摘要
由于其高速和可扩展性的特性,覆盖引导的灰盒模糊是发现漏洞的最流行和最有效的技术之一。然而,现有的技术通常关注代码覆盖率,但不关注易受攻击的代码。这些技术旨在覆盖尽可能多的路径而不去探索更容易受到攻击的路径。在选择要测试的种子时,现有的模糊测试通常相同地对待所有种子输入,而忽略了不同种子输入所执行的路径易受攻击的程度不同。这会浪费时间测试无用的路径而不是易受攻击的路径,从而降低漏洞检测的效率。在本文中,我们提出了一个解决方案,NeuFuzz,使用深度神经网络来指导灰盒模糊过程中的智能种子选择,以减轻上述限制。特别是利用深度神经网络从大量易受攻击的干净程序路径中学习隐藏的脆弱性模式,训练出一个预测模型,对路径是否易受攻击进行分类。然后,模糊器将能够覆盖可能是脆弱路径的种子输入进行优先排序,并为其分配更多的变异能量(即,要生成的输入数量)。我们实现了一个基于现有PTfuzz(一种基于硬件机制(Intel处理器跟踪)的greybox模糊方法,该方法支持二进制程序,就像仿真方法一样,同时它获得了与编译时插装方法相当的性能。)的NeuFuzz原型,并在两个不同的测试套件:LAVA-M和九个实际应用程序上对其进行了评估。实验结果表明,NeuFuzz能在较短的时间内发现比现有模糊算法更多的漏洞。我们在这些应用程序中发现了28个新的安全漏洞,其中21个在CVE中分配了id。
索引词:模糊测试,漏洞检测,深度神经网络,种子选择,软件安全
1.介绍
程序中隐藏的安全漏洞可能导致系统受损、信息泄漏或拒绝服务。正如我们从最近许多备受关注的漏洞攻击中看到的,如Heartbleed攻击[1]和WannaCry勒索软件[2],这些漏洞通常会在财务和社会上造成灾难性影响。因此,程序中的安全漏洞在被攻击者发现之前必须被识别并消除,以避免潜在的攻击。自20世纪90年代初引入模糊测试以来,它已经成为发现商业软件中的漏洞、错误或崩溃的最有效和可伸缩的测试技术之一。谷歌[4]和微软[5]等主流软件公司也广泛使用它,以确保其软件产品的质量。
模糊化的关键思想是向被测程序(PUT program under test)提供大量精心编制的输入,以触发意外的程序行为,如崩溃或挂起。根据对被测程序(PUT)内部结构知识的理解,模糊测试可以分为白盒、黑盒和灰盒。白盒模糊测试(如[6],[7])通常可以访问PUT的源代码或中间表示。其通常使用重量级的程序分析方法(如符号执行和路径遍历)来指导模糊化,因此存在可伸缩性问题。黑盒模糊测试(例如8、[9])完全不知道程序的内部结构,通常盲目地执行随机测试,因此效率极低。灰盒模糊测试(例如,[10]-12])的目标是一个折衷方案,它使用轻量级的程序分析方法(例如,仪器)从程序中获取反馈来指导模糊化,这通常比黑盒模糊测试更有效,比白盒模糊测试更具可伸缩性。
近年来,以代码覆盖率为反馈的覆盖导向灰盒模糊算法(CGF coverage-guided graybox fuzzing)已成为最成功的漏洞发现方法之一。这种类型的模糊器逐渐增加了代码覆盖率,并增加了发现漏洞的概率。AFL[10]、libFuzzer[11]和honggfuzz[12]是最先进的灰盒模糊器,已经引起了业界和学术界的关注,并发现了数百个引人注目的漏洞[13]。一般来说,这些方法使用轻量级分析对被测程序(PUT)进行测试,以提取每个执行的测试用例的覆盖率信息。如果一个测试用例执行了一个新的分支,那么这个用例被标记为感兴趣的;否则,这个用例被标记为无用的。在接下来的模糊迭代中,有趣的测试用例被重用为种子,以进行变异并为模糊测试生成新的测试用例。
尽管它在漏洞发现方面取得了相当大的成功,但我们发现CGF模糊器(例如AFL 编译时插装)有一个限制。当前的模糊检测旨在覆盖尽可能多的路径,而不是探索更容易受到攻击的路径。他们按照种子添加的顺序从种子队列中选择种子,并且在所有程序路径上平均花费测试能量。然而,不同的路径具有不同的脆弱概率。如[14]所述,程序中的错误分布通常是不平衡的,即大约80%的错误位于大约20%的程序代码中。因此,现有的CGF模糊器浪费了大量时间来测试无用的(即不易受攻击的)路径,从而降低了模糊化的效率。直观地说,使用更容易出错的程序路径的测试用例更容易触发错误,因此我们应该在这些路径上花费大部分的模糊工作,以增加在测试期间触发漏洞的可能性。
本文提出了一种新的路径敏感的灰盒模糊解决方案NeuFuzz,以缓解上述局限性。它应用了一种新的种子选择策略,该策略优先考虑那些更可能使用易受攻击路径的种子,并相应地为这些种子分配更高的测试能量(例如,要生成的输入数量),以提高脆弱性检测的效率。核心挑战是如何确定一条路径是否可能脆弱。在图像和语音识别取得巨大成功的启发下,我们利用深层神经网络来学习脆弱程序路径的隐藏模式,并识别出脆弱路径来指导种子的选择。具体来说,预测模型是从大量易受攻击且干净的程序路径中学习而来,然后用于在模糊化过程中对执行路径中是否存在漏洞进行分类。因此,模糊器优先处理由神经网络确定的易受攻击路径的种子,并为这些种子分配更多的变异能量,以最大限度地提高错误发现效率。
