1. Prometheus常用监控架构
1.1. 存储
1.1.1. 本地存储
Prometheus 支持本地存储和远程存储,默认采用的是本都存储。本地存储的目录结构如下:
prometheus/ # 数据存储目录├── 01EN7R4W36Z8EZ56GZRE3YPFTS # 数据块│ ├── chunks # 数据样本│ │ └── 000001│ ├── index # 索引文件│ ├── meta.json # 元数据文件│ └── tombstones # 逻辑数据├── 01EN86EMGH9RJBVSRCH6YXZCKP│ ├── chunks│ │ └── 000001│ ├── index│ ├── meta.json│ └── tombstones├── chunks_head│ └── 000002├── lock├── queries.active└── wal # 预写日志文件,即原始时间序列数据,还未压缩为块存储到本地磁盘├── 00000122├── 00000123├── 00000124├── 00000125└── checkpoint.00000121└── 00000000
每隔两小时的时间段包含一个目录,该目录包含一个或多个块文件,该文件包含该时间段的所有时间序列样本,以及元数据文件和索引文件(该索引文件将metric名称和标签索引到块文件中的时间序列 )。 通过API删除系列时,删除记录存储在单独的逻辑删除文件中(而不是立即从块文件中删除数据)。因为每个两个小时进行一次数据压缩和存储,因此还在内存中的数据会把原始数据写入wal预写日志文件中进行临时保存,方便后续从故障中恢复且不丢失数据。如果数据文件异常,可以从wal日志开始逐步删除文件,尝试恢复, `meta.json` 中有时间戳。
磁盘容量评估: 在磁盘容量的选择上,可以用这个方式做个预估,平均每个样本仅使用大约1-2 bytes,预估容量的公式如下:
S = T * c * s S 表示预期消耗的磁盘空间,单位 byte T 表示数据保留的时间,单位 s c 表示每秒钟采集的数据样本数,单位 1/s s 表示每个样本的大小,一般为 1-2 btye # 如: 对于100台机器,仅部署node_exporter,每个node_exporter产生大约500个指标 (60*60*24*30) * (500/60) * 2 / (1024 * 1024 * 1024)# 计算500台虚拟机在仅部署node_exporter下,每隔一分钟采集一次数据,一个月磁盘消耗量 在没有额外配置参数的情况下,node_exporter暴露的/metrics接口指标数494,加上recording_rule一起约500个 一台机器: (60*60*24*30) * (500/60) * 2 / (1024 * 1024 * 1024) = 0.04 Gb 500台机器: 500*0.04 = 20Gb文件系统选择:不推荐NFS文件系统,不支持非 POSIX 规范的文件系统。推荐使用本地存储
-
1.1.2. 远程存储
为了解决本地存储的扩展性和单点故障的风险,Prometheus提供了远程存储的选项,可以进行远程读和远程写两种。并不是所有的远程存储都支持读和写,详细可以参考:https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage

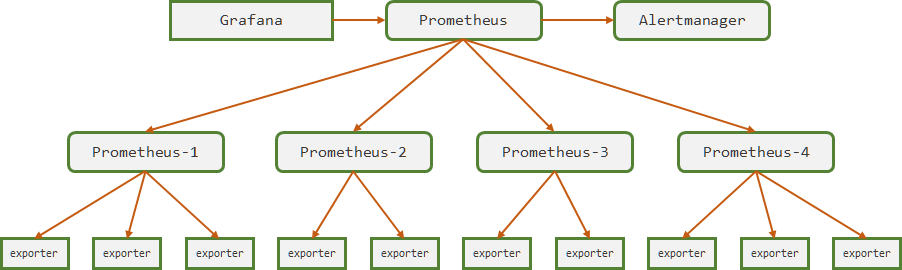
1.2. Prometheus集群联邦
集群联邦是由多台prometheus从从不同的 exporter 上取数据,并汇总到中心prometheus上的方案。一般在三种情况下会使用:
需要聚合数据,并且环境复杂,比如跨数据中心环境、多个k8s集群等
- target数量太多,一个prometheus性能不足,需要通过分片的方式分担压力
1.3. Prometheus高可用方案
上述提到的集群联邦,只是为了降低中心prometheus的压力,或者避免跨网络问题,但并没有实现 alertmanager 和 prometheus 的高可用问题。Prometheus自身并没有提供高可用集群方案,Alertmanager提供了高可用方案。无论采用什么方案,时间同步服务都需要部署!
