MCL01-Introduction
Tianqi Chen开设的暑期课程,主题是机器学习编译,课程网站:https://mlc.ai/summer22/
机器学习的技术在我们的日常生活中得到了广泛的应用,像是计算机视觉(CV),自然语言处理(NLP)和推荐系统(RecSys)等技术已经遍地开花。但是,一个机器学习算法,在它被设计到被部署并应用在真实的生产生活环境的这个过程中,存在着非常大的GAP,平时做实验使用的机器学习算法或许看起来非常美妙,但是要将它们部署在实际的生产环境中是非常困难的,因为可以部署的具体环境千奇百怪(云端,移动端等)。即使是属于同一类别的环境(如云),也有关于硬件(ARM或X86)、操作系统、容器执行环境、运行时库或涉及的加速器种类的问题。
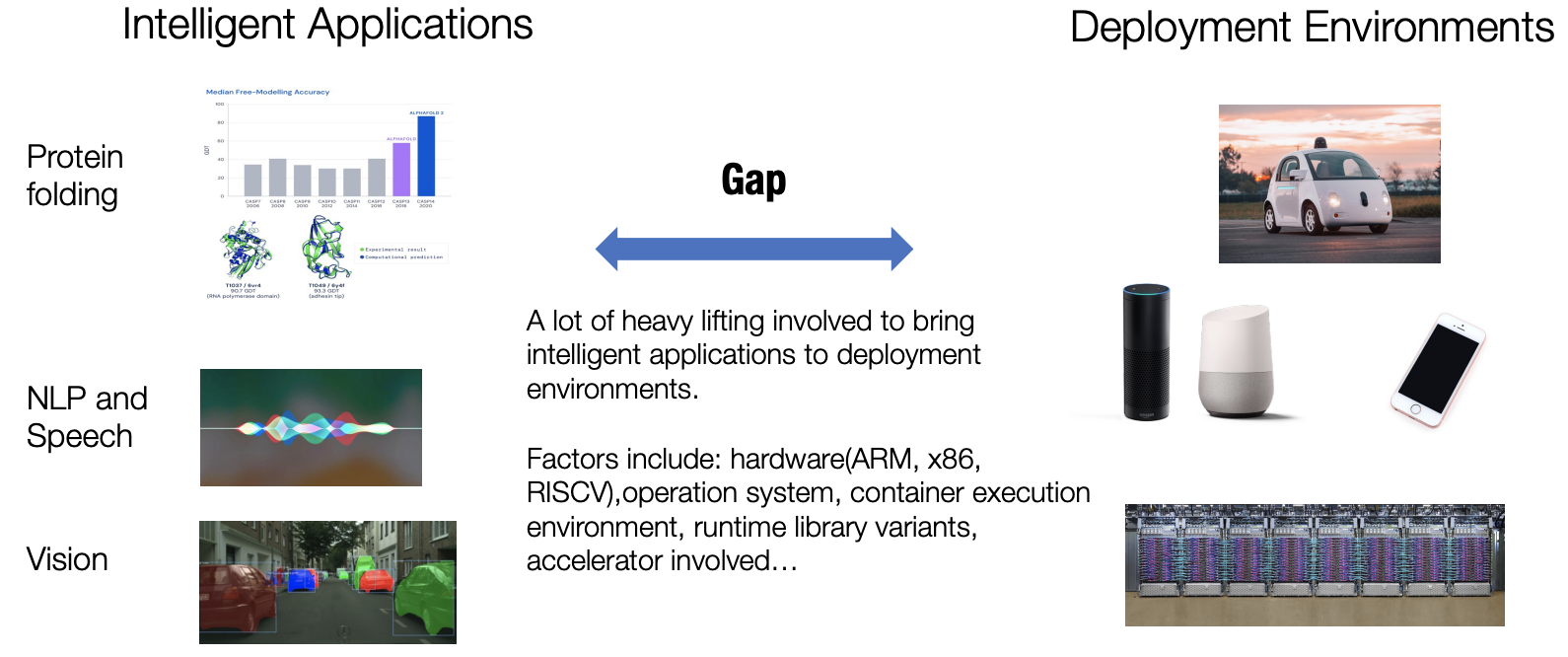