基于深层神经网络的NeuFuzz智能选种比最先进的模糊检测更有效。我们实现了一个基于AFL(例如:PTfuzz)的扩展,NeuFuzz的原型。我们在两个不同的测试套件上评估NeuFuzz。第一个是LAVA-M[16]基准测试,它包含四个带有手动注入漏洞的Linux程序;另一个是一组具有不同复杂性和功能的真实应用程序(即libtiff、binutils、libav、podofo、bento4、libsndfile、audilfile、nasm),这些程序通常被一些广泛使用作为第三方库使用的程序。实验结果表明,NeuFuzz比PTfuzz和QAFL[17]能在更短的时间内发现更多的漏洞。
总之,我们作出了以下贡献:
- 我们提出了一种新的种子选择策略,该策略优先考虑种子利用脆弱路径来提高脆弱性发现的效率。
- 我们提出了一种新的深度神经网络解决方案来预测哪些程序路径是脆弱的。
- 我们实现了NeuFuzz原型来对二进制程序进行模糊化,并用精心设计的基准和真实世界应用程序对其进行了评估,证明了该解决方案的有效性。
- 我们在一些广泛使用的实际应用程序中发现了21个CVE和7个未知的安全漏洞,有助于提高供应商产品的安全性。
本文的其余部分安排如下。第二节介绍了本文的研究背景和相关工作。第3节描述了NeuFuzz的概述。第四节详细介绍了NeuFuzz的技术细节。第五节介绍了NeuFuzz的实现和实验评价结果。第六节对论文进行总结。
2.研究背景和相关工作
近年来的研究从覆盖跟踪、种子选择、种子变异等方面,实现了程序分析、机器学习等多种助推技术,提高了CGF的效率和有效性。
A.硬件反馈模糊化
PTfuzz是一种具有硬件反馈的灰盒模糊器,也是基于AFL的。它使用CPU硬件机制Intel PT(Intel Process Tracer)[18]来收集分支信息,而不是编译时检测(例如,由AFL的gcc模式使用的)或运行时检测(例如,由AFL的QEMU模式使用的,表示为QAFL)。Intel PT是Intel体系结构的扩展,它能够以最小的性能开销精确跟踪程序控制流信息。因此,与QAFL相比,该模糊器不依赖源代码,在不损失覆盖跟踪精度的情况下获得了更高的性能。另一项最新的研究KAFL[19]也是基于AFL和Intel-PT实现的,它支持ring0中的内核模糊。我们的原型是基于PTfuzz实现的,因为我们的测试目标是ring3中的二进制程序。
B.种子选择策略
种子选择策略是灰盒模糊算法的关键。一个好的种子选择策略可以提高路径遍历和漏洞检测的能力。AFL采用一种简单的种子选择策略,即选择更小更快的种子,在给定的时间内生成和测试更多的测试用例。Rawat等人[20]对运行更深路径的种子进行了优先排序,对运行错误处理块和高频路径的种子进行了去优先排序,因此很可能会对难以到达的路径进行测试,并避免无用的错误处理路径。AFLFast[21]优先考虑使用低频路径和较少被选择的种子,因此冷路径可能会被彻底测试,在热路径上浪费更少的能量。AFLGo[22]对更接近预定目标位置的种子进行优先排序,从而达到定向模糊的目的。CollAFL[23]使用了三种新的种子选择策略,将模糊器直接推向未探索的路径,并更快地提高代码覆盖率。Angora[24]优先考虑路径包含条件语句且分支未探明的种子,这使得在探索高频路径之后,可以专注于低频路径。
现有的种子选择策略主要集中在执行速度、路径频率、路径深度和未遍历的路径分支上。本质上,它们关注的是代码覆盖率,而不是指导模糊测试容易出错的路径或代码。因此,现有的种子选择策略浪费了大量的时间来测试不感兴趣的路径,从而降低了模糊化的效率。本文的重点是解决这个问题。
C.种子变异策略
AFL将输入视为连续的二进制字节序列,因为无法感知输入的结构。这种随机变异策略使得完全靠运气找到新的路径或分支成为可能。为此,研究人员在多种程序分析方法的基础上提出了许多改进方案。Stephens等人。[25]结合了模糊化和符号执行的优点来检测漏洞。具体地说,当模糊检测被困在一些复杂的比较分支(如幻数字节)中时,使用共同执行生成测试输入,可以驱动执行通过检查,但它局限于符号执行的可伸缩性差,因此,模糊器很难应用到实际应用中。Lietal[26]使用轻量级运行时检测方法来监视比较指令或函数,并根据进度反馈信息指导变异,以生成可以通过分支的输入字节。T-fuzz[27]通过直接修改二进制程序来删除一些复杂的分支检查(例如,幻数字节、校验和和散列)。当发现崩溃时,使用符号执行技术来消除误报并在原始程序中重现错误。Rawatetal[20]使用静态分析来推断感兴趣的值,然后使用污染分析来确定比较指令的输入偏移量,以便这些偏移量由推断值进行变异,以传递一些复杂的条件。Chen和Chen[24]使用梯度下降算法而不是符号执行来引导变异来提高覆盖率。