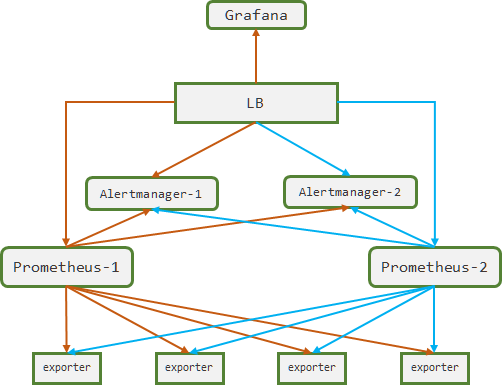
1.3.1. 简单高可用方案
- 方案:
- 两台Prometheus都拉取数据,并且存储在本地文件系统。其中Prometheus-2作为备用节点
- 查询请求通过LB请求到Prometheus-1上
- Alertmanager自身就是高可用,可以进行告警的聚合和去重
- 优点:
- 以较低的成本基本完成了Prometheus的高可用,不需要额外引入其它的组件
- 在不宕机重启的情况下,维护成本很低
- 缺点:
- Prometheus故障重启后,该节点故障期间的数据会部分丢失。将另一个节点的数据拷贝过来也是需要大量时间。仅限于需要高可用,但是对数据完整性要求不高的场景。
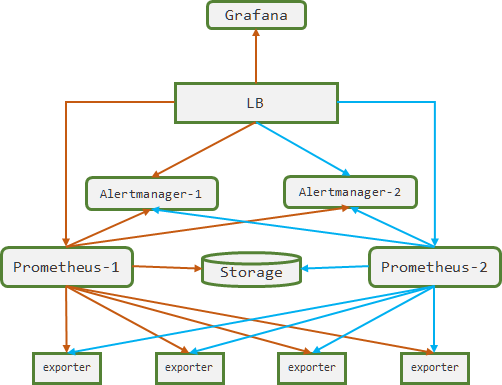
1.3.2. 远程存储的方案
- 方案:
- 与上述方案类似,只是数据持久化到一个远程存储设备,该远程存储设备最好支持读和写操作
- 优点:
- 本地Prometheus只需要存储少量的热点数据用于告警和热点查询,其它数据仅在查询时从远程存储读取
- 缺点:
- 两个Prometheus同时向一个远程存储写数据,会导致数据重复写入和数据直接的冲突问题。为了解决这个问题,两种方案可以参考:1. 增加过滤器对写入的数据进行去重;2. 引入其它服务或者控制器保证只有一台Prometheus处于工作状态,即两台prometheus互为主备,LB的请求始终指向主Prometheus
1.4. Thanos
其实Prometheus高可用集群方案的痛点在两个方面:1. Prometheus的数据如何长期存储(比如2-3个月) ? 2. 不同Prometheus之间的数据如何聚合和去重?Thanos 提供一种高可用和长期存储的 Prometheus 监控套件,并将他们变成了一个二进制文件,通过不同的子命令实现不同的功能,与 k3s 类似。详细的技术细节可以通过官方网站查询。目前还处于快速更新迭代的状态,暂时保持观望态度。
1.4.1. Thanos架构图
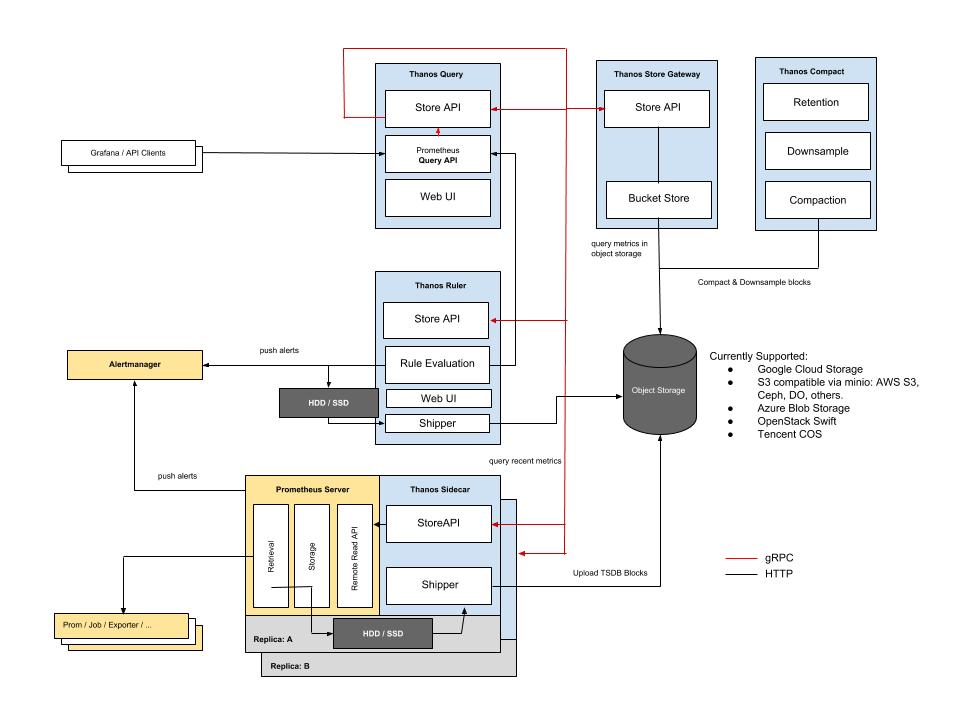
1.4.1. Thanos Query
Tanos Query 提供了能解析 PromQL的HTTP API 接口,Grafana 和其它查询客户端可以直接接入 Thanos Query API。Thanos Query 设计了查询模块 Store API的grpc模块,当用户查询指标时,请求先到 Thanos Query,然后 Store API 再去下游多个存储数据节点查询数据,并将数据汇总去重后返回给用户。
1.4.2. Thanos Sidecar
Thanos Sidecar 是和Prometheus进程部署在一个Pod或者虚拟机上,其作用有两个:
- 将Prometheus的数据定期上传到对象存储中进行持久化存储,需要注意的是,Prometheus不能压缩数据,否则容易上传失败
提供Store API,用于查询Prometheus本地的临时数据
1.4.3. Thanos Store Gateway
Thanos Store Gateway 提供了历史数据查询接口Store API,并且对历史数据进行缓存和查询索引优化,占用的内存和CPU较高。
1.4.4. Thanos Compact
Thanos Compact 将旧的数据进行压缩和降低采样率,进而减少历史数据的数量,从而降低磁盘消耗和提高查询速度。
1.4.5. Thanos Ruler
Thanos Ruler 实现了Prometheus中 recording rules 和 alerting rules ,在集群的环境下,各个Prometheus上数据不完整,可能不足以实现规则的评估,因此引出了 Ruler 组件。
1.5. 不同场景监控策略
1.5.1. Target发现方式
通常Target都推荐使用Prometheus自动发现机制去实现,避免了频繁修改Prometheus配置文件。常用的自动发现方式有:基于kubernets自动发现、文件自动发现、consul自动发现、其它注册中心的自动发现,以及自定义的自动发现规则。
其中自定义发现规则通常需要一定的编码能力,官方推荐不要入侵Prometheus,即不要修改Prometheus代码,避免后面升级的麻烦。推荐的方式是,在Prometheus中配置基于文件的自动发现规则,通过独立的程序定时更新这些自动发现的文件,好处就是大幅度降低开发难度,甚至不要求使用go语言就能实现。举个栗子,可以使用Python脚本实现,定时从CMDB接口中获取机器列表信息和label信息,并按照Prometheus的规则更新自动发现文件。1.5.2. 黑百盒监控
