1.现有的工具存在的两个问题
- 目前的漏洞检测依赖于人类根据经验去定义特征,定义的特征不具有客观性
-
2.本文做出的贡献
本研究是第一次将深度学习应用到漏洞检测方面
- 提出了一个基于深度学习的漏洞检测系统(VulDeepecker)的设计与实现
-
3.此系统前置指导原则
使程序对象之间的语义关系持久化,可以将程序先进行中间表示,就是先将程序转换成一个个code gadget
- 为了能够定位漏洞,程序表示不应是函数级别的,而应该是更细粒度的表示
-
4.系统设计
5.实验评估结果
TP:被模型预测为正的正样本;TN:被模型预测为负的负样本;FP:被模型预测为正的负样本;FN:被模型预测为负的正样本
评估标准
FPR:FP/(FP+TN)
FNR:FN/(FN+TN)
TPR:TP/(TP+FN) 1-FNR
P:TP/(TP+FP)
f1:2PTPR/(P+TPR)
数据收集使用的c/c++程序是19个开源的目前比较受欢迎的软件实现程序以及另外一些程序。80%作为训练程序,20%作为目标程序
系统实现使用python,框架使用的是Theano和Keras,实验环境是 NVIDIA GeForce GTX 1080 GPU;ntel
Xeon E5-1620 CPU在3.50GHz
a1)系统能够同时检测多种漏洞
五个指标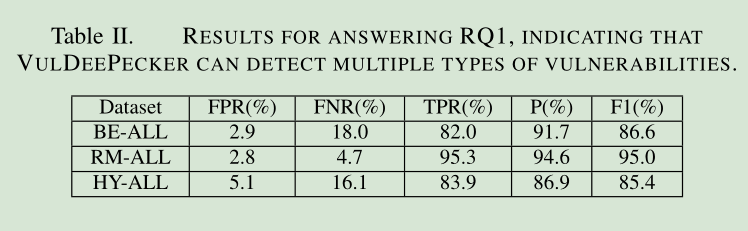
耗费时间
VulDeePecker可以同时检测多种类型的漏洞,但其有效性取决于与这些漏洞相关的库/API函数调用的数量(即与这些漏洞相关的库/API函数调用的数量,越少越好。
a2)将系统与人类经验结合,效果会更好
HY-ALL是所有的数据,HY-SEL是根据人类经验所选择过的数据
a3)基于深度学习的漏洞检测比其他系统更加有效
VulDeePecker比基于代码相似性的漏洞检测系统更有效,后者无法检测到不是由代码克隆引起的漏洞,因此经常导致较高的FNR。6.系统的不足与展望
不足:
VulDeePecker目前的设计仅限于通过假设程序源代码可用来处理漏洞检测。可执行程序中的漏洞检测是一个不同的、更具挑战性的问题。
- 目前的VulDeePecker设计只涉及C/ c++程序。需要进行进一步的研究以使其适应其他类型的编程语言。
- 目前的VulDeePecker设计只涉及与库/API函数调用相关的漏洞。未来将研究如何利用上面提到的其他类型的关键点来检测其他类型的漏洞。
- 目前的VulDeePecker设计只支持数据流分析,而不是控制流分析(即,控制依赖关系)。但是code gadget的概念可以适应数据依赖和控制依赖关系。利用数据流分析和适应控制流分析来增强漏洞检测能力,是以后研究的一个重要工作。
- VulDeePecker将code gadget转换成它们的符号表示,将可变长向量表示转换成定长向量。将来要进一步探索这样表示的有效性。
- 目前VulDeePecker的实现仅限于BLSTM神经网络。未来将计划利用其他类型的神经网络进行系统实验,用于漏洞检测。
- 由于数据集只包含缓冲区错误漏洞和资源管理错误漏洞,所以对VulDeePecker的评估是有限的。未来将对所有有价值的漏洞类型进行实验。虽然测试时针对3个软件产品( Xen, Seamonkey,和Libav),发现了4个没有在NVD中报告的漏洞,但是这些漏洞都是已知的,不是零日漏洞。所以未来需要对更多的软件产品进行大量的实验,以检查VulDeePecker是否有能力检测0天漏洞。
7.实验
参考:https://github.com/johnb110/VDPython
Python版本:3.7.5

- 数据集
该项目使用的是VulDeePecker创建者提供的数据集,该数据集总共包含61638个gadget,其中包含缓冲区错误漏洞的gadget有10440个,包含资源管理错误的gadget有7285个.