我们可以看到,所有这些方法都是为了通过突破程序中的一些复杂条件检查来提高代码覆盖率。这些方法与本文提出的方法是正交的,我们可以将它们集成到我们的工具中。
D.基于学习的漏洞检测
最近,研究人员开始应用人工智能技术来辅助脆弱性检测。Learn&Fuzz[28]使用神经网络学习基于语法的模糊化文件输入格式的生成模型。增强AFL[29]使用神经网络从过去的模糊中学习一个函数来预测种子文件中执行突变的好位置。Bóttinger等人。[30]使用最先进的Q学习算法优化奖励,并学习为特定程序输入选择高奖励变异操作。Li等人。[31]提出了一种基于深度学习的漏洞检测方法VulDeePecker,该方法不需要手工定义漏洞特征,但该方法需要源代码,只能检测与库函数相关的漏洞。VDiscover[32]将程序的动态和静态API序列作为特征提取出来,并使用传统的机器学习算法训练模型来预测未知程序中的漏洞。但是,由于API序列不能很好地表示漏洞特征,因此其准确性不高。
综上所述,一方面,现有的模糊机器学习方法主要用于指导种子的产生和变异,以达到较高的代码覆盖率。另一方面,机器学习直接应用于脆弱性预测,本质上是一种静态分析方法,需要人工验证。我们的工作利用脆弱性预测结果来指导模糊过程的种子选择。据我们所知,我们是第一个使用深层神经网络来学习模糊化过程中种子输入覆盖的有趣路径的人。
3.概述
在这一部分中,我们将通过一个激励性的例子进一步解释我们需要解决的问题,并对我们的方法进行概述。
A.激励性例子
如前所述,现有模糊算子的种子选择策略大大降低了脆弱性检测的效率。为了清楚地说明种子选择策略如何使AFL难以在PUT中找到漏洞,请考虑图1中的代码。图1(a)是源代码,图1(b)是对应的进程间控制流图。以字符“2”开头的输入字符串超过32个字符将导致代码的第9行出现堆栈溢出。请注意,这个示例相对简单,为了方便起见,我们在源代码中显示它。实际上,我们的方法可以直接应用于二进制程序。
给定初始种子输入“fuzz”,AFL可以快速找到图1(b)的控制流图中所示的其他三条路径,假设执行这些路径的测试用例是“0aaa”、“1bbb”和“2ccc”。然后AFL将按照图1(c)所示的添加顺序对每个测试用例执行突变。然而,种子输入0aaa、1bbb和3ddd所执行的三条路径(分别用红色、黄色和黑色线表示)显然不太可能存在漏洞;因此,模糊化它们的重要性非常低,种子输入2ccc所执行的路径(用蓝色线表示)易受攻击,对模糊化更有意义。而且为了触发路径中的潜在漏洞,种子应该比其他种子模糊更多次。事实上,实际程序比这个示例更复杂,通常包含更健全的检查和路径分支。假设一个程序执行n(n>1000)条路径,并且只有一条路径存在漏洞,那么我们的方法的优点很明显:我们可以首先测试易受攻击的路径,以便尽早暴露漏洞,而不是浪费大量时间测试其他n-1条路径。
我们的想法是使用一种种子优先策略来保证更好的种子将首先被测试,并用更多的变异能量进行变异,从而提高模糊器的效率和有效性。因此,我们需要考虑并解决以下三个启发式问题。
1.如何推断种子输入是否优于其他输入?
种子输入的重要性取决于对它所走的道路的兴趣程度。例如,AFLFast认为,从代码覆盖率的角度来看,触发低频路径的种子更好。然而,在本文中,如果它的执行路径更有趣(即路径更容易受到攻击),那么我们认为首先测试这个输入会更好、更有意义。显然,专注于测试执行可能是易受攻击路径的种子将增加触发漏洞的可能性。例如,在图1所示的示例中,种子2ccc所覆盖的路径是脆弱的,因此应该首先对该种子进行模糊处理并进行多次测试。值得注意的是,如果一个种子运行一个易受攻击的路径,则无法保证该路径中隐藏的漏洞肯定会由该种子的突变触发。然而,从这个种子变异肯定会增加触发隐藏漏洞的概率。
2.如何确定一条路径是值得关注的,即更容易受到攻击?
我们知道示例中的蓝色路径(2ccc)中存在缓冲区溢出漏洞,该漏洞在未进行任何安全检查的情况下调用危险的strcpy函数。传统的自动发现漏洞的方法需要依赖于特征数据库。然而,在实际应用中,脆弱性条件比直接建模要复杂得多。提取特征来刻画脆弱性是一个挑战;因此,我们不依赖基于专家经验的传统脆弱性特征来确定路径是否存在脆弱性。相反,我们依靠一个深度神经网络来自动提取脆弱性的特征,从大量的训练数据中学习脆弱性模式,并识别其他感兴趣的脆弱路径。
3.如何在不丧失性能优势的情况下将我们的方法应用于现有的二进制模糊器?