白盒监控是侧重获取目标对象的状态信息,比如node_exporter,redis_exporter等,这些信息会保留较长的时间,这些信息往往需要不同的 exporter 来实现。
黑盒监控是侧重获取目标对象的可用性,通常使用 blackbox_exporter实现,可以对 http/https/tcp/icmp 协议的目标地址进行监控。- job_name: 'blackbox' metrics_path: /probe params: module: [http_2xx] static_configs: - targets: - http://web.ddn.com - http://blog.ddn.com - http://deploy.ddn.com relabel_configs: - source_labels: [__address__] target_label: __param_target # __parm_<name>=value 是特殊内置标签类型,会转成param参数: <name>=value - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: 127.0.0.1:9115 # blackbox地址。改写后地址为: http://127.0.0.1:9115/probe?module=http_2xx&target=<target>1.5.3. 自定义监控
从传统运维的角度来看,关注的虚拟机监控指标有以下几个:
机器状态信息,如CPU、内存、磁盘、网络等。这些 node_exporter 能采集到
- 开源软件的状态信息,如MySQL,Redis,Nginx等。这些已经有成熟的开源软件来实现
- 业务软件的状态信息,如新注册用户数、top10文章点击量、发帖数量等。这些由业务程序自行暴露/metrics接口
- 当前业务/机器可用性,如机器是否宕机、业务API是否联通、TCP端口是否正常能响应。这些由 blackbox exporter 实现
- 业务进程状态,消耗的CPU、内存等。这些推荐自行开发,思路如下:
2. 虚拟机监控
2.1. 虚拟机监控设计
虚拟机暴露的 exporter 接口注册到 consul 中,Prometheus 通过consul自动发现服务获取注册的 target 信息。Nginx作为代理服务器,代理 Grafana、Prometheus、Alertmanager的HTTP接口,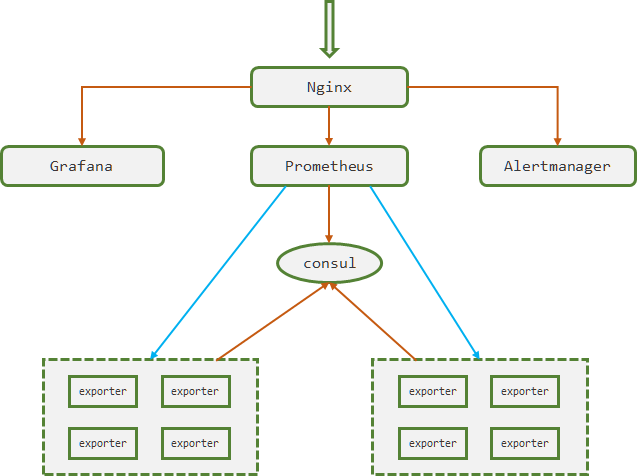
| 主机名 | IP | 配置 | OS | Role |
|---|---|---|---|---|
| prometheus-71 | 10.4.7.71 | 2C 4G | CentOS 7.5 | Prometheus |
| Alertmanager | ||||
| grafana-79 | 10.4.7.79 | 2C 4G | CentOS 7.5 | Grafana |
| Consul | ||||
| Nginx | ||||
| ubuntu-61 | 10.4.7.61 | 2C 4G | Ubuntu 1804 | node_exporter |
| process_exporter | ||||
| ubuntu-62 | 10.4.7.62 | 2C 4G | Ubuntu 1804 | node_exporter |
| process_exporter | ||||
| ubuntu-63 | 10.4.7.63 | 2C 4G | Ubuntu 1804 | node_exporter |
| process_exporter |
2.2. 部署过程
2.2.1. 部署时间同步服务
prometheus-71和grafana-79 是centos系统,
scan_host.sh参考: https://www.yuque.com/duduniao/linux/me34z0#mZWn5[root@duduniao ~]# scan_host.sh cmd -h 10.4.7.71 10.4.7.79 "yum install -y chrony" # 跳板机执行批量安装 [root@prometheus-71 ~]# vim /etc/chrony.conf # 修改ntp服务地址,并启动守护进程 server ntp1.aliyun.com iburst server ntp2.aliyun.com iburst server ntp3.aliyun.com iburst server ntp4.aliyun.com iburst ...... [root@prometheus-71 ~]# systemctl status chronydubuntu-61,ubuntu-62,ubuntu-63是ubuntu系统