- 流程
- 将数据集中的每个gadget转换成符号表示(清洗)
用户定义的变量和函数的名称分别被替换为VAR#和FUN#。“#”是gadget中特定变量或函数的整数标识符的占位符。这样做的原因是可以将gadget转换成令牌时工作量大幅度缩减
if var_name not in var_symbols.keys():
var_symbols[var_name] = ‘VAR’ + str(var_count)
var_count += 1
if fun_name not in fun_symbols.keys():
fun_symbols[fun_name] = ‘FUN’ + str(fun_count)
fun_count += 1
- 将清洗后的gadget向量化
首先将一行c++代码(字符串)作为输入,标记c++代码(分解为标识符、变量、关键字、操作符)返回令牌列表
def tokenize(line):
标记每一行,加到一个长列表中
for line in gadget:
tokens = GadgetVectorizer.tokenize(line)
tokenized += tokens
if len(list(filter(function_regex.match, tokens))) > 0:
backwards_slice = True
else:
backwards_slice = False
return tokenized, backwards_slice
将输入的gadget添加到模型中,对这些gadget建立令牌并缓存,添加到列表中
def add_gadget(self, gadget):
tokenized_gadget, backwards_slice = GadgetVectorizer.tokenize_gadget(gadget)
self.gadgets.append(tokenized_gadget)
if backwards_slice:
self.backward_slices += 1
else:
self.forward_slices += 1
使用Word2Vec为每个gadget创建一个向量,通过组合令牌嵌入获取gadget向量,使用的令牌数量是number_of_token和50的最小值
if backwards_slice:
for i in range(min(len(tokenized_gadget), 50)):
vectors[50 - 1 - i] = self.embeddings[tokenized_gadget[len(tokenized_gadget) - 1 - i]]
else:
for i in range(min(len(tokenized_gadget), 50)):
vectors[i] = self.embeddings[tokenized_gadget[i]]
model = Word2Vec(self.gadgets, min_count=1, size=self.vector_length, sg=1)
self.embeddings = model.wv
- 构建BLSTM
首先对数据进行分割,切分成特征数据和标签数据
vectors = np.stack(data.iloc[:, 0].values)
labels = data.iloc[:, 1].values
训练数据和测试数据,0.8训练数据,0.2测试数据
X_train, X_test, y_train, y_test = train_test_split(vectors[resampled_idxs, ], labels[resampled_idxs],
test_size=0.2, stratify=labels[resampled_idxs])
对数据进行热编码
self.y_train = to_categorical(y_train)
self.y_test = to_categorical(y_test)
建立模型,输入层是300个神经元节点,优化器使用Adamax,训练周期为4个周期
model = Sequential()
model.add(Bidirectional(LSTM(300), input_shape=(vectors.shape[1], vectors.shape[2])))
model.add(Dense(300))
model.add(LeakyReLU())
model.add(Dropout(0.5))
model.add(Dense(300))
model.add(LeakyReLU())
model.add(Dropout(0.5))
model.add(Dense(2, activation=’softmax’))
adamax = Adamax(lr=0.002)
model.compile(adamax, ‘categorical_crossentropy’, metrics=[‘accuracy’])
训练
self.model.fit(self.X_train, self.y_train, batch_size=self.batch_size, epochs=4, class_weight=self.class_weight)
self.model.save_weights(self.name + “_model.h5”)
测试,评价指标是FPR、FNR、精确度和F1分数
self.model.load_weights(self.name + “_model.h5”)
values = self.model.evaluate(self.X_test, self.y_test, batch_size=self.batch_size)
print(“Accuracy is…”, values[1])
predictions = (self.model.predict(self.X_test, batch_size=self.batch_size)).round()
tn, fp, fn, tp = confusion_matrix(np.argmax(self.y_test, axis=1), np.argmax(predictions, axis=1)).ravel()
print(‘False positive rate is…’, fp / (fp + tn))
print(‘False negative rate is…’, fn / (fn + tp))
recall = tp / (tp + fn)