基于学习的神经网络模型,可以指导灰盒模糊算法的种子选择。因为CGF的吸引力在于它的速度,所以在实现该策略时,应该限制对fuzzer引入性能开销。因此,我们考虑了一些支持二元模糊的现有模糊器,包括AFL-PIN[33]、Vuzzerand PTfuzz,但是前两个工具的实现依赖于动态仪表PIN[34],这可能会产生大量成本,因此违反了我们的原则。如前所述,PTfuzz与QAFL相比有很大的性能改进,它依赖于Intel PT来支持执行控制流跟踪,这有助于将程序执行路径作为输入恢复到模型中,而无需依赖昂贵的方法,如动态检测。因此,我们选择基于PTfuzz实现我们的方法。
B.方法概述
为了解决上述现有灰盒模糊器的局限性,我们提出了NeuFuzz,如图2所示,它由离线模型训练和在线引导模糊两个阶段组成,分别对应于图2(a)和图2(b)。这两个阶段都需要使用Intel PT的CPU提供硬件支持。在离线模型训练阶段,输入的是大量的二进制程序,包括易受攻击程序和非易受攻击程序。易受攻击的程序意味着它包含一个或多个已知漏洞,而非易受攻击的程序意味着已应用修补程序修复该漏洞。输出是一个学习的预测模型,用于分类未看到的程序路径中是否存在漏洞。在在线引导模糊化阶段,我们将预测模型集成到一个灰盒模糊器中,在将种子加入到这些edqueue之前,通过对其执行路径的脆弱性预测来确定种子的优先级和变异能量。然后,模糊器根据种子队列的优先级选择种子输入。这一过程使种子选择更加智能。
有两点需要注意。首先,我们不会丢弃不覆盖我们的模型所识别的脆弱路径的种子。我们仍然将这些种子添加到种子队列中,原因有二:一方面,从fuzzer的代码覆盖率来看,这些种子仍然是有价值的,因为对它们进行模糊处理可以发现新的路径;另一方面,我们的模型预测精度不能保证为100%,因此我们不能错过发现这些漏洞的机会,即使是如果概率低得多。其次,虽然训练神经网络需要时间,但在应用于所有应用程序之前,我们只需要训练一次网络。另外,我们在主模糊环中加入了路径恢复和脆弱性预测,这当然会导致额外的开销,但是我们的实验表明,这两个模块的开销非常低,可以接受。
4.实现
在这一部分中,我们描述了基于PTfuzz的NeuFuzz的关键技术细节,我们的方法与之前研究人员提出的提高代码覆盖率的方法是正交的。
A.离线模型训练
如图2(a)所示,该阶段有四个步骤。首先,我们收集训练程序,包括易受攻击的版本和非易受攻击的版本,用于神经模型训练。其次,使用概念证明(POCs)作为这些程序的输入。利用Intel-PT的控制流跟踪能力,我们可以得到两种类型的程序路径:易受攻击的和干净的。第三,在训练前将这些路径转化为向量表示作为神经网络的输入。第四,根据神经网络对大量训练数据的特征学习能力,建立了在线模糊阶段指导种子选择的预测模型。
1)收集训练程序
鉴于程序的复杂性和多样性,需要大量的训练实例来训练机器学习模型,以便直接从代码中有效地学习安全漏洞的模式。另外,由于我们需要动态运行程序来获得执行路径,我们需要一个可以执行的二进制程序和相应的测试用例。然而,据我们所知,不存在公开可用的完整二进制程序数据集。尽管VulDeePecker提供了一个数据集[35],但只包含源代码,并且没有为程序执行提供测试用例。
我们从三个数据源构建了第一个二进制数据集:NIST SARD项目[36]、GitHub[37]和Exploit DB[38]。NIST SARD项目包含许多合成程序,每个程序都有一个好(补丁后)和坏(补丁前)程序,并涵盖各种类型的CWE(常见弱点枚举),我们选择内存损坏漏洞,如堆栈溢出(CWE121)、heapoverflow(CWE122)、整数溢出(CWE190)、UAF(CWE416)等。我们最终从SARD收集了26080个二进制程序,每个程序都有一个补丁前和补丁后版本。然而,SARD中的程序是合成的,因此它们的漏洞可能不同于实际应用中的漏洞,这可能会限制我们模型的可伸缩性。因此,我们还从GitHub收集实际应用程序(如ImageMagick、libtiff和bintuils)并利用DB。GitHub可以跟踪对源文件的更改,我们可以通过检索应用程序主分支的提交历史和从公共存储库(如bugtracker和GitHub问题)抓取poc来确定每个bug的修补前和修补后版本,以验证和保留可以触发bug的测试用例。我们最终从Github收集了560个应用程序。另外,我们从漏洞数据库中收集了1039个易受攻击的程序和相应的poc。