[root@duduniao ~]# scan_host.sh cmd -h 10.4.7.61 10.4.7.62 10.4.7.63 "apt-get install -y chrony" root@ubuntu-7-61:~# vim /etc/chrony/chrony.conf pool ntp1.aliyun.com iburst maxsources 4 pool ntp2.aliyun.com iburst maxsources 1 pool ntp3.aliyun.com iburst maxsources 1 pool ntp4.aliyun.com iburst maxsources 2 ...... root@ubuntu-7-63:~# systemctl restart chronyd2.2.2. 部署consul
当前的consul仅仅作为Prometheus服务发现方式,不对此作高可用和额外配置,企业中应该使用CMDB或者已有的注册中心。 ``` [root@grafana-79 ~]# cd /opt/src/ [root@grafana-79 src]# wget https://releases.hashicorp.com/consul/1.8.4/consul_1.8.4_linux_amd64.zip [root@grafana-79 src]# mkdir /opt/release/consul_1.8.4 [root@grafana-79 src]# unzip consul_1.8.4_linux_amd64.zip -d /opt/release/consul_1.8.4/ [root@grafana-79 src]# ln -s /opt/release/consul_1.8.4 /opt/apps/consul [root@grafana-79 ~]# mkdir -p /data/consul /opt/logs/consul [root@grafana-79 ~]# groupadd -g 9090 monitor [root@grafana-79 ~]# useradd -g 9090 -u 9090 -s /sbin/nologin -M monitor [root@grafana-79 ~]# chown -R monitor.monitor /data/consul/ /opt/release/consul_1.8.4 /opt/logs/consul/ [root@grafana-79 ~]# vim /usr/lib/systemd/system/consul.service [Unit] Description=consul service After=network.target ntpdate.service sntp.service ntpd.service chronyd.service
[Service] User=monitor Group=monitor KillMode=control-group Restart=on-failure RestartSec=60 ExecStart=/opt/apps/consul/consul agent -dev -client=0.0.0.0 -data-dir=/data/consul -bind=0.0.0.0 -log-file=/opt/logs/consul/consul.log -log-rotate-max-files=3
[Install] WantedBy=multi-user.target [root@grafana-79 ~]# systemctl daemon-reload [root@grafana-79 ~]# systemctl start consul.service && systemctl enable consul.service
<a name="Olpc5"></a>
#### 2.2.3. 安装Nginx
一般情况下,内网应该配置DNS服务器,统一做内网域名解析,访问HTTP/HTTPS服务的时候,都走Nginx的代理层。本实验的域名解析,都使用 `/etc/hosts` 实现
