模糊化的关键思想是向被测程序(PUT program under test)提供大量精心编制的输入,以触发意外的程序行为,如崩溃或挂起。近年来,以代码覆盖率为反馈的覆盖导向灰盒模糊算法(CGF coverage-guided graybox fuzzing)已成为最成功的漏洞发现方法之一。CGF模糊器(例如AFL 编译时插装)有一个限制。当前的模糊检测旨在覆盖尽可能多的路径,而不是探索更容易受到攻击的路径。如[14]所述,程序中的错误分布通常是不平衡的,即大约80%的错误位于大约20%的程序代码中。因此,现有的CGF模糊器浪费了大量时间来测试无用的(即不易受攻击的)路径,从而降低了模糊化的效率。直观地说,使用更容易出错的程序路径的测试用例更容易触发错误,因此我们应该在这些路径上花费大部分的模糊工作,以增加在测试期间触发漏洞的可能性。
本文提出了一种新的路径敏感的灰盒模糊解决方案NeuFuzz,以缓解上述局限性。它应用了一种新的种子选择策略(测试用例的选择),该策略优先考虑那些更可能包含受攻击路径的种子,并相应地为这些种子分配更高的测试能量(例如,要生成的输入数量),以提高脆弱性检测的效率。我们利用深层神经网络来学习脆弱程序路径的隐藏模式,并识别出脆弱路径来指导种子的选择。
总之,我们作出了以下贡献:
- 我们提出了一种新的种子选择策略,该策略优先考虑种子利用脆弱路径来提高脆弱性发现的效率。
- 我们提出了一种新的深度神经网络解决方案来预测哪些程序路径是脆弱的。
- 我们实现了NeuFuzz原型来对二进制程序进行模糊化,并用精心设计的基准和真实世界应用程序对其进行了评估,证明了该解决方案的有效性。
- 我们在一些广泛使用的实际应用程序中发现了21个CVE和7个未知的安全漏洞,有助于提高供应商产品的安全性。
现有的种子选择策略很难使AFL在PUT中找到漏洞。给定初始种子输入“fuzz”,AFL可以快速找到图1(b)的控制流图中所示的其他三条路径,假设执行这些路径的测试用例是“0aaa”、“1bbb”和“2ccc”。然后AFL将按照图1(c)所示的添加顺序对每个测试用例执行突变。然而,种子输入0aaa、1bbb和3ddd所执行的三条路径(分别用红色、黄色和黑色线表示)显然不太可能存在漏洞;因此,模糊化它们的重要性非常低,种子输入2ccc所执行的路径(用蓝色线表示)易受攻击,对模糊化更有意义。而且为了触发路径中的潜在漏洞,种子应该比其他种子模糊更多次。事实上,实际程序比这个示例更复杂,通常包含更健全的检查和路径分支。假设一个程序执行n(n>1000)条路径,并且只有一条路径存在漏洞,那么我们的方法的优点很明显:我们可以首先测试易受攻击的路径,以便尽早暴露漏洞,而不是浪费大量时间测试其他n-1条路径。
种子输入的重要性取决于对它所经过路径的有用程度,使用深度学习来找出有用的路径。选择基于PTfuzz来实现NeuFuzz以保证在不损失性能的情况下使用二进制模糊器。
离线模型训练:
1)收集训练数据
本文需要一个可以执行的二进制程序和相应的测试用例,但是现在没有这样的数据集,所以从三个数据源构建了第一个二进制数据集:NIST SARD项目[36]、GitHub[37]和Exploit DB[38]。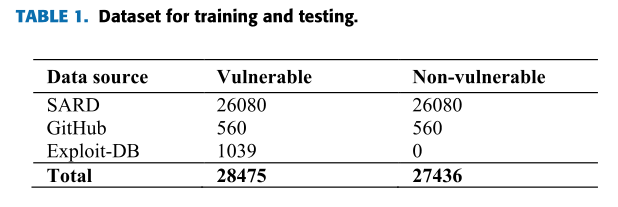
2)提取执行路径标注地面真相
使用intel PT的控制流跟踪能力提取路径,可使用POC(0day的别名)作为输入执行易受攻击和不易受攻击的程序,以获取易受攻击的路径(标记为“1”)和干净的路径(标记为“0”)。最后,从我们构建的数据集中提取出27820条脆弱路径和26871条干净路径,其中4/5用于训练,其余1/5用于测试。
3)将执行路径转换为向量表示
每个指令的十六进制字节码被视为一个令牌,例如,0x890424表示mov[ebp],eax;然后,字节码序列被word2vec训练。输出是256维空间中每条指令的矢量表示。然后,我们可以将执行路径转换为每条指令的矢量表示,如图3所示。
很明显,不同路径的长度是不相等的,而且变化很大。这种路径很难输入到深层神经网络结构中。因此,我们将路径的最大长度设置为n。短于n的路径从其后端填充0。而大于n的路径则从其前端截断,因为新触发的路径分支通常位于路径的末端。当填充到元素X1,X2,…,Xn(Xi是每个指令的矢量表示)的固定长度时,一条路径的输入序列可以表示为X1:n=X1⊕X2⊕。。。⊕Xn,其中⊕是连接符。