如图1所示,我们在数据集中收集了28475个易受攻击的二进制程序和27436个非易受攻击的二进制程序,用于神经网络训练和测试,以及可以触发易受攻击路径和干净路径的测试用例。
2)提取执行路径标注地面真相
利用所构造的数据集和POCs,我们可以通过在训练和预测两个阶段执行程序来提取程序的执行路径。最常用的方法是使用Pin动态检测来提取执行路径,但这种方法会导致较高的开销,降低模糊器的执行速度,特别是在在线引导模糊阶段。因此,我们使用Intel PT技术提取路径,这将在B节的第一部分中详细说明。程序执行路径的每条指令都以字节码形式记录,并且我们不会跟踪系统库函数中的指令并保留库函数名(例如。,strcpy和memcpy)与路径跟踪过程中的漏洞特性相关,减少了路径中记录的指令数量,同时尽可能保留了漏洞语义。
下一步,我们给地面真相贴上标签。VulDeePecker保守地认为,只要代码中没有发现漏洞,代码就不易受攻击;实际上,这种假设并不成立。我们假设修补后的代码是不易受攻击的;因此,相比之下,基本事实更为准确。可使用POC作为输入执行易受攻击和不易受攻击的程序,以获取易受攻击的路径(标记为“1”)和干净的路径(标记为“0”)。最后,从我们构建的数据集中提取出27820条脆弱路径和26871条干净路径,其中4/5用于训练,其余1/5用于测试。
3)将执行路径转换为向量表示
在将由指令字节码组成的程序执行路径作为深层神经网络的输入之前,需要将路径转换为向量表示,同时尽可能保留执行路径的原始语义信息。我们可以通过一种文本处理方法来学习:一条路径可以看作是一个句子,路径中的每一条指令可以看作是句子中的一个单词。因此,我们必须执行单词嵌入,其中one-hot[39]和word2vec[40]是常用的方法。one-hot将第i个指令表示为一个向量,其元素设置为1,其他元素设置为0。例如,如果有5条指令,则第二条指令的向量表示为[0,1,0,0,0]。但是,该方法不包含任何语料信息,而且所有单词之间的距离是相同的。Word2vec 根据上下文来表示向量,关联度高的词有更近的距离,因此,从数据的内在特征来看,Word2vec更具表现力。因此,我们选择word2vec进行单词嵌入。
每个指令的十六进制字节码被视为一个令牌,例如,0x890424表示mov[ebp],eax;然后,字节码序列被word2vec训练。输出是256维空间中每条指令的矢量表示。然后,我们可以将执行路径转换为每条指令的矢量表示,如图3所示。
很明显,不同路径的长度是不相等的,而且变化很大。这种路径很难输入到深层神经网络结构中。因此,我们将路径的最大长度设置为n。短于n的路径从其后端填充0。而大于n的路径则从其前端截断,因为新触发的路径分支通常位于路径的末端。当填充到元素X1,X2,…,Xn(Xi是每个指令的矢量表示)的固定长度时,一条路径的输入序列可以表示为X1:n=X1⊕X2⊕。。。⊕Xn,其中⊕是连接符。
4)神经网络模型的训练
在该步骤中,从包含大量易受攻击和干净路径的训练数据中学习隐藏漏洞模式。我们选择长短期记忆(LSTM)神经网络作为训练对象,输出一个模型,用于对模糊过程中触发的不可见路径进行分类。一方面,LSTM擅长处理顺序数据:程序路径与自然语言中的语句非常相似,一段代码是否易受攻击取决于上下文。另一方面,LSTM有一个适合处理长依赖关系的内存函数,因为与该漏洞相关联的代码可能位于路径中相对较长的距离。
我们基于LSTM的神经网络由4层组成,如图4所示。第一层是嵌入层,它将序列中的所有元素映射到一个固定的维向量。第二层和第三层是层叠的LSTM层,每一层都包含64个双向形式的LSTM单元,层叠的LSTM模型可以学习更高层次的时域特征表示。最后,我们使用一个具有单个神经元和sigmod激活函数的密集输出层来对任务中的两类进行预测。我们的损失函数是二元交叉熵,优化器是adam,并且由于LSTM经常遭受过度拟合,我们使用dropout来解决这个问题。当辍学率设为0.6时,我们的模型取得了最好的结果。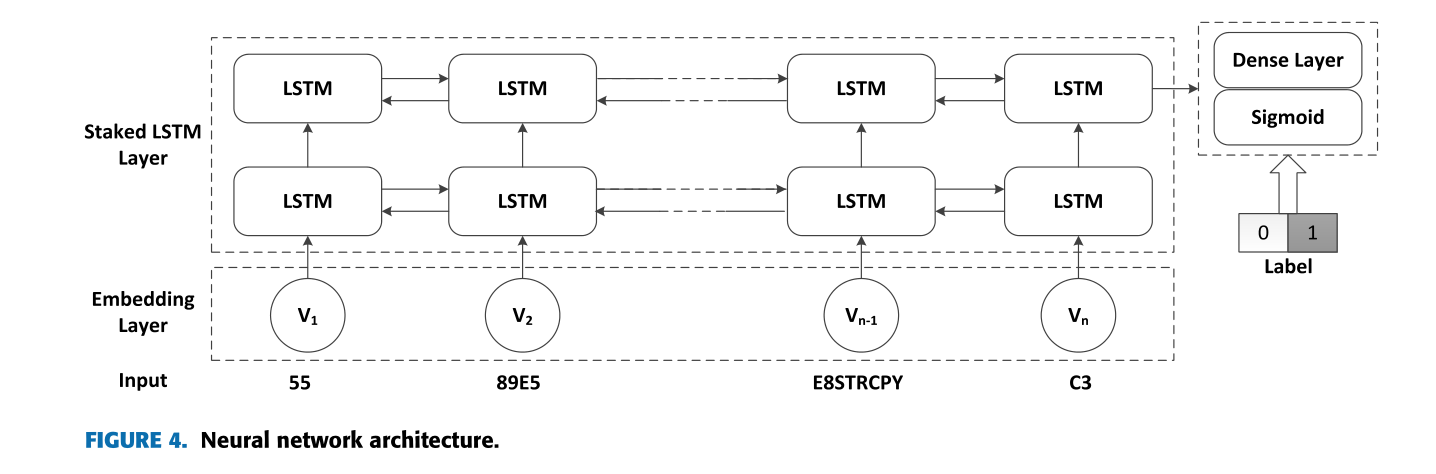
B.在线引导模糊
在PTfuzz主模糊环的基础上实现了在线引导模糊。当fuzzer生成一个新的输入并实现新的分支覆盖时,它将被添加到种子队列中。为了实现我们的种子优先级策略,我们在将种子添加到种子队列之前添加了一个执行路径恢复和漏洞预测模块,如图2(b)中的灰色框所示。我们可以根据Intel PT捕获的控制流信息和目标二进制文件来恢复程序的完整执行路径。然后,我们使用我们的预测模型来确定一条看不见的路径是否脆弱。根据预测结果标记种子(易受攻击的种子标记为“1”,不易受攻击的种子标记为“0”),然后将其添加到种子队列中。最后,在下一个种子选择过程和种子突变过程中,对易感种子进行优先排序和分配更多的突变能量。
