- 1. 概念
- HELP node_cpu_seconds_total Seconds the cpus spent in each mode.
- TYPE node_cpu_seconds_total counter
- HELP node_load5 5m load average.
- TYPE node_load5 gauge
- HELP prometheus_http_request_duration_seconds Histogram of latencies for HTTP requests.
- TYPE prometheus_http_request_duration_seconds histogram
- HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
- TYPE go_gc_duration_seconds summary
- 2. Prometheus基本配置
- 全局配置
- 从各个target上获取监控指标的时间间隔
- 获取监控指标时超时时间
- 评估规则时间间隔
- 与外部系统通信时对时间序列或者告警信息添加的标签,如remote storage、alertmanager等
- PromQL查询日志,reload操作会重新打开日志
- 外部规则文件列表,会从这些文件中读取rules和alerts
- 抓取监控的规则配置
- 告警配置
- 告警标签重写
- alertmanager 配置
- 可写入的远程存储
- 可读取的远程存储
- 远程写入的地址
- 远程存储响应超时时间
- 对时间序列数据进行标签重写
- 远程存储的标识
- 请求远程存储时,在header中加入Authorization认证
- TLS配置
- 代理配置
- 配置远程存储写入的队列
- 每个分片中最大样本缓冲数量,超过将阻塞从WAL中读取,建议适当调大
- 最大分片数,即并发数
- 最小分片数,即并发数
- 每次发送的样本数
- 样本在缓冲区过期时间
- 初始重试延迟,每次重试都会翻倍
- 最大重试延迟
- 3. prometheus配置案例
1. 概念
1.1. 时间序列
时间序列指在连续等间隔的时间点上获取的数据值,存储时间序列数据的数据库称为时间序列数据库Time Series Database (TSDB),时间序列数据库特点是写远大于读,并且写入平稳,基本不会涉及更新操作。Prometheus从本质上来说,就是将所有监控指标存储为时间序列,默认存在宿主机上。Prometheus的每个时间序列通过metirc name和label来标识的。
Prometheus中常见的几个名词:
- 时间序列(time-series):时间序列,也成为向量(vector)
- 时间戳(timestamp):精确到毫秒的时间戳
- 指标(metric):由指标的名称(metric name)和当前指标的标签(lable)组成,格式:
<metric name>{<label name>=<label value>, ...}1- metric name:指标名称匹配正则表达式:
[a-zA-Z_:][a-zA-Z0-9_:]* - label: 标签匹配
[a-zA-Z_][a-zA-Z0-9_]*,__开头的标签仅内部使用
- metric name:指标名称匹配正则表达式:
-
1.2. 指标类型
1.2.1. 基本类型
当前prometheus提供了四种指标类型(metric type),这四种表达的含义不同,在查询语句中需要进行区分。
计数器(Counter)
Counter是一个在运行中单调递增的数字,比如CPU时间片信息,只有当系统或者服务重启才会置零。
- 仪表盘(Gauge)
Gauge是一个可增可减的数字,比如进程数量,可用内存大小等。
- 直方图(Histogram)
直方图对观察值(通常是请求持续时间或响应大小之类的东西)进行采样,并将其计数在可配置的bucket中。它还提供所有观察值的总和,这是一种复杂的数据类型,个别指标才会使用的数据类型。在一次取样中会暴露多个时间序列信息,比如:
<basename>_bucket{le="<upper inclusive bound>"}bucket 的累计计数器<basename>_sum观测值总和<basename>_count观测的指标计数
通过 histogram_quantile() 可以计算分位数
- 摘要(Summary)
类似于直方图,摘要会采样观察值(通常是请求持续时间和响应大小之类的东西)。虽然它还提供了观测值的总数和所有观测值的总和,但它可以计算滑动时间窗口内的可配置分位数,在一次取样中会暴露多个时间序列信息,比如:
<basename>{quantile="<φ>"}观测事件的φ分位数(0≤φ≤1)<basename>_sum观测值的综合<basename>_count观测的事件数量1.2.2. 类型区分
metircs 接口中会对每一种类型的指标给出类型提示: ```
仪表盘类型(10.4.7.71:9100/metrics)
HELP node_load5 5m load average.
TYPE node_load5 gauge
node_load5 0.1
直方图类型(10.4.7.72:9090/metrics)
HELP prometheus_http_request_duration_seconds Histogram of latencies for HTTP requests.
