线程池概念
池化技术介绍
池化技术指的是提前准备一些资源,在需要时可以重复使用这些预先准备的资源,他的优点是提前创建、重复利用。常见的池化技术有:线程池、数据库连接池、HttpClient连接池
线程池的基本概念和优点
线程池的思路是,有工作来就向线程池中取出线程,当工作完成后,并不直接关闭线程,而是将该线程归还至线程池共其他任务使用,这样可以避免频繁的创建、销毁线程,极大提高响应速度。例如创建线程的时间为T1,执行任务时间T2,销毁线程需要的时间为T3,使用线程池大约节约了T1+T3的时长
- 例如省级银行的网络中心,高峰期每秒的客户端请求并发数超过200,如果为每个客户端请求创建一个新线程的话,耗费的CPU时间和内存是十分惊人的,而如果采用一个拥有200个线程的线程池,将会节约大量的系统资源,使得更多的CPU时间和内存用以处理实际的商业应用,而不是频繁的线程创建、销毁工作。
- 优点:
- 解耦作用:现成的创建与执行完全分开,方便维护
- 重复使用,降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的损耗
- 统一管理线程:控制线程并发数量,降低服务器压力,统一管理所有线程
- 提升系统响应速度:使用线程池,工作效率一般可提高10倍以上
线程池工作原理
| 类型 | 形参 | 内容 | | —- | —- | —- | | int | corePoolSize | 线程池中的核心线程数量,这几个核心线程,在没有用的时候,也不会被回收 | | int | maximumPoolSize | 线程池中可以容纳的最大线程的数量(核心线程数+非核心线程数) | | long | keepAliveTime | 非核心线程可以保留的最长空闲时间(200毫秒) | | TimeUnit | unit | 时间单位,使用例如TimeUint.MILLISECONDS的常量 | | BlockingQueuepublic ThreadPoolExecutor(int corePoolSize...)
