核心原理
底层实现
- 底层采用哈希表,一种非常重要的数据结构,redis数据库的核心技术和HashMap一样
- 数据结构中数组加链表对数据进行存储时,各有特点:
- 数组占用空间连续。寻址容易,查询速度快,但是增加和删除效率非常低
- 链表占用空间不连续。寻址困难,查询速度慢,但是增删效率非常高
- 哈希表结合了数组和链表的优点,查询快,增删效率也高。其本质是“数组+链表”
- 一个Entry对象存储内容如下
- key 键对象 value 值对象
- next 下一个节点
- hash 键对象的hash值
- 每一个Entry对象就是一个单向链表结构,使用图形表示一个Entry对象的典示例

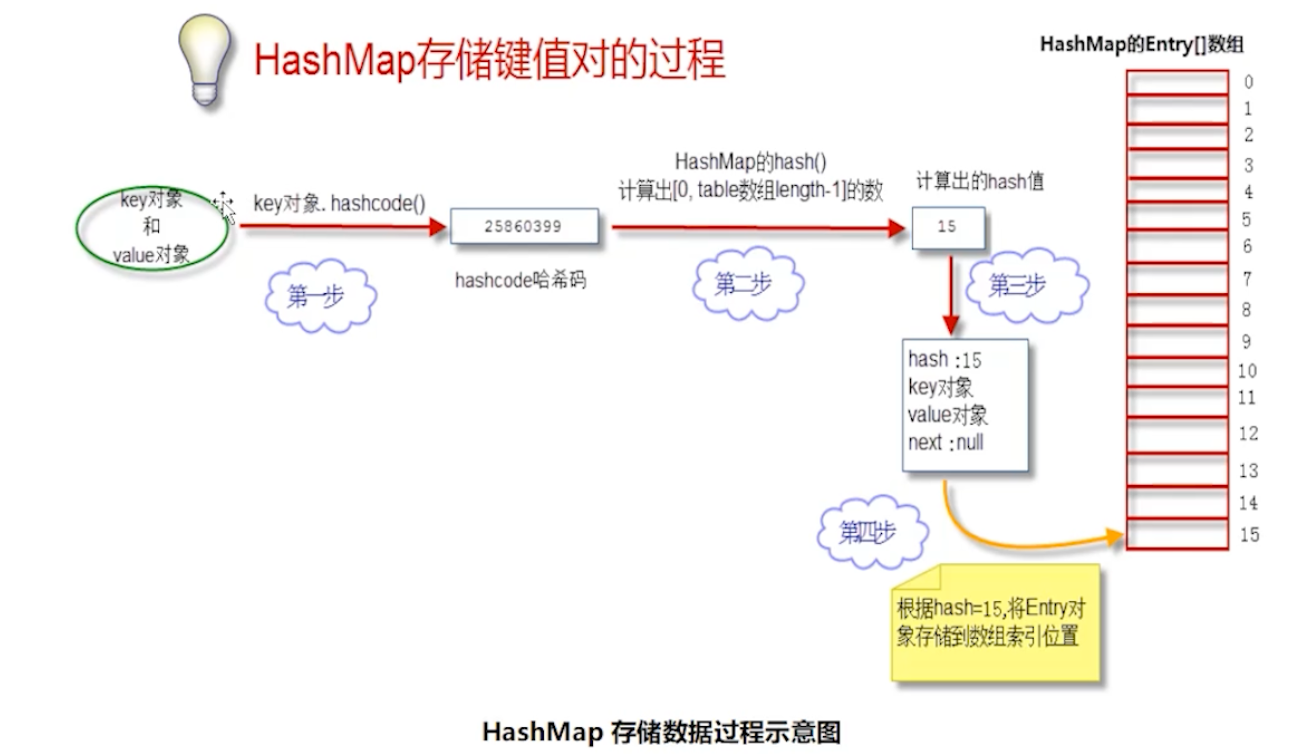
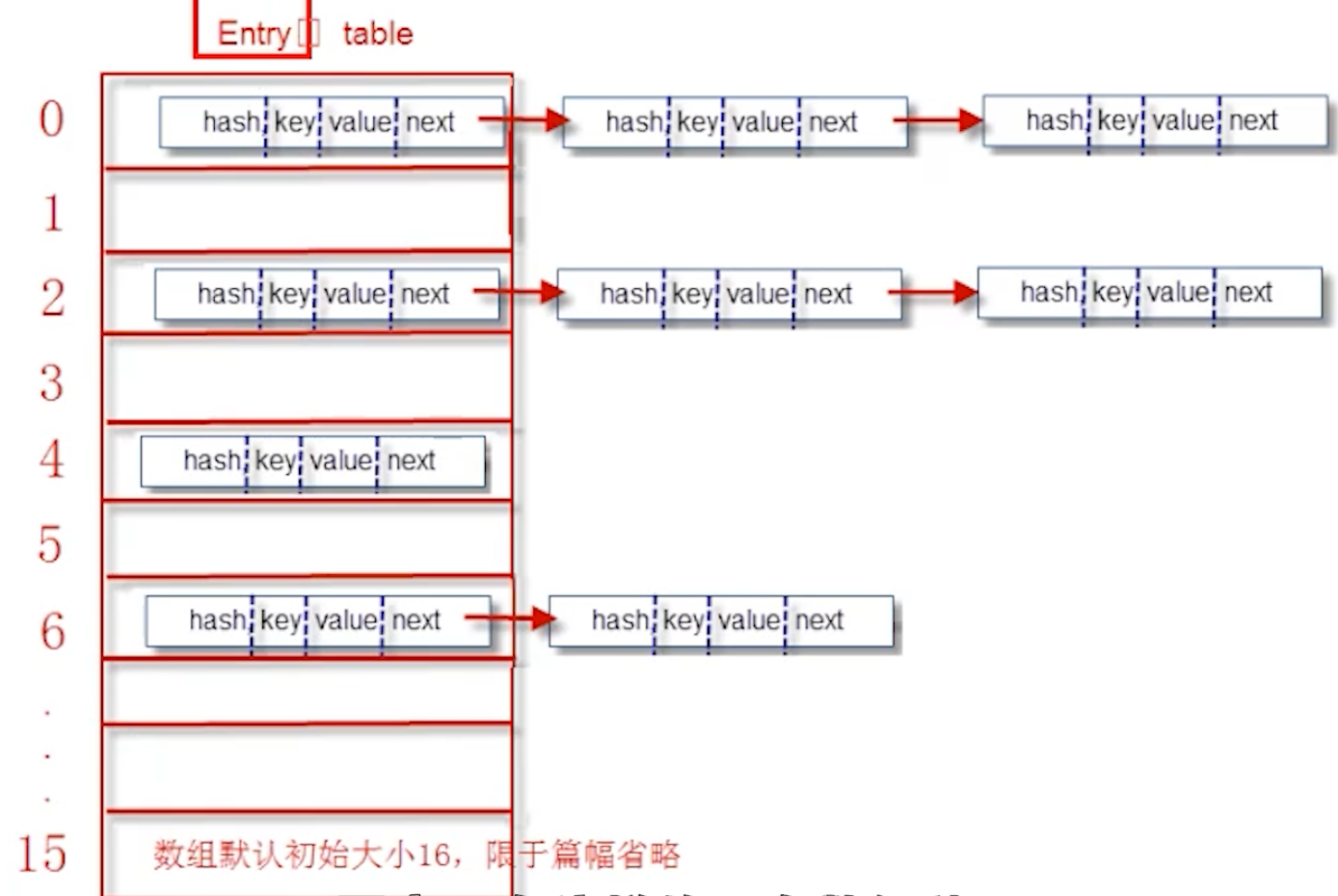
手写示例
package collection;/*** 自定义接口MyMap,实现Map部分内容* @pram K,V*/public interface MyMap<K,V> {int size();boolean isEmpty();boolean containsKey(Object key);boolean containsValue(Object value);V get(K key);void put(K key, V value);void remove(Object key);}
package collection;public class MyHashMap<K,V> implements MyMap<K,V>{private final static int INIT_CAPACITY = 1<<4;private int size;private Entry[] table;public MyHashMap() {table = new Entry[INIT_CAPACITY];}public static void main(String[] args) {MyHashMap<String,String> hm = new MyHashMap<>();hm.put("name","zhangsan");hm.put("age","13");hm.put("sex","male");hm.put("career","home");hm.put("career","car");System.out.println(hm.get("sex"));System.out.println(hm.toString());hm.remove("age");System.out.println(hm.toString());}private int hash(K key) {int hashVal = key.hashCode();hashVal = (hashVal<0)?-hashVal:hashVal;return hashVal & (table.length-1);// return hashVal & (1);}@Overridepublic int size() {return size;}@Overridepublic boolean isEmpty() {return size == 0;}@Overridepublic boolean containsKey(Object key) {return false;}@Overridepublic boolean containsValue(Object value) {return false;}@Overridepublic V get(K key) {int index = hash(key);Entry e = table[index];while (e != null){if (e.key.equals(key)){return (V)e.value;}e = e.next;}return null;}@Overridepublic void put(K key, V value) {int index = hash(key);Entry en = new Entry<>(index,key,value,null);if (table[index] == null){table[index] = en;}else{Entry pos = table[index];Entry last = pos;while (pos!=null) {if (pos.key.equals(key)){pos.value = value;return;}last = pos;pos= pos.next;}last.next = en;}size++;return;}@Overridepublic void remove(K key) {int index = hash(key);Entry e = table[index];Entry prevous = null;while (e != null) {if (e.key.equals(key)) {if (prevous == null) {// 说明是第0个元素e = e.next;} else {// 说明是第n个元素prevous.next = e.next;}size --;return;}prevous = e;e = e.next;}return;}@Overridepublic String toString() {StringBuilder sb = new StringBuilder();sb.append("[");for (Entry entry:table) {while(entry!=null){sb.append("{"+entry.key + ":" + entry.value + "}");if (entry.next!=null){sb.append(",");}entry = entry.next;}}sb.append("]");return sb.toString();}}class Entry<K,V>{int hash;K key;V value;Entry next;public Entry(int hash, K key, V value, Entry next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public Entry() {}}
HashSet
package collection;public class MyHashSet<E> {MyHashMap map;public static final Object DEFAULT_OBJ = new Object();public MyHashSet() {map = new MyHashMap<>();}public static void main(String[] args) {MyHashSet<String> set = new MyHashSet();set.add("aaa");set.add("bbb");set.add("aaa");}private void add(E val) {map.put(val,DEFAULT_OBJ);}public int size() {return map.size();}}
知识点
- equals和hashcode通常必须在一起重写
- equals为true,那么hashcode必须相等,这么处理就是为了在HashMap的存取中不会出现悖论,如果hashcode不一致,在hashmap中就无法定位到正确的entry去进行比较
int index = hash(key);

若有收获,就点个赞吧
0 人点赞