TYPE prometheus_http_request_duration_seconds histogram
prometheus_http_request_duration_seconds_bucket{handler=”/api/v1/label/:name/values”,le=”0.1”} 1 prometheus_http_request_duration_seconds_bucket{handler=”/api/v1/label/:name/values”,le=”0.2”} 1 prometheus_http_request_duration_seconds_bucket{handler=”/api/v1/label/:name/values”,le=”0.4”} 1 prometheus_http_request_duration_seconds_bucket{handler=”/api/v1/label/:name/values”,le=”1”} 1 prometheus_http_request_duration_seconds_bucket{handler=”/api/v1/label/:name/values”,le=”3”} 1 prometheus_http_request_duration_seconds_bucket{handler=”/api/v1/label/:name/values”,le=”8”} 1 prometheus_http_request_duration_seconds_bucket{handler=”/api/v1/label/:name/values”,le=”20”} 1 prometheus_http_request_duration_seconds_bucket{handler=”/api/v1/label/:name/values”,le=”60”} 1 prometheus_http_request_duration_seconds_bucket{handler=”/api/v1/label/:name/values”,le=”120”} 1 prometheus_http_request_duration_seconds_bucket{handler=”/api/v1/label/:name/values”,le=”+Inf”} 1 prometheus_http_request_duration_seconds_sum{handler=”/api/v1/label/:name/values”} 0.001787999
摘要类型(10.4.7.71:9100/metrics)
HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile=”0”} 0 go_gc_duration_seconds{quantile=”0.25”} 0 go_gc_duration_seconds{quantile=”0.5”} 0 go_gc_duration_seconds{quantile=”0.75”} 0 go_gc_duration_seconds{quantile=”1”} 0 go_gc_duration_seconds_sum 0 go_gc_duration_seconds_count 0 ```
1.2.3. 摘要类型和直方图类型用途
摘要和直方图常用于请求时间、请求大小等可能会被个别事件严重影响平均值的场景,举个例子:假设我们关注业务中某个API请求响应的平均时间,大部分请求时间都在500ms以内,少数请求耗时超过10s,那么这些10秒得请求就导致平均请求时间不合理。因此需要知道不同请求时间段下请求得数量,或者95%得请求消耗得时间为多少等等。更多信息参考官方文档:https://prometheus.io/docs/practices/histograms/
2. Prometheus基本配置
Prometheus 配置分为两个部分,命令行传递的不可变配置,配置文件传递的可变配置。所谓不可变是指进程进行运行中是不可以动态更新。
2.1. prometheus命令行
Prometheus提供了两个可执行文件:prometheus 和 promtool,前者用于prometheus server的启停,后者为prometheus调试工具,常用于配置文件检查。
prometheus 常用参数,更多参考
prometheus --help-h, --help 显示帮助信息--version 显示版本--config.file="prometheus.yml" 指定配置文件--web.listen-address="0.0.0.0:9090" 指定监听的端口--web.max-connections=512 最大连接数--web.enable-lifecycle 是否开启reload和shutdown的远程API--web.enable-admin-api 是否开启管理API--web.console.templates="consoles" 控制台模板目录--web.console.libraries="console_libraries" 控制台库文件目录--storage.tsdb.path="data/" 数据存储路径--storage.tsdb.retention.time 数据保留时间,默认15天--query.timeout=2m 查询超时时间--query.max-concurrency=20 最大并发查询数量--query.max-samples=50000000 单次查询返回的最大样本数--log.level=info 日志级别: [debug, info, warn, error]--log.format=logfmt 日志输出格式:[logfmt, json]
promtool常用参数,更多参考
promtool --helpcheck config <config-files>... 检查配置文件 check rules <rule-files>... 检查规则文件2.2. 配置文件
更改prometheus配置文件后,可以通过两种方式动态重载:
发送
SIGHUP信号给prometheus进程- 调用
/-/reloadAPI,仅在启用--web.enable-lifecycle状态下
prometheus配置文件为 yaml 格式,以下文档中 [ ] 表示可选项,value的数据类型有以下几种:
<boolean>布尔值,true 或 false<duration>时间段,可精确到毫秒,如5m10s1m30s等<filename>文件名,路径相对于当前工作目录而言<host>主机,主机名(域名)/IP + 端口(可选)组成,如127.0.0.1:9090<int>整数<labelname>标签名称,符合正则表达[a-zA-Z_][a-zA-Z0-9_]*<labelvalue>标签值,unicode 字符串<path>URL路径<scheme>协议,支持http和https<secret>密钥,普通字符串格式<string>字符串<tmpl_string>模板字符串2.2.1. 一级字段