1) 恢复执行路径
使用PTfuzz进行模糊处理时,执行控制流信息以数据包的形式实时收集,如表2所示(Intel PT指定可以将程序流更改为流更改指令(COFI)的指令),并存储在指定的内存空间中。表示代码分支覆盖率信息的位图通过解码这些数据包来更新。但是,在整个过程中,我们的模型输入并不需要完整的执行路径信息。因此,在使用我们的预测模型之前,我们必须通过解码存储在特定内存中的跟踪来恢复基于控制流包和目标程序二进制文件的执行路径。
算法1详细描述了该过程。具体来说,首先加载二进制程序,并从主入口函数(第1、2行)获取指令地址。然后,根据当前指令类型获取下一条指令,并将其字节码添加到路径中,直到跟踪的最后一条指令(第4-8行)。如果指令是条件跳转,则跳转方向根据TNT包(第11-18行)确定。如果指令是间接跳转或传输,则根据TIP包获得跳转目标地址(第19-21行)。如果指令是无条件直接跳转,则从指令(第22、23行)获取跳转目标地址。如果指令不是跳转,则根据当前指令的大小获取下一条指令(第24、25行)。我们使用Intel提供的解码库libipt[41]对PT跟踪信息进行解码。
2) 用神经网络模型指导模糊控制
我们的最终目标是利用学习到的模型来引导模糊者优先处理那些易受攻击路径的种子,以便尽早暴露出脆弱性,并为它们分配更多的突变能量,但给种子分配更少的能量来使用干净的路径来增加触发脆弱性的概率。因此,我们需要修改PTfuzz的原始算法,将我们的训练模型集成到fuzzer中。
我们的NeuFuzz实现如算法2所示,其中灰色框表示我们的方法与PTfuzz算法之间的差异。具体地说,当变异输入触发新分支(第14行)时,首先根据PT和二进制程序文件捕获的控制流信息恢复执行路径(第15行)。然后,利用该模型对路径是否易受攻击进行分类,根据预测结果对种子进行标记并添加到队列中(第16-20行)。当种子从队列中取出时,第一步是检查是否有标记为易受攻击的种子。如果存在易受攻击的种子,则对其进行优先排序(第5-9行)。我们的AssignEnergy的实现(第10行)将最多的突变能量(PTfuzz的默认最大值为1600)分配给易受攻击的种子,而将较少的能量(原始分配能量的50%)分配给不易受攻击的种子,如等式(3)所示,如果种子被标记为易受攻击,则vul返回true。式(2)表示PTfuzz的原始能量计算方法,其使用执行时间f速度、块转换覆盖率f cov、创建时间f时间和种子f深度的路径深度,如式(1)所示。值得注意的是,在极端情况下,在相当长的一段时间内不会发现任何脆弱的路径。在这种情况下,NeuFuzz遵循PTfuzz的原始种子选择策略,直到识别出一条脆弱路径。
5.实施与评估
我们的模型训练包含大约180行Python代码,基于TensorFlow作为后端开发,模糊模块基于PTfuzz实现,它增加了大约600行C/C++代码,包括与路径恢复、模型预测、种子选择相关的模块实现,能源分配等等。
A.评估设置
为了评估我们提出的方法的有效性,我们在不同的测试套件上进行了多个实验,以与当前的先进工具进行比较。
我们选择了一个通用的基准数据集LAVA-M,它包含四个易受攻击的Linux程序,分别是base64、md5sum、uniq和who,并且每个应用程序都手动注入了多个bug。此外,为了验证NeuFuzz在实际软件中的可扩展性和有效性,我们选择了9个广泛使用的实际应用程序进行测试,即libtiff、binutils、libav、podofo、bento4、libsnd文件、audio file和nasm,它们处理多种文件格式,包括图像、elf、文档、视频、音频和asm文件。
我们比较了NeuFuz、PTfuzz和QAFL,它们都支持二进制模糊,而不依赖源代码。我们在一台装有ubuntu16.04系统、32gb RAM、intelcorei78700k处理器和Nvidia 1080Ti GPU的计算机上运行所有的实验,在所有的比较实验中,我们只运行一个带有一个CPU核的fuzz实例,每个实例运行24小时。实验旨在回答以下三个研究问题。
1.我们学习的神经网络模型有多有效?