print(‘True positive rate is…’, recall)
precision = tp / (tp + fp)
print(‘Precision is…’, precision)
print(‘F1 score is…’, (2 precision recall) / (precision + recall))
- 主函数
文件解析,遍历整个文件,通过”-“33划分为多个gadget,忽略每个gadget的第一行,就是以整数+空格开头的。
if “-“ 33 in line and gadget:
yield clean_gadget(gadget), gadget_val
gadget = []
每个gadget最后一行都是以二进制0或者1结尾,表示此gadget是否是漏洞
elif stripped.split()[0].isdigit():
if gadget:
# Code line could start with number (somehow)
if stripped.isdigit():
gadget_val = int(stripped)
else:
gadget.append(stripped)
将每个gadget向量化,构建gadget字典列表(包含gadget和漏洞指示器)
vectorizer = GadgetVectorizer(vector_length)
for gadget, val in parse_file(filename):
count += 1
print(“Collecting gadgets…”, count, end=”\r”)
vectorizer.add_gadget(gadget)
row = {“gadget” : gadget, “val” : val}
gadgets.append(row)
print(‘Found {} forward slices and {} backward slices’
.format(vectorizer.forward_slices, vectorizer.backward_slices))
print()
print(“Training model…”, end=”\r”)
vectorizer.train_model()
print()
vectors = []
count = 0
for gadget in gadgets:
count += 1
print(“Processing gadgets…”, count, end=”\r”)
vector = vectorizer.vectorize(gadget[“gadget”])
row = {“vector” : vector, “val” : gadget[“val”]}
vectors.append(row)
print()
df = pandas.DataFrame(vectors)
获取文件名,如果存在,则加载向量DataFrame;如果不存在,则创建它实例化神经网络,传递数据,训练测试,打印精度
def main():
if len(sys.argv) != 2:
print(“Usage: python vuldeepecker.py [filename]”)
exit()
filename = sys.argv[1]
parse_file(filename)
base = os.path.splitext(os.path.basename(filename))[0]
# print(base)
vector_filename = base + “_gadget_vectors.pkl”
vector_length = 50
if os.path.exists(vector_filename):
df = pandas.read_pickle(vector_filename)
else:
df = get_vectors_df(filename, vector_length)
df.to_pickle(vector_filename)
print(df)
blstm = BLSTM(df,name=base)
blstm.train()
blstm.test()
- 运行
python vuldeepecker.py [gadget_file]
- 结果
中间生成的结果:
- cleaned_gadget:
- token:
- vectors:

自然语言处理(NLP)
词嵌入
一种算法:Word2Vec(Word to Vector)/ Doc2Vec(Document to Vector)
相关资料:
https://zhuanlan.zhihu.com/p/26306795
https://blog.csdn.net/qq_39521554/article/details/86696202
1. Mikolov 两篇原论文:『Distributed Representations of Sentences and Documents』贡献:在前人基础上提出更精简的语言模型(language model)框架并用于生成词向量,这个框架就是 Word2vec『Efficient estimation of word representations in vector space』贡献:专门讲训练 Word2vec 中的两个trick:hierarchical softmax 和 negative sampling优点:Word2vec 开山之作,两篇论文均值得一读缺点:只见树木,不见森林和树叶,读完不得要义。这里『森林』指 word2vec 模型的理论基础——即 以神经网络形式表示的语言模型『树叶』指具体的神经网络形式、理论推导、hierarchical softmax 的实现细节等等2. 北漂浪子的博客:『深度学习word2vec 笔记之基础篇』优点:非常系统,结合源码剖析,语言平实易懂缺点:太啰嗦,有点抓不住精髓3. Yoav Goldberg 的论文:『word2vec Explained- Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method』优点:对 negative-sampling 的公式推导非常完备缺点:不够全面,而且都是公式,没有图示,略显干枯4. Xin Rong 的论文:『word2vec Parameter Learning Explained』:!重点推荐!理论完备由浅入深非常好懂,且直击要害,既有 high-level 的 intuition 的解释,也有细节的推导过程一定要看这篇paper!一定要看这篇paper!一定要看这篇paper!5. 来斯惟的博士论文『基于神经网络的词和文档语义向量表示方法研究』以及他的博客(网名:licstar)可以作为更深入全面的扩展阅读,这里不仅仅有 word2vec,而是把词嵌入的所有主流方法通通梳理了一遍6. 几位大牛在知乎的回答:『word2vec 相比之前的 Word Embedding 方法好在什么地方?』刘知远、邱锡鹏、李韶华等知名学者从不同角度发表对 Word2vec 的看法,非常值得一看7. Sebastian 的博客:『On word embeddings - Part 2: Approximating the Softmax』详细讲解了 softmax 的近似方法,Word2vec 的 hierarchical softmax 只是其中一种
