将图片输入到神经网络中,输出结果存储在outpus中,target为真实标签
loss_value = yolo_loss(outputs, targets)
一、主函数
1.1 YOLOLoss初始化类
nn.BCEWithLogitsLoss的使用,见这篇文章:https://zhuanlan.zhihu.com/p/170558960
class YOLOLoss(nn.Module):def __init__(self, num_classes, strides=[8, 16, 32]):super().__init__()self.num_classes = num_classes # 类数self.strides = strides # 步长列表,即输出特征图中的一个点相当于原图片中多少个像素self.bcewithlog_loss = nn.BCEWithLogitsLoss(reduction="none")# BCEWithLogitsLoss先做一次sigmoid(logits函数),然后再求BCE损失self.iou_loss = IOUloss(reduction="none")# IOU损失# 先生成若干个0(后面再填充),这是列表的扩展self.grids = [torch.zeros(1)] * len(strides)# [torch.zeros(1)]的结果是[tensor([0.])]
1.2 forward方法
def forward(self, inputs, labels=None):outputs = []x_shifts = []y_shifts = []expanded_strides = []#-----------------------------------------------## inputs [[batch_size, 5 + num_classes, 80, 80]# [batch_size, 5 + num_classes, 40, 40]# [batch_size, 5 + num_classes, 20, 20]]# outputs [[batch_size, 6400, num_classes + 5]# [batch_size, 1600, num_classes + 5]# [batch_size, 400, num_classes + 5]]# x_shifts [[batch_size, 6400]# [batch_size, 1600]# [batch_size, 400]]#-----------------------------------------------#for k, (stride, output) in enumerate(zip(self.strides, inputs)):output, grid = self.get_output_and_grid(output, k, stride)#每个网格在x方向上的偏移x_shifts.append(grid[:, :, 0])#每个网格在y方向上的偏移y_shifts.append(grid[:, :, 1])#每个特征图上每个网格的步长(相当于每个网格锚框的大小)expanded_strides.append(torch.ones_like(grid[:, :, 0]) * stride)outputs.append(output)return self.get_losses(x_shifts, y_shifts, expanded_strides, labels, torch.cat(outputs, 1))
二、获取调整后的预测框和网格
本函数的目的是生成一个张量来表示grid,使其表示特征图中每个网格左上角 的坐标,并让output的中心点坐标和高宽变成letterbox图像中的数据
def get_output_and_grid(self, output, k, stride):#获取第k个特征层网格,第一次获取[80,80]grid = self.grids[k]#特征层高和宽hsize, wsize = output.shape[-2:]if grid.shape[2:4] != output.shape[2:4]:#生成80x80的网格yv, xv = torch.meshgrid([torch.arange(hsize), torch.arange(wsize)])#生成每个网格的横纵坐标grid = torch.stack((xv, yv), 2).view(1, hsize, wsize, 2).type(output.type())self.grids[k] = gridgrid = grid.view(1, -1, 2)#将预测框信息x步长,相当于步长大小的锚框output = output.flatten(start_dim=2).permute(0, 2, 1)output[..., :2] = (output[..., :2] + grid.type_as(output)) * strideoutput[..., 2:4] = torch.exp(output[..., 2:4]) * stridereturn output, grid
三、计算损失
def get_losses(self, x_shifts, y_shifts, expanded_strides, labels, outputs):#-----------------------------------------------## [batch, n_anchors_all, 4]# 预测框中心点坐标及宽高,#-----------------------------------------------#bbox_preds = outputs[:, :, :4]#-----------------------------------------------## [batch, n_anchors_all, 1]# 目标置信度#-----------------------------------------------#obj_preds = outputs[:, :, 4:5]#-----------------------------------------------## [batch, n_anchors_all, n_cls]# 