2.NeuFuz的漏洞检测能力有多好?
3.NeuFuzz模糊循环的开销如何?
B.结果
1)神经网络模型的有效性(RQ 1)
该模型的有效性对于NeuFuzz是至关重要的,因为种子选择是基于模型预测结果的。因此,在本节中,我们将评估训练模型的结果。如图5所示,经过5个阶段的训练,模型的训练精度达到91%,训练损失降低到22%。目前,还没有一种工具可用于二进制程序的漏洞检测,而与我们的方法最密切相关的工作是VDiscover,它提取API序列作为特征,然后使用传统的机器学习算法对其进行训练。相比之下,我们以执行路径为输入,使用LSTM进行训练。为了说明我们的方法(称为PATH+LSTM)的优点,我们实现了VDiscover的方法,该方法提取动态API序列,然后使用随机森林算法(称为API+RF)进行训练。
我们考虑了机器学习中广泛使用的以下指标来评价我们的方法:假阳性率(FPR)、假阴性率(FNR)、真阳性率(TPR)或召回率、精确度(P)和F1测度(F1)。设TP为正确检测到漏洞的样本数,FP为错误检测到漏洞的样本数,FN为未检测到真实漏洞的样本数,TN是没有未检测到的漏洞的样本数,FPR=FP/(FP+TN)是假阳性漏洞与不易受攻击样本总数的比率,FNR=FN/(TP+FN)是假阴性漏洞与易受攻击样本总数的比率。TPR=TP/(TP+FN)是真实阳性脆弱性与整个脆弱样本总体的比率。精度P=TP/(TP+FP)测量检测到的漏洞的正确性。F1=2·P·TPR/(P+TPR)既有精度又有TPR。
我们在两个数据集上评估我们的方法。第一个是我们构建的数据集的一部分(称为测试数据),包括5564条易受攻击的路径和5356条干净的路径,占我们提取的所有执行路径的1/5。另一个是LAVA-M数据集。尽管此数据集提供了易受攻击的程序和触发这些漏洞的输入,但没有修补版本的程序,因此我们只考虑TPR和FNR。结果见表3。我们可以看到NeuFuzz outper方法对两个数据集都形成了VDiscover,这可以解释为该漏洞不仅反映在API调用序列中,而且还反映在约束条件中。例如,使用完整的安全检查调用strcpy可能是安全的。此外,虽然我们的模型在LAVA-M上的性能比在FPR和TPR方面的测试数据差,但仍然达到了82.5%的阳性率,即在区分易受攻击代码和非易受攻击代码方面非常有效。
2)漏洞检测能力(RQ 2)
独特的碰撞次数是衡量模糊器有效性的一个重要因素。一些崩溃可能是由相同的根本原因(即重复的)引起的,也可能不是安全相关的;但是,一般来说,发现的崩溃数量越多,识别出更多漏洞的概率就越高。在本节中,我们比较了NeuFuzz、PTfuzz和QAFL在LAVA-M和实际应用中的结果。表4显示了在LAVA-M中使用不同的模糊器发现了不同的错误。第一列是目标程序名,第二列是目标程序中已知的错误数,最后三列分别是NeuFuzz、PTfuzz和QAFL发现的错误数。NeuFuzz发现了19个bug,超过了PTfuzz和QAFL。NeuFuzz、PTfuzz和QAFL无法完成md5sum实验,因为这些方法在第一次输入时崩溃,在[15]中也出现了同样的现象。
实际应用的结果如表5所示。这些应用程序在测试时都是最新版本。NeuFuzz比PTfuzz和QAFL能发现更多的崩溃,因此NeuFuzz发现漏洞的概率更高。在测试这些程序24小时后,共发现1290个崩溃。然后,我们使用AddressSanitizer[42]执行重复数据消除,并进一步确定42个漏洞。这些漏洞中有14个是其他研究人员先前发现并披露的,但这些供应商尚未发布补丁。其余28例不明,其中21例经CVE证实。发现的漏洞主要包括缓冲区溢出、UAF、空指针解引用、除以零、无效内存访问和其他内存损坏问题。此外,表的最后一列显示NeuFuzz可以在24小时内找到所有cve,比PTfuzz和QAFL快得多。PTfuzz和QAFL遗漏了一些漏洞,“N”表示工具找不到相应的CVE。
图6显示了在24小时内9个实际应用程序上不同模糊器的独特崩溃的增长。从增长趋势可以看出,NeuFuzz发现的独特崩溃数量比PTfuzz和QAFL增长更快,NeuFuzz发现的崩溃数量更多。例如,当模糊libsndfile库的sndfile-deinterleave程序时,NeuFuzz发现5个崩溃,而PTfuzz和QAFL没有找到。进一步分析表明,这是一个堆栈溢出漏洞。此外,QAFL在三个fuzzer中表现最差,因为它基于QEMU,并且在执行速度方面比基于硬件实现的PTfuzz效率低得多。简言之,NeuFuzz在漏洞检测的效率和有效性方面都表现得更好。