```yaml全局配置
global:从各个target上获取监控指标的时间间隔
[ scrape_interval:| default = 1m ] 获取监控指标时超时时间
[ scrape_timeout:| default = 10s ] 评估规则时间间隔
[ evaluation_interval:| default = 1m ] 与外部系统通信时对时间序列或者告警信息添加的标签,如remote storage、alertmanager等
external_labels: [: … ] PromQL查询日志,reload操作会重新打开日志
[ query_log_file:]
外部规则文件列表,会从这些文件中读取rules和alerts
rule_files:
[ -
抓取监控的规则配置
scrape_configs:
[ -
告警配置
alerting:
告警标签重写
alert_relabel_configs:
[ -
alertmanager 配置
alertmanagers:
[ -
可写入的远程存储
remote_write:
[ -
可读取的远程存储
remote_read:
[ -
<a name="7qxDS"></a>
#### 2.2.2. scrap_config
```yaml
# 当前抓取作业的名称
job_name: <job_name>
# 当前Job的抓取指标的时间间隔,默认采用全局配置
[ scrape_interval: <duration> | default = <global_config.scrape_interval> ]
# 每个target抓取超时时间
[ scrape_timeout: <duration> | default = <global_config.scrape_timeout> ]
# 抓取的API接口
[ metrics_path: <path> | default = /metrics ]
# 当抓取的指标中label与系统默认添加的冲突时如何处理
# 为true表示保留抓取的label,false表示对抓取的时间序列label重命名:expoted_<org_label_name>
[ honor_labels: <boolean> | default = false ]
# 当抓取的指标中时间戳存在冲突时如何处理
# true表示以exporter显示的时间为准,反之为 false
[ honor_timestamps: <boolean> | default = true ]
# 访问 metrics API 的协议,默认 http
[ scheme: <scheme> | default = http ]
# 访问 metrics API 的参数
params:
[ <string>: [<string>, ...] ]
# 访问 metrics API 时在header中添加 Authorization字段
# 内容为基本认证信息的用户名和密码。password和password_file互斥
basic_auth:
[ username: <string> ]
[ password: <secret> ]
[ password_file: <string> ]
# 访问 metrics API 时在header中添加 Authorization字段,内容为 token
# bearer_token_file和bearer_token互斥
[ bearer_token: <secret> ]
[ bearer_token_file: <filename> ]
# tls 配置
tls_config:
# 用于验证服务端的server证书的 CA 证书
[ ca_file: <filename> ]
# 客户端证书和key,用于被服务端验证
[ cert_file: <filename> ]
[ key_file: <filename> ]
# server_name 扩展名,指的就是服务器名称
[ server_name: <string> ]
# 禁用服务器证书验证
[ insecure_skip_verify: <boolean> ]
# 代理地址,部分跨网络的情况,可以采用正向代理
[ proxy_url: <string> ]
# 静态抓取目标配置,一般只有极个别场景才会配置,否则会导致主配置文件更新频繁,并且很臃肿
static_configs:
# 指定抓取目标的地址
targets:
[ - '<host>' ]
# 对采集到的数据指定额外的标签
labels:
[ <labelname>: <labelvalue> ... ]
# target 标签重写规则
relabel_configs:
[ - <relabel_config> ... ]
# metrics 标签重写规则
metric_relabel_configs:
[ - <relabel_config> ... ]
# 各类服务发现配置,涉及种类较多。常用有三种:
# 基于文件的自动发现规则: file_sd_configs
# 基于k8s的自动发现规则: kubernetes_sd_configs
# 基于consul的自动发现规则:consul_sd_configs
file_sd_configs:
[ - <file_sd_config> ... ]
kubernetes_sd_configs:
[ - <kubernetes_sd_config> ... ]
consul_sd_configs:
[ - <consul_sd_config> ... ]
azure_sd_configs:
[ - <azure_sd_config> ... ]
digitalocean_sd_configs:
[ - <digitalocean_sd_config> ... ]
dockerswarm_sd_configs:
[ - <dockerswarm_sd_config> ... ]
dns_sd_configs:
[ - <dns_sd_config> ... ]
ec2_sd_configs:
[ - <ec2_sd_config> ... ]
eureka_sd_configs:
[ - <eureka_sd_config> ... ]
gce_sd_configs:
[ - <gce_sd_config> ... ]
hetzner_sd_configs:
[ - <hetzner_sd_config> ... ]
marathon_sd_configs:
[ - <marathon_sd_config> ... ]
nerve_sd_configs:
[ - <nerve_sd_config> ... ]
openstack_sd_configs:
[ - <openstack_sd_config> ... ]
serverset_sd_configs:
[ - <serverset_sd_config> ... ]
triton_sd_configs:
[ - <triton_sd_config> ... ]
# 样本数限制,超过规定之则被丢弃。0表示不限制
[ sample_limit: <int> | default = 0 ]
# target 数量限制,超过的将被丢弃,目前为实验性功能。0表示不限制
[ target_limit: <int> | default = 0 ]
2.2.3. 自动发现规则
自动发现规则是prometheus非常大的亮点,通过配置自动发现规则来避免频繁更新配置文件的问题。举个栗子,比如在一个拥有自己的CMDB公司,当服务器的数量发生变化时,如果每次手动更新prometheus就会非常繁琐,此时可以开发一个通过CMDB查询所有机器列表的API接口,配合prometheus的自动发现规则,就能动态更新监控的主机列表。再比如在 k8s 集群环境中,需要对pod进行监控,而pod地址变化非常频繁,通过运维手动更新,此时只需要prometheus定期去apiServer查询资源列表,就能自动更新监控目标的地址和信息。
官方提供了几个自动发现插件,常用的有 基于文件、k8s、consul这三种。上面描述的 CMDB 的自动发现肯定是没有的,需要自己开发,可以参考官方的博客:https://prometheus.io/blog/2018/07/05/implementing-custom-sdu
2.2.3.1. 基于文件的自动发现规则
配置target 的文件可以是json也可以是yaml,推荐使用yaml,方便查看。
# 主配置文件中 <file_sd_config>
# 配置target的文件列表
files:
[ - <filename_pattern> ... ]
# 从这些文件中读取配置的时间间隔
[ refresh_interval: <duration> | default = 5m ]
# 自动发现文件配置案例
- targets:
- address1
- address2
labels:
labelname1: labelvalue1
labelname2: labelvalue2
2.2.3.2. 基于kubernetes自动发现规则
kubernetes 集群监控相对而言比较复杂,复杂在于标签重写。官方案例推荐:kubernetes-example
# api_server地址。如果prometheus在被监控集群内部,可以忽略该字段,
# 此时会自动使用pod的CA certificate和token (/var/run/secrets/kubernetes.io/serviceaccount/)
[ api_server: <host> ]
# 资源角色:可选 endpoints, service, pod, node, or ingress.
role: <string>
# Api server认证信息(可选)。`basic_auth`, `bearer_token` and `bearer_token_file` 互斥
basic_auth:
[ username: <string> ]
[ password: <secret> ]
[ password_file: <string> ]
[ bearer_token: <secret> ]
[ bearer_token_file: <filename> ]
# 代理地址
[ proxy_url: <string> ]
# TLS 配置
tls_config:
# 用于验证服务端的server证书的 CA 证书
[ ca_file: <filename> ]
# 客户端证书和key,用于被服务端验证
[ cert_file: <filename> ]
[ key_file: <filename> ]
# server_name 扩展名,指的就是服务器名称
[ server_name: <string> ]
# 禁用服务器证书验证
[ insecure_skip_verify: <boolean> ]
# namespace配置,不配置则起用所有名称空间
namespaces:
names:
[ - <string> ]
# 指定字段选择器和标签选择器
[ selectors:
[ - role: <string>
[ label: <string> ]
[ field: <string> ] ]]
Kuberntest自动发现中角色说明:
- node
指k8s集群内部节点监控,一个节点一个target,默认为 Kubelet 的 HTTP 地址。target的地址寻找优先级为: NodeInternalIP,NodeExternalIP,NodeLegacyHostIP,NodeHostName。内部标签 instance 将被设置为API中获取到的节点名称
- service
指k8s集群内部所有service监控,target 为service域名和端口,这个对 blackbox 监控很有用
- pod
暴露所有pod的容器端口,如果资源清单中没有指定端口,则添加为无端口的target
- endpoint
暴露所有service发现的endpoint地址作为target,每一个endpoint地址都是一个target。如果endpoint对应的Pod有其它未绑定endpoint的端口,也会生成target
- ingress
暴露ingress所有path路径,这个对 blackbox 监控很有帮助
2.2.3.3. consul 自动发现规则
consul 是基于go语言写的注册中心,在生产中可以作为prometheus自动发现的中间件。
# consul 地址信息
[ server: <host> | default = "localhost:8500" ]
[ token: <secret> ]
[ datacenter: <string> ]
[ scheme: <string> | default = "http" ]
[ username: <string> ]
[ password: <secret> ]
tls_config:
[ <tls_config> ]
# 自动发现请求访问哪些服务,默认是所有服务
services:
[ - <string> ]
# 过滤目标节点,只有全部包含这些tag的服务地址才会给prometheus认定为target
tags:
[ - <string> ]
# 通过元数据的键值对节点进行过滤
[ node_meta:
[ <string>: <string> ... ] ]
# The string by which Consul tags are joined into the tag label.
[ tag_separator: <string> | default = , ]