各个类别的概率#-----------------------------------------------#cls_preds = outputs[:, :, 5:]#三个特征图所有的anchor数量total_num_anchors = outputs.shape[1]#-----------------------------------------------## x_shifts [1, n_anchors_all]# y_shifts [1, n_anchors_all]# expanded_strides [1, n_anchors_all]#-----------------------------------------------#x_shifts = torch.cat(x_shifts, 1).type_as(outputs)y_shifts = torch.cat(y_shifts, 1).type_as(outputs)expanded_strides = torch.cat(expanded_strides, 1).type_as(outputs)cls_targets = []reg_targets = []obj_targets = []fg_masks = []num_fg = 0.0# 用来记录当前batch中,总共有多少个anchorfor batch_idx in range(outputs.shape[0]):# 当前图片的GT数目,即真实框数目num_gt = len(labels[batch_idx])if num_gt == 0:# 如果第batch_idx张图片中,GT的数目为0,那么就新建几个空张量# .new_zeros表示新建一个与outputs类型相同的零张量cls_target = outputs.new_zeros((0, self.num_classes))reg_target = outputs.new_zeros((0, 4))obj_target = outputs.new_zeros((total_num_anchors, 1))fg_mask = outputs.new_zeros(total_num_anchors).bool()else:#-----------------------------------------------## gt_bboxes_per_image [num_gt, num_classes]# gt_classes [num_gt]# bboxes_preds_per_image [n_anchors_all, 4]# cls_preds_per_image [n_anchors_all, num_classes]# obj_preds_per_image [n_anchors_all, 1]#-----------------------------------------------## GT的中心点坐标及宽高gt_bboxes_per_image = labels[batch_idx][..., :4].type_as(outputs)# GT的类别gt_classes = labels[batch_idx][..., 4].type_as(outputs)# 预测框的中心点坐标及宽高bboxes_preds_per_image = bbox_preds[batch_idx]# 预测框的各个类别概率cls_preds_per_image = cls_preds[batch_idx]# 预测框的目标置信度obj_preds_per_image = obj_preds[batch_idx]# 标签分配,即8400个anchor中,哪些作为正样本,哪些作为负样本gt_matched_classes, fg_mask, pred_ious_this_matching, matched_gt_inds, num_fg_img = self.get_assignments(num_gt, total_num_anchors, gt_bboxes_per_image, gt_classes, bboxes_preds_per_image, cls_preds_per_image, obj_preds_per_image,expanded_strides, x_shifts, y_shifts,)torch.cuda.empty_cache()num_fg += num_fg_img# 分类目标# F.one_hot(gt_matched_classes.to(torch.int64), self.num_classes)返回的张量维度为(len_sg, 4)# pred_ious_this_matching.unsqueeze(-1)返回的张量维度为(len_sg, 1)# 上述两个张量相乘,得到的张量维度为(len_sg, 4)# TODO 上述两个张量相乘的目的是什么?为何类型要乘以IOU?cls_target = F.one_hot(gt_matched_classes.to(torch.int64), self.num_classes).float() * pred_ious_this_matching.unsqueeze(-1)# 置信度目标obj_target = fg_mask.unsqueeze(-1)# 回归目标reg_target = gt_bboxes_per_image[matched_gt_inds]cls_targets.append(cls_target)reg_targets.append(reg_target)obj_targets.append(obj_target.type(cls_target.type()))fg_masks.append(fg_mask)cls_targets = torch.cat(cls_targets, 0)reg_targets = torch.cat(reg_targets, 0)obj_targets = torch.cat(obj_targets, 0)fg_masks = torch.cat(fg_masks, 0)num_fg = max(num_fg, 1)loss_iou = (self.iou_loss(bbox_preds.view(-1, 4)[fg_masks], reg_targets)).sum()loss_obj = (self.bcewithlog_loss(obj_preds.view(-1, 1), obj_targets)).sum()loss_cls = (self.bcewithlog_loss(cls_preds.view(-1, self.num_classes)[fg_masks], cls_targets)).sum()reg_weight = 5.0loss = reg_weight * loss_iou + loss_obj + loss_clsreturn loss / num_fg