机器学习编译就是一个将处于开发状态的机器学习算法进行迁移和优化,并在部署环境下进行运行的过程。本课程研究将机器学习从开发阶段带到生产环境的课题。我们将研究一系列促进ML生产化进程的方法。机器学习生产化仍然是一个开放和活跃的领域,机器学习和系统社区正在开发新技术。
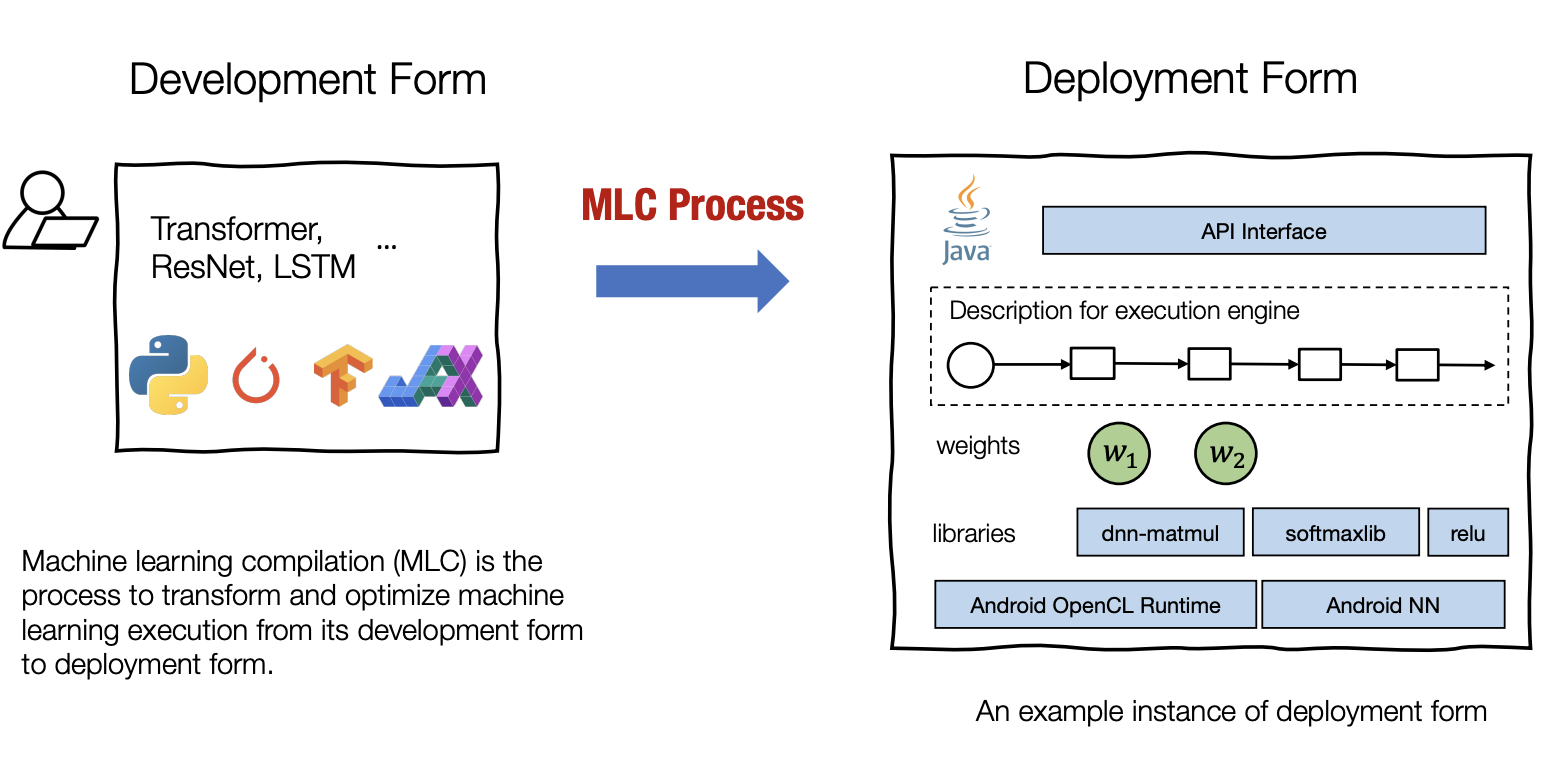
什么是MLC
前面说到MLC是将开发状态的机器学习算法转换成部署状态的过程,开发状态说的就是平时做算法研究的阶段,比如使用PyTorch写出模型和训练的代码,并在标准的数据集上进行测试,这个过程就是算法的开发,而算法的部署状态的是执行机器学习应用程序所需的全部元素。它通常涉及一组生成的代码,以支持机器学习模型的每一步,管理资源(如内存)的例程,以及应用开发环境的接口(如安卓应用的java API)
这门课程名字里的Compilation指的就是机器学习算法从开发状态到部署状态的这个过程(编程语言中的编译往往指的是源代码转换成目标程序的过程),因此要将这门课程里的Compilation和传统意义上的Compilation区别开来。