4)神经网络模型的训练
我们基于LSTM的神经网络由4层组成,如图4所示。第一层是嵌入层,它将序列中的所有元素映射到一个固定的维向量。第二层和第三层是层叠的LSTM层,每一层都包含64个双向形式的LSTM单元,层叠的LSTM模型可以学习更高层次的时域特征表示。最后,我们使用一个具有单个神经元和sigmod激活函数的密集输出层来对任务中的两类进行预测。我们的损失函数是 binary_crossentropy,优化器是adam,并且由于LSTM经常遭受过度拟合,我们使用dropout来解决这个问题。当dropout设为0.6时,我们的模型取得了最好的结果。
在线模糊引导
为了实现我们的种子优先级策略,我们在将种子添加到种子队列之前添加了一个执行路径恢复和漏洞预测模块,如图2(b)中的灰色框所示。我们可以根据Intel PT捕获的控制流信息和目标二进制文件来恢复程序的完整执行路径。然后,我们使用我们的预测模型来确定一条看不见的路径是否脆弱。根据预测结果标记种子(易受攻击的种子标记为“1”,不易受攻击的种子标记为“0”),然后将其添加到种子队列中。最后,在下一个种子选择过程和种子突变过程中,对易感种子进行优先排序和分配更多的突变能量。
1) 恢复执行路径
根据intel PT捕获的控制流信息(以数据包形式收集)和目标二进制文件来恢复
2) 用神经网络模型指导模糊控制
当变异输入触发新分支(第14行)时,首先根据PT和二进制程序文件捕获的控制流信息恢复执行路径(第15行)。然后,利用该模型对路径是否易受攻击进行分类,根据预测结果对种子进行标记并添加到队列中(第16-20行)。当种子从队列中取出时,第一步是检查是否有标记为易受攻击的种子。如果存在易受攻击的种子,则对其进行优先排序(第5-9行)。我们的AssignEnergy的实现(第10行)将最多的突变能量(PTfuzz的默认最大值为1600)分配给易受攻击的种子,而将较少的能量(原始分配能量的50%)分配给不易受攻击的种子,如等式(3)所示,如果种子被标记为易受攻击,则vul返回true。
在极端情况下,在相当长的一段时间内不会发现任何脆弱的路径。在这种情况下,NeuFuzz遵循PTfuzz的原始种子选择策略,直到识别出一条脆弱路径。



二者对比:
数据集:
vuldeepecker:CWE-119 CWE-399 该项目使用的是VulDeePecker创建者提供的数据集,该数据集总共包含61638个gadget, 提供的是源码,只能检测出与库函数有关的漏洞
NeuFuzz:从三个数据源构建了第一个二进制数据集:NIST SARD项目[36]、GitHub[37]和Exploit DB[38]。构成是二进制数据+相应的测试用例
均是4/5用于训练,其余1/5用于测试。
深度学习用法不同:
vuldeepecker:使用代码小工具训练神经网络,最终得到的是包含漏洞的片段,使用的激活函数是softmax
NeuFuzz:使用执行路径训练神经网络,得到的是执行路径是否是可能包含漏洞(即脆弱的) 使用的激活函数是sigmod
均是使用的LSTM
认定漏洞的严谨性:
VulDeePecker:保守地认为,只要代码中没有发现漏洞,代码就不易受攻击;
NeuFuzz:这种假设并不成立。使用ground truth更为准确。
word2vec的使用:
VulDeePecker:token是一些列的字符串,
NeuFuzz:token是十六进制字节码
截断方式不同:
VulDeePecker:根据前向后向切片对向量进行截断。后向切片,向量少于50,则在前面补零,否则在后面补零;向量大于50,则截断前面的,否则截断后面的
NeuFuzz:将路径的最大长度设置为n。短于n的路径从其后端填充0。而大于n的路径则从其前端截断。
运行需求不同:
VulDeePecker:系统实现使用python,框架使用的是Theano和Keras,实验环境是 NVIDIA GeForce GTX 1080 GPU;ntelXeon E5-1620 CPU在3.50GHz
NeuFuzz:硬件要求较高,Intel PT,只能在Linux上运行,Linux内核版本至少4.1.x

若有收获,就点个赞吧
0 人点赞