3)Neuffuz的开销(RQ 3)
灰盒模糊器的有效性在很大程度上取决于它的执行速度,在很大程度上,它只受执行一个测试用例所需的时间的限制。因此,我们需要确保我们的方法不会导致较大的性能开销,从而降低模糊化效率。我们通过每秒执行的测试用例数(exe/s)来衡量每个fuzzer的执行速度,以演示fuzzing开销。如图7所示,NeuFuzz的执行速度比QAFL快约2.5倍,但比PTfuzz慢约8%,因为NeuFuzz需要额外的时间进行路径恢复和漏洞预测。事实上,我们发现时间开销主要来源于路径恢复,路径恢复与执行路径的长度成正比。在一个简单的神经网络中,预测结果的时间复杂度仅为O(n1·n2+n2·n3+…)[43]。因此,当节点数在一个很小的范围内时,就像我们的模型一样,预测过程所需的时间比实际运行目标程序一次要少得多。简而言之,模糊化任务的开销相对来说是可以接受的。此外,虽然训练神经网络模型需要一些时间,但训练过程是离线进行的,并且我们只需为所有后续测试训练一次模型;因此,我们不考虑用于模型训练的时间。
C.讨论
评估结果表明,NeuFuzz在合理的代价下比现有的最先进的fuzzer具有更好的脆弱性检测能力,但还存在一些不足,值得进一步研究。
首先,NeuFuzz需要特定硬件和操作系统的支持,因为我们的方法是基于PTfuzz的。PTfuzz使用Intel PT,这是第五代Intel cpu的新功能,PTfuzz只能在Linux平台上运行,Linux内核版本至少为4.1.x。
其次,当我们使用执行路径作为输入来训练模型时,NeuFuzz不能处理一些超过我们阈值的程序路径,这限制了我们模型的能力。在未来,我们将考虑其他方法来表示路径,例如动态程序切片。此外,我们应该考虑应用其他神经网络模型来学习脆弱性模式。
第三,NeuFuzz无法发现隐藏在复杂的健全性检查背后的漏洞,比如魔法字节,因为神经网络模型只能预测训练路径来指导种子选择。这个问题是提高代码覆盖率的热门话题,我们可以将当前的一些先进方法集成到我们的工具中,以增强漏洞检测能力。
第四,即使在模糊化过程中发现一个种子触发了一条新路径,并且所学习的模型准确地识别了该路径,NeuFuzz仍然可能不会触发该漏洞。这是由于模糊的随机性,因为变异产生的新种子可能无法触发原始的脆弱路径。Farifuzz被提出用动态仪器来解决这个问题。在未来,我们可以考虑应用深度强化学习来尽可能地保证指定的路径被测试,从而进一步提高模糊化能力。
6.结论
当前的灰盒模糊技术主要关注如何提高代码覆盖率,而忽略了程序中易受攻击代码的分布,即试图覆盖尽可能多的程序路径,而不是探索可能是易受攻击的路径。本文提出了一种基于深度神经网络的种子选择策略,并实现了一种路径敏感的二值模糊工具NeuFuzz。我们构造一个大的数据集来训练我们的神经网络模型来学习隐藏的脆弱性模式,然后使用产生的模型来预测模糊化过程中触发的新路径。最后,我们根据预测结果,对执行脆弱路径的种子进行优先排序,并相应地赋予这些种子更多的变异能量。我们在精心设计的基准和实际应用程序上进行了实验。结果表明,本文提出的方法在碰撞检测和脆弱性检测方面是有效的。与PTfuzz和QAFL相比,NeuFuzz能够在更短的时间内发现更多的漏洞。我们在9个广泛应用的实际应用程序中发现了28个新的安全漏洞,其中21个已被CVE证实。
PTfuzz:Greybox fuzzing,例如american fuzzy lop(AFL),在发现软件漏洞方面非常有效,这使得它成为最先进的fuzzing技术。Greybox fuzzing利用程序运行期间收集的分支信息作为反馈来指导选择种子。当前的greybox模糊处理通常使用两种方法来收集分支信息:编译时插装(AFL)和仿真(AFL扩展QEMU仿真(QAFL))。编译时检测是有效的,但它不支持二进制程序。同时,仿真支持二进制程序,但效率很低。本文提出了一种基于硬件机制(Intel处理器跟踪)的greybox模糊方法PTfuzz。我们的方法支持二进制程序,就像仿真方法一样,同时它获得了与编译时插装方法相当的性能。实验结果表明,PTfuzz可以在不做任何修改的情况下对原始二进制程序进行模糊处理,与QAFL相比,性能提高了3倍。

若有收获,就点个赞吧
0 人点赞