| workQueue | 任务可以存储在任务队列中等待被执行,执行的是FIFIO原则 | | ThreadFactory | threadFactory | 创建线程对象的工厂 (默认值Executors.defaultThreadFactory()) | | RejectedExecutionHandler | handler | 线程池满时的执行策略(默认值defaultHandler) |
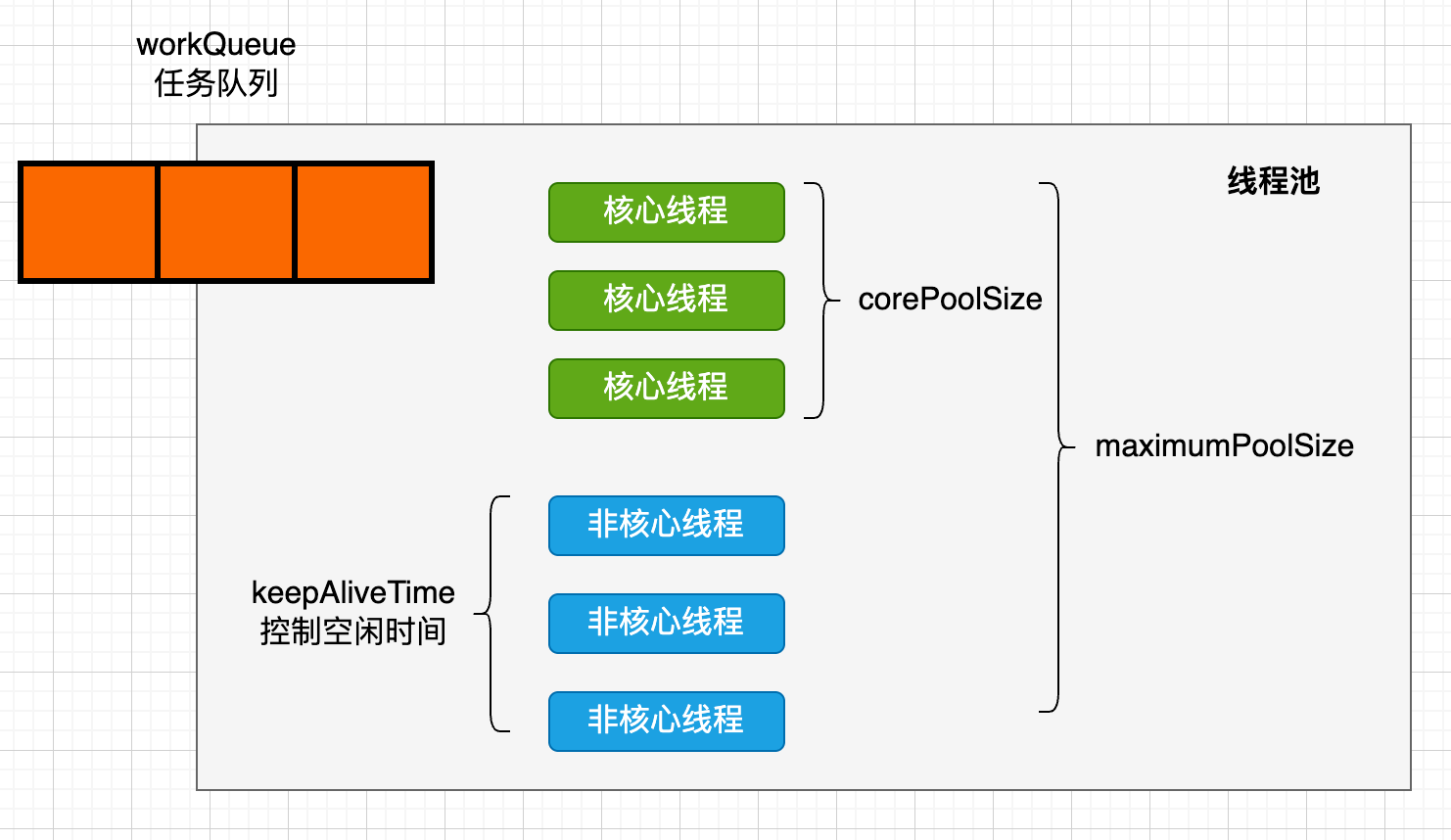
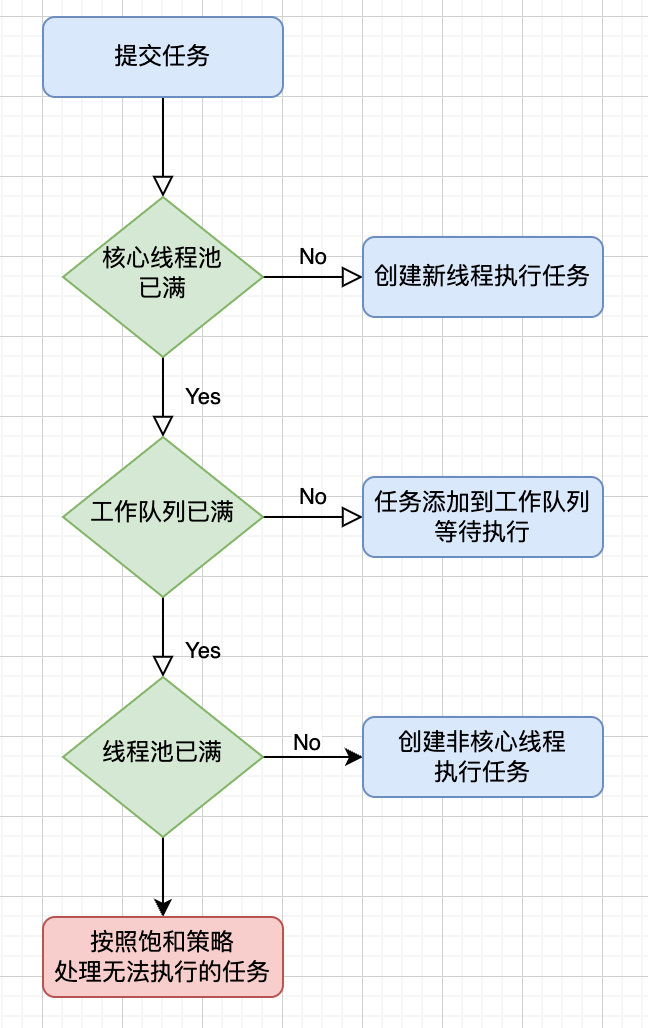
- 饱和处理策略
- AbortPolicy:不执行任务,直接抛出异常,提示线程池已满(默认)
- DiscardPolicy:不执行新任务,也不抛出异常
- DiscardOldSetPolicy:将消息队列中的第一个任务替换为当前新进来的任务执行
- CallRunsPolicy:直接调用execute来执行任务 ```java package bob;
import java.util.concurrent.*;
public class Test {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 200, TimeUnit.MILLISECONDS, new ArrayBlockingQueue
class myTask implements Runnable{ int taskId;
public myTask(int taskId) {this.taskId = taskId;}@Overridepublic void run() {System.out.println(taskId + "开始执行");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(taskId + "执行完毕");}
}
<a name="eBbz3"></a># JDK内置的四种线程池1. CachedThreadPool:该线程池没有核心线程,非核心线程数量为Integer.max_value,就是无限大,当需要时创建线程任务来执行任务,没有需要时回收线程,适用于耗时少,任务量大的情况。