五、标签分配self.get_assignments
def get_losses调用了self.get_assignments,它是将8400个anchor划分成正负样本,正样本就是能和GT进行匹配的anchor,负样本就是不能和GT进行匹配的anchor,正样本可以和GT计算分类、回归、置信度损失,负样本只能计算置信度损失。这个函数的代码如下(先展示一部分,讲完第二轮筛选后会讲第二部分):
def get_assignments(self, num_gt, total_num_anchors, gt_bboxes_per_image, gt_classes, bboxes_preds_per_image, cls_preds_per_image, obj_preds_per_image, expanded_strides, x_shifts, y_shifts):"""一张图片输入到模型后,三个检测头会得到8400个anchor,这些anchor只有一部分会当成正样本,与标签进行损失函数计算这个函数就是把这些anchor给找出来Args:num_gt: 当前图片中GT的数量,纯数字total_num_anchors: 三个检测头的anchor总数,纯数字,这里是8400gt_bboxes_per_image: 当前图片中GT的中心点坐标及宽高,维度为(num_gt, 4)gt_classes: 当前图片中,所有GT的类别索引,维度为(num_gt,)bboxes_preds_per_image: 当前图片预测框的中心点坐标及宽高,维度为(8400, 4)cls_preds_per_image: 当前图片预测目标的类别,维度为(8400, 4)obj_preds_per_image: 当前图片预测目标的置信度(目标置信度),维度为(8400, 1)expanded_strides: 各个anchor与输入图片中网格的尺寸比例,即步长,维度为(1, 8400)x_shifts: 各个anchor在特征图中的横坐标,维度为(1, 8400)y_shifts: 各个anchor在特征图中的纵坐标,维度为(1, 8400)Returns:gt_matched_classes:第二轮筛选后得到的anchor对应GT的索引,维度为(len_sg, ),len_sg是经过第二轮筛选后得到的anchor数量fg_mask:第二轮筛选后得到的anchor在8400个anchor中的布尔索引,维度为(8400, )pred_ious_this_matching:第二轮筛选得到的anchor,与其对应的GT的iou,维度为(len_sg, )matched_gt_inds:第二轮筛选得到的anchor能和哪些GT匹配,维度为(len_sg, )num_fg:当前图片中,经过两轮筛选后,所有GT的正样本总数,即能与任意一个GT匹配的anchor总数,一个纯数字""""""第一轮筛选"""#-------------------------------------------------------## fg_mask [n_anchors_all]# is_in_boxes_and_center [num_gt, len(fg_mask)]#-------------------------------------------------------#fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts, total_num_anchors, num_gt)"""下面是第二轮筛选""""""获得筛选后的anchor的边框、类别概率和置信度"""#-------------------------------------------------------## fg_mask [n_anchors_all]# bboxes_preds_per_image [fg_mask, 4]# cls_preds_ [fg_mask, num_classes]# obj_preds_ [fg_mask, 1]#-------------------------------------------------------#bboxes_preds_per_image = bboxes_preds_per_image[fg_mask]cls_preds_ = cls_preds_per_image[fg_mask]obj_preds_ = obj_preds_per_image[fg_mask]num_in_boxes_anchor = bboxes_preds_per_image.shape[0]"""计算IOU损失"""#-------------------------------------------------------## pair_wise_ious [num_gt, fg_mask]#-------------------------------------------------------#pair_wise_ious = self.bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False)pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)"""计算分类损失"""#-------------------------------------------------------## cls_preds_ [num_gt, fg_mask, num_classes]# gt_cls_per_image [num_gt, fg_mask, num_classes]#-------------------------------------------------------#if self.fp16:with torch.cuda.amp.autocast(enabled=False):cls_preds_ = cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * obj_preds_.