[root@grafana-79 ~]# yum install -y gcc gcc-c++ pcre pcre-devel zlib zlib-devel openssl openssl-devel [root@grafana-79 ~]# useradd -u 8080 -M -s /sbin/nologin nginx [root@grafana-79 ~]# cd /opt/src/ ; wget -e “http_proxy=http://10.4.7.1:10080“ -e “https_proxy=http://10.4.7.1:10080“ https://nginx.org/download/nginx-1.14.2.tar.gz [root@grafana-79 src]# tar -xf nginx-1.14.2.tar.gz [root@grafana-79 src]# cd nginx-1.14.2/ [root@grafana-79 nginx-1.14.2]# ./configure —prefix=/opt/release/nginx-1.14.2 —user=nginx —group=nginx —with-http_ssl_module && make -j 2 && make install [root@grafana-79 nginx-1.14.2]# ln -s /opt/release/nginx-1.14.2 /opt/apps/nginx [root@grafana-79 nginx-1.14.2]# vim /opt/apps/nginx/conf/nginx.conf worker_processes auto; events { worker_connections 1024; } pid /opt/logs/nginx/nginx.pid; http { include mime.types; default_type application/octet-stream; error_log /opt/logs/nginx/error.log error ; log_format access ‘$time_local|$http_x_real_ip|$remote_addr|$http_x_forwarded_for|$upstream_addr|’ ‘$request_method|$server_protocol|$host|$request_uri|$http_referer|$http_user_agent|’ ‘$proxy_host|$status’ ; access_log /opt/logs/nginx/access.log access ;
sendfile on;
keepalive_timeout 65;
include conf.d/*.conf;
} [root@grafana-79 nginx-1.14.2]# vim /usr/lib/systemd/system/nginx.service [Unit] Description=nginx server After=network-online.target remote-fs.target nss-lookup.target Wants=network-online.target
[Service] Type=forking PIDFile=/opt/logs/nginx/nginx.pid ExecStartPre=/opt/apps/nginx/sbin/nginx -t -c /opt/apps/nginx/conf/nginx.conf ExecStart=/opt/apps/nginx/sbin/nginx -c /opt/apps/nginx/conf/nginx.conf ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s TERM $MAINPID
[Install] WantedBy=multi-user.target [root@grafana-79 ~]# systemctl daemon-reload; systemctl start nginx; systemctl enable nginx
```
[root@grafana-79 ~]# vim /opt/apps/nginx/conf/conf.d/consul.conf
server {
server_name consul.ddn.com;
listen 80;
location / {
proxy_pass http://10.4.7.79:8500 ;
}
}
[root@grafana-79 ~]# systemctl reload nginx.service
2.2.4. 部署Alertmanager
alertmanager部署和配置参考 02-4-告警管理 中的说明文档,alertmanager部署完毕后,配置nginx