1. ScheduledThreadPool:周期性执行任务的线程池,按照某种特定的计划执行线程的任务,有核心线程,也有非核心线程,非核心线程的大小也为无限大。也可以执行周期性的任务。1. SingleThreadPool:只有一个线程来执行任务,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO,LIFO,优先级)执行适用于有顺序的任务的应用场景。1. FixedThreadPool:定长的线程池,只有核心线程,核心线程数量即最大线程数量,没有非核心线程。```javaExecutorService executor = Executors.newCachedThreadPool();ExecutorService executor = Executors.newFixedThreadPool(30);ExecutorService executor = Executors.newSingleThreadPool();ScheduledExecutorService executor = Executors.newScheduledThreadPool(30);
ThreadLocal
概念
- ThreadLocal为每个线程提供独立的变量副本,所以每一个线程都可以独立的改变自己的副本,而不会影响其他线程所对应的副本
ThreadLocal更多是为了实现数据隔离,避免多次传参问题,围绕这点开展相关应用场景
ThreadLocal类的4个方法
public void set(T value); //设置当前线程的线程局部变量的值public T get();//该方法返回当前线程所对应的线程局部变量// 使用完ThreadLocal变量时,应该将线程局部变量删除。避免因为线程周期长引起的内存泄漏public void remove();// 在线程第1次调用get或set时才执行,并且仅执行1次(缺省null)protected T initialValue();
```java package bob;
public class TestThread extends Thread{
public static ThreadLocal