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()gt_cls_per_image = F.one_hot(gt_classes.to(torch.int64), self.num_classes).float().unsqueeze(1).repeat(1, num_in_boxes_anchor, 1)pair_wise_cls_loss = F.binary_cross_entropy(cls_preds_.sqrt_(), gt_cls_per_image, reduction="none").sum(-1)else:# 正样本anchor的预测分类# cls_preds_.float().unsqueeze(0)返回的维度为(1, fg_mask, cls),.repeat(num_gt, 1, 1)返回的维度为(num_gt, fg_mask, cls)# .sigmoid_()对每个类别的概率做二分类# obj_preds_.unsqueeze(0)返回的维度为(1, fg_mask, 1),.repeat(num_gt, 1, 1)返回的维度为(num_gt, fg_mask, 1)## 之所以这么操作,是为了方便做广播。上述命令执行后,cls_preds_为每个类别的置信度,维度为(num_gt, fg_mask, cls)# 可以改成 (cls_preds_.float().sigmoid_() * obj_preds_.sigmoid_())..unsqueeze(0).repeat(num_gt, 1, 1)cls_preds_ = cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * obj_preds_.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()# 将正样本anchor的预测分类做成one-hot编码gt_cls_per_image = F.one_hot(gt_classes.to(torch.int64), self.num_classes).float().unsqueeze(1).repeat(1, num_in_boxes_anchor, 1)pair_wise_cls_loss = F.binary_cross_entropy(cls_preds_.sqrt_(), gt_cls_per_image, reduction="none").sum(-1)del cls_preds_cost = pair_wise_cls_loss + 3.0 * pair_wise_ious_loss + 100000.0 * (~is_in_boxes_and_center).float()num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds = self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)del pair_wise_cls_loss, cost, pair_wise_ious, pair_wise_ious_lossreturn gt_matched_classes, fg_mask, pred_ious_this_matching, matched_gt_inds, num_fg
5.1 第一轮样本筛选self.get_in_boxes_info
def get_assignments出现了self.get_in_boxes_info函数,它对8400个anchor做第一轮筛选。第一轮筛选使用了两种方法,任意一个anchor只要通过其中一种筛选方法,就可以认为其通过了第一轮筛选。
第一种方法是先把网格的各个中心点坐标求出来,判断其是否在GT的内部,如果在GT的内部,那么就认为该网格对应的anchor与GT匹配。如下图所示: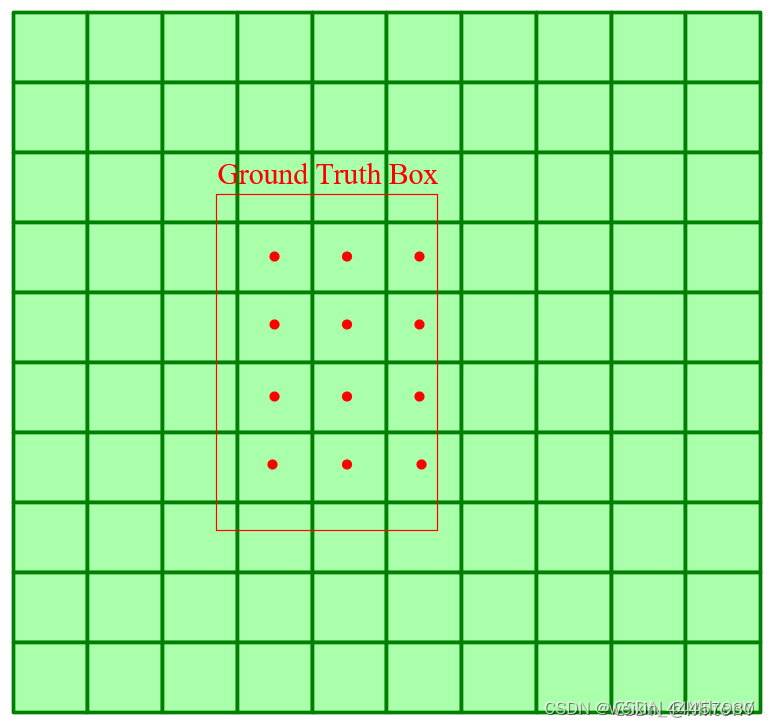
第二种方法是以每个GT的中心点为中心,生成一个边长为5的正方形,判断各个网格的中心点是否在这个正方形的内部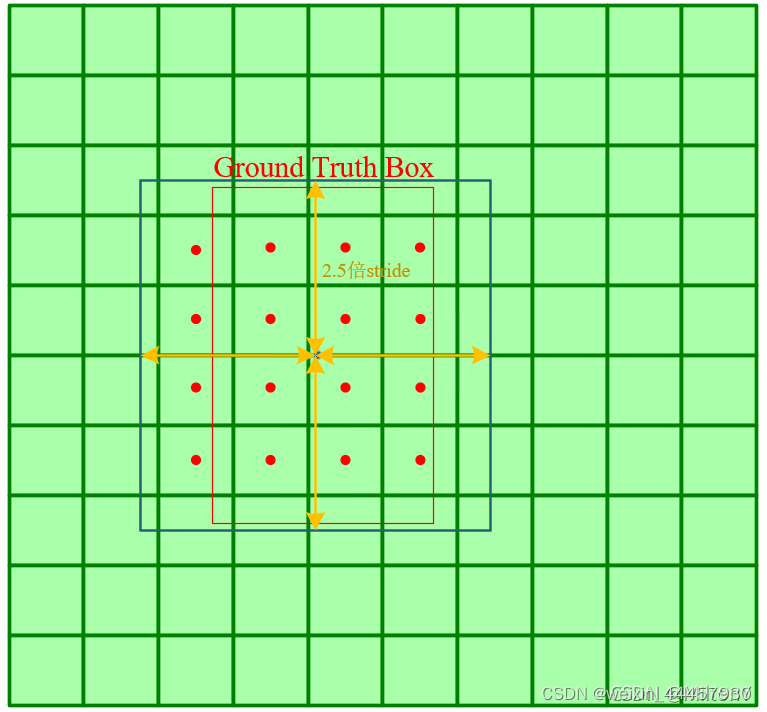
def get_in_boxes_info(self, gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts, total_num_anchors, num_gt, center_radius = 2.5):"""三个检测头,共有8400个anchor,但这些anchor只有部分能和标签进行匹配,本函数就是筛选出能和标签进行匹配的anchor本函数中使用两种方法对anchor进行筛选Args:gt_bboxes_per_image:当前图片中,各个真实框的中心点坐标及宽高,维度为(num_gt, 4)expanded_strides:每个网格的步长,维度为torch.Size([1, 8400])x_shifts:维度为torch.Size([1, 8400])y_shifts:维度为torch.Size([1, 8400])total_num_anchors:网格点总数,纯数字,例如8400num_gt:真实框总数,纯数字center_radius:半径,纯数字Returns:is_in_boxes_anchor 能通过两种方法之一的anchor的布尔索引,维度为(8400, )is_in_boxes_and_center 这也是一个布尔索引,表示第一种筛选方法得到的anchor中,能通过第二种筛选方法的anchor,维度为(num_gt, len_first),len_first是is_in_boxes_anchor中True的数量"""#-------------------------------------------------------## expanded_strides_per_image [n_anchors_all]# x_centers_per_image [num_gt, n_anchors_all]# x_centers_per_image [num_gt, n_anchors_all]#-------------------------------------------------------## 获得每个网格的步长expanded_strides_per_image = expanded_strides[0]# 获得各个网格的中心点横坐标x_centers_per_image = ((x_shifts[0] + 0.5) * expanded_strides_per_image).unsqueeze(0).repeat(num_gt, 1)# 获得各个网格的中心点纵坐标y_centers_per_image = ((y_shifts[0] + 0.5) * expanded_strides_per_image).unsqueeze(0).repeat(num_gt, 1)"""第一种筛选方式:筛选出中心点在GT内部的网格,所对应的anchor""""""各个GT的上下左右边缘"""#-------------------------------------------------------## gt_bboxes_per_image_x [num_gt, n_anchors_all]#-------------------------------------------------------## 每个真实框左边缘x坐标,l表示left,同样的,r、t、b分别 表示右、上、下gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0] - 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1).repeat(1, total_num_anchors)gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0] + 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1).repeat(1, total_num_anchors)gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1] - 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1).repeat(1, total_num_anchors)gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1] + 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1).repeat(1, total_num_anchors)"""计算各个网格中心点与GT各个边缘的距离"""#-------------------------------------------------------## bbox_deltas [num_gt, n_anchors_all, 4]#-------------------------------------------------------#b_l = x_centers_per_image - gt_bboxes_per_image_lb_r = gt_bboxes_per_image_r - x_centers_per_imageb_t = y_centers_per_image - gt_bboxes_per_image_tb_b = gt_bboxes_per_image_b - y_centers_per_image# 新增加一个维度,stack之后,返回的张量维度为(num_gt, 8400, 4)bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2)"""获得各个anchor的匹配情况"""#-------------------------------------------------------## is_in_boxes [num_gt, n_anchors_all]# is_in_boxes_all [n_anchors_all]#-------------------------------------------------------## 获得GT和anchor的匹配矩阵# 只有当最后一个维度的4个数都大于0,才说明对应网格的中心点在GT的内部# 获得一个布尔索引,维度为(num_gt, 8400),# 如果is_in_boxes[i, j]为True,表示第i个GT和第j个网格对应的anchor能匹配上is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0# 获得正样本的索引# is_in_boxes.sum(dim=0)是计算每个网格能与多少个GT进行匹配,# >0表示对应的anchor至少存在一个GT与之匹配# 返回值的维度为(8400, )is_in_boxes_all = is_in_boxes.sum(dim=0) > 0"""第二种筛选方式:以GT的中心为中心,生成一个边长为5个stride的正方形(这里简称GT方框),将中心点落在这个正方形内的网格所对应的anchor,作为与GT匹配的正样本"""# 获得GT方框的左右上下边缘gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(1, total_num_anchors) - center_radius * expanded_strides_per_image.unsqueeze(0)gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(1, total_num_anchors) + center_radius * expanded_strides_per_image.unsqueeze(0)gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(1, total_num_anchors) - center_radius * expanded_strides_per_image.unsqueeze(0)gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(1, total_num_anchors) + center_radius * expanded_strides_per_image.unsqueeze(0)"""计算各个网格中心点与GT方框各个边缘的距离"""#-------------------------------------------------------## center_deltas [num_gt, n_anchors_all, 4]#-------------------------------------------------------#c_l = x_centers_per_image - gt_bboxes_per_image_lc_r = gt_bboxes_per_image_r - x_centers_per_imagec_t = y_centers_per_image - gt_bboxes_per_image_tc_b = gt_bboxes_per_image_b - y_centers_per_imagecenter_deltas = torch.stack([c_l, c_t, c_r, c_b], 2)"""获得各个anchor的匹配情况"""#-------------------------------------------------------## is_in_centers [num_gt, n_anchors_all]# is_in_centers_all [n_anchors_all]#-------------------------------------------------------#is_in_centers = center_deltas.min(dim=-1).values > 0.0is_in_centers_all = is_in_centers.sum(dim=0) > 0"""将上述两种方法综合起来"""#-------------------------------------------------------## is_in_boxes_anchor [n_anchors_all]# is_in_boxes_and_center [num_gt, is_in_boxes_anchor]#-------------------------------------------------------## anchor按照上述两种方法,只要有一种能和标签匹配上,就认为其是正样本is_in_boxes_anchor = is_in_boxes_all | is_in_centers_allis_in_boxes_and_center = is_in_boxes[:, is_in_boxes_anchor] & is_in_centers[:, is_in_boxes_anchor]return is_in_boxes_anchor, is_in_boxes_and_center
5.2第二轮筛选(simOTA算法)
第一轮筛选后,就要做第二轮筛选了。第二轮筛选使用简化的OTA算法,即simOTA算法,它的过程如下:
(1)计算每个anchor(经过第一轮筛选后得到的anchor)与每个GT的分类损失和iou损失,然后求和得到cost矩阵(成本函数);
(2)在经过第一轮筛选后得到的anchor中,为每个GT找到与其有最大IOU的10个anchor,将这10个anchor对应的IOU值求和取整,即为当前GT所匹配到的anchor数量,即dynamic_k,IOU排名前dynamic_k的anchor即为和当前GT匹配的anchor。可以用如下例子理解这一过程: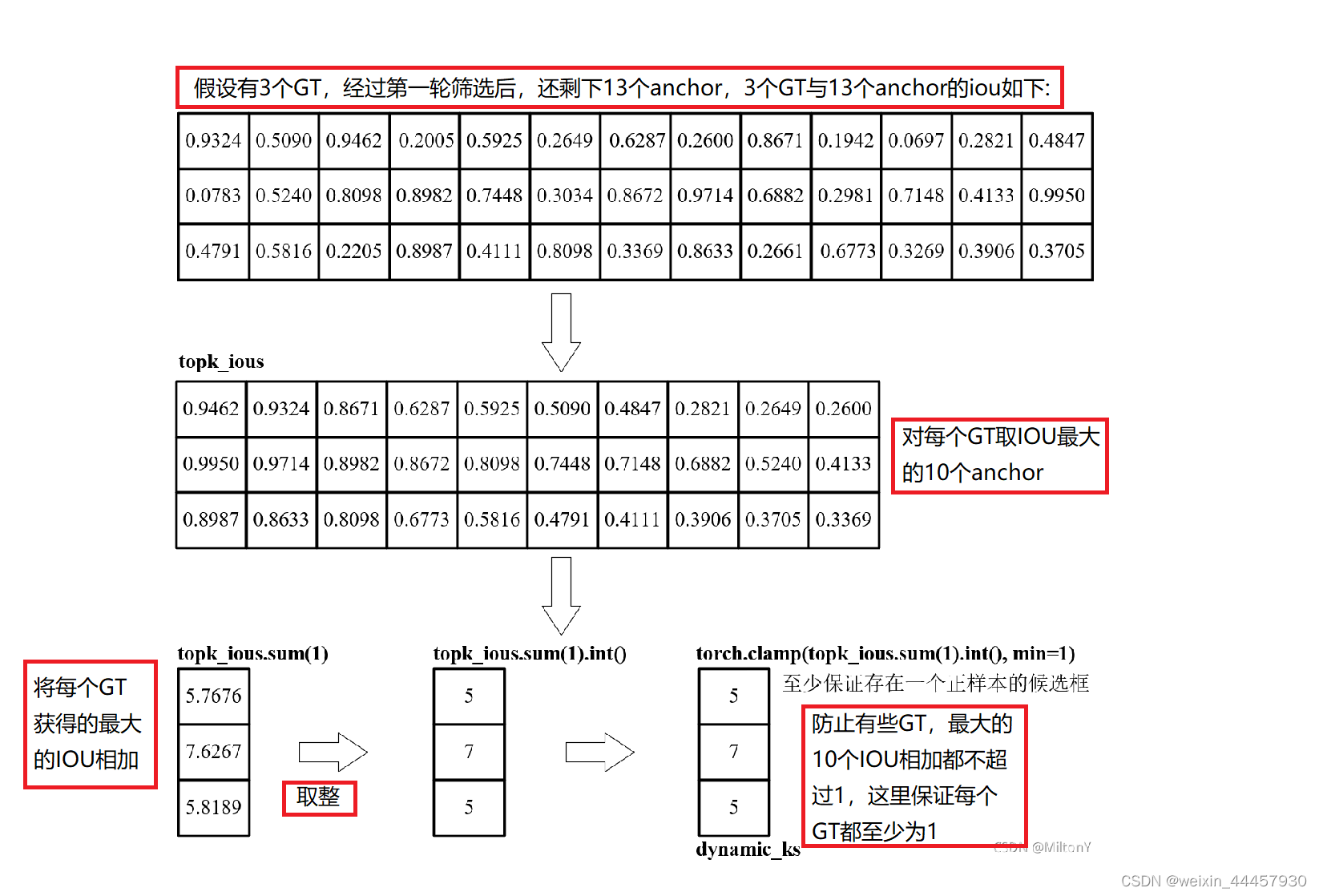
理解了以上过程,就能更好地看懂第二轮筛选的代码了。让我们回到def get_assignments函数中,添加以下代码,做第二轮筛选:
5.2.1 self.bboxes_iou
def bboxes_iou(self, bboxes_a, bboxes_b, xyxy=True):"""求GT与预测框(anchor)的交并比Args:bboxes_a: GT,维度为(num_gt, 4)bboxes_b: 预测框,维度为(len_fg, 4),len_fg是经过第一轮筛选后得到的anchor数量xyxy:GT和预测框,是否为边框上下角点的坐标Returns: iou GT和预测框的交并比,维度为(num_gt, len_fg),例如iou[i, j]表示第i个GT和第j个预测框的交并比"""if bboxes_a.shape[1] != 4 or bboxes_b.shape[1] != 4:raise IndexErrorif xyxy:#交集的左上角xy坐标tl = torch.max(bboxes_a[:, None, :2], bboxes_b[:, :2])#交集的右下角xy坐标br = torch.min(bboxes_a[:, None, 2:], bboxes_b[:, 2:])#a面积area_a = torch.prod(bboxes_a[:, 2:] - bboxes_a[:, :2], 1)#b面积area_b = torch.prod(bboxes_b[:, 2:] - bboxes_b[:, :2], 1)else:tl = torch.max((bboxes_a[:, None, :2] - bboxes_a[:, None, 2:] / 2),(bboxes_b[:, :2] - bboxes_b[:, 2:] / 2),)br = torch.min((bboxes_a[:, None, :2] + bboxes_a[:, None, 2:] / 2),(bboxes_b[:, :2] + bboxes_b[:, 2:] / 2),)area_a = torch.prod(bboxes_a[:, 2:], 1)area_b = torch.prod(bboxes_b[:, 2:], 1)# 获得左上角小于右下角的索引# (tl < br)得到布尔索引,.type(tl.type())将其转化为数值,.prod(dim=2)表示将第二个维度的元素相乘# 如果相乘之后还是1,那么说明“左<右”和“上<下”同时满足,即GT和预测框存在交集# 维度为(num_gt, len_fg)en = (tl < br).type(tl.type()).prod(dim=2)# 计算交集面积area_i = torch.prod(br - tl, 2) * en# 返回交并比return area_i / (area_a[:, None] + area_b - area_i)