# Allow stale Consul results (see https://www.consul.io/api/features/consistency.html). Will reduce load on Consul.
[ allow_stale: <boolean> | default = true ]
# 访问consul的时间间隔
[ refresh_interval: <duration> | default = 30s ]
2.2.4. 标签重写
标签重写配置(relabel_config) 是实现的是对结果的标签重写、数据丢弃等操作,其功能非常强大,也属于 prometheus配置中比较复杂的部分。标签按名称的格式分为两类:
- 双下划线开头的
__为临时标签,在刚刚采集的数据中是存在的,但是经过一系列的 reblabel_confg 操作后,双下划线标签将被丢弃,不会入库。 - 非双下划线开头的标签会被正常入库。
需要注意的的是,用到这一套标签重写规则的配置有以下几个配置项:
- scrap_config 中 relabel_configs
- scrap_config 中 metric_relabel_configs
- alerting 中 alert_relabel_configs
每一个endpoint, 在relabel之前,都至少存在: job 、 __address__ 、 __metrics_path__ 、 __scheme__ ,relabel之后,这些双下划线的 label 不会入库。
对于 relabel 中,产生的临时标签规范建议使用 __tmp 开头标签命名
# 串联一组标签的值,用于后续操作
[ source_labels: '[' <labelname> [, ...] ']' ]
# source_labels 中各个标签值的拼接符
[ separator: <string> | default = ; ]
# 替换的结果会赋值给目标标签
[ target_label: <labelname> ]
# 匹配source_labels拼接后的值,系统会自动进行首尾锚定,去除锚定使用 .*<regex>.*
# 该正则表达式规范:https://github.com/google/re2/wiki/Syntax
# 分组的值可以被replacement引用($1,$2...)
[ regex: <regex> | default = (.*) ]
# 对source_labels的hash进行取模时指定的被除数
[ modulus: <int> ]
# 执行替换操作,可以引用正则表达式中的分组
[ replacement: <string> | default = $1 ]
# 执行的动作。支持: replace,drop,keep,labelmap,labeldrop,labelkeep,hashmod
[ action: <relabel_action> | default = replace ]
动作action具体包含以下几种:
- replace: regex匹配source_labels,替换为 replacement ,写入 target_label
- keep:删除regex与source_labels不匹配的target
- drop: 删除regex与source_labels匹配的target
- labelmap: 对所有标签key进行regex匹配(不是sourcelabels),将原标签的key替换为replacement指定的key,通常用于改写 `_` 开头的标签
- labeldrop: 对所有标签key进行regex匹配(不是source_labels),匹配到的标签被删除(不是target被删除)
- labelkeep: 对所有标签key进行regex匹配(不是source_labels),不匹配到的标签被删除(不是target被删除)
- hashmod: 当一个job中监控目标数量太多时(自动发现中容易出现),将任务分散到不同的机器上。hashmod会将 source_labels值哈希后采用 modulus 取余数,并赋值到一个标签,然后在接下来的relabel中进行保留或者剔除,这样能实现每个prometheus采集一部分target数据
2.2.5. alerting 配置
参考告警章节2.2.6. remote_write配置
在高可用场景中,或者需要数据集中存储的场景中,需要prometheus定期建时间序列数据写入远程存储数据库进行集中化管理。 ```yaml远程写入的地址
url:
远程存储响应超时时间
[ remote_timeout:
对时间序列数据进行标签重写
write_relabel_configs:
[ -
远程存储的标识
[ name:
请求远程存储时,在header中加入Authorization认证
basic_auth:
[ username:
TLS配置
tls_config:
[ ca_file:
代理配置
[ proxy_url:
配置远程存储写入的队列
queue_config:
每个分片中最大样本缓冲数量,超过将阻塞从WAL中读取,建议适当调大
[ capacity:
最大分片数,即并发数
[ max_shards:
最小分片数,即并发数
[ min_shards:
每次发送的样本数
[ max_samples_per_send:
样本在缓冲区过期时间
[ batch_send_deadline:
初始重试延迟,每次重试都会翻倍
[ min_backoff:
最大重试延迟
[ max_backoff:
<a name="xJfRd"></a>
#### 2.2.7. remote_read配置
prometheus 可以从远程存储读取时间序列数据
```yaml
# 远程存储读取地址
url: <string>
# 远程存储标识
[ name: <string> ]
required_matchers:
[ <labelname>: <labelvalue> ... ]
# 读取超时时间
[ remote_timeout: <duration> | default = 1m ]
# 当查询的时间范围在本地存储数据保留的时间范围内,是否还去远程存储查询
[ read_recent: <boolean> | default = false ]
# 请求远程存储时,在header中加入Authorization认证
basic_auth:
[ username: <string> ]
[ password: <secret> ]
[ password_file: <string> ]
[ bearer_token: <string> ]
[ bearer_token_file: <filename> ]
# TLS配置
tls_config:
[ ca_file: <filename> ]
[ cert_file: <filename> ]
[ key_file: <filename> ]
[ server_name: <string> ]
[ insecure_skip_verify: <boolean> ]
# 代理配置
[ proxy_url: <string> ]
2.2.8. recording rule
在一级字段中,存在 rule_files 配置项,用于配置规则文件,规则文件分为两种:记录规则(recording rule)和报警规则(altering rule)。报警规则在告警管理中阐述。recording rules 目的是将常用的复杂查询结果周期性写入数据库,避免频繁计算带来的资源消耗,一般将dashboard中复杂查询写入recording rules 中。
groups:
# 组名,配置文件中不能重复
- name: <string>
# 多久计算计算一次
[ interval: <duration> | default = global.evaluation_interval ]
rules:
# 入库的指标名称
- record: <string>
# PromQL表达式
expr: <string>
# 标签
labels:
[ <labelname>: <labelvalue> ]
3. prometheus配置案例
3.1. relabel_configs 配置
prometheus 中难以理解的是标签重写规则,本节针对不同 action 进行 target 的标签重写,实验环境如下: 在 prometheus-72 上启动三个 node_exporter 实例,分别监听 8081, 8082, 8083 端口,prometheus-72 从这三个 node_exporter 中采集数据。
[root@prometheus-72 ~]# jobs
[1] Running /opt/apps/node_exporter/node_exporter --log.level=error --web.listen-address=":8081" &
[2]- Running /opt/apps/node_exporter/node_exporter --log.level=error --web.listen-address=":8082" &
[3]+ Running /opt/apps/node_exporter/node_exporter --log.level=error --web.listen-address=":8083" &
3.1.1. action: replace
- 重写规则之前: ```yaml [root@prometheus-72 prometheus]# cat prometheus.yml global: scrape_interval: 60s external_labels: monitor: ‘codelab-monitor’
scrape_configs:
- job_name: ‘node’
static_configs:
- targets: [“10.4.7.72:8081”] labels: app: app-01 env: dev role: master
- targets: [“10.4.7.72:8082”] labels: app: app-02 env: prod role: master
- targets: [“10.4.7.72:8083”] labels: app: app-02 env: prod role: slave
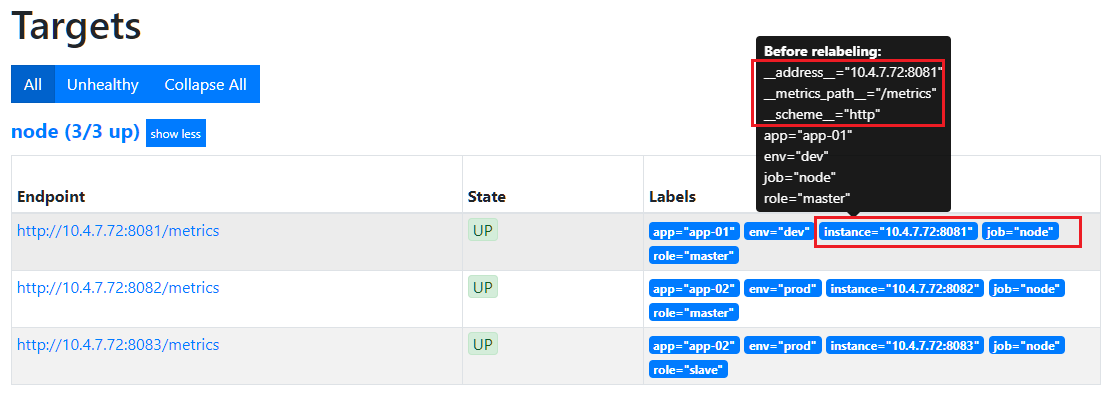
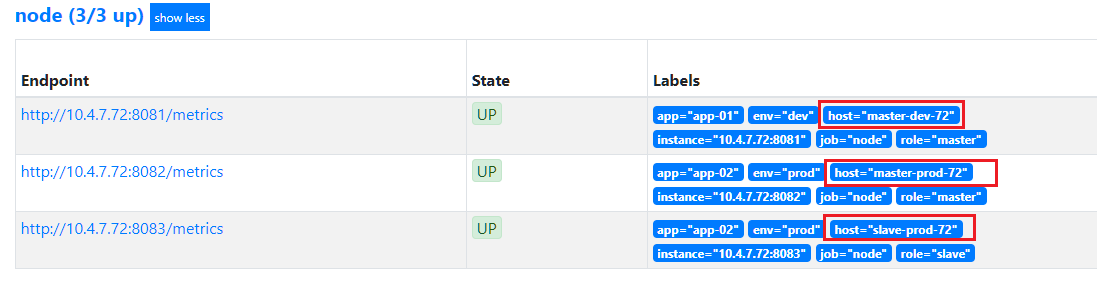
- 添加新标签host,使其格式为: master-dev-72
```yaml