[root@grafana-79 ~]# vim /opt/apps/nginx/conf/conf.d/alertmanager.conf
server {
server_name alertmanager.ddn.com;
listen 80;
error_page 500 502 503 504 /50x.html;
location / {
proxy_pass http://10.4.7.71:9093;
}
location =50x.html {
return 403 "error request\n";
}
}
[root@grafana-79 ~]# systemctl reload nginx.service
2.2.5. 部署prometheus
Prometheus配置文件详解,参考 02-2-Prometheus配置
[root@prometheus-71 ~]# cd /opt/src/
[root@prometheus-71 src]# wget https://github.com/prometheus/prometheus/releases/download/v2.22.0-rc.0/prometheus-2.22.0-rc.0.linux-amd64.tar.gz
[root@prometheus-71 src]# tar -xf prometheus-2.22.0-rc.0.linux-amd64.tar.gz -C /opt/release/
[root@prometheus-71 src]# ln -s /opt/release/prometheus-2.22.0-rc.0.linux-amd64 /opt/apps/prometheus
[root@prometheus-71 src]# mkdir /opt/apps/prometheus/rules.d/
[root@prometheus-71 src]# vim /opt/apps/prometheus/prometheus.yml
global:
scrape_interval: 60s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'prometheus'
consul_sd_configs:
- server: consul.ddn.com
services: ["monitor"]
tags: ["prometheus"]
refresh_interval: 60s
- job_name: 'node_exporter'
consul_sd_configs:
- server: consul.ddn.com
services: ["monitor"]
tags: ["node_exporter"]
refresh_interval: 60s
alerting:
alertmanagers:
- timeout: 10s
static_configs:
- targets: ["10.4.7.72:9093"]
rule_files:
- /opt/apps/prometheus/rules.d/node_exporter_alerting.yaml
[root@prometheus-71 src]# vim /opt/apps/prometheus/rules.d/node_exporter_alerting.yaml # 生产中应该配置的更详细
groups:
- name: node_resource
rules:
- alert: node_cpu_used_percent_alert_info
expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by (host,instance,job) >= 0.8
labels:
level: info
type: cpu
annotations:
summary: "cpu used more than 80%"
value: "{{ $value }}"
for: 3m
- alert: node_cpu_used_percent_alert_warn
expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by (host,instance,job) >= 0.8
labels:
level: warn
type: cpu
annotations:
summary: "cpu used more than 80%"
value: "{{ $value }}"
for: 20m
- name: node_base_info
rules:
- alert: node_unreachable # 主机不可达