5.2.2 self.dynamic_k_matching
def dynamic_k_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):"""一个GT能和多个anchor进行匹配,但一个anchor只能和一个GT进行匹配,也就是说GT和anchor是一对多的关系这个函数先进行第二轮筛选,获得若干个anchor,然后求这些anchor与对应GT、GT的目标类别、与所匹配GT的IOU本函数还以传引用的方式对fg_mask进行了更新,更新后的fg_mask变成了第二轮筛选后得到的anchor在8400个anchor中的布尔索引Args:cost:第一轮筛选得到的anchor与GT的成本函数,维度为(num_gt, len_fg),len_fg是8400个anchor经过第一轮筛选后得到的数量pair_wise_ious:GT和第一轮得到的anchor的交并比,维度为(num_gt, len_fg)gt_classes:当前图片中,所有GT的类别索引,维度为(num_gt,)num_gt:当前图片中GT的数量,纯数字fg_mask:第一轮筛选得到的anchor在8400个anchor中的布尔索引,维度为(8400, )Returns: num_fg:当前图片中,所有GT的正样本总数,即能与任意一个GT匹配的anchor总数,一个纯数字gt_matched_classes:第二轮筛选后得到的anchor对应GT的索引,维度为(len_sg, ),len_sg是经过第二轮筛选后得到的anchor数量pred_ious_this_matching:第二轮筛选得到的anchor,与其对应的GT的iou,维度为(len_sg, )matched_gt_inds:第二轮筛选得到的anchor能和哪些GT匹配,维度为(len_sg, )假如len_fg=50,len_sg=20,若 matched_gt_inds[5]=3 则表示第5个anchor(20中的第5个)匹配的GT的索引是3gt_matched_classes[5]=2 则表示与第5个anchor(20中的第5个)匹配的GT(即索引为3的GT),其类别索引是2pred_ious_this_matching[5]=0.53,则表示第5个anchor(20中的第5个),与其匹配的GT(即索引为3的GT)的iou为0.53""""""初始化匹配矩阵"""#-------------------------------------------------------## cost [num_gt, fg_mask]# pair_wise_ious [num_gt, fg_mask]# gt_classes [num_gt]# fg_mask [n_anchors_all]# matching_matrix [num_gt, fg_mask]#-------------------------------------------------------#matching_matrix = torch.zeros_like(cost)"""确定每个GT能匹配的anchor数量"""#------------------------------------------------------------## 选取iou最大的n_candidate_k个点# 然后求和,判断应该有多少点用于该框预测# topk_ious [num_gt, n_candidate_k]# dynamic_ks [num_gt]# matching_matrix [num_gt, fg_mask]#------------------------------------------------------------#n_candidate_k = min(10, pair_wise_ious.size(1))# 对每个GT,寻找最大的10个(或len_fg个)IOUtopk_ious, _ = torch.topk(pair_wise_ious, n_candidate_k, dim=1)#确定和GT匹配的anchor数量,最少为1dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1)"""给每个真实框选取k个标签进行匹配"""for gt_idx in range(num_gt):#------------------------------------------------------------## pos_idx是损失最小的k个预测框(anchor)对应的索引#------------------------------------------------------------#_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False)# 给匹配矩阵的对应的索引赋1matching_matrix[gt_idx][pos_idx] = 1.0# 释放内存del topk_ious, dynamic_ks, pos_idx"""有些anchor可能同时和多个GT匹配,需要在matching_matrix中,对这些anchor进行处理"""#------------------------------------------------------------## anchor_matching_gt [fg_mask]#------------------------------------------------------------## 维度为(fg_mask, ),表示每个anchor能和多少个GT进行匹配anchor_matching_gt = matching_matrix.sum(0)# anchor_matching_gt>1 的返回值是一个维度为(fg_mask, )的布尔索引# 在fg_mask个anchor中,如果存在某个anchor能和多个GT匹配,那么这个anchor对应的索引就是True# .sum()用来求有多少个这样的特征点if (anchor_matching_gt > 1).sum() > 0:# 当某一个anchor指向多个GT的时候,选取cost最小的GT作为与其匹配的GT# cost[:, anchor_matching_gt > 1] 是将能与多个GT匹配的anchor取出,维度为(num_gt, match_mul),# 某些anchor能与多个GT匹配,这样的anchor数量为match_mul,即match_mul是能与多个GT匹配的anchor的数量# torch.min dim=0表示对每列求最小值# cost_argmin每列最小值所对应的索引(GT的索引),维度为(match_mul, )# 若cost_argmin[2]为4,则表示在cost矩阵中,# 第2个anchor(match_mul中的第2个anchor)所在列中,与第4个GT的损失函数最小_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)# 在matching_matrix中,先把这样的anchor所在列全部设为0matching_matrix[:, anchor_matching_gt > 1] *= 0.0# 再把每个这样的anchor列的最小值所对应的GT设为1matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0"""第二轮筛选整理"""#------------------------------------------------------------## fg_mask_inboxes [fg_mask]# num_fg为正样本的特征点个数#------------------------------------------------------------## 返回一个布尔索引,代表第一轮筛选得到的anchor是否能通过第二轮筛选,# 即是否为正样本,维度为(fg_mask, )fg_mask_inboxes = matching_matrix.sum(0) > 0.0# 当前图片中,所有GT的正样本总数,即能与任意一个GT匹配的anchor总数,即len_sgnum_fg = fg_mask_inboxes.sum().item()#------------------------------------------------------------## 对fg_mask进行更新#------------------------------------------------------------## fg_mask本身代表8400个anchor中,通过第一轮筛选的anchor所对应的布尔索引# fg_mask[fg_mask.clone()],布尔索引的布尔索引,即把所有为True的元素筛选出来,对这些元素进行重新赋值,# 赋值之后,fg_mask代表第二轮筛选后得到的anchor在8400个anchor中的索引# 至此,第二轮筛选结束,fg_mask的维度为(8400, )fg_mask[fg_mask.clone()] = fg_mask_inboxes"""获得第二轮筛选后得到的anchor,其所对应GT、GT的目标类别、与所匹配GT的IOU"""# 获得anchor对应GT的索引,维度为(len_sg, ),sg表示 second GT# matching_matrix[:, fg_mask_inboxes]返回的是GT与第二轮筛选得到的anchor的匹配矩阵,维度为(num_fg, len_sg)# .argmax(0)是求各列的最大值,因为各列只有一个值为1,其余都为0,由于每个anchor最多只能和一个GT匹配,# 所以这里是求各个anchor能和哪些GT匹配,维度为(len_sg, )# 假设len_sg=20,即通过第二轮筛选后还剩20个anchor,若matched_gt_inds[5]的值为3,# 那么意思是第5个anchor(20中的第5个)匹配的GT的索引是3matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)# 根据GT的索引,获得特征点对应的GT的类别# 若gt_matched_classes[5]的值为2,#那么意思是第5个anchor(20中的第5个)匹配的GT,其类别索引为2gt_matched_classes = gt_classes[matched_gt_inds]# matching_matrix * pair_wise_ious的维度是(num_gt, len_fg),表示经第二轮筛选后得到的anchor与GT的iou,# 每列最多只有一个元素有值,有可能一个都没有,所以.sum(0)是将这些iou给取出来,变成一个维度为(fg_mask, )的张量,# [fg_mask_inboxes]是从中取出经过第二轮筛选后得到的anchor与对应的GT的iou# 最后得到的pred_ious_this_matching,其维度为(len_sg, ),表示第二轮筛选得到的anchor,与其对应的GT的iou# 若pred_ious_this_matching[5]的值为0.53,则表示第5个anchor(20中的第5个),与其匹配的GT的iou为0.53# 第5个anchor与哪一个GT匹配呢,这个要看 matched_gt_inds 才知道pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[fg_mask_inboxes]return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds
Reference

若有收获,就点个赞吧
0 人点赞
