us, and keep pushing the innovation forward. We look forward to hearing from you.

若有收获,就点个赞吧
0 人点赞