expr: up{job="node"} == 0
labels:
level: error
type: node
annotations:
summary: "host unreachable"
value: "{{ $value }}"
for: 10s
[root@prometheus-71 src]# mkdir -p /data/prometheus
[root@prometheus-71 src]# chown -R monitor.monitor /opt/release/prometheus-2.22.0-rc.0.linux-amd64 /data/prometheus/
[root@prometheus-71 ~]# vim /usr/lib/systemd/system/prometheus.service
[Unit]
Description=prometheus service
# 如果该机器上部署了时间同步服务或者ntp脚本,不太建议设置开机自启动
# 非常容易出现 Error on ingesting samples that are too old or are too far into the future
After=network.target ntpdate.service sntp.service ntpd.service chronyd.service
[Service]
User=monitor
Group=monitor
KillMode=control-group
Restart=on-failure
RestartSec=60
ExecStart=/opt/apps/prometheus/prometheus --config.file=/opt/apps/prometheus/prometheus.yml --web.console.templates=/opt/apps/prometheus/consoles --web.console.libraries=/opt/apps/prometheus/console_libraries --storage.tsdb.path=/data/prometheus --log.level=info
ExecReload=/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target
[root@prometheus-71 ~]# systemctl daemon-reload
[root@prometheus-71 ~]# systemctl start prometheus.service .
[root@prometheus-71 ~]# systemctl enable prometheus.service
配置Nginx代理
[root@grafana-79 ~]# cat /opt/apps/nginx/conf/conf.d/prometheus.conf
server {
server_name prometheus.ddn.com;
listen 80;
error_page 500 502 503 504 /50x.html;
location / {
proxy_pass http://10.4.7.71:9090;
}
location =50x.html {
return 403 "error request\n";
}
}
[root@grafana-79 ~]# systemctl reload nginx.service
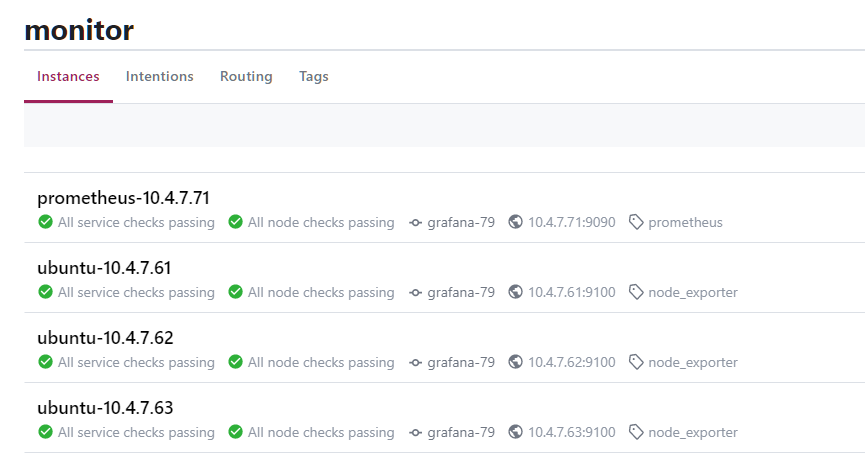
注册Prometheus到consul中。当前的场景中只有一台prometheus,其实意义不大,可以直接配置 localhost:9090 ,但是当存在多个prometheu实例时,就有必要用注册中心统一管理。这里踩到一个坑:如果curl命令无法注册和取消注册,先更新curl命令: yum update curl
[root@prometheus-71 ~]# cat /tmp/request.json # name 统一为monitor,id作为唯一标识,区分各个exporter,tags作为过滤标签
{
"ID":"prometheus-10.4.7.71",
"Name":"monitor",
"Address":"10.4.7.71",
"Port": 9090,
"Tags": ["prometheus"],
"Check":{
"HTTP":"http://10.4.7.71:9090/-/healthy",
"Interval":"30s"
}
}