global:
scrape_interval: 60s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ["10.4.7.72:8081"]
labels:
app: app-01
env: dev
role: master
- targets: ["10.4.7.72:8082"]
labels:
app: app-02
env: prod
role: master
- targets: ["10.4.7.72:8083"]
labels:
app: app-02
env: prod
role: slave
relabel_configs:
- source_labels: ["role", "env", "__address__"]
target_label: host
regex: (.+);(.+);([0-9]{1,3}\.){3}([0-9]+):[0-9]+ # source_labels默认 ; 拼接
replacement: $1-$2-$4
3.1.2. action: keep
global:
scrape_interval: 60s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ["10.4.7.72:8081"]
labels:
app: app-01
env: dev
role: master
- targets: ["10.4.7.72:8082"]
labels:
app: app-02
env: prod
role: master
- targets: ["10.4.7.72:8083"]
labels:
app: app-02
env: prod
role: slave
relabel_configs:
- source_labels: ["role", "env", "__address__"]
target_label: host
regex: (.+);(.+);([0-9]{1,3}\.){3}([0-9]+):[0-9]+ # source_labels默认 ; 拼接
replacement: $1-$2-$4
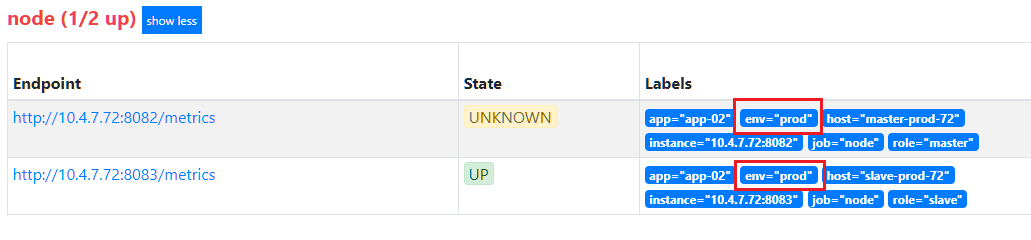
- source_labels: ["env"] # 仅保留 env=prod 的target
regex: prod
action: keep
3.1.3. action: drop
global:
scrape_interval: 60s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ["10.4.7.72:8081"]
labels:
app: app-01
env: dev
role: master
- targets: ["10.4.7.72:8082"]
labels:
app: app-02
env: prod
role: master
- targets: ["10.4.7.72:8083"]
labels:
app: app-02
env: prod
role: slave
relabel_configs:
- source_labels: ["role", "env", "__address__"]
target_label: host
regex: (.+);(.+);([0-9]{1,3}\.){3}([0-9]+):[0-9]+ # source_labels默认 ; 拼接
replacement: $1-$2-$4
- source_labels: ["env"] # 删除 lable_name 为env,切value为prod的target
regex: prod
action: drop

3.1.4. action: labelkeep
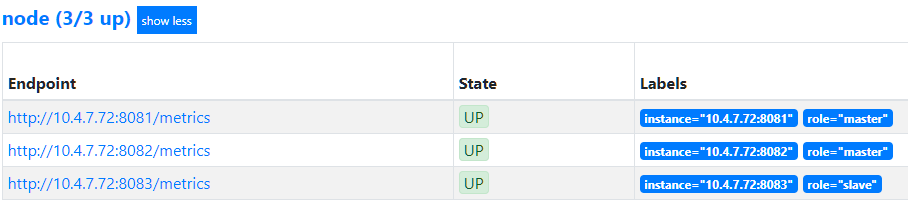
尽量不要删除 __ 的标签,比如删了 __address__ 标签会导致 instance 生成异常,进而导致无法获取target信息
[root@prometheus-72 prometheus]# cat prometheus.yml
global:
scrape_interval: 60s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ["10.4.7.72:8081"]
labels:
app: app-01
role: master
- targets: ["10.4.7.72:8082"]
labels:
app: app-02
env: prod
role: master
- targets: ["10.4.7.72:8083"]
labels:
app: app-02
env: prod
role: slave
relabel_configs:
- regex: (__|role).* # 非临时标签仅保留 role
action: labelkeep
3.1.5. action: labeldrop
global:
scrape_interval: 60s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ["10.4.7.72:8081"]
labels:
app: app-01