机器学习编译,往往包含了这样几个关键的目标(这也是我们要在MLC过程中完成的一些事情):
- 集成和依赖性最小化。部署的过程通常涉及到整合—将必要的元素组装在一起用于部署应用程序。组装和最小化必要的依赖关系的能力对于减少整体规模和增加应用程序可以部署的环境的可能数量相当重要。实际上这里说的就是从软件工程的角度来优化算法的总体架构,不要像平时做实验一样代码能跑就行
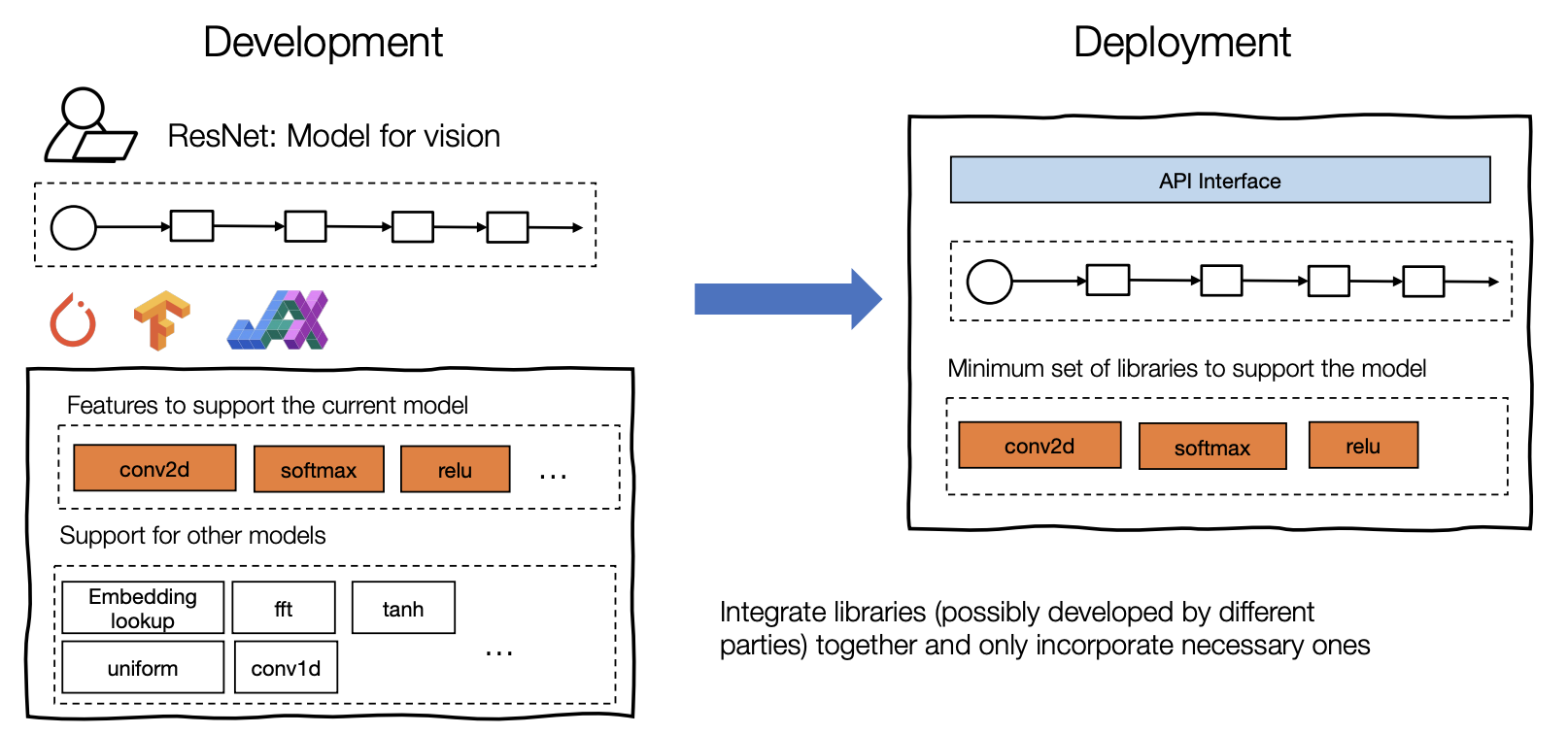
- 充分利用硬件原生加速技术。每个部署环境都有自己的一套原生加速技术,其中许多是专门为ML开发的。机器学习编译过程的一个目标是利用该硬件的原生加速技术。我们可以通过构建调用原生加速库的部署形式或生成利用原生指令(如TensorCore)的代码来实现。

- 一般情况下的优化。有许多等价的方法可以来执行相同的操作。MLC的共同主题是以不同的形式进行优化,以最小化内存使用或提高执行效率的方式转变模型执行。