[root@prometheus-71 ~]# curl -XPUT http://consul.ddn.com/v1/agent/service/register -d@/tmp/request.json # 注册服务
[root@prometheus-71 ~]# curl --request PUT http://consul.ddn.com/v1/agent/service/deregister/prometheus-10.4.7.71 # 注销服务
2.2.6. 部署node_exporter
ubuntu-61, ubuntu-62, ubuntu-63 操作安装node_exporter步骤一致
root@ubuntu-7-61:~# cd /opt/src/
root@ubuntu-7-61:/opt/src# wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz
root@ubuntu-7-61:/opt/src# tar -xf node_exporter-1.0.1.linux-amd64.tar.gz -C /opt/release/
root@ubuntu-7-61:/opt/src# ln -s /opt/release/node_exporter-1.0.1.linux-amd64 /opt/apps/node_exporter
root@ubuntu-7-61:/opt/src# groupadd -g 9100 monitor
root@ubuntu-7-61:/opt/src# useradd -g 9100 -u 9100 -s /sbin/nologin -M monitor
root@ubuntu-7-61:/opt/src# chown -R monitor.monitor /opt/release/node_exporter-1.0.1.linux-amd64
root@ubuntu-7-61:/opt/src# vim /lib/systemd/system/node_exporter.service
[Unit]
Description=node-exporter service
After=network.target
[Service]
User=monitor
Group=monitor
KillMode=control-group
Restart=on-failure
RestartSec=60
# 启动参数可以使用 /opt/apps/node_exporter/node_exporter --help 查看
ExecStart=/opt/apps/node_exporter/node_exporter --collector.disable-defaults --log.level=error --collector.cpu --collector.meminfo --collector.cpu.info --collector.diskstats --collector.ipvs --collector.loadavg --collector.netclass
[Install]
WantedBy=multi-user.target
root@ubuntu-7-61:/opt/src# systemctl daemon-reload
root@ubuntu-7-61:/opt/src# systemctl start node_exporter.service
root@ubuntu-7-61:/opt/src# systemctl enable node_exporter.service
注册 node_exporter 到consul中,每个服务的ID和
root@ubuntu-7-61:~# cat /tmp/request.json
{
"ID":"ubuntu-10.4.7.61",
"Name":"monitor",
"Address":"10.4.7.61",
"Port": 9100,
"Tags": ["node_exporter"],
"Check":{
"HTTP":"http://10.4.7.61:9100/healthy",
"Interval":"30s"
}
}
root@ubuntu-7-61:~# curl -XPUT http://consul.ddn.com/v1/agent/service/register -d@/tmp/request.json
3. Kubernetes监控
参考:https://www.yuque.com/duduniao/k8s/zoky08
后续会进一步补充


若有收获,就点个赞吧
0 人点赞