role: master
- targets: ["10.4.7.72:8082"]
labels:
app: app-02
env: prod
role: master
- targets: ["10.4.7.72:8083"]
labels:
app: app-02
env: prod
role: slave
relabel_configs:
- regex: env # 将env标签删除,并是上次target
action: labeldrop

3.1.6. action: labelmap
global:
scrape_interval: 60s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ["10.4.7.72:8081"]
labels:
app: app-01
role: master
- targets: ["10.4.7.72:8082"]
labels:
app: app-02
env: prod
role: master
- targets: ["10.4.7.72:8083"]
labels:
app: app-02
env: prod
role: slave
relabel_configs:
- regex: __(.+)__ # 将所有双下划线的标签名改为非双下划线的标签名称
action: labelmap
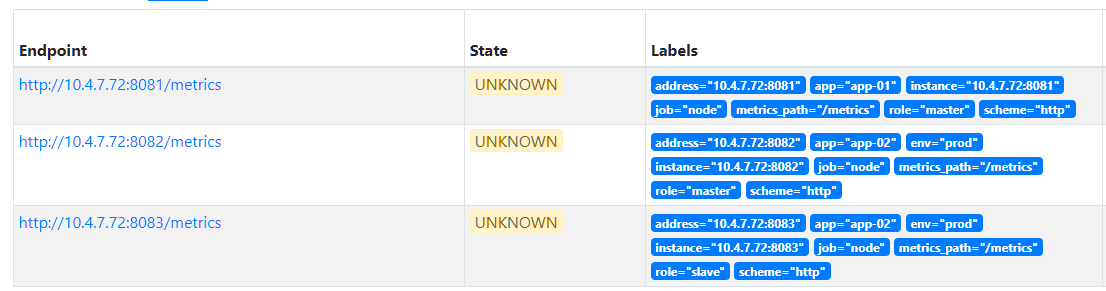
3.1.7. action: hashmod
当一个job中监控目标数量太多时(自动发现中容易出现),将任务分散到不同的机器上。hashmod会将 source_labels值哈希后采用 modulus 取余数,并赋值到一个标签,然后在接下来的relabel中进行保留或者剔除,这样能实现每个prometheus采集一部分target数据。下面案例中,其余后 __tmp_hash_value 值有 0、1、2,因此将target分为三组,可以由三个不同的prometheus去获取监控指标。
global:
scrape_interval: 60s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ["10.4.7.72:8081"]
labels:
app: app-01
role: master
- targets: ["10.4.7.72:8082"]
labels:
app: app-02
env: prod
role: master
- targets: ["10.4.7.72:8083"]
labels:
app: app-02
env: prod
role: slave
relabel_configs:
- source_labels: ["__address__"]
action: hashmod
modulus: 3
target_label: __tmp_hash_value
- source_labels: [__tmp_hash_value]
regex: "0"
action: drop
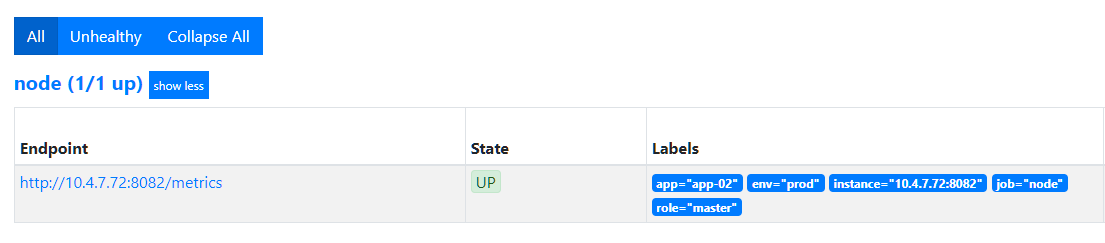
3.2. recording rule 配置
# cat prometheus.yml
global:
scrape_interval: 60s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets:
- "10.4.7.72:9100"
- "10.4.7.79:9100"
relabel_configs:
- source_labels: [__address__]
regex: (.+):[0-9]+
target_label: host
rule_files:
- /opt/apps/prometheus/rules.d/node_exporter.yaml
# cat rules.d/node_exporter.yaml
groups:
- name: node_cpu_rules
rules:
- record: node_cpu_avg_used_perecent
expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by (host,instance,job) * 1
- name: node_filesystem_rules
rules:
- record: node_filesystem_avail_percent
expr: node_filesystem_avail_bytes {fstype=~"ext.*|xfs",mountpoint !~".*pod.*"} / node_filesystem_size_bytes{fstype=~"ext.*|xfs",mountpoint !~".*pod.*"}
- record: node_inode_avail_percent
expr: node_filesystem_files_free{fstype=~"ext.*|xfs",mountpoint !~".*pod.*"}/node_filesystem_files{fstype=~"ext.*|xfs",mountpoint !~".*pod.*"}


若有收获,就点个赞吧
0 人点赞