public static Integer getNextNum1() {seqNum1.set(seqNum1.get()+1);return seqNum1.get();}@Overridepublic void run() {for (int i = 0; i < 3; i++) {System.out.println(Thread.currentThread().getName() + "seqNum1:" + getNextNum1());}}public static void main(String[] args) {new TestThread().start();new TestThread().start();new TestThread().start();// 用完需要remove,清除防止内存泄漏seqNum1.remove();// 继续线程的其他事情}
底层源码与内存分析
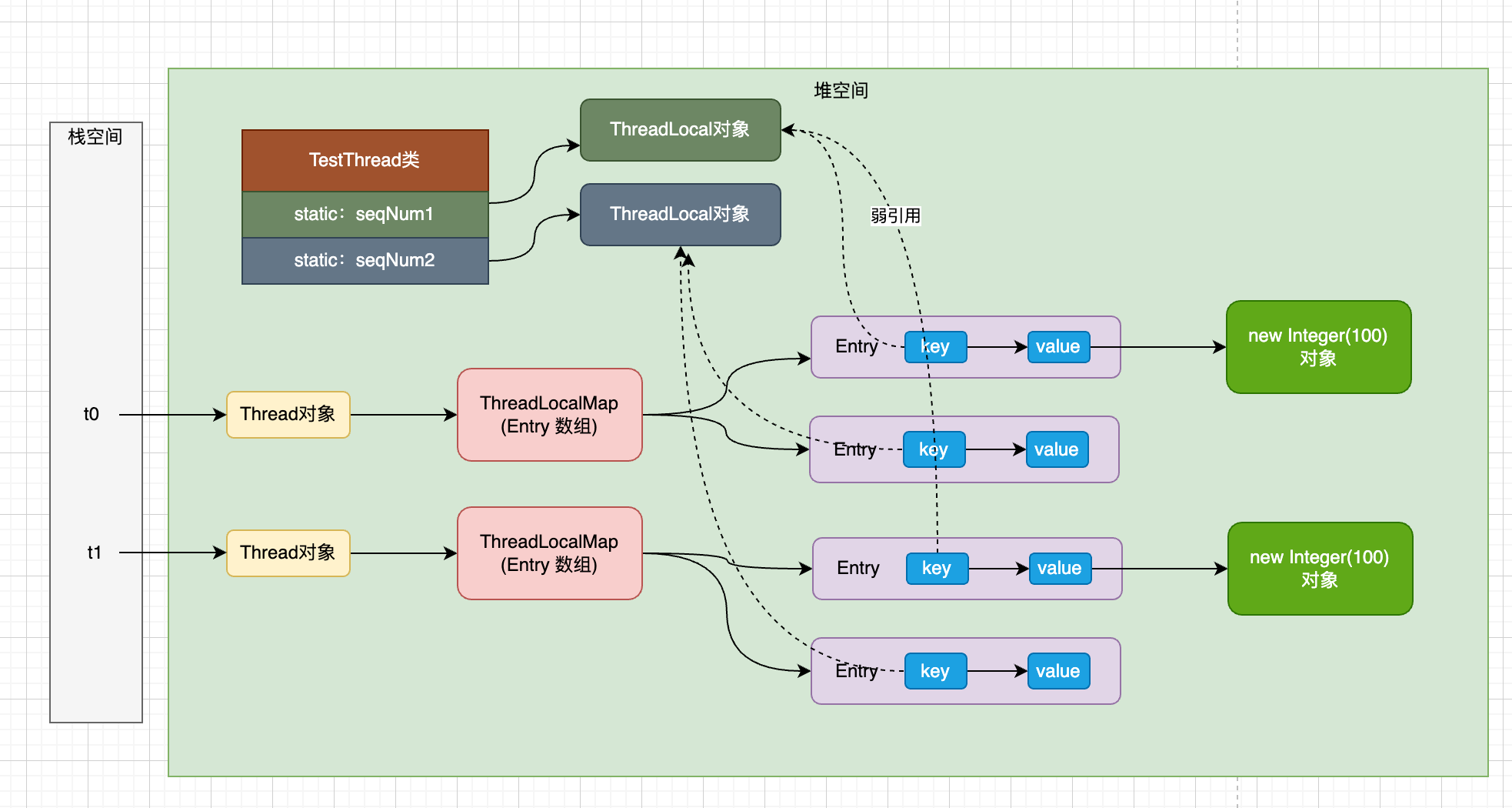
- ThreadLocalMap 不是map,是一个Entry数组
- 各线程内部Entry数组的一个键值对中的键key是共享ThreadLocal对象的(减少key的个数)
实现是强引用,虚线是弱引用,有弱引用指向的对象无强引用指向时,仍然会被垃圾回收,可能造成内存泄漏
强弱引用与内存泄露
不再会被使用的对象或者变量占用的内存不能被回收,就是内存泄漏
内存泄漏产生原因:长生命周期对象持有短生命周期的对象导致短生命周期对象无法释放
强引用
最普遍的引用,一个对象具有强引用,不会被垃圾回收器回收,当内存空间不足,java虚拟机会抛出OutOfMemoryError错误,使程序异常终止,也不回收对象
若需要取消强引用和某个对象的关联,可以显式地将引用赋值为null,这样可以使JVM在合适的时间回收该对象
弱引用
进行垃圾回收时,无论内存是否充足,会回收之被弱应用关联的对象。java中,用java.lang.ref.WeakReference类来表示
- 弱引用可能会造成内存泄漏。如果ThreadLocal只被弱引用会被GC回收。回收后,没有再调用get()/set()/remove()释放,从而造成value对象无法回收

若有收获,就点个赞吧
0 人点赞