这些目标之间并没有严格的分界线,很多时候往往互相有交叉。
为什么要学习MLC
这门课程指出了,为什么我们需要学习机器学习编译,主要有这样几点:
学习构建机器学习模型部署的解决方案,MLC提供了一套工具和方法论来解决机器学习算法实际部署时的各种问题,比如减小内存开销,模型推理优化,依赖性最小化等
深入理解已有的框架,常见的机器学习框架(如PyTorch)中越来越多地开始集成MLC的模块,通过学习MLC可以更深入地理解这些框架背后的设计理念和准则
为新的硬件构建软件栈,通过学习MLC,我们可以学会如何在新型的硬件上开发一套机器学习的软件栈,来部署具体的机器学习算法
它(指MLC)很有趣
MLC中的关键元素
在MLC中最关键的两个元素就是张量以及张量的操作函数,张量是存储了输入输出以及模型中间结果的多维数组,而操作函数是一些针对具体张量的运算方式,比如投影、卷积、激活函数。

上面这张图片的例子是一个简单的MLP在部署时候的例子,虽然前一种方式到后一种方式的转化过程中,第一个线性层和RELU函数进行了组合,也就是说,这里采用了两种不同程度的抽象。
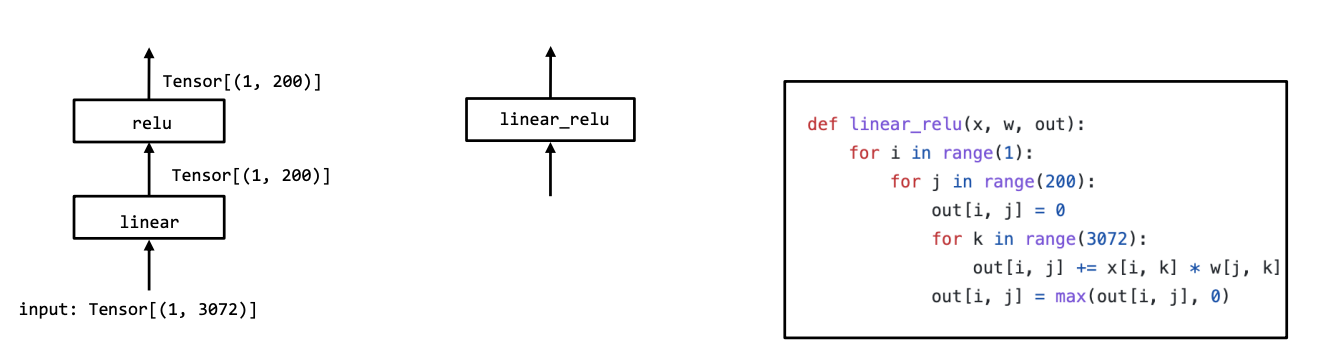
在MLC中,抽象是一个非常重要的概念。抽象指定了 “做什么“,而实现提供了 “怎么做“。没有具体的界限。根据我们的看法,for循环本身可以被看作是一个抽象,因为它可以用python解释器实现,也可以编译成本地汇编代码。
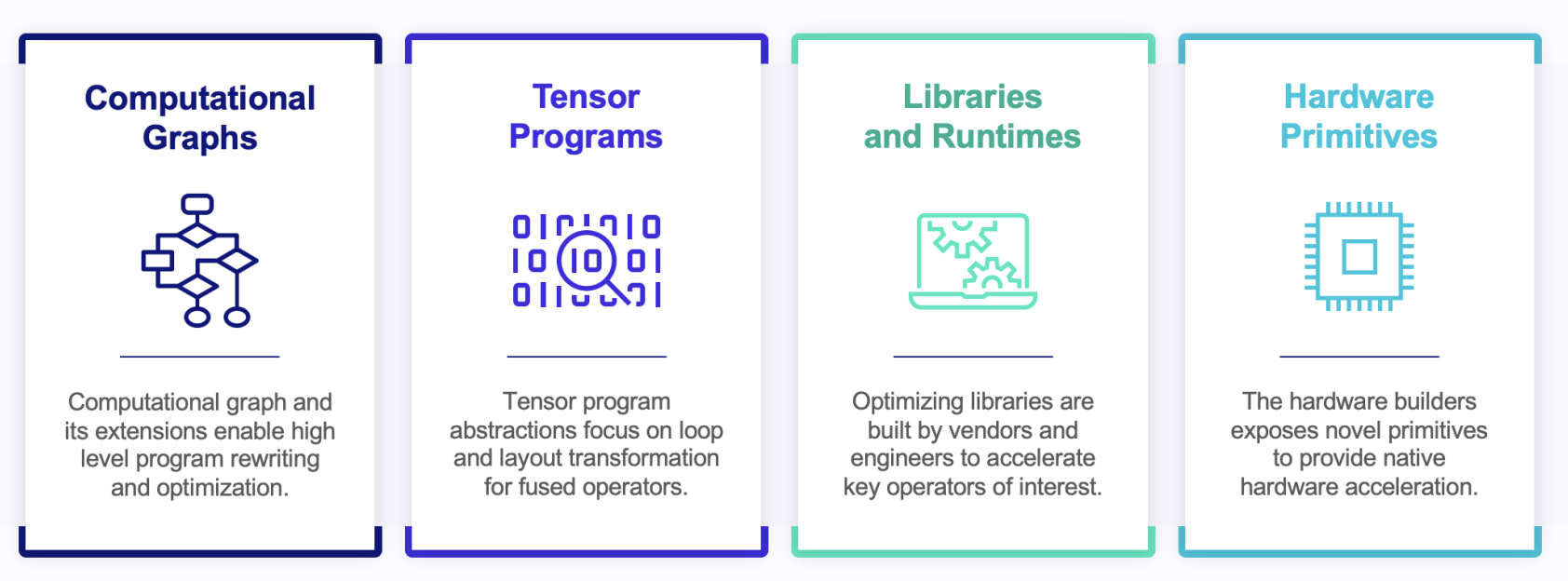
MLC实际上是一个在相同或不同的抽象下对张量函数进行转换和组装的过程。我们将研究张量函数的不同种类的抽象,以及它们如何共同解决机器学习部署中的挑战。我们后续将接触到四种不同级别的抽象:
- 计算图
- 张量规划
- 库和运行时
- 硬件原语

若有收获,就点个赞吧
0 人点赞