Word2Vec是由Tomas Mikolov 等人在《Efficient Estimation of Word Representation in Vector Space》一文中提出,是一种用于有效学习从文本语料库嵌入的独立词语的统计方法。其核心思想就是基于上下文,先用向量代表各个词,然后通过一个预测目标函数学习这些向量的参数。
例如:判断一个词的词性,是动词还是名词。用机器学习的思路,我们有一系列样本(x,y),这里 x 是词语,y 是它们的词性,我们要构建 f(x)->y 的映射,但这里的数学模型 f(比如神经网络、SVM)只接受数值型输入,而 NLP 里的词语,是人类的抽象总结,是符号形式的(比如中文、英文、拉丁文等等),所以需要把他们转换成数值形式,或者说——嵌入到一个数学空间里,这种嵌入方式,就叫词嵌入(word embedding),而 Word2vec,就是词嵌入( word embedding) 的一种。
程序切片
前向切片:表示的是程序P中所有收到变量(或变量集)V在n点的值影响的语句或者控制谓词的集合
后向切片:表示的是程序P中所有对变量(或变量集)V在n点的值有影响的语句和控制谓词的集合
区分前向后向切片
根据库/API函数调用语句的位置确定,后向切片的最后一条语句是函数调用语句,前向切片的第一条语句是函数调用语句
代码中怎么体现前向后向
提取函数调用是怎么提取的
- Warning: your JVM has a maximum heap size of less than 2 Gig. You may need to import large code bases in batches.
If you have additional memory, you may want to allow your JVM to access it by using the -Xmx flag.
Exception in thread “main” org.neo4j.kernel.StoreLockException: Unable to obtain lock on store lock file: .joernIndex/store_lock. Please ensure no other process is using this database, and that the directory is writable (required even for read-only access)
at org.neo4j.kernel.StoreLocker.checkLock(StoreLocker.java:82)
at org.neo4j.unsafe.batchinsert.BatchInserterImpl.(BatchInserterImpl.java:228)
at org.neo4j.unsafe.batchinsert.BatchInserters.inserter(BatchInserters.java:94)
at org.neo4j.unsafe.batchinsert.BatchInserters.inserter(BatchInserters.java:88)
at org.neo4j.unsafe.batchinsert.BatchInserters.inserter(BatchInserters.java:63)
at neo4j.batchInserter.Neo4JBatchInserter.openDatabase(Unknown Source)
at outputModules.neo4j.Neo4JIndexer.initializeDatabase(Unknown Source)
at tools.index.Indexer.initialize(Unknown Source)
at tools.index.IndexMain.setupIndexer(Unknown Source)
at tools.index.IndexMain.main(Unknown Source)
Caused by: java.io.IOException: Unable to lock org.neo4j.kernel.impl.nioneo.store.StoreFileChannel@47089e5f
at org.neo4j.kernel.impl.nioneo.store.FileLock.wrapFileChannelLock(FileLock.java:38)
at org.neo4j.kernel.impl.nioneo.store.FileLock.getOsSpecificFileLock(FileLock.java:93)
at org.neo4j.kernel.DefaultFileSystemAbstraction.tryLock(DefaultFileSystemAbstraction.java:93)
at org.neo4j.kernel.StoreLocker.checkLock(StoreLocker.java:74)
… 9 more
rm -rf .joernIndex/
先删除已有的.joernIndex,再导入
- 报错:ValueError: With n_samples=0, test_size=0.2 and train_size=None, the resulting train set will be empty. Adjust any of the aforementioned parameters.
可能是数据集量不够,由于内存太小,一下导入不了太多数据,所以将切片数量定为600(根据二分法,找到最小适合的数据量).

若有收获,就点个赞吧
0 人点赞
